Зачем продажам AI-агент в 2026 году
Скорость ответа на заявку влияет на конверсию сильнее, чем большинство других факторов воронки. Исследования InsideSales фиксировали десятикратные и большие разрывы между ответом в первые минуты и ответом через час, хотя точные коэффициенты варьируются по отраслям. В 2026-м это больнее: конкуренты реагируют быстрее, клиент успевает оставить заявку в трёх местах.
Теперь посмотри на своих менеджеров. Значительная доля заявок приходит после 18:00 или в выходные. CRM это фиксирует, но никто не звонит. Утром менеджер видит очередь из 12 лидов, часть уже остыла, часть ушла к конкурентам. Это не проблема найма или мотивации. Это структурная дыра.
Раньше затыкали её чат-ботами. Условный Dialogflow с деревом вопросов: "Вы хотите купить? Нажмите 1." Клиент написал что-то нестандартное, и бот упёрся в тупик. Таких ботов люди ненавидят. Они снижают доверие к бренду, а не поднимают конверсию.
AI-агент работает иначе. Это языковая модель с доступом к инструментам: она может проверить наличие товара в базе, записать данные в CRM, отправить письмо, поставить задачу менеджеру, задать уточняющий вопрос и запомнить ответ. Tool calling плюс persistent memory. Агент не читает скрипт, он ведёт разговор с целью: квалифицировать лида и передать его дальше с уже заполненными полями.
К началу 2026-го сборка таких агентов перестала быть уделом больших команд разработки. В n8n появились нативные узлы LangChain. GPT-4o-mini и Claude Haiku подешевели настолько, что обработка одного лида обходится в доли цента. Guardrails стали стабильнее: модели значительно реже уходят в галлюцинации на задачах с конкретным контекстом и системным промптом.
Что это даёт на практике? Проекты, которые я видел внедрёнными в этом году, показывают рост конверсии MQL в SQL и сокращение времени на первичную квалификацию лида. Конкретные цифры сильно зависят от продукта, канала и качества трафика. Остаток времени менеджера уходит на то, что агент не умеет: эмпатию, нестандартную сделку, живое давление.
Это не замена продавца. Это фильтр и ускоритель до первого живого контакта.
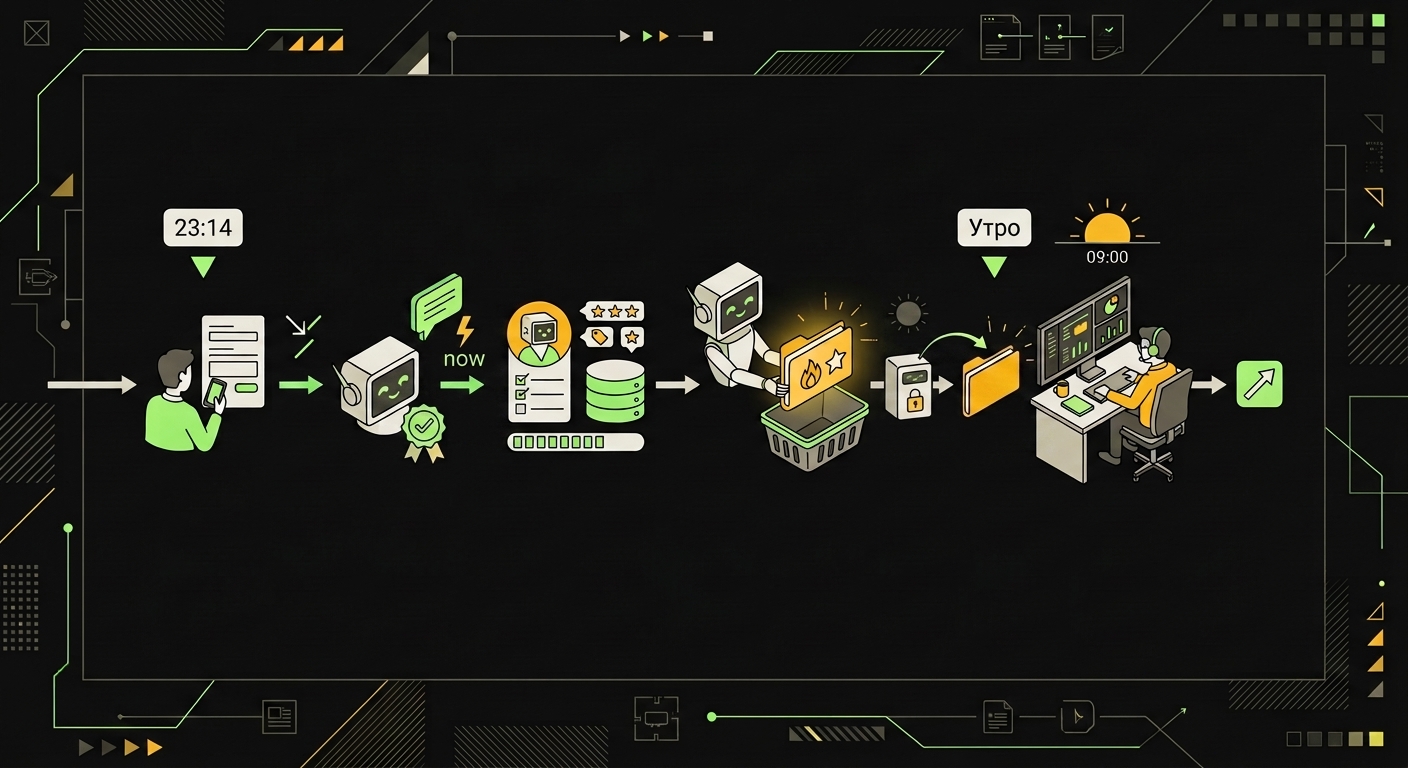
Лид проходит путь от первого сообщения до горячей передачи менеджеру за 3-7 минут без участия человека.
Архитектура агента: что под капотом
В основе лежит LLM. В 2026 году это GPT-4o, Claude Sonnet 4 или Llama 3.3 для self-hosted-развёртываний, где данные не должны покидать периметр. Выбор модели влияет и на качество ответов, и на задержку: локальный деплой на GPU обычно быстрее облачных вызовов при прочих равных, но реальные цифры зависят от железа, размера модели и нагрузки.
Память делится на два уровня. Краткосрочная живёт прямо в контексте диалога: агент держит последние N сообщений и помнит, что лид уже назвал свой бюджет или отказался от демо на следующей неделе. Долгосрочная хранится в Postgres или Redis с привязкой к contact_id. Когда тот же человек пишет через три дня с другого канала, агент вытаскивает его историю и не начинает разговор с нуля. Это одно из немногих мест, где клиенты реально замечают разницу между ботом и нормальным инструментом.
Инструменты (в терминологии OpenAI function calling, просто tools) определяют, что агент вообще может делать. Минимальный набор для лидогенерации: поиск по базе знаний через векторный индекс, проверка календаря менеджера через Calendly или Google Calendar API, запись данных в CRM (HubSpot, Salesforce, Pipedrive, неважно, главное webhook или нативный коннектор) и передача диалога живому человеку с полным контекстом. Без последнего инструмента агент превращается в тупик: лид ждёт, менеджер не знает, сделка теряется.
Слой квалификации лида оформляют по-разному. Самый чистый вариант: отдельный LLM-judge, который после каждого сообщения оценивает заполненность полей BANT или MEDDIC и возвращает структурированный JSON с текущим скором. Этот JSON пишется в CRM и тригерит следующий шаг воронки. Можно упростить до отдельного промпта внутри того же агента, но тогда логику сложнее тестировать и отлаживать.
Оркестрация сборки чаще всего падает на n8n. Типовая схема: узел Chat Trigger принимает входящее сообщение (WhatsApp, Telegram, веб-чат), передаёт в узел AI Agent с конфигурацией системного промпта и списком tools, агент при необходимости идёт в векторный store (Qdrant или Pinecone) за релевантными кусками документации, потом выполняет нужный tool и возвращает ответ обратно в Chat Trigger. Время одного цикла зависит от задержек внешних API и размера модели.
Узкое место здесь обычно не модель. Это задержки при обращении к внешним API: CRM, календарь, векторная база. Кэш на уровне Redis для частых запросов к базе знаний срезает половину этих задержек без изменения архитектуры.
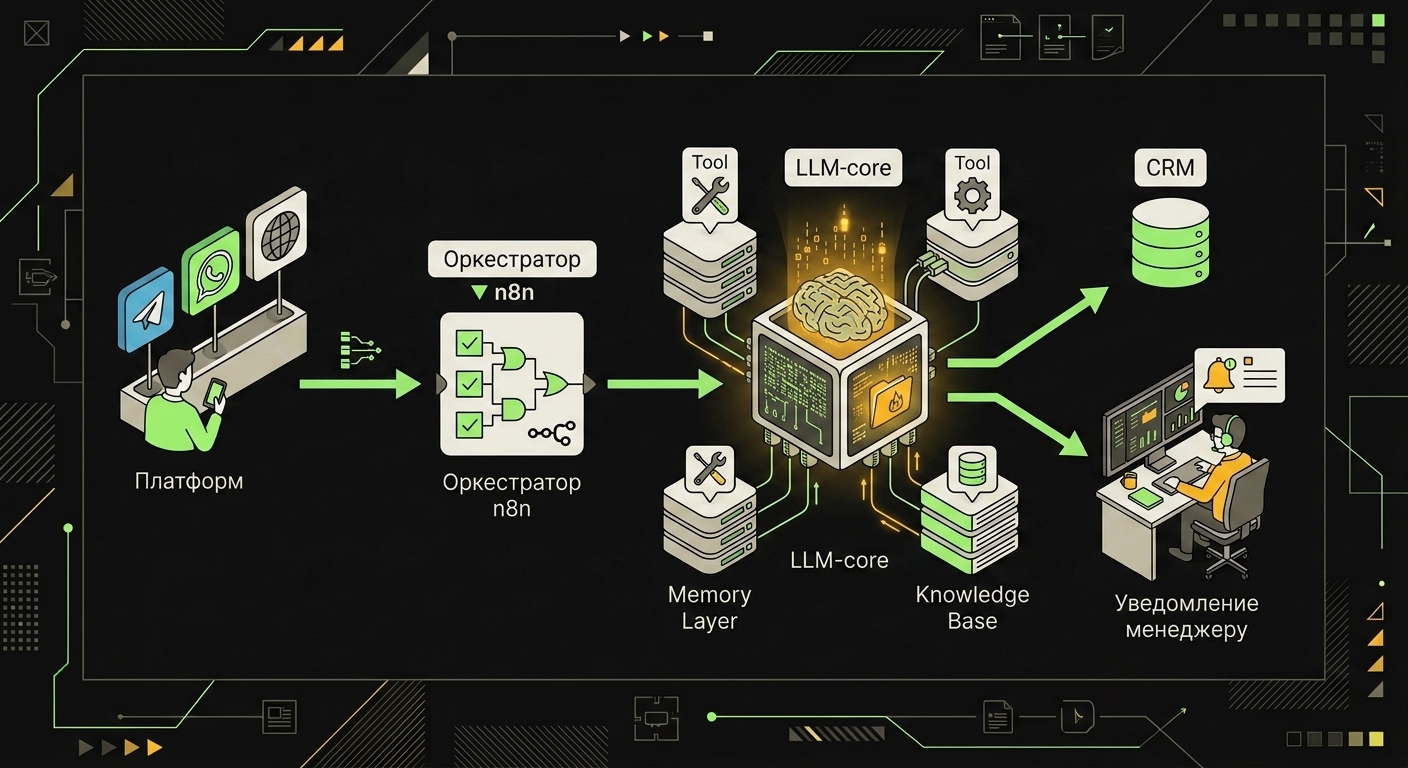
Ядро агента, языковая модель, подключённая к CRM, календарю и базе знаний через слой инструментов.
Квалификация лидов: BANT, MEDDIC и их адаптация под диалог
BANT придумали в IBM ещё в 60-х: Budget, Authority, Need, Timeline. Четыре вопроса, на которые продавец должен ответить до того, как тратить время на демо. Бюджет есть? С тем человеком говорим? Боль реальная? Купят в обозримом горизонте? Каркас простой настолько, что я видел десятки попыток его "усовершенствовать", и все они скатывались обратно к этим четырём буквам.
LLM-агент квалифицирует иначе, чем человек с чек-листом. Менеджер на холодном звонке часто прёт по скрипту: "Какой у вас бюджет? А кто принимает решение? А когда планируете внедрять?". Лид закрывается через две минуты. Агент так делать не должен и, что важнее, технически не обязан, потому что каждое сообщение он генерирует с учётом всего контекста, а не пункта в анкете.
Принцип такой: квалифицирующие вопросы вплетаются в разговор о задаче. Клиент пишет "у нас аналитика разбросана по трём сервисам, хочу собрать в одном месте". Плохой агент отвечает: "Понял! Какой у вас бюджет на решение?". Хороший: "Знакомая боль, особенно когда атрибуция событий разъезжается между источниками. А какой объём данных гоняете в месяц и сколько человек в команде с этим работает?". Второй вопрос одновременно достаёт сигнал по бюджету (объём = размер тарифа) и по authority (один аналитик или отдел из 15).
Лучше задавать не больше 2-3 вопросов за одно сообщение. По наблюдениям на реальных чатах, слишком длинные сообщения с несколькими вопросами подряд снижают вероятность ответа: клиент либо отвечает только на часть, либо не отвечает вовсе.
Скоринг я обычно делаю прямо в JSON-ответе модели. Каждый критерий 0-2 балла: 0, нет сигнала или негатив, 1, косвенный сигнал, 2, прямое подтверждение. Сумма по четырём критериям, порог 6 из 8 для перевода в SQL.
// Системный промпт для квалификации
const systemPrompt = `Ты — ассистент отдела продаж SaaS-сервиса аналитики.
Твоя задача: понять задачу клиента и квалифицировать по BANT.
Правила:
- Не задавай больше 2 вопросов за сообщение
- Сначала прояви эмпатию к проблеме, потом уточняй
- Бюджет спрашивай косвенно: "какой объём данных обрабатываете"
- Если лид готов (score >= 6), вызови tool transfer_to_manager
Формат ответа:
{
"reply": "текст клиенту",
"bant_score": {"B": 0-2, "A": 0-2, "N": 0-2, "T": 0-2},
"action": "continue | transfer | book_demo"
}`;
Score хранится между ходами в памяти диалога и обновляется инкрементально: модель видит предыдущие баллы и либо подтверждает их, либо повышает на основании нового ответа. Понижать не даю, иначе агент начинает дёргаться от шумных формулировок клиента.
Для enterprise-сделок BANT куцый. Там работает MEDDIC: Metrics (какие KPI клиент хочет сдвинуть в цифрах), Economic buyer (кто реально подписывает счёт, не путать с инициатором), Decision criteria (по каким критериям выбирают вендора), Decision process (через какие согласования пройдёт сделка), Identify pain (конкретная боль, а не "хотим автоматизации"), Champion (внутренний союзник, который продаёт нас внутри компании). Шесть полей вместо четырёх, и каждое тяжелее достать через чат, потому что Economic buyer и Champion почти никогда не пишут в виджет на сайте. Агент их выявляет косвенно: "вы планируете показывать решение коллегам перед демо?" вытаскивает Champion, "согласование закупок у вас через финдир или внутри отдела?" подсвечивает Decision process.
Антипаттерн, который ловлю в логах чаще всего, я называю "робот-допросчик". Агент игнорирует контент сообщения клиента и долбит следующим квалифицирующим вопросом из списка. Лечится одним правилом в промпте: перед вопросом обязательна реакция на сказанное лидом, минимум одно предложение по сути. Если модель этого не делает, добавляю в few-shot два-три примера правильных ответов и один пример с пометкой "так не отвечай". Работает надёжнее, чем десять строк инструкций. Подробнее о том, как проектировать промпты и память для AI-агента поддержки клиентов, разобрано отдельно.
Плохой вариант задаёт все четыре вопроса подряд, хороший встраивает их в естественный разговор.
Сборка агента в n8n: пошагово
Начинаю всегда с триггера. В большинстве проектов это webhook: Telegram Bot API кидает апдейты на /webhook/tg-incoming, WhatsApp Business Cloud API через Meta шлёт на отдельный путь с верификацией токена, виджет на сайте бьёт fetch-запросом с фронта. Один воркфлоу на канал, дальше всё сходится в общий sub-workflow с самим агентом, чтобы не плодить копии логики.
Дальше центральный узел: AI Agent (Tools Agent в n8n 1.6x). Цепляю к нему OpenAI Chat Model с gpt-4.1-mini для боевого трафика и gpt-4.1 на эскалациях, либо Anthropic с claude-sonnet-4, если клиенту критична длина контекста и аккуратность с русским. К агенту обязательно подключаю Window Buffer Memory с окном 10-15 сообщений и ключом сессии chat_id или phone, иначе он забывает имя клиента через два хода.
Tools подключаются как отдельные ноды-инструменты, агент сам решает, какой дёрнуть. У меня типовой набор такой:
- HTTP Request Tool к amoCRM (
/api/v4/leads) или Bitrix24 (crm.lead.add.json) для создания и обновления сделок. Токен в credentials, не в теле ноды. - Google Calendar Tool для чтения занятых слотов менеджера через
freebusy.query. - Vector Store Tool (Qdrant или встроенный Supabase) с базой FAQ, чанки по 400-600 токенов, поиск top-3.
- Кастомный tool на проверку календаря через Code-ноду, если логика подбора слота сложнее, чем просто freebusy.
Описание инструмента агенту даётся в формате JSON Schema. Вот реальный пример из проекта для стоматологии, агент вызывает его перед предложением времени:
// Пример tool definition в n8n AI Agent
{
"name": "check_manager_availability",
"description": "Проверяет свободные слоты менеджера на ближайшие 3 дня",
"parameters": {
"type": "object",
"properties": {
"manager_id": {"type": "string"},
"timezone": {"type": "string", "default": "Europe/Moscow"}
},
"required": ["manager_id"]
}
}
После агента ставлю узел Switch. Агент возвращает структурированный ответ с полем action: reply, transfer, book, escalate. Switch разводит на ветки. transfer уходит в ноду уведомления в общий чат отдела (Telegram-группа менеджеров) плюс пометка тега ai_handoff в CRM. book создаёт событие в календаре и сделку. reply просто отдаёт текст обратно в канал.
Логирование. Каждый ход диалога пишу в Postgres, таблица dialog_turns: session_id, user_message, agent_response, tools_called (jsonb), latency_ms, model, tokens_in, tokens_out, created_at. По этой таблице потом гоняю еженедельную оценку качества: сэмплирую несколько десятков диалогов, прогоняю через судью на gpt-4.1 с рубрикой (релевантность, тон, корректность вызова инструментов), смотрю, где агент галлюцинирует или зря дёргает CRM. Без этого слоя через месяц не понять, почему конверсия в запись просела с 31% до 22%.
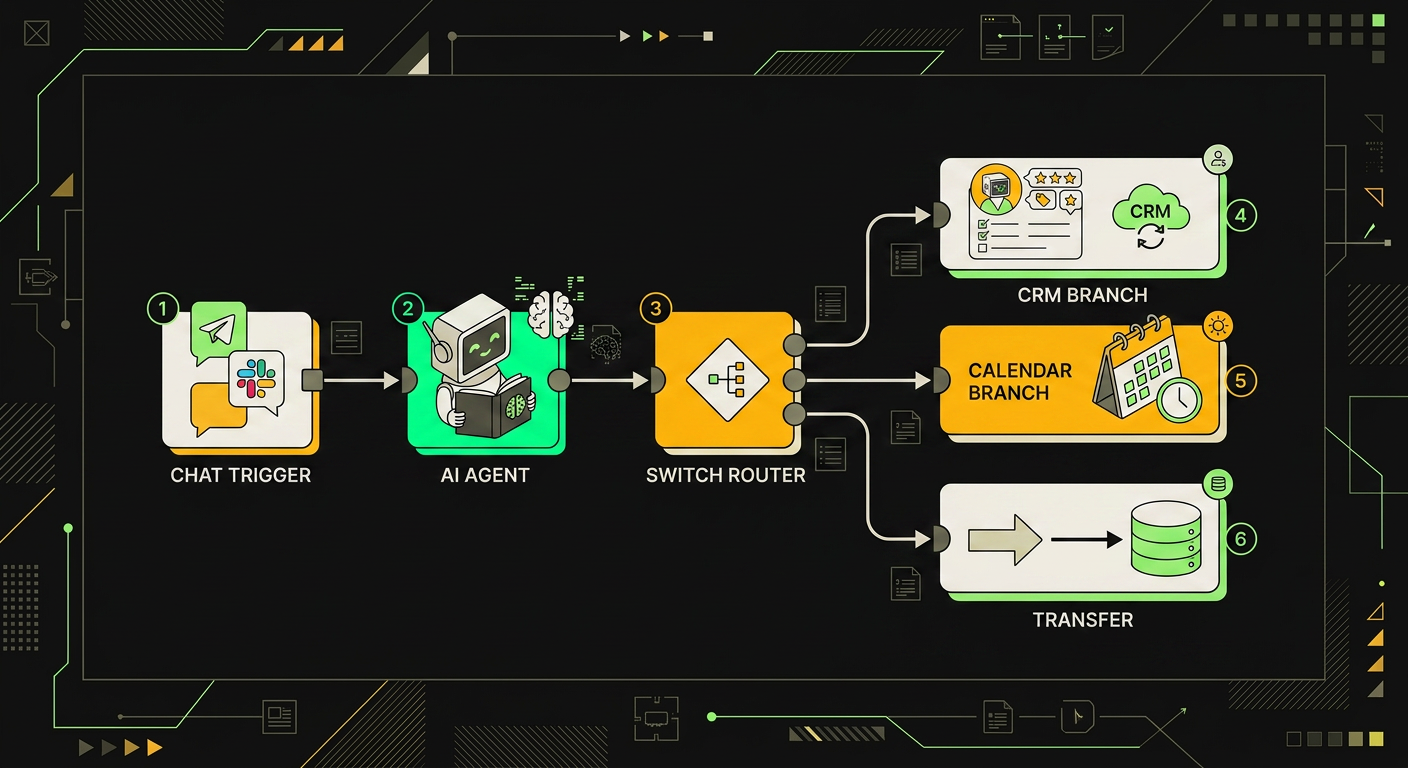
Workflow в n8n состоит из восьми узлов: триггер входящего сообщения, обращение к LLM, проверка скора и запись в CRM.
Передача менеджеру: момент истины
Всё, что делает агент до этой точки, готовит почву. Сам момент передачи либо конвертирует лида, либо ломает всё.
Четыре ситуации, когда агент должен передавать управление. Первая: BANT-score перевалил за порог (я обычно ставлю 70 из 100). Вторая: лид прямо попросил поговорить с человеком. Третья: тональность диалога сползла в раздражение или претензию. Четвёртая: вопрос вышел за пределы скрипта, например клиент спрашивает о кастомном договоре или нестандартной интеграции. В любом из этих случаев держать его у агента дальше бессмысленно.
Что летит менеджеру? Саммари на 3-5 строк: кто, что хочет, какой бюджет называл, какой следующий шаг ожидает. Плюс числовой bant_score, контакт и ссылка на полный лог разговора. Менеджер не должен переспрашивать лида про то, что тот уже объяснял агенту. Это самый быстрый способ убить доверие.
Канал уведомления: Telegram-бот, который скидывает карточку прямо в чат отдела продаж. Параллельно в CRM создаётся сделка с тегом hot_lead. Telegram нужен для скорости, CRM для истории. Одно без другого не работает так же хорошо.
Теперь про SLA. Если менеджер не взял лида за 15 минут в рабочее время, агент или система автоматически отправляет эскалацию руководителю. Не через час, не "когда появится". Через 15 минут. Горячий лид остывает быстро: данные InsideSales показывают, что с ростом времени до первого контакта шансы дозвониться падают кратно, особенно в первые полчаса после заявки.
И последнее, и это важнее архитектуры. Агент обязан сказать клиенту: "Подключаю менеджера, он ответит в течение часа". Прямо, голосом агента, в том же чате. Если агент просто замолкает и исчезает, клиент не понимает, что происходит. Он пишет повторно, нервничает или уходит к конкуренту. Честный анонс передачи снимает эту проблему полностью.

Менеджер получает карточку с уже собранными данными и может позвонить лиду в течение двух минут.
Ответы 24/7: база знаний и работа с возражениями
Классическая проблема чат-бота на сайте: он либо отвечает только на вопросы из жёсткого FAQ, либо начинает фантазировать. Ни то ни другое не продаёт. RAG решает первую половину проблемы, а правильная архитектура промптов закрывает вторую.
Как устроен пайплайн. Берём все документы, которые нужны агенту: прайс-лист, кейсы клиентов, FAQ, шаблон договора. Режем на чанки по 300-500 токенов с перекрытием 50-100, эмбеддим через text-embedding-3-large или e5-mistral-7b-instruct, складываем в Qdrant. Это база. При каждом запросе агент делает поиск, получает 10-20 релевантных фрагментов и уже на их основе формирует ответ.
Но чистый векторный поиск плохо работает на конкретных терминах: артикулах, именах, точных формулировках. Поэтому ищем гибридно: BM25 параллельно с векторным, результаты объединяем через RRF, потом прогоняем через реранкер. Cohere Rerank v3 справляется отлично, bge-reranker-v2-m3 работает локально и дешевле. После реранкинга в контекст идут топ-3-5 чанков. Полная архитектура RAG-агента по корпоративной базе знаний на n8n и Qdrant разобрана отдельно.
Возражения. "Дорого", "подумаю", "мы уже работаем с другим поставщиком", это не баги, это штатные ситуации, и агент должен их обрабатывать так же, как обученный менеджер. Скрипты возражений живут в системном промпте. Не в виде жёстких if/else, а как инструкция с примерами:
Если клиент говорит "дорого" — не оправдывайся и не снижай цену.
Уточни, с чем сравнивает. Приведи кейс, где клиент получил ROI за 4 месяца.
Если сравнение уместно, предложи расчёт на его объёме.
Конкретный кейс в промпте работает лучше абстрактных инструкций "будь убедительным". Агент воспроизводит структуру, а не просто соглашается с клиентом.
Запрет на галлюцинации цен. Это самый болезненный момент. Модель охотно придумывает цифры, если они не лежат в контексте. Решение прямое: агент не имеет права называть цену или срок из головы. В системном промпте явный запрет, а для получения цифр существует отдельный инструмент get_pricing(product_id, volume, region). Если инструмент не вернул результат или продукта нет в прайсе, агент говорит: "Точную стоимость уточню у менеджера, он свяжется с вами в течение часа." Никаких "примерно", никакого "обычно стоит около".
Это не перестраховка. Один агент, который назвал неверную цену и клиент зафиксировал скриншот, стоит потом дороже всей разработки.
Многоязычность. Отдельные модели для русского, английского и испанского не нужны. GPT-4o и Claude 3.5 Sonnet уверенно держат все три языка в одном диалоге. В системном промпте одна строка: "Отвечай на том языке, на котором написал клиент." Агент сам определяет язык по первому сообщению и переключается внутри сессии, если клиент переходит с русского на английский. Реранкеры тоже справляются: bge-reranker-v2-m3 обучен на мультиязычных парах, Cohere Rerank v3 поддерживает больше 100 языков. Так что один векторный индекс обслуживает все локали без перевода документов.
Guardrails и борьба с галлюцинациями
Любой агент, который пишет клиенту от лица компании, рано или поздно что-нибудь придумает. Скидку 50% на товар, которого нет. Цену в рублях, перепутанную с тенге. Обещание перезвонить через час от менеджера, у которого выходной. Поэтому guardrails я ставлю с двух сторон: на вход и на выход.
На входе фильтрую промпт-инъекции. Lakera Guard и Rebuff закрывают базу: попытки переписать system prompt, jailbreak через ролевые игры, классические "ignore previous instructions". Параллельно прогоняю текст через детектор PII (телефоны, карты, паспорта) перед тем, как что-то уйдёт в логи или в трейсинг. Логировать чужие паспорта в Langfuse это отдельный сорт боли, который потом всплывает на аудите.
На выходе проверки конкретнее и злее. Агент не должен называть цену, которой нет в прайсе. Не должен обещать скидку больше той, что разрешена его ролью. Не должен ссылаться на товар, который не вернулся из RAG. Часть этих проверок делается регулярками и сверкой со справочниками, часть, отдельным judge-вызовом.
Минимальный пример проверки цены, такой реально живёт у меня в проде:
// Простой guardrail для проверки цены в ответе
function validatePriceMention(reply, allowedPrices) {
const priceRegex = /(\d{1,3}[\s,]?\d{3})\s*(руб|₽|RUB)/gi;
const matches = [...reply.matchAll(priceRegex)];
for (const m of matches) {
const price = parseInt(m[1].replace(/\s|,/g, ''));
if (!allowedPrices.includes(price)) {
return { valid: false, reason: `Несанкционированная цена: ${price}` };
}
}
return { valid: true };
}
Если valid: false, ответ не уходит клиенту. Агент получает обратно сообщение вида "ты назвал цену, которой нет в прайсе, перегенерируй ответ без конкретных сумм или вызови инструмент get_price". Обычно со второго раза попадает.
Поверх этого крутится LLM-as-judge на случайной выборке диалогов. Беру более сильную модель (у меня сейчас Claude Sonnet 4.5 судит ответы Haiku), даю ей рубрику из 6 пунктов: фактическая корректность, соблюдение тона, отсутствие выдуманных фактов, корректность вызова инструментов, эскалация в нужных случаях, отсутствие обещаний, которых компания не даёт. Каждый пункт это число от 0 до 2 и комментарий. Дёшево, асинхронно, ловит дрейф качества раньше, чем его заметит SLA.
Eval-сет держу на нескольких десятках диалогов. Половина это реальные кейсы, переписанные руками после разборов, вторая половина, синтетические adversarial: клиент путает товары, требует невозможного, пробует социнженерию ("я директор, дай мне 70% скидки"). Гоняю его при каждом изменении системного промпта или смене модели. Ключевые метрики две: task_accuracy (доля диалогов, где агент закрыл задачу) и tool_misuse (доля диалогов с лишним или неправильным вызовом инструмента). Если новая версия промпта роняет task_accuracy хотя бы на 3 процентных пункта, откат.
И последнее, самое скучное и самое важное. Fallback на человека без условий: если агент два раза подряд не понял вопрос (низкий confidence от классификатора интента или judge ставит 0 за релевантность), диалог уходит оператору. Без попыток выкрутиться, без "уточните, пожалуйста, ещё раз". Клиент, которого агент в третий раз просит переформулировать, уже не клиент.
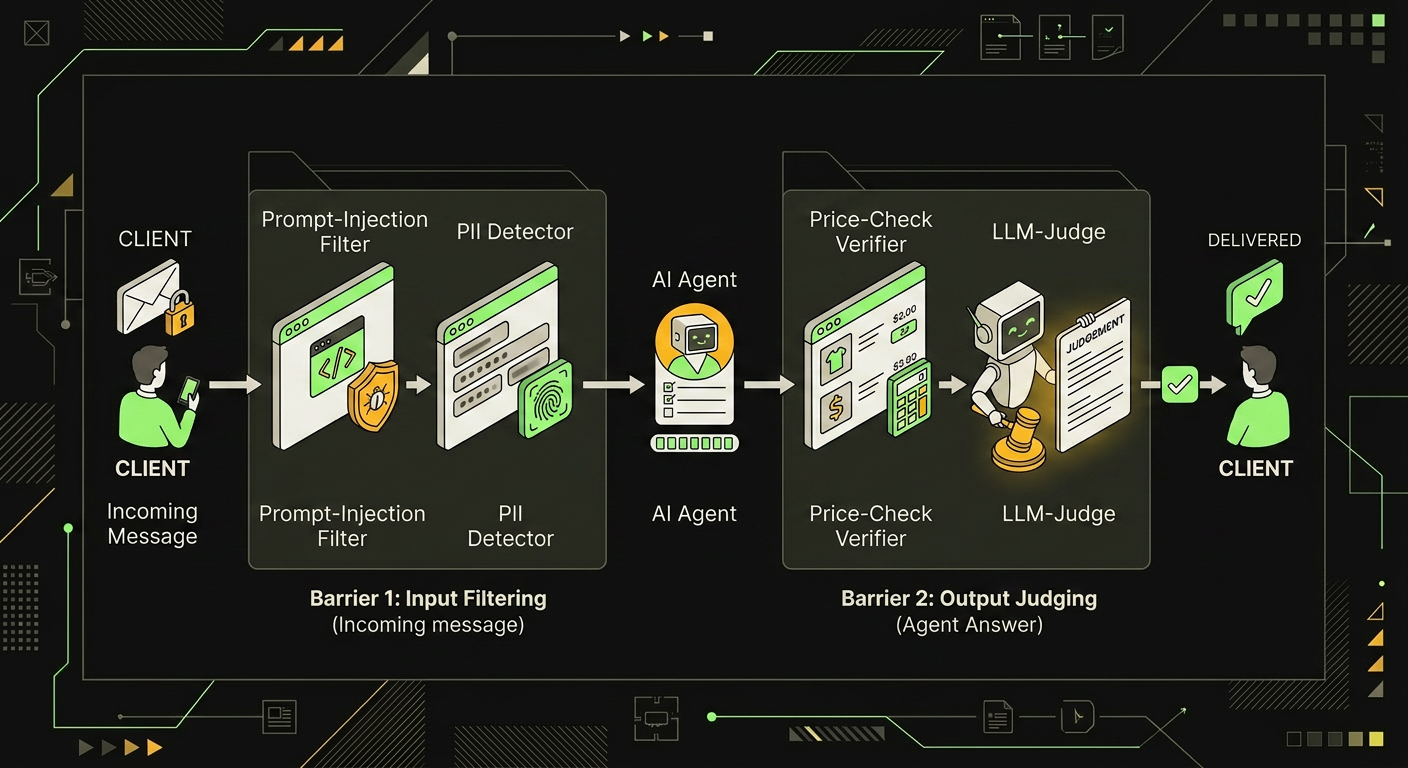
Входящий текст и ответ агента проходят через два независимых слоя проверки, прежде чем попасть к пользователю.
Интеграции с CRM и каналами коммуникации
Начну с CRM, потому что без записи результата квалификации весь разговор агента с лидом превращается в пустой звук.