Почему сравнение стало актуальным именно сейчас
Года три назад вопрос "n8n или LangGraph" просто не звучал. n8n автоматизировал Webhook-триггеры и Slack-уведомления, LangGraph не существовал. Агентские системы были уделом исследовательских лабораторий.
В 2026 картина другая. Команды строят агентов, которые принимают решения, вызывают инструменты, хранят состояние между шагами и умеют вернуться назад при ошибке. Это уже не "интеграция приложений" в классическом смысле. И именно здесь инструменты начали пересекаться на одной территории.
n8n проделал серьёзный путь. AI Agent-нода, LangChain-интеграция, поддержка memory. Маркетингово это выглядит как "да, мы тоже агенты". Но под капотом n8n остался тем, чем был: workflow-движком с последовательным или ветвящимся исполнением нод. Граф там направленный и ациклический. Петли, условная маршрутизация с возвратом, динамическое изменение плана по ходу выполнения, всё это требует костылей или просто не работает так, как нужно.
LangGraph 0.2+ пошёл другим путём. Stateful-агенты, явные циклы в графе, встроенная телеметрия через LangSmith. Это не надстройка над чем-то старым, а архитектура, спроектированная под то, что агент может выполнить шаг, получить результат, переоценить ситуацию и вернуться.
Реальная проблема проявилась не в теории, а в проектах. PoC на n8n собирается за день. Буквально: накидал ноды, прогнал тестовый сценарий, показал стейкхолдерам. А потом начинается продакшн, и появляются требования: retry при падении LLM-вызова, human-in-the-loop перед критическим действием, ветвление по результату предыдущего агентского шага. И оказывается, что визуальный редактор n8n превращается в источник боли, а не скорости.
Вопрос сместился. Раньше спрашивали "что выбрать". Теперь спрашивают конкретнее: где именно ломается no-code подход, и стоит ли вообще начинать на n8n, если через месяц придётся переписывать.

То, что работает за выходные в PoC, в продакшне обрастает обработкой ошибок, ретраями и мониторингом, и превращается в совсем другой зверь.
Архитектурная разница: DAG против графа состояний
n8n под капотом это DAG. Ориентированный ациклический граф нод, где данные текут от триггера к выходу одним потоком. Каждая нода получает массив items, что-то с ним делает, отдаёт следующей. Никаких циклов в графе по определению. Если нужно итерироваться, ты берёшь Loop Over Items или собираешь самовозвратную конструкцию через Merge и IF, и оно работает, но визуально превращается в спагетти, а отладка становится археологией.
LangGraph построен иначе. Это StateGraph, где узлы не передают данные друг другу напрямую, а читают и пишут в общий State. Рёбра могут быть условными, циклическими, какими угодно. Узел "agent" вызывает узел "tools", тот возвращается обратно в "agent", и так пока условие выхода не сработает. Цикл не костыль, а первичная конструкция.
Вот ReAct-агент с пятью итерациями рефлексии целиком:
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
iterations: int
def agent_node(state):
return {"messages": [llm.invoke(state["messages"])], "iterations": state["iterations"] + 1}
def should_continue(state):
if state["iterations"] >= 5:
return END
return "tools" if state["messages"][-1].tool_calls else END
graph = StateGraph(AgentState)
graph.add_node("agent", agent_node)
graph.add_node("tools", tool_node)
graph.add_conditional_edges("agent", should_continue)
graph.add_edge("tools", "agent")
graph.set_entry_point("agent")
app = graph.compile(checkpointer=postgres_saver)
Тридцать строк. Попробуй собрать то же самое в n8n: получишь полотно из десятка нод с обратными связями через Wait и Set, ручным счётчиком итераций в workflow static data и проверкой tool_calls через Function-ноду. Работать будет, читаться нет.
Дальше про State. Annotated[list, operator.add] это не косметика. Это редьюсер: когда узел возвращает {"messages": [new_msg]}, LangGraph не перезаписывает поле, а конкатенирует. Поле iterations без аннотации перезаписывается. Ты явно описываешь семантику изменения каждого ключа состояния, и это даёт предсказуемость, которую в n8n приходится эмулировать через workflow variables и осторожный merge.
Checkpointer, вторая принципиальная вещь. Компиляция с postgres_saver (или SqliteSaver для локалки) означает, что после каждого шага граф сериализует State в БД. Падение процесса, рестарт пода, человек ушёл пить кофе на час посреди human-in-the-loop, любой сценарий: ты вызываешь app.invoke(None, config={"configurable": {"thread_id": "..."}}) и продолжаешь с той же точки. Состояние агента, история сообщений, счётчик итераций, всё восстанавливается.
n8n тоже хранит execution data. Но это лог запуска воркфлоу для UI и ретраев, а не state machine агента. Resume в n8n означает "перезапустить ноду с теми входами, которые у неё были". Resume в LangGraph означает "продолжить работу конечного автомата с того узла, где он остановился, со всем накопленным контекстом". Разные вещи на уровне примитивов.
Отсюда практический водораздел. Линейный pipeline с ветвлениями и парой ретраев живёт в n8n отлично и быстрее собирается мышкой. Агент с рефлексией, ветвящимися инструментами, паузой на подтверждение оператора и продолжением через сутки, это территория LangGraph. Пытаться затащить второе в первое можно, но ты переизобретаешь StateGraph поверх DAG, и каждая новая фича ломает предыдущую.
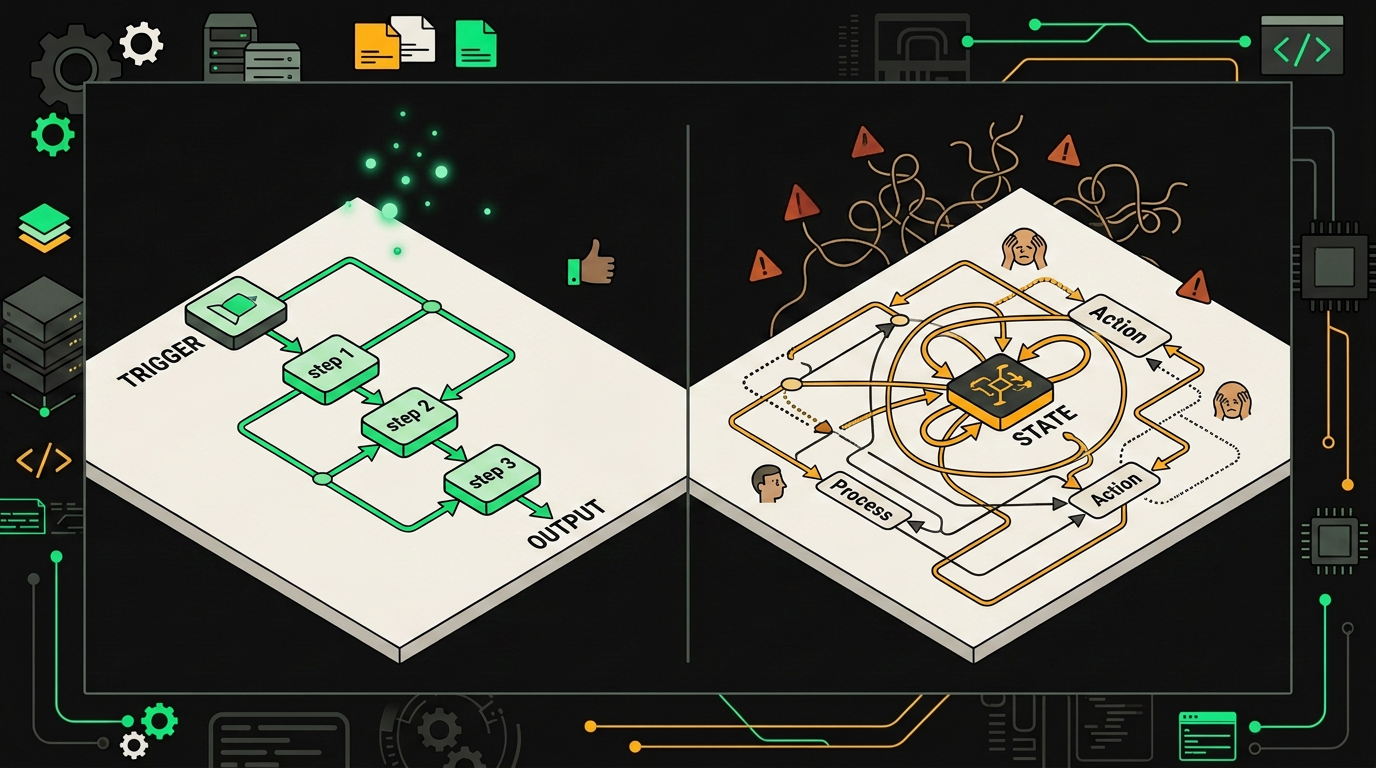
n8n строит линейный DAG узлов, а LangGraph описывает граф состояний с циклами и условными переходами, разница принципиальная, если агент должен итерировать.
Скорость прототипирования: где n8n действительно выигрывает
Конкретный пример: Telegram-бот, который принимает вопрос, ищет релевантные страницы в Notion через API и отдаёт ответ через GPT-4o. В n8n это собирается за 20 минут. Webhook-нода, HTTP Request к Notion Search, OpenAI-нода, ответ обратно в Telegram. Всё.
В LangGraph тот же пайплайн займёт 2-3 часа, если делать честно. Надо поднять Python-окружение, прописать зависимости (langchain, langgraph, python-telegram-bot или аналог), написать граф с нодами и рёбрами, настроить async-обработку, задеплоить куда-то где это будет жить. И это без учёта времени на отладку, когда Notion отдаёт 429 и надо разбираться почему.
n8n закрывает рутину через 400+ готовых интеграций. Slack, Gmail, Airtable, Stripe, HubSpot, Google Sheets, всё подключается за минуту через OAuth. Не нужно читать документацию каждого API, разбираться с auth-флоу, писать обёртки. Для отдела маркетинга или операций, где автоматизации строит человек без глубокого Python-бэкграунда, это принципиально.
Отдельно про отладку. В n8n после каждого запуска видно payload на каждой ноде: что пришло на вход, что ушло на выход, сколько занял запрос. Можно кликнуть на любой шаг и посмотреть сырой JSON. Это удобно не только новичкам, я сам трачу меньше времени на поиск бага, когда данные видны визуально, а не в логах терминала.
LangGraph устроен иначе. Там нужно самому добавлять логирование, ставить pdb или LangSmith, настраивать трейсинг. Это нормально для инженера, который строит продакшн-агента. Но если задача, автоматизировать онбординг лидов из HubSpot в Notion с уведомлением в Slack, это избыточная инфраструктура.
Вердикт прямой: для линейных пайплайнов и внутренних автоматизаций n8n быстрее и дешевле. Маркетинг, продажи, операционка, HR-процессы, всё, где логика не разветвляется и агент не принимает сложных решений на основе состояния. Здесь n8n выигрывает по скорости в разы, а по стоимости разработки, ещё больше.

Рабочий прототип агента в n8n собирается перетаскиванием узлов быстрее, чем пишется первый класс на Python.
Где no-code ломается: 6 сценариев в пользу LangGraph
n8n и Make хороши, пока workflow линейный или с парой ветвлений. Как только появляется реальная агентность, начинается боль. Я собрал шесть точек, где я бросаю no-code и переписываю на LangGraph.
1. Supervisor-pattern с делегированием. Координатор смотрит на запрос, выбирает специализированного агента (researcher, coder, critic), отдаёт задачу, собирает результат, решает что дальше. В n8n это рисуется как дерево из IF-нод и ломается на третьем уровне вложенности. В LangGraph supervisor это узел, который возвращает имя следующего узла, и граф сам маршрутизирует. Добавить седьмого агента, три строчки.
2. Долгая память между сессиями. Чат-бот должен помнить, что пользователь две недели назад жаловался на биллинг. n8n хранит контекст в рамках одного запуска, дальше начинаются костыли с внешней БД и ручной сериализацией. LangGraph через PostgresSaver или RedisSaver сохраняет полный state по thread_id из коробки, и ты просто продолжаешь разговор.
3. Human-in-the-loop с реальным прерыванием. Это сценарий, ради которого я в первую очередь беру LangGraph. Агент дошёл до отправки письма клиенту, остановился, ждёт апрув в админке, через час менеджер нажал "ок" и агент продолжил с того же места, не пересчитывая всё с нуля.
from langgraph.checkpoint.postgres import PostgresSaver
# Прерывание перед критическим узлом
app = graph.compile(
checkpointer=PostgresSaver.from_conn_string(DB_URL),
interrupt_before=["send_email"]
)
config = {"configurable": {"thread_id": "user-42"}}
result = app.invoke(input_data, config)
# Состояние сохранено, ждём апрува
# ...через час, после approve в админке:
app.invoke(None, config) # продолжает с того же узла
В n8n такое реализуется через webhook-паузу, но восстановление всего состояния агента (история сообщений, промежуточные tool calls, scratchpad) ты будешь шить руками.
4. Streaming токенов в UI. Пользователь хочет видеть, как ответ печатается. n8n отдаёт результат ноды только когда нода завершилась целиком, поэтому стриминг через него не пробросить. LangGraph даёт astream_events, и я пушу токены в SSE или WebSocket по мере генерации, плюс отдельно стримлю события вроде on_tool_start, чтобы в интерфейсе показать "ищу в базе...".
5. Fallback между моделями. Стратегия "GPT-4o упал по rate limit, переключись на Claude Sonnet 4.5, если и он упал, на локальный Qwen". В no-code это городится через Error Trigger и копию workflow для каждого провайдера. В LangGraph fallback это узел с try/except и условным ребром, плюс retry-политика на уровне runnable. Логика fallback живёт в одном месте, а не размазана по семи нодам.
6. Граф, который меняется во время выполнения. LLM посмотрела на задачу и решила, что нужно сначала декомпозировать её на 4 подзадачи, потом для каждой запустить отдельный subgraph, потом смерджить. Количество подзадач заранее неизвестно. LangGraph умеет в Send API: узел возвращает список Send("worker", state) и платформа параллельно запускает N веток. В n8n ты максимум сделаешь Split In Batches с фиксированной логикой, а динамическое ветвление через LLM-решение придётся имитировать через Code-ноду с ручным вызовом API.
Грубое правило для меня сейчас: если в схеме появляется слово "агент" в его настоящем смысле (модель сама решает, что делать дальше, и решение зависит от предыдущих шагов), n8n заканчивается. Дальше LangGraph.

Супервайзер-агент останавливает выполнение и ждёт подтверждения человека перед тем, как делегировать задачу суб-агенту с деструктивными правами.
Observability: LangSmith vs логи n8n
Когда у тебя в продакшене крутится агент с пятью инструментами и ветвлением по результатам ретривала, вопрос "почему он ответил вот так" перестаёт быть риторическим. И вот тут разница между LangSmith и n8n становится болезненно очевидной.
LangSmith из коробки пишет трейс на каждый вызов LLM. Видно дерево: какой узел графа дёрнул какую модель, сколько токенов ушло в prompt, сколько вернулось в completion, латентность по миллисекундам, стоимость в долларах. Всё агрегируется по тредам, по пользователям, по версиям промпта. Открываешь UI, фильтруешь по latency > 8s за последние сутки, и сразу видишь, что тормозит конкретный tool call к внешнему API, а не сама модель.
Дальше eval. У LangSmith встроены датасеты и LLM-as-judge: сохраняешь сотню реальных диалогов из прода, размечаешь ожидаемое поведение, и при каждом изменении промпта гоняешь регрессию. Это позволяет ловить деградации, которые в ручном тестинге легко пропустить: новый системный промпт может улучшать ответы на типовых кейсах и при этом ронять точность на edge-cases.
n8n показывает execution logs на каждой ноде. Input, output, ошибка если была. Этого хватает, чтобы понять "вот тут JSON развалился". Но агрегации по моделям нет. Сравнить gpt-4o и claude-3.5 по средней латентности за неделю? Сам пиши SQL по дампу executions. Посчитать суммарную стоимость токенов за месяц? Парси output вручную, токены n8n не выделяет в отдельное поле.
На практике это значит: для нормальной observability в n8n ты прикручиваешь сбоку Elasticsearch с Kibana или Prometheus с Grafana. Пишешь HTTP-ноду, которая после каждого LLM-вызова шлёт метрику. Делаешь дашборды. Это рабочая схема, я так делал на двух проектах, но это заметный объём инженерного времени, который в LangSmith ты получаешь после pip install.
OpenTelemetry усугубляет разрыв. LangGraph экспортирует OTLP-трейсы нативно, конфиг на четыре строки, и спаны летят в Jaeger или Tempo. n8n такого не умеет, нужен middleware-слой: либо форк с инструментацией, либо прокси перед HTTP-нодами, который сам генерит спаны.
Цена вопроса простая. Single-agent flow с линейной логикой ты отдебажишь по логам n8n за полчаса. Multi-agent с динамической маршрутизацией, где агент-супервизор решает, к кому из четырёх специалистов идти, и они могут вызывать друг друга, без трассировки превращается в дни перебора. У меня был кейс, где баг воспроизводился редко и зависел от порядка tool calls. Фильтры трейсов в LangSmith позволили локализовать проблему значительно быстрее, чем это было бы возможно по логам n8n.

LangSmith показывает точно, какой вызов съел 80% бюджета токенов и где агент завис на 4 секунды из 5.
TCO и масштабирование: реальные цифры
Считаю в лоб, по прайсам на май 2026.
n8n Cloud. Pro-тариф $50/мес за 10k executions. Звучит дёшево, пока один AI-воркфлоу не начинает жечь по 5-7 executions на запрос (тулзы, ретраи, sub-workflows). 10k улетают за пару недель активного использования агентом в проде. Enterprise-тариф включает SSO, аудит-логи, RBAC и SLA; без этого корпоративная безопасность часто не подписывает интеграцию.
n8n self-hosted. Лицензия Community бесплатная (Sustainable Use License, с оговорками про резейл и встраивание в свой SaaS). Дальше начинается реальный счёт: VPS на 4 vCPU / 8 GB RAM это где-то $40/мес у Hetzner, $80-120 у AWS/GCP за сравнимую конфигурацию. Плюс Postgres, плюс Redis для queue mode, плюс бэкапы, плюс мониторинг. И главная статья: DevOps-часы. При 50+ параллельных AI-воркфлоу n8n начинает упираться в очередь queue mode, Redis распухает, а worker-ноды приходится скейлить руками. Автоскейла из коробки нет.
LangGraph. Сама библиотека MIT, ставится pip install и работает. LangGraph Platform (managed) в составе платной подписки от $39/seat в месяц за Plus, есть тариф с usage-based ценой за деплои. LangSmith Plus отдельно $39/seat для трейсинга и оценок. Если хостите сами, LangGraph живёт как обычное Python-приложение: FastAPI + Celery + Redis, либо LangGraph Server в Docker. Горизонтальное масштабирование это вопрос количества подов в Kubernetes, а не архитектурной перестройки.
Грубая прикидка для проекта на 100k AI-запросов в месяц с 5 разработчиками:
| Вариант | Платформа | Инфра | Команда | Итого/мес |
|---|---|---|---|---|
| n8n Cloud Pro | $50 + overage ~$200 | 0 | 0 | ~$250 |
| n8n self-hosted | 0 | $80 VPS + $40 Redis/PG | ~$400 DevOps | ~$520 |
| LangGraph self-hosted + LangSmith | $195 (5 seats) | $150 K8s | ~$600 разработка | ~$945 |
| LangGraph Platform | $195 + ~$300 deploys | 0 | ~$300 | ~$795 |
И вот скрытая статья, которую никто не закладывает на старте. Когда продукт на n8n вырастает за рамки "автоматизация на 20 нод" и начинаются кастомные ретраи, версионирование промптов, A/B-тесты агентов, человекочитаемые трейсы для аналитиков, миграция в код может занять несколько месяцев у небольшой инженерной команды. Если вы заранее знаете, что строите AI-продукт, а не внутреннюю автоматизацию, эти месяцы дешевле потратить сразу на LangGraph.
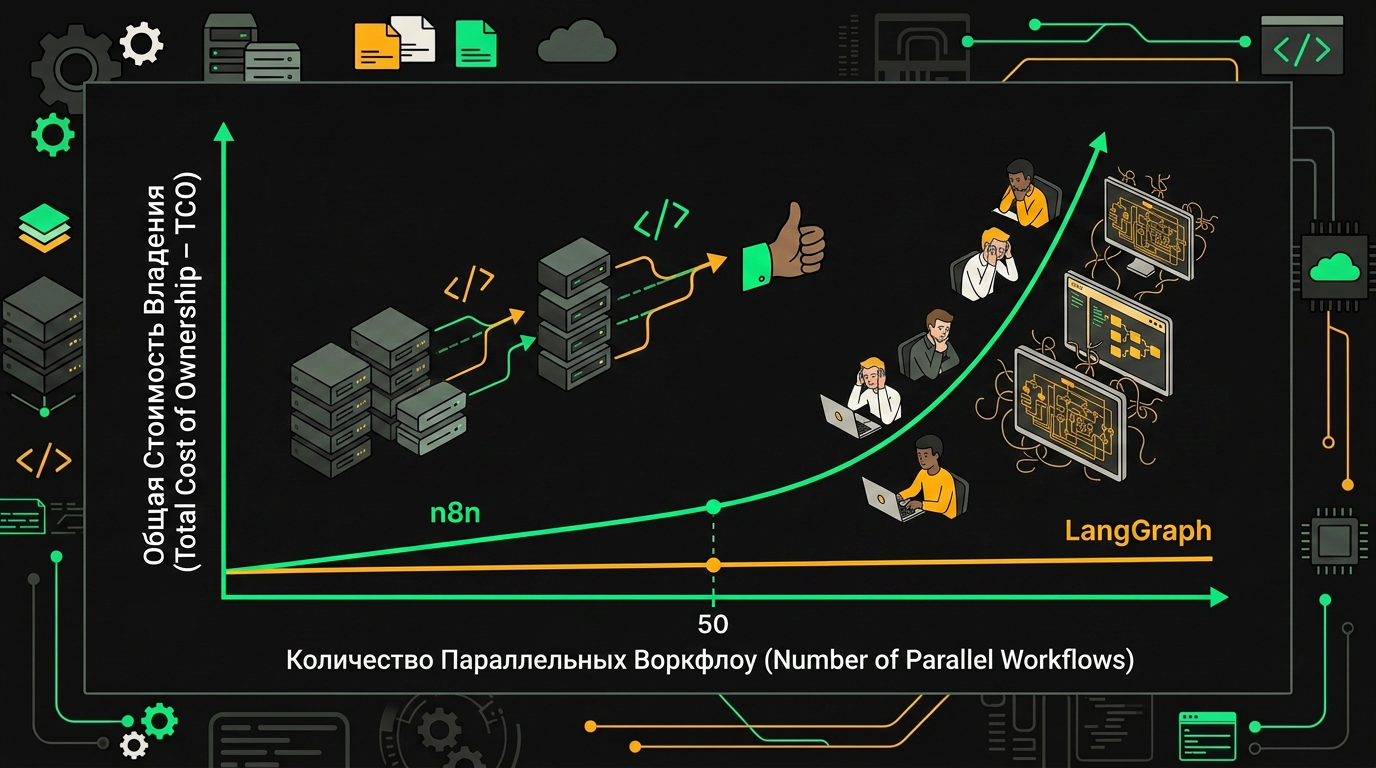
При росте числа запросов расходы на n8n Cloud растут линейно по исполнениям, тогда как LangGraph на своём инфраструктуре упирается в стоимость вычислений.
Гибридный подход: n8n как фронт, LangGraph как мозг
К весне 2026 в проде у нас устаканился один паттерн, и я его сейчас тащу почти в каждый клиентский проект. n8n ловит события и разруливает интеграции, LangGraph думает. Между ними HTTP.
Логика простая. Webhook от Telegram, новое письмо в Gmail, изменение карточки в Pipedrive. n8n получает событие, дотягивает контекст из соседних систем (тот же Notion, Postgres, S3), собирает payload и стучится по HTTP в LangGraph-сервис. Тот развёрнут как FastAPI-эндпоинт или через LangServe, держит состояние в чекпоинтере (мы используем Postgres), отвечает результатом. n8n кладёт ответ туда, куда надо: в чат, в CRM, в очередь на ручную проверку.
Почему так, а не всё в одном месте. У n8n 400+ нод, и писать руками клиент к Hubspot или Salesforce, когда есть готовая нода с OAuth, это самосаботаж. У LangGraph человеческий API для графов с циклами, прерываниями, human-in-the-loop, чего в n8n из коробки нет и не будет. Поэтому интеграции и роутинг живут в n8n, агентская логика и долгое состояние в LangGraph.
Минимальная обёртка, которую я ставлю в первый день проекта:
# FastAPI-обёртка над LangGraph для вызова из n8n
from fastapi import FastAPI
from pydantic import BaseModel
app_api = FastAPI()
class Request(BaseModel):
user_id: str
message: str
@app_api.post("/agent")
async def run_agent(req: Request):
config = {"configurable": {"thread_id": req.user_id}}
result = await app.ainvoke(
{"messages": [("user", req.message)]},
config
)
return {"reply": result["messages"][-1].content}
thread_id это ключ к чекпоинтеру. Передаёшь user_id из Telegram, и агент помнит весь предыдущий диалог без единой строчки про память на стороне n8n. В n8n остаётся HTTP Request нода с тремя полями.
Живой кейс с прошлого месяца. Клиент собирает лиды из пяти источников: два инстанса amoCRM, Hubspot, формы Tilda, входящие в Gmail и комменты в VK. n8n всё это ловит, нормализует в единую схему (имя, контакт, источник, сырой текст запроса), отправляет в /agent/qualify. LangGraph-агент квалификации делает три вещи: проверяет компанию через Dadata, тянет похожие сделки из истории по векторному поиску, формирует решение (hot/warm/cold + аргументация). Ответ возвращается в n8n, та раскладывает горячих в отдельную воронку с тегом, тёплых ставит в очередь на письмо, холодных архивирует.
Команда на это: один питонист, который пишет агентов и тесты к ним, и два автоматизатора, которые собирают флоу в n8n и подключают новые источники. Питонист не лезет в OAuth и вебхуки, автоматизаторы не пишут промпты и не трогают граф состояний. Конфликтов в гите нет, потому что и нет общего кода. Контракт между ними это JSON-схема запроса и ответа, зафиксированная в Pydantic-моделях.
Что важно на инфре. LangGraph-сервис ставлю отдельным контейнером, n8n отдельным, между ними внутренняя сеть. Таймаут на стороне n8n стоит выставлять с запасом: агенты с инструментами, особенно при нескольких последовательных tool calls, могут выполняться значительно дольше, чем обычные HTTP-запросы. И не забудь про идемпотентность: если n8n ретраит запрос, агент не должен второй раз отправлять письмо клиенту. Я обычно прокидываю idempotency_key из n8n и проверяю его в чекпоинтере перед запуском графа.
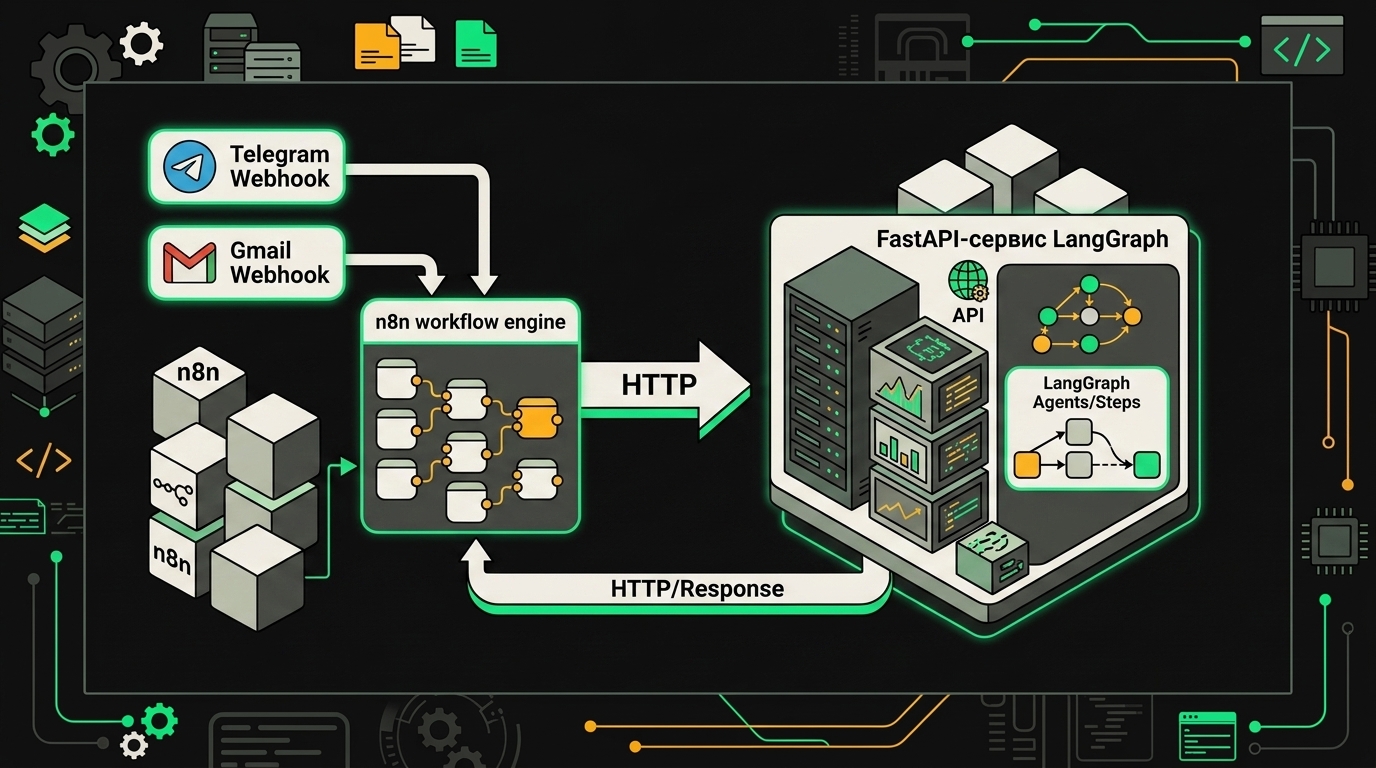
n8n берёт на себя интеграции и расписание, а сложную логику агента отдаёт в LangGraph через один HTTP-узел.
Матрица решений: что брать под конкретную задачу
Я выписал семь типовых сценариев и решения, к которым прихожу после двух десятков внедрений. Это не догма, но если ваш кейс попадает в один из них, начинайте отсюда.
Линейная автоматизация без LLM в цикле. ETL между Postgres и Snowflake, нотификации в Slack по вебхуку, синк сделок из HubSpot в Notion. Берите n8n и не думайте про LangGraph. Граф состояний тут паразитная сложность, а визуальный workflow читается продактом и саппортом без онбординга.
Чат-бот с одним LLM-вызовом и парой инструментов. Условный FAQ-бот, который иногда дёргает поиск по корпоративной базе знаний и создаёт тикет в Jira. n8n с AI Agent нодой закрывает это за вечер. LangChain под капотом там уже есть, переписывать на голый Python ради двух tool calls бессмысленно.
**Агент с 3+ инструментами, рефлексией и пам
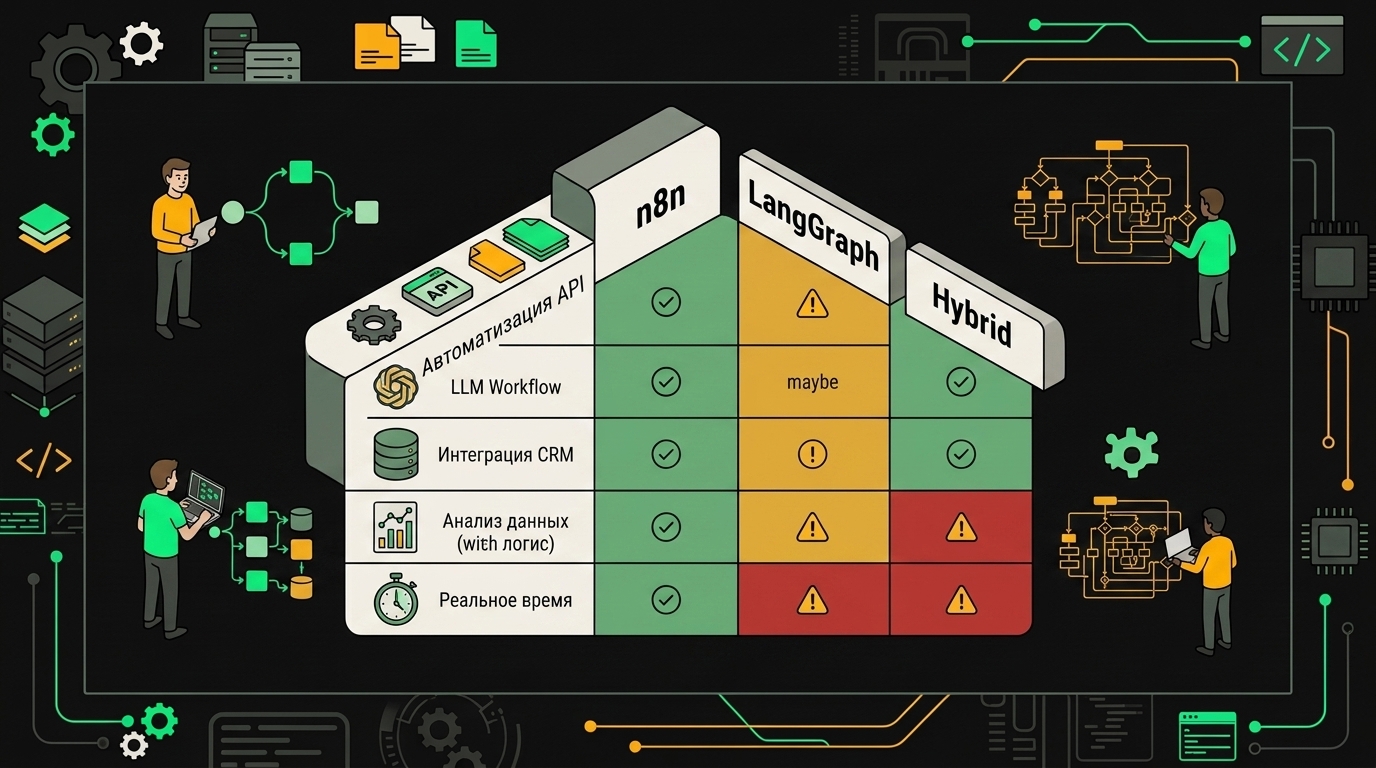
Матрица позволяет за 30 секунд определить, какой инструмент подходит под конкретный сценарий, не читая документацию обоих фреймворков.