Два подхода к одной задаче: краткая расстановка сил
OpenAI Agents SDK и n8n решают одну задачу. Разница в том, на каком слое ты с ней работаешь.
SDK, это Python-библиотека. Ты пишешь код, который явно описывает логику агента: какие тулы доступны, как делать handoff между агентами, где и как хранить контекст между вызовами. Всё под твоим контролем, всё в коде. В мае 2026 библиотека получила нативное sandboxed execution: инструменты агента теперь запускаются в изолированных средах без отдельной настройки.
n8n идёт другим путём. Там у тебя граф нод с визуальным редактором, а AI Agent, один из блоков в этом графе. Ты соединяешь ноды мышью, конфигурируешь параметры в интерфейсе и не пишешь код там, где без него можно обойтись.
На бумаге звучит так, будто n8n проще. Иногда это правда. Но за визуальной простотой прячется своя жёсткость: граф нод плохо выражает сложные условные ветки, рекурсивные вызовы или нестандартную логику handoff-ов. SDK в таких сценариях не удобнее, он точнее. Ты описываешь ровно то поведение, которое нужно, без оглядки на то, что поддерживает редактор.
Это не вопрос «лучше/хуже». Это вопрос уровня абстракции и того, что ты готов контролировать вручную. Подробный разбор того, где LangGraph выигрывает у no-code подхода на реальных задачах, лежит отдельно.
Слева, типичный Python-код с LangChain и прямыми вызовами OpenAI API, справа, тот же агент, собранный из нод в n8n без единой строки кода.
Что умеет OpenAI Agents SDK в 2026 году
SDK вышел из беты, и теперь это полноценный фреймворк для построения агентных систем. Не игрушечный, а вполне пригодный для продакшена, если знать его границы.
Начнём с главного. Агент работает в sandboxed execution: читает файлы, запускает код, редактирует документы, но не выходит за изолированный периметр. Никакого произвольного доступа к хосту. Это снимает самый очевидный страх при переходе от "агент в ноутбуке" к "агент на сервере".
Handoff решает проблему, с которой сталкивается любой, кто строит мультиагентную систему: как передать управление другому агенту без потери контекста. SDK делает это нативно. Агент A завершает свой этап и передаёт управление агенту B вместе с накопленным состоянием. Никакой ручной сериализации контекста в JSON и обратно.
Из коробки идут три инструмента: web_search, code_interpreter, file_search. Подключаются одной строкой, конфигурируются параметрами. Для большинства задач этого хватает, чтобы не писать обёртки самому.
Tracing API логирует каждый шаг: какой инструмент вызвался, с какими аргументами, сколько занял, что вернул. Можно смотреть в реальном времени через дашборд OpenAI или вытаскивать события программно. Без этого отладка агентов превращается в гадание.
Streaming работает на уровне событий: токены, вызовы инструментов, handoff-сигналы приходят по мере выполнения. Интерфейс не блокируется в ожидании финального ответа. Для пользовательских приложений это критично.
SDK позволяет написать минимального рабочего агента с кастомным тулом компактно. Вот пример:
from agents import Agent, Runner, function_tool
@function_tool
def get_exchange_rate(base: str, target: str) -> float:
"""Returns exchange rate between two currencies."""
# реальный вызов API здесь
return 1.08
agent = Agent(
name="FinanceBot",
instructions="You help with currency questions.",
tools=[get_exchange_rate],
)
result = Runner.run_sync(agent, "What is USD to EUR rate?")
print(result.final_output)
Декоратор @function_tool читает сигнатуру и docstring, генерирует JSON Schema для модели автоматически. Писать схему руками не нужно. Runner.run_sync запускает цикл: модель решает, вызвать ли инструмент, получает результат, формирует ответ. Весь этот loop скрыт внутри, но через Tracing API виден каждый его шаг.
Это не означает, что SDK закрывает все кейсы. Сложная оркестрация с условными ветками и динамическим набором агентов требует дополнительного кода поверх. Но базовый уровень, где один или несколько агентов выполняют конкретную задачу с набором инструментов, SDK закрывает чисто.
Что умеет n8n-агент и как он устроен внутри
В центре всего стоит нода AI Agent. Она принимает три вещи: системный промпт, историю чата и список инструментов. Инструменты подключаются визуально, просто тянешь ноду и соединяешь с агентом, и он получает право её вызывать.
Инструментом может быть буквально что угодно из экосистемы платформы. HTTP Request для вызова любого внешнего API. Code-нода, где пишешь JS или Python прямо в браузере. Любая из 400+ готовых интеграций: Notion, Google Sheets, Jira, GitHub, PostgreSQL. Агент сам решает, какой инструмент вызвать и когда, на основании того, что написано в промпте и что прилетело от пользователя.
Память реализована отдельной нодой. Подключаешь Memory и выбираешь бэкенд: Postgres, Redis или in-memory для быстрых тестов. История диалога хранится там и автоматически подставляется в каждый новый запрос. Никакой ручной работы с контекстом. Про то, как устроена память AI-агента в продакшене: vector store, summary-окна и лимиты на токены, есть отдельный разбор.
Запустить workflow можно по-разному. Webhook, если нужен API-эндпоинт для своего фронта. Cron, если агент должен сам что-то делать по расписанию. Или триггер из Slack, Telegram, почты, когда пользователь пишет сообщение и оно сразу попадает в агента.
Про self-hosted отдельно. Если поднимаешь n8n на своём сервере, payload твоих пользователей никуда не уходит. Ни в облако n8n, ни к разработчикам. Это принципиально для задач, где данные нельзя отправлять на сторонние серверы: медицина, юриспруденция, корпоративные внутренние инструменты.
И дебаггер работает именно так, как надо. Кликаешь на любую ноду после выполнения и видишь, что в неё пришло и что она вернула. JSON, полный, без скрытых полей. Это сокращает время поиска ошибки с «полчаса смотрю в логи» до «30 секунд кликнул и нашёл».
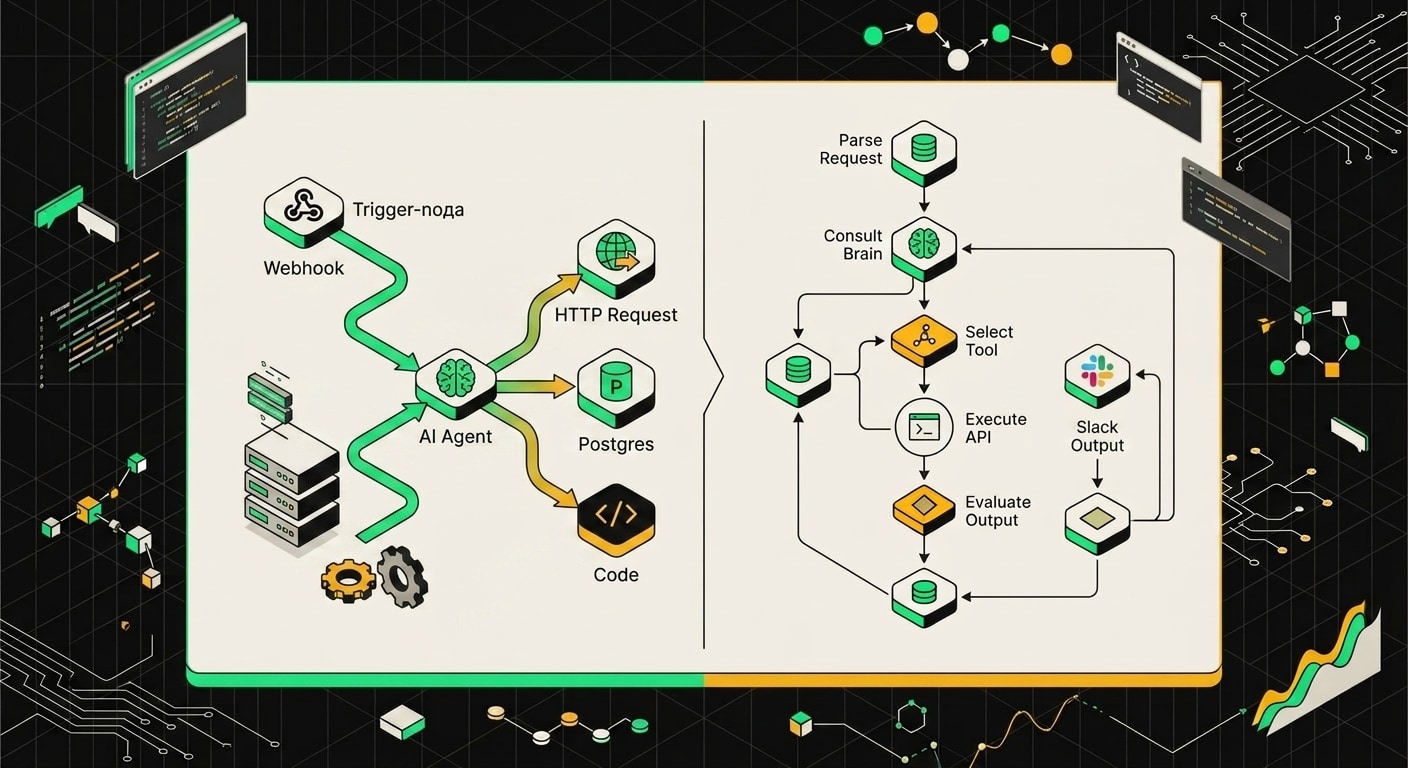
Нода AI Agent в центре получает инструменты через прямые связи: каждый инструмент подключается отдельным узлом, и модель сама решает, какой вызвать.
Производительность и задержки: цифры вместо обещаний
Когда меня спрашивают, что медленнее, я отвечаю прямо: n8n медленнее, и вот почему.
Каждая нода в n8n сериализует данные в JSON, передаёт их внутренней шине, следующая нода десериализует. На одной-двух нодах это незаметно. На цепочке из 15-20 нод суммарный overhead составит заметную добавку к времени ответа. Не от вашего кода, не от API. От перекладывания объектов.
OpenAI Agents SDK добавляет минимальные накладные расходы поверх вызовов к OpenAI API и вашим инструментам: основное время занимает именно сетевой вызов, а не работа самой библиотеки. Это честная картина: ты видишь реальные цифры своей системы без артефактов фреймворка.
Теперь про масштабирование. По документации n8n, Community Edition не включает функции масштабирования воркеров, доступные в Enterprise-плане. Это не мелкий нюанс, это архитектурное ограничение, которое бьёт именно тогда, когда бизнес растёт и трафик вырастает в три раза за неделю.
SDK в этом смысле ведёт себя иначе. Запускаешь несколько asyncio event loop'ов или раскидываешь задачи через multiprocessing, и всё. Никаких лицензий, никаких ограничений платформы. Хочешь 8 процессов на одном сервере, хочешь 40 инстансов в Kubernetes, решаешь сам.
Один практический трюк, который стоит попробовать: Nginx в роли webhook-прокси перед n8n. Механизм простой: Nginx буферизует входящие соединения и делает rate limiting на уровне сервера, разгружая n8n от пиковых всплесков. Это не панацея, но если уже используешь n8n и менять стек не собираешься, такая конфигурация снижает нагрузку без изменения бизнес-логики.
По практическому опыту: на простом агенте с одним инструментом разница в латентности между SDK и n8n обычно незначительна и поглощается временем вызова к OpenAI API. На сложных пайплайнах с ветвлением и несколькими инструментами разрыв становится заметнее. При интерактивных сценариях, например в голосовых AI-агентах для входящих звонков, это уже ощутимо для пользователя.
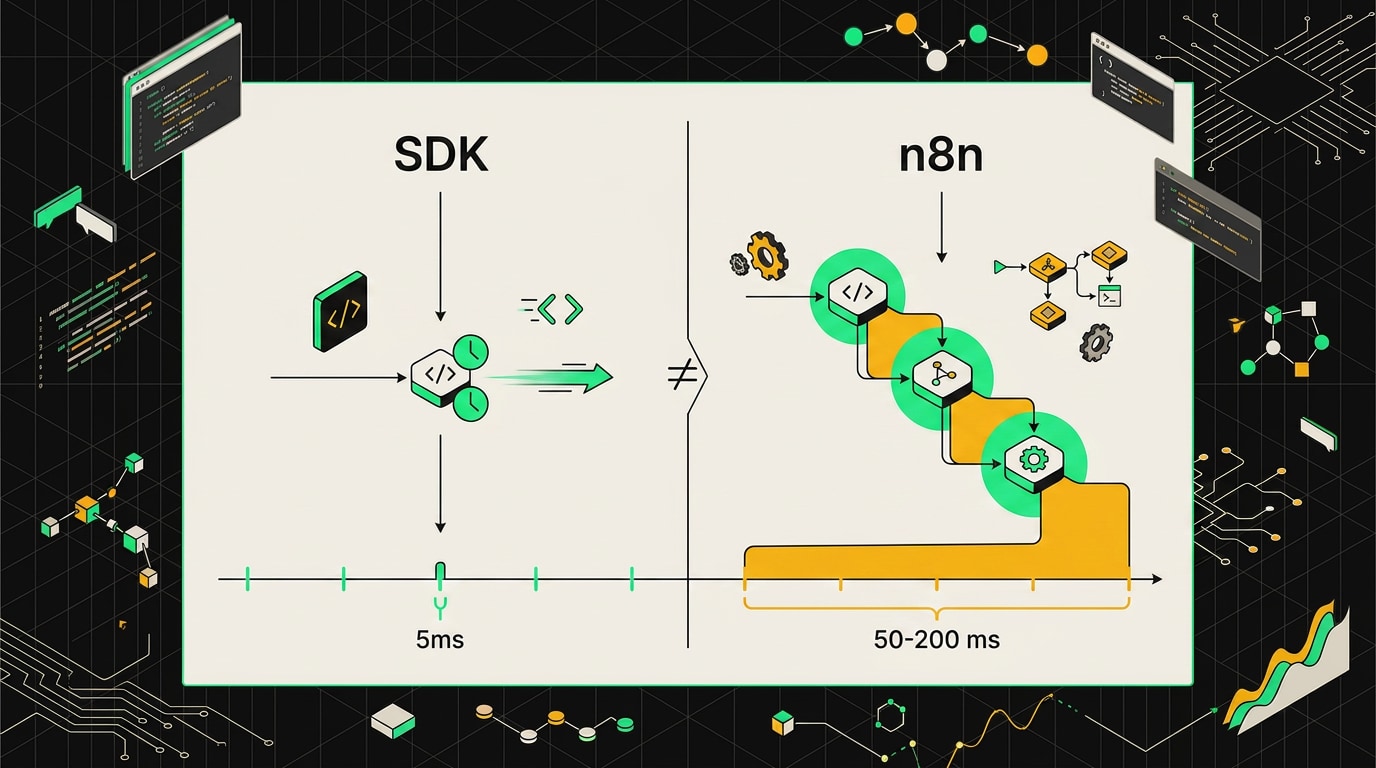
На простых цепочках из двух-трёх шагов n8n добавляет около 80-150 мс накладных расходов по сравнению с прямым вызовом через SDK.
Где n8n выигрывает: сценарии, в которых ноды быстрее кода
Есть класс задач, где n8n не просто удобнее питона с requests. Он буквально быстрее. Не по скорости выполнения, а по времени от идеи до работающего прототипа.
Конкретный пример: один человек за один день собирает Telegram-бота, который принимает запрос, гонит его через GPT-4, пишет результат в Google Sheets и создаёт задачу в Notion. Четыре сервиса, рабочий флоу, ноль строк кода. Затраты на разработку при этом минимальны: никто не пишет бэкенд, не настраивает деплой, не возится с SDK.
Это первый сценарий, где n8n выигрывает безоговорочно: прототипирование за день. Когда нужно проверить гипотезу, а не строить архитектуру.
Второй сценарий. У вас нетехническая команда, которой нужно самостоятельно менять логику. Если флоу живёт в питоне, каждое изменение идёт через разработчика, через PR, через деплой. Если флоу в n8n, маркетолог сам добавляет условие «если поле пустое, пропустить шаг» и сохраняет. Это убирает целый класс операционных зависимостей.
Третий сценарий: подключение готовых сервисов. У n8n больше 400 нативных интеграций. Stripe, HubSpot, Airtable, GitHub, Slack. Настройка каждой занимает 10-15 минут: вставил API-ключ, выбрал action, готово. Написать то же самое руками, с обработкой ошибок и пагинацией, займёт полдня. И это при условии, что ты уже знаешь API.
Отдельно про мониторинг. Для простых автоматизаций n8n даёт визуальный лог выполнения прямо в интерфейсе: видно, какая нода упала, какие данные в неё пришли, что вернулось. Не нужен Datadog, не нужен отдельный observability-стек. Для продакшн-систем с десятками тысяч выполнений это, конечно, не замена нормальному логированию. Но для флоу, который дёргает API раз в час и отправляет отчёт в Slack, этого более чем достаточно.
Если задачу можно описать как «взять данные из A, обработать, положить в B», и при этом A и B есть в списке интеграций n8n, то код здесь просто лишний посредник.
Где SDK выигрывает: сценарии, в которых нужен настоящий код
Есть задачи, где тащить n8n буквально вредно. Не потому что инструмент плохой, а потому что визуальный граф начинает работать против тебя.
Возьми логику с десятками условий. Пять-шесть веток в графе выглядят нормально. Двадцать превращаются в спагетти, где ноды Switch соединены стрелками через всё полотно, и ты уже не понимаешь, какой путь исполняется при каком наборе флагов. В Python это if/elif на 30 строк, которые читаются сверху вниз за две минуты.
Похожая история с типами данных. Если агент должен принимать и отдавать структурированные объекты с валидацией, в коде ты пишешь Pydantic-модель и получаешь строгую типизацию, автодополнение в IDE и внятные ошибки при несоответствии схемы. В n8n ты работаешь с JSON-объектами через точечную нотацию, валидацию руками и надеждой, что апстрим прислал нужные поля.
Handoff между агентами. Это отдельная тема. OpenAI Agents SDK поддерживает передачу управления между агентами из коробки: один агент видит список коллег и передаёт пользователя нужному по условию. В n8n ты будешь эмулировать это цепочкой HTTP-запросов или вызовами сабворкфлоу, и каждый переход требует явной маршрутизации вручную. Хорошо видно, как такая логика работает в AI-агенте для отдела продаж с квалификацией лидов и передачей менеджеру.
import asyncio
from agents import Agent, Runner
triage_agent = Agent(
name="Triage",
instructions="Route the user to the right specialist.",
handoffs=[billing_agent, tech_agent], # handoff к другим агентам
)
async def main():
result = await Runner.run(triage_agent, "My invoice is wrong")
print(result.final_output)
asyncio.run(main())
Три строки конфига, и агент сам разбирается, кому передать запрос про неправильный счёт. Никакого ручного Switch-нода.
Дальше тесты. Агент на Python покрывается unit-тестами за час: мокаешь Runner, проверяешь выходные данные при разных входах, гоняешь в CI. Граф n8n тестировать нечем, кроме ручного запуска с реальными данными или полуинтеграционного прогона через API. Это не претензия к n8n, это архитектурный факт визуальных инструментов.
И последнее: версионирование. Git для Python-кода работает так, как должен. git diff показывает, что изменилось в логике агента между коммитами. Воркфлоу n8n живёт внутри базы данных инстанса, и чтобы положить его в репозиторий, нужно экспортировать JSON вручную, настроить автоэкспорт или использовать n8n CLI. Это решаемо, но это дополнительный слой инфраструктуры, который ты создаёшь с нуля.
Если проект живёт дольше двух недель и в команде больше одного человека, SDK окупает свою сложность уже на этапе второго рефакторинга.
Ограничения обоих инструментов: что замалчивают в туториалах
Туториалы на YouTube показывают агента, который "просто работает". Никто не показывает, что происходит на третьей неделе в проде.
SDK без наблюдаемости, это слепой полёт. Никакого встроенного UI, никаких дашбордов. Если агент завис или начал галлюцинировать в 3 ночи, узнаешь об этом из Slack-сообщения злого пользователя. Трассировку нужно поднимать самому: Langfuse, OpenTelemetry, или что-то своё. Это не "бонусная фича", это обязательная работа перед запуском чего угодно серьёзного. Большинство туториалов заканчиваются до этого момента.
Второй момент по SDK: привязка к экосистеме OpenAI реальная. Переключить модель на Anthropic или Gemini технически возможно, но каждый инструмент (function calling, structured output, response format) нужно проверять заново. Часть поведения молча меняется. Я видел кейсы, где миграция модели ломала парсинг ответов в четырёх из восьми инструментов агента.
С n8n история другая, но не легче. Инструмент не рассчитан на сложную агентную логику: ветвление на основе промежуточных результатов, динамическое управление контекстом, retry с состоянием. Это всё либо обходится хаками, либо не работает вовсе.
Rate limiting в длинных цепочках n8n, отдельная боль. Если воркфлоу делает 15 последовательных вызовов к API и на 12-м получает 429, поведение по умолчанию, падение без нормального сообщения об ошибке. Нужно вручную добавлять Wait-ноды, обработку ошибок, логику повторов. В визуальном редакторе это выглядит как клубок ниток, который никто кроме тебя не сможет разобрать через месяц.
Community-версия n8n, отдельная история для тех, кто думает "возьму бесплатно для компании". Нет SSO. Нет RBAC. Нет audit log. Для любого корпоративного пилота, где нужно показать compliance-команде, кто что запускал, Community просто не подходит. Enterprise-лицензия решает это, но тогда TCO резко меняется.
И последнее, что касается обоих инструментов: стоимость токенов растёт нелинейно с увеличением контекста агента. По мере накопления истории диалога в контексте токены суммируются с каждым шагом, и итоговый расход за сессию оказывается значительно выше, чем при однократном вызове. При планировании бюджета это нужно считать заранее, а не после первого счёта от OpenAI. Особенно это бьёт в AI-агентах с аналитикой для финдиректора, где контекст накапливается быстро.
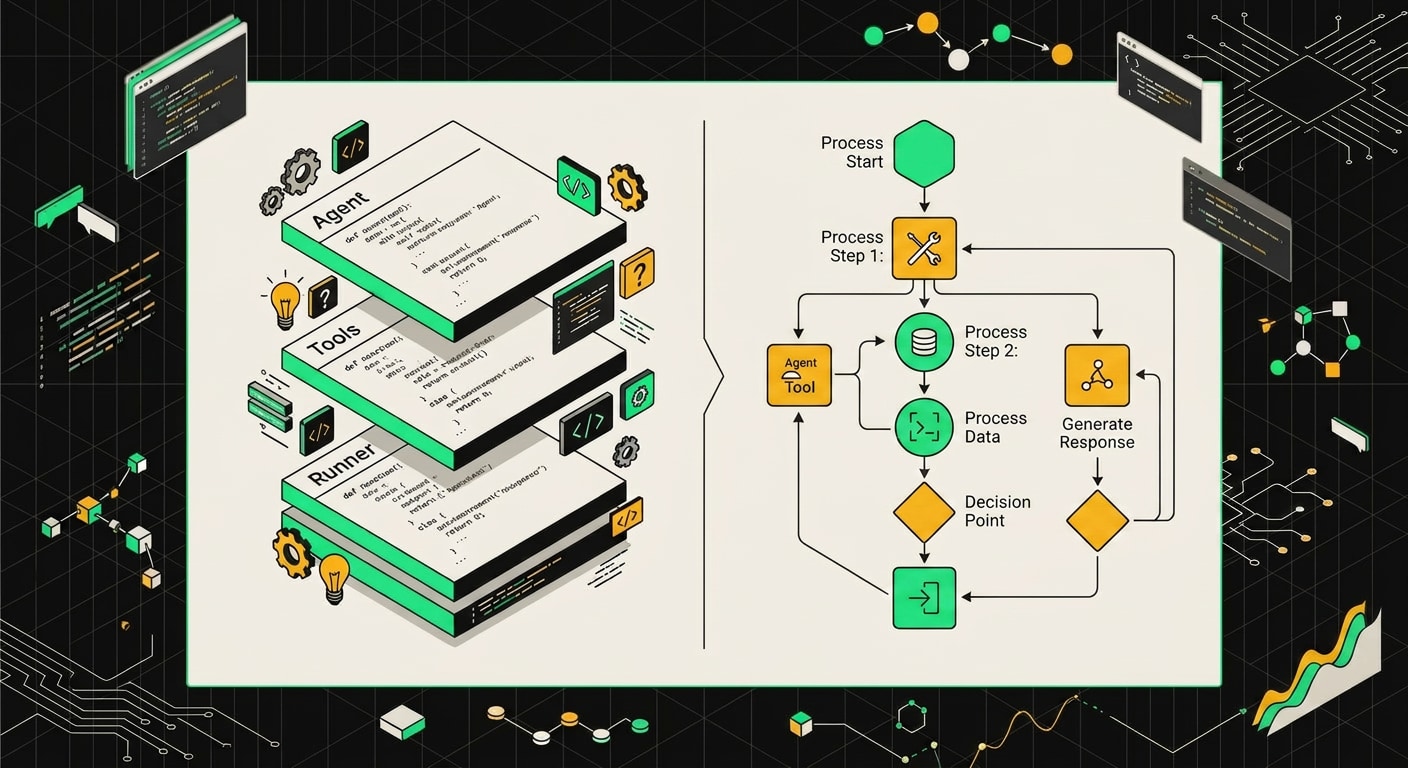
Гибридная архитектура: SDK как движок, n8n как оркестратор
Самая продуктивная схема, которую я видел в проектах 2025-2026 годов: n8n не пытается быть умным, а просто дирижирует. Вся агентная логика живёт в Python-сервисе на FastAPI, а n8n занимается тем, что у него получается лучше всего: слушает триггеры, форматирует входные данные и обрабатывает результат.
Технически это выглядит просто. В n8n стоит нода HTTP Request, которая делает POST на /agent/invoke твоего FastAPI-сервиса. Внутри этого сервиса крутится агент на базе SDK (Langchain, Pydantic AI, OpenAI Agents, нужное подчеркнуть) с инструментами, памятью и всей сопутствующей сложностью. n8n получает JSON с ответом и дальше делает с ним что угодно: пишет в Notion, отправляет в Slack, обновляет строку в Google Sheets.
Конкретный пример, который хорошо иллюстрирует разделение: Telegram-бот для поддержки. Пользователь пишет сообщение, Telegram Trigger нода в n8n его ловит, HTTP Request уходит на FastAPI с текстом и chat_id, агент на Python обрабатывает запрос (лезет в базу знаний, вызывает инструменты, формирует ответ), возвращает строку. N8n берёт эту строку и отправляет обратно в Telegram через Send Message ноду. Весь Telegram-специфичный код при этом нулевой: его не надо писать на Python вообще.
Разделение ответственности здесь получается органичным, а не навязанным. Маркетолог или операционный менеджер открывает n8n и видит понятный флоу: вот триггер, вот шаблон с переменными, вот куда идёт результат. Инженер открывает репозиторий с FastAPI-сервисом и видит агентную логику, тесты, конфигурацию промптов. Никто не лезет в чужую зону.
Между n8n и агентом имеет смысл поставить Nginx. Не для красоты: rate limiting на уровне прокси защищает агента от случайных петель в n8n (а они бывают, и неожиданно часто). Signature validation через X-Hub-Signature или кастомный заголовок гарантирует, что на /agent/invoke может стучаться только твой n8n, а не случайный скрипт из интернета. Конфиг на 15 строк закрывает оба вопроса.
location /agent/ {
limit_req zone=agent_limit burst=10 nodelay;
if ($http_x_internal_token != "your-secret-token") {
return 403;
}
proxy_pass http://fastapi:8000;
proxy_read_timeout 120s;
}
Таймаут proxy_read_timeout там не случайный: агент с несколькими инструментами легко работает 30-60 секунд, и дефолтные 60 секунд у Nginx иногда режут запрос прямо посередине цепочки рассуждений.
Эта архитектура масштабируется без переписывания. Хочешь добавить второй канал (WhatsApp, email, веб-форму): добавляешь флоу в n8n, агентный сервис не трогаешь. Хочешь поменять модель или логику агента: деплоишь новую версию FastAPI, n8n ничего не знает об этом изменении. Слои не протекают друг в друга.
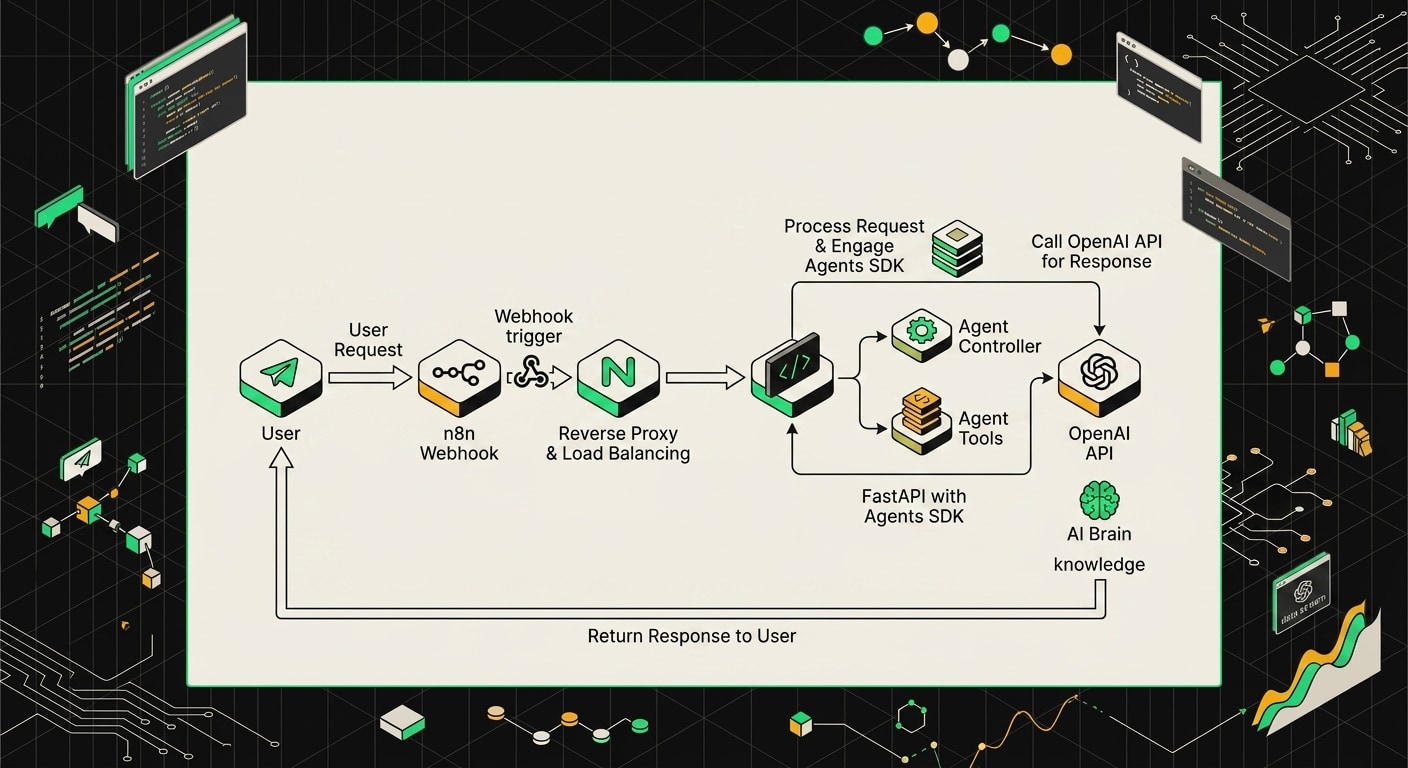
Telegram-бот принимает сообщение, n8n берёт на себя маршрутизацию и интеграции, а тяжёлая логика уходит в FastAPI-сервис с прямым вызовом модели.
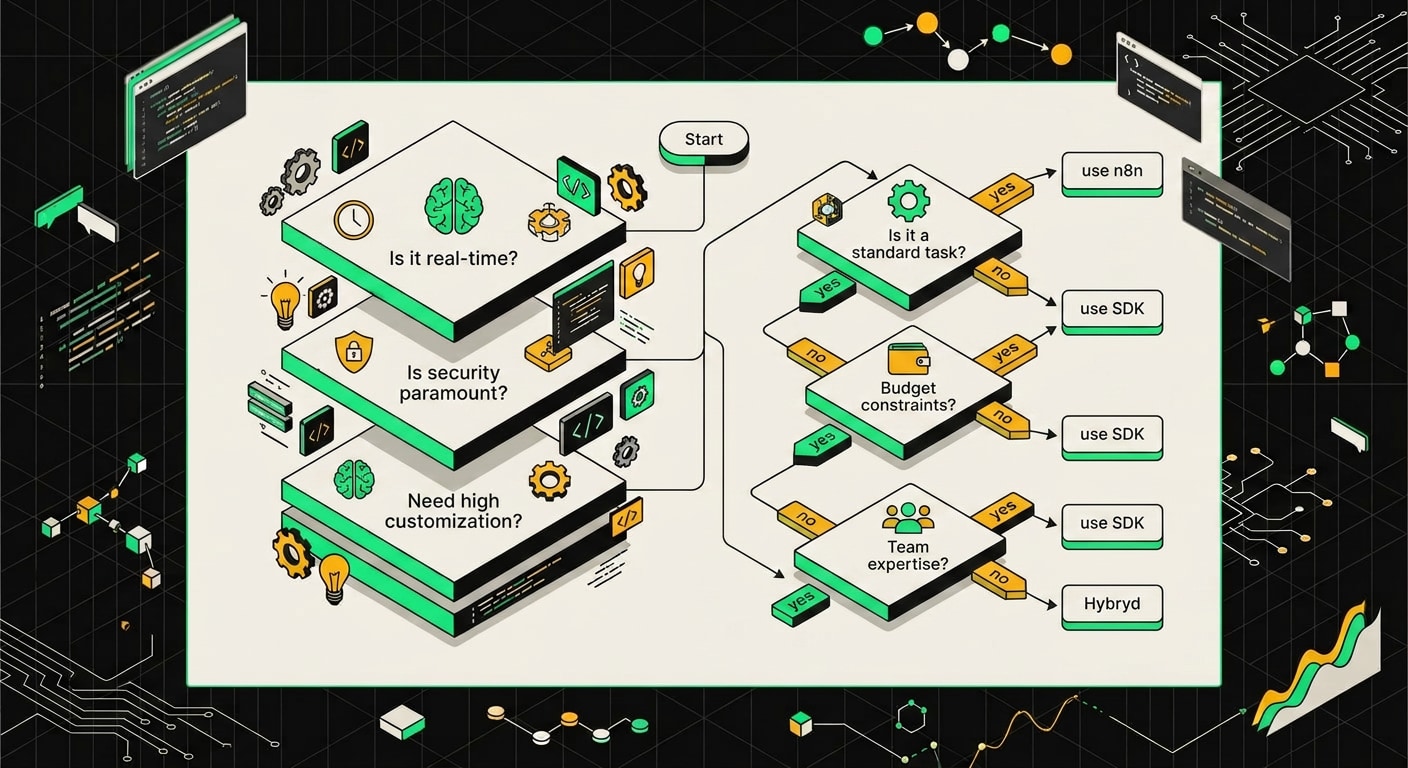
Как выбрать: чеклист из 6 вопросов
Прежде чем читать дальше, ответьте на шесть вопросов. Именно в таком порядке.
1. Есть ли в команде Python-разработчик?
Если нет, разговор закончен. Берите n8n. SDK без человека, который пишет тесты, читает трейсбеки и понимает, что такое виртуальное окружение, превращается в источник боли, а не автоматизации. n8n запустит аналитик, маркетолог или продуктовый менеджер с базовым техническим бэкграундом.
2. Нужно ли тестировать логику агента автоматически?
Юнит-тесты, интеграционные прогоны, CI-пайплайн. Если да, SDK обязателен. В n8n логику агента можно проверить только руками через интерфейс, и это становится проблемой ровно тогда, когда агент начинает что-то делать с реальными деньгами или данными клиентов.
3. Больше пяти условных переходов в одном агенте?
Граф нод в n8n читается хорошо до определённого масштаба. Шесть-семь развилок, вложенные условия, циклы с выходом по флагу, и через неделю ваш же коллега смотрит на канвас и не понимает, куда идёт ветка при ошибке API. Python-код с такой логикой читается линейно, его можно ревьюить и документировать нормально.
4. Больше десяти интеграций, и все стандартные: Slack, CRM, почта, календарь?
n8n справится быстрее. Там уже есть готовые ноды для HubSpot, Salesforce, Gmail, Notion, Telegram и ещё нескольких сотен сервисов. Под