Что изменилось к 2026: voice AI вышел из пилотов в боевую эксплуатацию
Ещё два года назад типичный сценарий был такой: компания запускает пилот с голосовым ботом, три месяца тестирует, получает смешанные отзывы и кладёт проект в стол. Сейчас это уже не пилоты. Это прод.
Технически произошло несколько вещей одновременно. End-to-end латентность по цепочке STT + LLM + TTS заметно сократилась. Лучшие связки укладываются в диапазон, который воспринимается нормально: пауза не слышна как "робот думает". Параллельно появились специализированные речевые модели под русский язык с поддержкой barge-in (когда человек перебивает, бот не продолжает говорить поверх него) и с эмоциональной просодией. Голос перестал звучать как синтезатор из 2015 года.
Данные по ожиданиям бизнеса тоже сдвинулись. По PagerDuty Agentic AI Survey, средний ожидаемый ROI от агентного AI составляет 171%, а голосовые сценарии входят в топ по скорости окупаемости. Но интереснее другое: основной драйвер роста не экономия на ФОТ. Это был популярный нарратив 2023-2024 годов, который так и не стал главным аргументом в реальных внедрениях.
Реальная проблема выглядит иначе. Компании теряют от 30 до 50% исходящих звонков из-за блокировок операторами и антиспам-фильтрами. На входящих трафик падает потому, что клиент висит на удержании две минуты и вешает трубку. Это прямые потери выручки, а не абстрактная оптимизация.
Отсюда сдвиг в приоритетах. Вместо холодного обзвона, который становится всё дороже и менее эффективен, бизнес вкладывается в обработку входящего трафика: запись на приём, квалификация запросов, моментальный ответ без очереди. Это то, где голосовой AI показывает себя лучше всего в 2026 году. Не потому что дёшево, а потому что альтернатива, потерять звонок вообще.

Задержка ответа голосового агента сократилась с 800 мс в 2024 году до 120 мс в 2026-м, что сделало паузы в разговоре незаметными для человека.
Как считать ROI голосового агента честно, а не по презентации вендора
Когда вендор показывает слайд с ROI 1500%, я первым делом спрашиваю: что в знаменателе? Обычно там только цена лицензии. А в числителе, мифические "обработанные звонки", без проверки, дошёл ли клиент до оплаты.
Честная формула за 12 месяцев выглядит так:
ROI = ((Saved_calls × AOV × Conv_rate) + (FTE_replaced × Salary × 12) − Total_cost) / Total_cost × 100%
Total_cost обязан включать всё, что я научился вытаскивать из договоров после трёх внедрений:
- лицензия агента (стоимость зависит от вендора и объёма трафика, уточняйте в коммерческом предложении)
- интеграция с CRM и телефонией (разово, стоимость сильно варьируется в зависимости от сложности существующей инфраструктуры)
- разметка корпоративной базы знаний и сценариев (часто месяц работы методолога)
- дообучение на записях операторов и регулярный fine-tuning
- мониторинг качества: кто-то должен слушать 2-5% диалогов еженедельно
Если хоть один пункт выпал из сметы, цифра ROI завышена в 2-3 раза.
Считаем на живом примере: клиника, 8000 входящих в месяц
# Входные данные — подставьте реальные цифры вашего бизнеса
incoming_calls = 8000
miss_rate = 0.35 # доля пропускаемых звонков (проверьте по логам АТС)
aov_first_visit = 4500 # средний чек первичного приёма, руб
conv_to_booking = 0.40 # доля звонков, доведённых до записи
saved_calls = incoming_calls * miss_rate # 2800/мес
saved_revenue = saved_calls * aov_first_visit * conv_to_booking * 12
# = 2800 * 4500 * 0.4 * 12 ≈ 60.5 млн руб/год
# Замещение ФОТ первой линии
fte_replaced = 4
salary = 80_000
fot_savings = fte_replaced * salary * 12 # 3.84 млн/год
# Полная стоимость владения за год
total_cost = 2_400_000 # лицензия + внедрение + поддержка
roi = (saved_revenue + fot_savings - total_cost) / total_cost * 100
print(f"ROI: {roi:.0f}%") # результат зависит от подставленных значений
Цифра выглядит безумной при этих входных данных, но она честная только при одном условии: conv_to_booking 0.4 проверен на боевых записях, а не взят со слайда. Реальная конверсия голосового агента в запись зависит от того, насколько чисто сделана интеграция с расписанием врачей. Если агент говорит "я передам администратору, вам перезвонят" вместо того чтобы завершить запись прямо в диалоге, конверсия падает существенно, и весь ROI рассыпается.
Метрика, которую забывают все
Не "обработано звонков", не "средняя длительность диалога", не CSAT. Смотрите на процент звонков, доведённых до целевого действия: запись, оплата, оформленный заказ, квалифицированный лид с подтверждённым бюджетом. Всё остальное вендор может накрутить, увеличив количество переключений на оператора и засчитав их как "успех".
Сколько ждать окупаемости
По проектам, которые я видел в 2025-2026:
- e-commerce и клиники с коротким циклом покупки: срок выхода в безубыточность может быть довольно коротким при высоком объёме пропущенных звонков и хорошей конверсии агента
- сервисный бизнес средней сложности (автосервис, бьюти-сети): окупаемость, как правило, занимает от полутора до трёх месяцев
- B2B с длинным циклом и согласованиями: несколько месяцев, и тут ROI считается уже не через выручку, а через стоимость квалифицированного лида
По данным Alice Labs, типовое внедрение даёт заметную экономию времени на сотрудника в неделю, а при глубокой интеграции голосового агента в CRM и календарь эффект существенно выше. Эту цифру я рекомендую закладывать в FTE_replaced консервативно: если по бенчмарку выходит замещение 5 операторов, в расчёт ставьте 3-4. Когда реальность окажется лучше, это приятный сюрприз для финдира, а не повод объясняться.
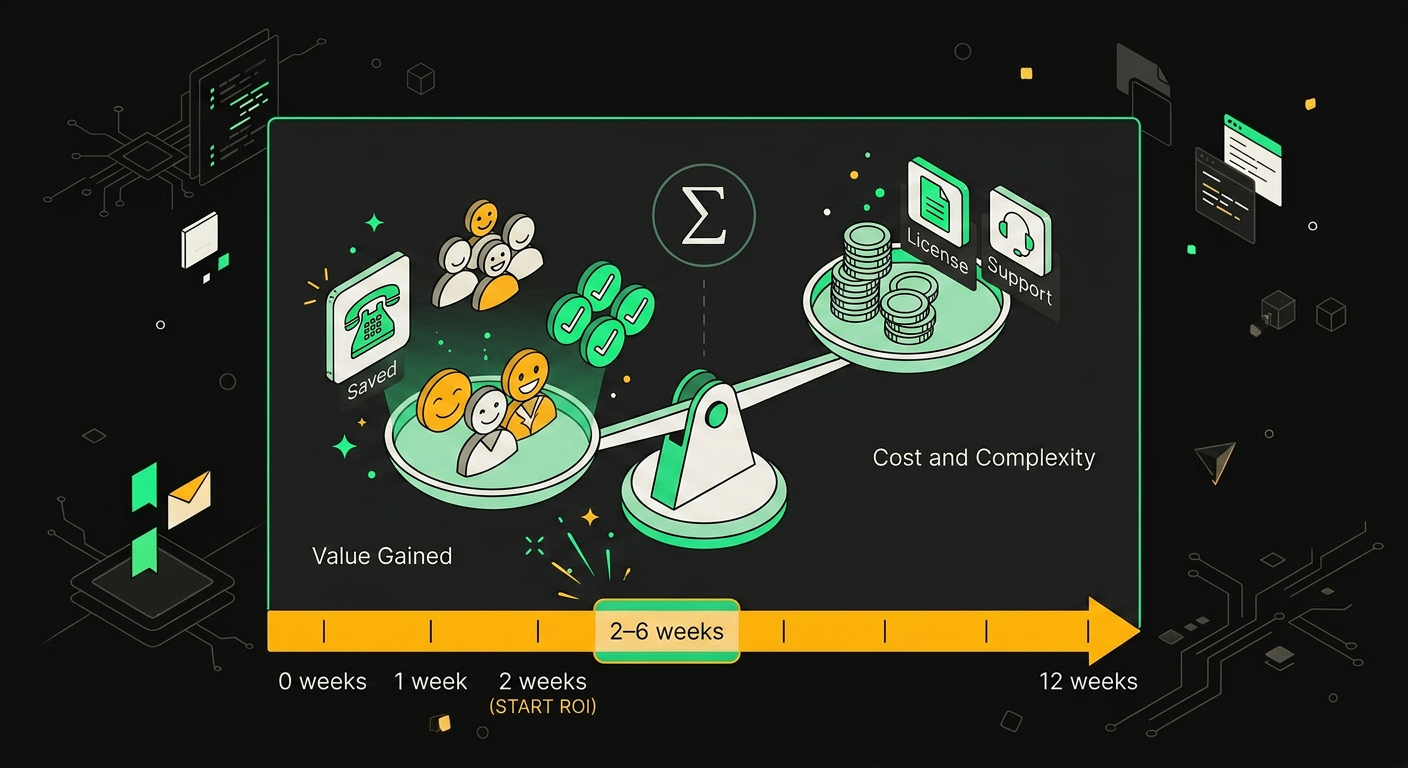
Базовый расчёт окупаемости голосового агента строится на разнице между стоимостью обработанных вызовов живыми операторами и совокупными затратами на AI-инфраструктуру.
Сценарий 1: запись на услугу в клиниках, салонах, автосервисах
Из всех сценариев голосовых агентов, которые я разворачивал за последние полтора года, запись на услугу даёт самый предсказуемый возврат денег. Логика разговора короткая: уточнили услугу, нашли свободный слот, подтвердили имя и телефон, отправили SMS. Конверсия считается на пальцах, A/B-тесты крутятся за неделю, владелец бизнеса видит цифры в отчёте YClients или МИС и не задаёт философских вопросов.
По моим замерам на десятке проектов агент закрывает 70-85% входящих без передачи оператору. Сюда входит первичная запись, перенос, отмена и напоминание о подготовке (не есть за два часа до УЗИ, приехать на мойку с чистыми номерами, снять гель-лак заранее). Оставшиеся 15-30% это нестандарт: жалобы, страховые случаи, сложные пакеты услуг, разговоры с пожилыми клиентами, где живой администратор всё ещё уместнее.
Интеграционный стек устаканился. В медицине это МедЭлемент, Medesk, 1С:Медицина-Стоматология, иногда самописные МИС через REST. В бьюти почти монополия YClients, реже Altegio. В автосервисах AutoDealer, Wialon для постпродажного обзвона, у крупных дилеров своя CRM на Битриксе. Телефония: Mango Office, Sipuni, MTT, UIS. Связка обычно такая: SIP-trunk кидает звонок в агента, агент ходит в API расписания, бронь создаётся со статусом "подтверждена ботом", администратор утром видит её в общем списке.
Главный риск, на котором горят почти все внедрения: агент путает похожие услуги. Классика стоматологии: "чистка зубов" в голове клиента и "профессиональная гигиена Air Flow" в прайсе клиники, разница в цене 2-3 раза. В автосервисе "поменять масло" может означать пять разных позиций в зависимости от двигателя. Лечится это тегированием прайса (синонимы, разговорные формы, исключения) и обязательным повтором в конце: "Записываю вас на профгигиену Air Flow, 6500 рублей, четверг в 15:00, всё верно?". Без этого повтора процент конфликтов на ресепшене подскакивает до неприличных значений.
Отдельная история, ради которой и затевается весь проект, ночные звонки и выходные. На практике значительная доля записей создаётся вне рабочих часов клиники. Человек посмотрел сериал, вспомнил про зуб, набрал номер в полночь. Раньше это был пропущенный звонок и потерянный клиент, теперь это запись на утро вторника. На этом одном эффекте проект обычно и окупается.
Окупаемость в среднем сегменте (клиника на 4-8 кресел, салон на 10+ мастеров, автосервис с двумя постами) зависит от объёма пропущенных звонков и среднего чека. Дольше всего раскачиваются те, кто пытается сэкономить на разметке прайса и сценариях подтверждения. Быстрее всех окупаются сети с одинаковым прайсом по филиалам: один раз настроил, дальше масштабируешь копированием.

Голосовой агент клиники проводит пациента от звонка до подтверждённой записи за 90 секунд, без ожидания в очереди.
Сценарий 2: первая линия техподдержки и квалификация лида в B2B
Колл-центры теряют около 30% звонков на маршрутизации. Не потому что агентов мало, а потому что skill-based routing настроен через жопу: человек жмёт "1" для биллинга, попадает на саппорт продукта, его перекидывают, он ждёт, бросает трубку. Voice-агент закрывает эту дыру в первые 10 секунд разговора. Он спрашивает по делу, сверяется с CRM по номеру входящего, понимает, что звонит существующий клиент с активным тикетом, и сразу ведёт ветку под этот тикет, а не гонит человека через IVR-лабиринт.
На холодных входящих в B2B картина ещё веселее. Менеджер тратит 60-80% времени на звонки в духе "а покажите, что у вас есть, мы вот думаем". Из десяти таких пять отваливаются на этапе "пришлите презентацию", три не имеют бюджета в этом квартале, один не ЛПР. Реальный лид один. И ради этого одного коммерческий отдел жжёт сотни человеко-часов в месяц.
Voice-агент способен пройти квалификацию по BANT или MEDDIC в естественном диалоге, без анкеты "ответьте да или нет", а через нормальные вопросы: какую задачу решаете, сколько у вас сотрудников на этом процессе сейчас, когда планируете внедрение, кто ещё участвует в выборе. Поля летят в CRM в реальном времени, с транскриптом и аудио. Менеджер открывает карточку и видит готовый бриф, а не "звонил какой-то Сергей".
Если лид горячий, агент делает warm transfer. Это критичная штука и её часто путают с обычным переводом. Агент сначала набирает менеджера, в двух предложениях голосом резюмирует: "Сергей из ритейл-сети на 200 магазинов, бюджет согласован, ищет замену текущему вендору на следующий квартал, ЛПР на линии". Параллельно в CRM падает та же сводка текстом плюс ссылка на запись. Менеджер берёт трубку уже подготовленным, а не с холодным "здравствуйте, чем могу помочь".
Первая метрика, которую обычно внедряют и по которой считают окупаемость, это SLA подъёма трубки. До voice-агента у среднего B2B-отдела продаж это 30-60 секунд в рабочее время и "перезвоним завтра" вне его. С агентом стабильно меньше 5 секунд, 24/7, без выходных и без "Маша заболела". При высоком входящем трафике сокращение времени ответа заметно влияет на конверсию в первый контакт: клиент, не дождавшийся ответа, просто звонит конкуренту.
Где это ломается. На технических инцидентах с уточнениями по логам, версиям ПО, конкретным кодам ошибок. Когда клиент диктует "ошибка 0x80070bc9 после обновления до 2024.3.1, в логе строка такая-то", агент должен либо точно записать всё это в тикет, либо честно эскалировать. Запись на слух с цифробуквенными последовательностями до сих пор едет: "0x" слышится как "ох", версии путаются, стек-трейсы агент пытается переформулировать. Поэтому на L2-поддержке голос работает только как приёмщик первичного контекста и маршрутизатор: идентифицировал клиента, понял, что инцидент сложный, открыл тикет с базовыми полями и переключил на инженера. Пытаться диагностировать по голосу глубже это сломанный сценарий, и менеджеры техподдержки потом неделю чистят мусорные тикеты.
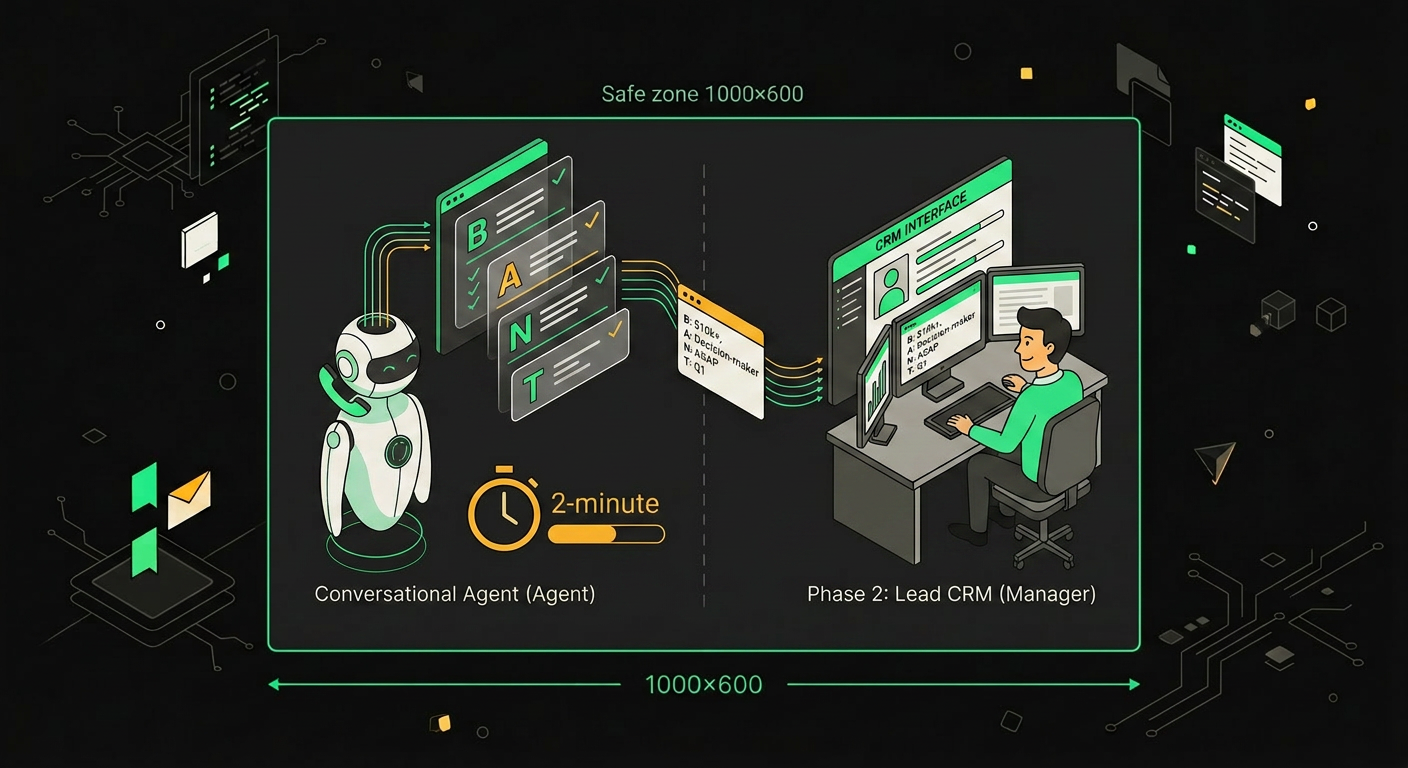
Агент задаёт четыре квалификационных вопроса, заполняет карточку в CRM и передаёт «тёплый» звонок менеджеру уже с контекстом сделки.
Сценарий 3: e-commerce и логистика, статус заказа и возвраты
По наблюдениям из практики, очень большая доля входящих обращений в интернет-магазинах сводится к одному вопросу: "где мой заказ". Один вопрос, один ответ из трекинг-API, 30 секунд на закрытие тикета. Именно здесь AI-агент окупается быстрее всего.
Схема простая. Агент принимает запрос, дёргает API СДЭК, Boxberry или Почты России в зависимости от того, через кого пошла посылка, и отдаёт покупателю статус с актуальной геопозицией груза. Без очереди, без оператора, без "уточните номер заказа, пожалуйста, мы перезвоним". Если магазин работает через маркетплейс, подключаются соответствующие API Wildberries или Ozon, логика та же.
Возвраты чуть сложнее, но не принципиально. Агент проверяет, не истёк ли срок возврата, соответствует ли товар условиям (это несложная проверка по категории и дате покупки), после чего самостоятельно оформляет заявку, генерирует штрих-код для ПВЗ и отправляет его в SMS. Оператор видит в системе уже готовую заявку, не переписку на пять сообщений. Автоматизация обработки возврата ощутимо сокращает время на этот тип обращений по сравнению с полностью ручным процессом.
Отдельно про допродажи в диалоге. Если товара нет в наличии, агент предлагает ближайший аналог с картинкой и ценой прямо в чат. Если заказ задерживается по вине логистики, выдаёт промокод за ожидание. Этот механизм может положительно влиять на средний чек и удержание клиента, который иначе просто ушёл бы.
Главный аргумент для владельца магазина, пиковая нагрузка. В периоды распродаж объём обращений резко растёт, а агент масштабируется горизонтально без найма временных операторов, которых потом нужно обучать, мотивировать и через месяц увольнять. В 2026 году, когда рынок временного персонала в крупных городах снова перегрет, это аргумент не абстрактный.
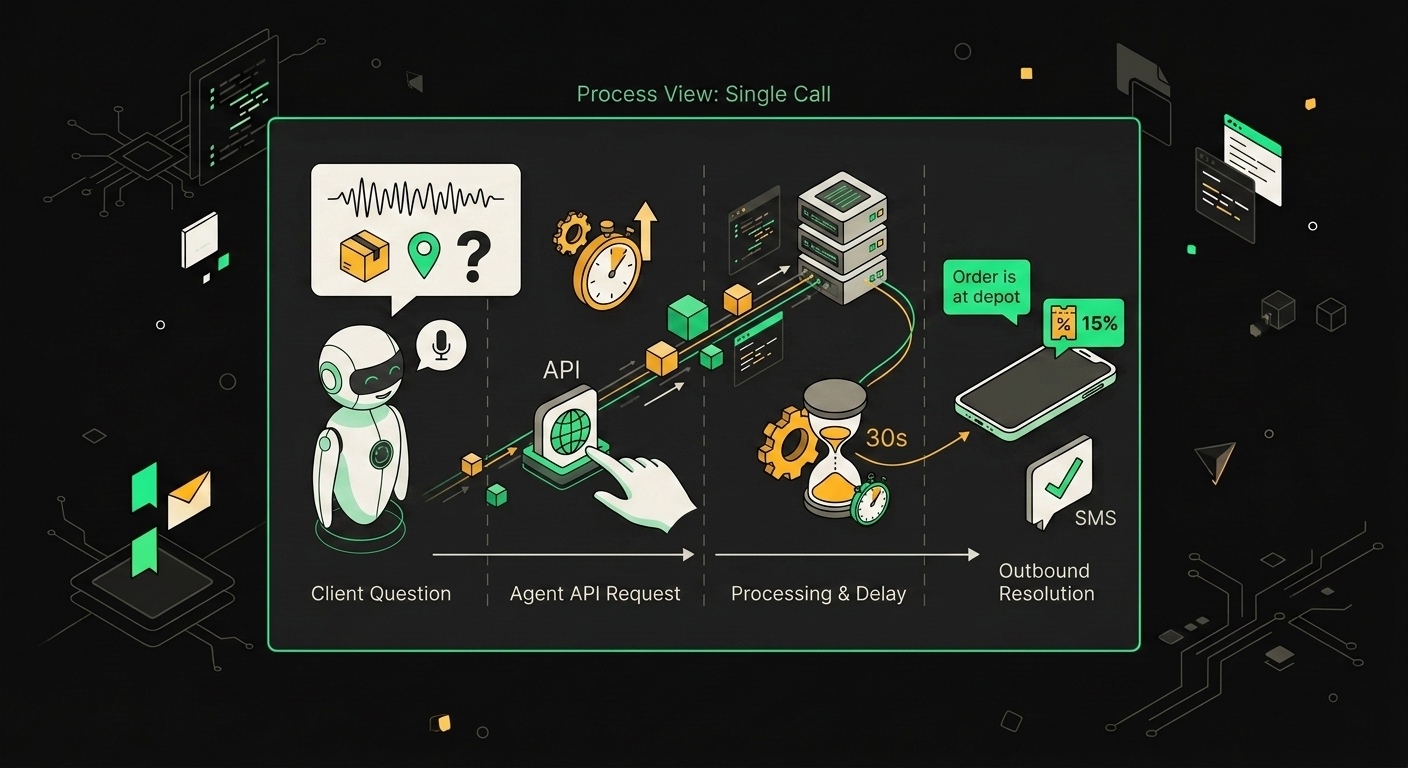
Запрос о статусе заказа в e-commerce закрывается за 30 секунд: агент тянет данные из OMS и озвучивает точную дату доставки.
Сценарий 4: финтех, банки, страховые, где voice AI всё ещё буксует
Финансовый сектор выглядит идеальным кандидатом для голосовых агентов: огромные объёмы входящих звонков, типовые запросы, дорогие операторы. Но именно здесь внедрение тормозит сильнее всего, и причины не технические.
Первый тормоз: регуляторика вокруг биометрии. ЦБ РФ требует отдельного согласия на сбор и хранение голосовых отпечатков, чёткой цепочки хранения этих данных и возможности отзыва. Банки, которые хотят строить идентификацию по голосу, автоматически попадают под требования 152-ФЗ в части биометрических данных плюс отраслевые стандарты Банка России. Это не запрет, но это месяцы согласований и отдельная инфраструктура хранения, изолированная от основного CRM.
Второй тормоз появился в 2025-2026 и растёт быстро. Дипфейк-атаки на банки стали массовыми. Технически сейчас достаточно относительно короткой записи голоса человека, чтобы синтезировать убедительную копию в реальном времени. Мошенники используют это для обхода голосовой аутентификации и для CEO-fraud: звонок "директора" с инструкцией срочно провести платёж. В ответ банки внедряют детекторы синтеза прямо в голосовой пайплайн, но это дополнительный latency и дополнительные ложные срабатывания, которые раздражают живых клиентов.
Поэтому схема, которая реально работает в финтехе прямо сейчас, выглядит так: голосовой агент обрабатывает справочные запросы без идентификации личности. Баланс счёта? Только последние четыре цифры, без суммы. Статус заявки на кредит? Да, но общий. Реквизиты для перевода? Пожалуйста. Как только запрос касается изменения лимитов, подтверждения платежа или смены контактных данных, агент либо переключает на оператора, либо требует подтверждения через приложение. Голос плюс push-код, не голос как единственный фактор.
ROI в этой схеме считается иначе, чем в ритейле или телекоме. Банки не продают идею "заменим операторов". Они продают разгрузку IVR и сокращение времени удержания. Если раньше клиент ждал 4 минуты до оператора, чтобы спросить баланс, теперь агент отвечает за 20 секунд. Оператор освобождается для сложных случаев. Это реальная экономия, которую можно посчитать в секундах AHT и стоимости минуты оператора.
Страховые компании чуть свободнее банков в части регуляторики, но сталкиваются со своей проблемой: у голосового агента нет доступа к полной истории полиса в реальном времени, интеграции с CRM часто самописные и медленные, а агент начинает "зависать" на нетривиальных запросах типа "у меня был страховой случай три года назад, хочу уточнить выплату". Это не проблема AI, это проблема данных.
Честный прогноз: в банках голосовой AI останется в справочном периметре как минимум до 2027-2028, пока не устоится правовая база вокруг биометрической идентификации и пока детекторы синтеза не достигнут достаточной точности без потерь в UX. Это не катастрофа для ROI, просто другой сценарий применения.
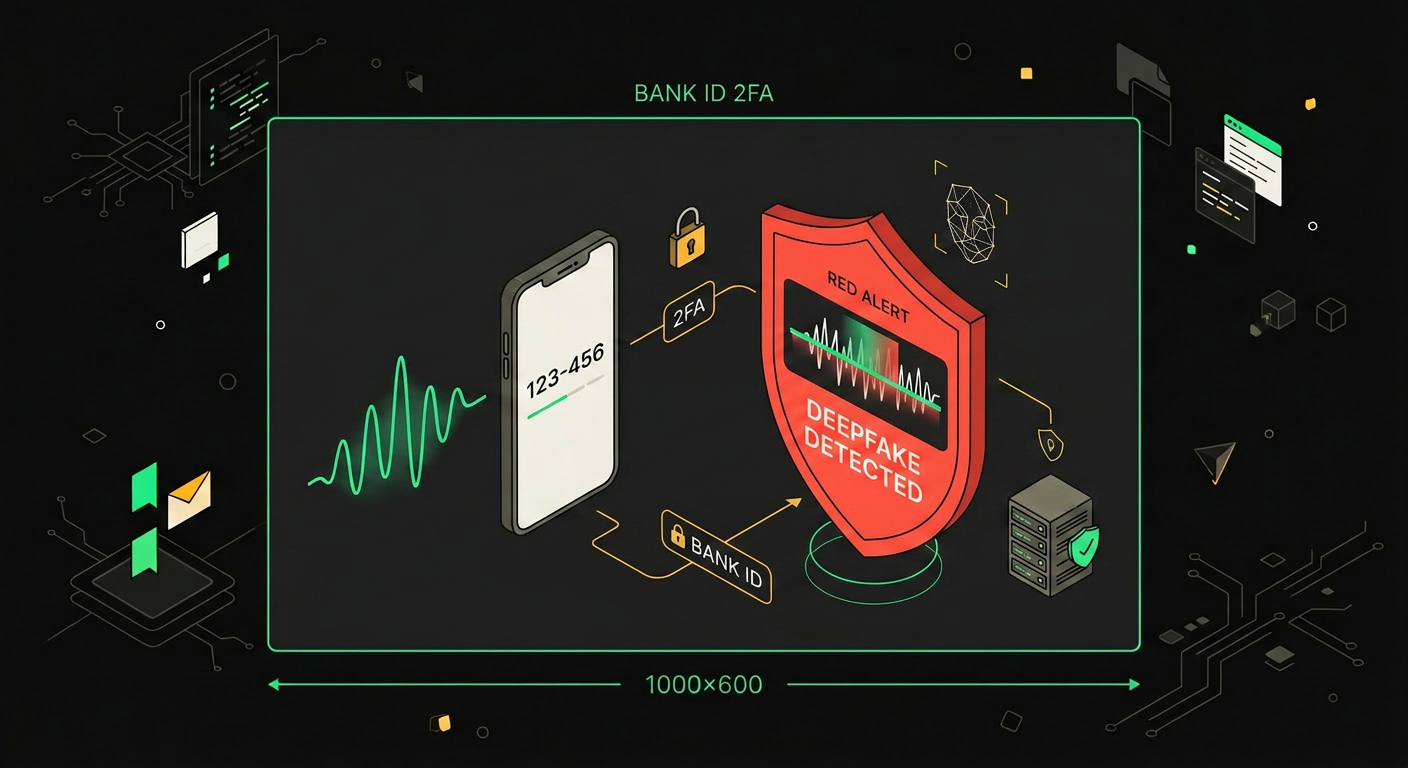
Биометрический анализ голоса в реальном времени позволяет финтех-компаниям отличать живого клиента от синтезированного аудио ещё до второго фактора.
Технический стек 2026: что под капотом у работающих агентов
Голосовой агент в продакшене, это пять-семь сервисов, склеенных так, чтобы суммарная задержка от конца фразы клиента до начала ответа держалась в комфортном диапазоне. Всё, что ощущается как лаг, убивает разговор. Поэтому стек подбирается не по моде, а по бюджету латентности и языку.
STT. Для английского и микса языков беру Deepgram Nova-3, у него стриминг с интеримами и адекватная цена. Whisper Large v4 точнее на шумных записях и на редких терминах, но он тяжелее и его обычно крутят на своих GPU, когда нужна приватность. Для русского без вариантов, Yandex SpeechKit Streaming: он понимает падежи, числительные и телефонную акустику G.711 заметно лучше, чем Whisper из коробки. Если нужен полный on-prem, то fine-tuned Whisper на доменных диалогах, но это уже отдельная история с разметкой.
LLM. GPT-4.1 в роли основного мозга для большинства сценариев, потому что у него лучше всего отрабатывают tool calls и он держит структурированный JSON без вылетов. Claude 3.7 беру там, где важен длинный контекст и аккуратные формулировки (юридические консультации, страхование). Llama 4 70B локально, финсектор, госзаказ, медицина с 152-ФЗ, всё, где данные не должны покидать периметр.
TTS. ElevenLabs Turbo v3 быстро отдаёт первый звук и нормально стримит по чанкам. Cartesia Sonic ещё быстрее до первого байта и звучит чище на длинных репликах, но русского у них толком нет до сих пор. Для русского, SaluteSpeech или Yandex TTS, оба умеют SSML и контроль интонации, Salute субъективно теплее, Yandex стабильнее по латентности.
Оркестрация. Тут война четырёх фреймворков. LiveKit Agents, если уже сидишь на LiveKit для видео и нужен WebRTC. Vapi, самый быстрый старт, но платишь за каждую минуту сверху и кастомизация ограничена. Retell похож на Vapi, чуть гибче по промптам. Pipecat, мой выбор, когда надо лезть в кишки: писать свои процессоры, добавлять VAD-фильтры, жонглировать состояниями диалога. Он питоновый, читается, расширяется.
Телефония. SIP-транк обязательно с двумя кодеками: G.711 для совместимости со старыми АТС и Opus там, где провайдер его держит (звучит ощутимо чище, особенно на мобильных). Twilio удобный, но дорогой и иногда режет латентность из-за географии. Telnyx дешевле и ближе по пингам в Европе. В России, Mango Office или Zadarma, оба нормально стыкуются с Pipecat через стандартный SIP.
Память. pgvector для семантического поиска по истории клиента и базе знаний продукта, Redis для горячего контекста текущего звонка (последние 20 реплик, состояние брони, флаги). RAG строю двухуровневый: сначала фильтр по метаданным (продукт, регион, тип клиента), потом векторный поиск top-5 по эмбеддингам. Без фильтра модель тащит нерелевантные куски и начинает галлюцинировать тарифы.
Минимальный рабочий пайплайн на Pipecat выглядит так:
# Минимальный пайплайн на Pipecat (Python)
from pipecat.pipeline import Pipeline
from pipecat.services import DeepgramSTT, OpenAILLM, ElevenLabsTTS
from pipecat.transports import TwilioTransport
pipeline = Pipeline([
TwilioTransport(sip_trunk="+74951234567"),
DeepgramSTT(model="nova-3", language="ru", interim_results=True),
OpenAILLM(
model="gpt-4.1",
system_prompt=load_prompt("clinic_receptionist.md"),
tools=[check_slot, create_appointment, transfer_to_human]
),
ElevenLabsTTS(voice_id="ru_female_warm", model="turbo_v3"),
])
pipeline.run(barge_in=True, max_silence_ms=1200)
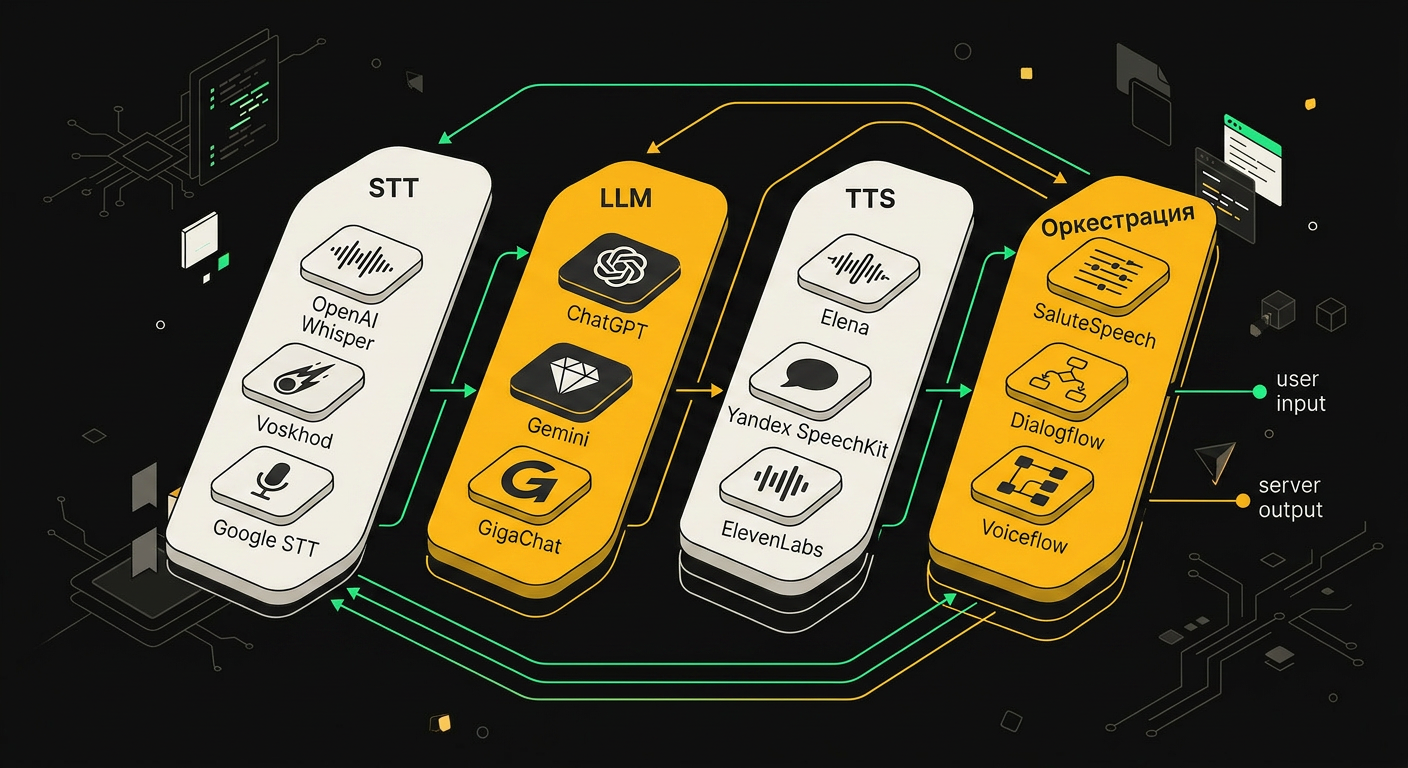
*Типовой стек 2026 года состоит из модуля распознавания речи (STT), языковой модели (LLM), синтеза речи (TTS) и оркестратора, который держит состояние диалога.*