Анатомия памяти агента: четыре слоя, которые работают вместе
Когда я проектирую агента, я держу в голове не "память" вообще, а четыре отдельных механизма с разными жизненными циклами. Они конфликтуют, если их свалить в один бак, и работают как часы, если разнести.
Слой 1. Системный промпт. Статичная память роли: кто агент, какие у него границы, какой стиль ответа, какие политики безопасности. Это самый дорогой токен в системе, он зачитывается на каждом ходе. Я держу его коротким и не пихаю туда динамику. Никаких "сегодня пользователь спросил про X". Только то, что не меняется неделями.
Слой 2. Краткосрочная память. Последние N сообщений в окне контекста. Я обычно беру скользящее окно в 20-30 ходов, не больше, даже если контекст 200K. Не потому что не влезает, а потому что модель начинает теряться в середине, lost-in-the-middle никуда не делся в 2026-м. Старые сообщения уходят на суммаризацию, не в забвение.
Слой 3. Долгосрочная семантическая память. Vector store с фактами о мире и о пользователе. Использую Qdrant или pgvector, эмбеддинги text-embedding-3-large или Cohere v4. Сюда попадают извлечённые факты ("пользователь работает на Postgres 16, любит явные транзакции"), документация, FAQ. Ключевая ошибка, которую я вижу у команд: они кидают сюда же историю диалогов целиком. Получается каша, retrieval тянет случайные куски бесед вместо фактов.
Слой 4. Эпизодическая память. Суммаризации прошлых сессий с временными метками и темами. Структура у меня такая: {session_id, user_id, started_at, summary, topics[], unresolved[]}. Когда пользователь возвращается через неделю, я делаю запрос по user_id плюс семантический поиск по теме текущего вопроса, подтягиваю 2-3 релевантных эпизода. По опыту, это заметно снижает жалобы на "агент меня не помнит".
Процедурная память стоит особняком. Tool definitions, few-shot примеры под конкретные задачи, цепочки вызовов которые сработали раньше. Я храню её как отдельный индекс с тегами по задаче. Когда агент классифицирует входящий запрос как "анализ SQL-плана", он подтягивает 2-3 примера именно под это, а не общие демонстрации.
Почему чистый RAG ломается на 20-м ходе
Классический сценарий. Команда поднимает RAG поверх vector store, в него пишут все сообщения подряд. Первые 10-15 ходов всё хорошо. Потом начинается галлюцинирование: агент уверенно ссылается на факты, которые пользователь не говорил, или путает текущий контекст с прошлой сессией.
Причина простая. Без суммаризации vector store наполняется фрагментами реплик вне контекста. Запрос "а что я говорил про бюджет" вытаскивает три похожих фрагмента из разных дней, эмбеддинги-то близкие. Модель честно их склеивает в один правдоподобный ответ. Эпизодическая память с явными временными метками и границами сессий это убивает: retrieval возвращает не куски, а связные сводки с датами.
Три индекса, не один
Я физически разделяю хранилище:
- per-user: факты и предпочтения конкретного человека, эпизоды его сессий
- per-session: рабочая память текущего диалога, очищается или архивируется на закрытии
- global: документация продукта, общие знания, политики
При retrieval запрос идёт параллельно во все три, с разными top_k и разными порогами similarity. Глобальный индекс я фильтрую жёстче, пользовательский мягче, потому что персональные факты часто формулируются криво и эмбеддинги расходятся. Финальный re-rank cross-encoder'ом, обычно bge-reranker-v2.
Смешивать эти три в один коллекшен заманчиво ради простоты. Но через месяц вы получите утечки контекста между пользователями (страшно), смешение документации с личными данными (юридически больно) и невозможность забыть конкретного юзера по GDPR-запросу без полного переиндексирования. Разделение на старте стоит два дня работы. Объединённый индекс через полгода переписывается неделями.
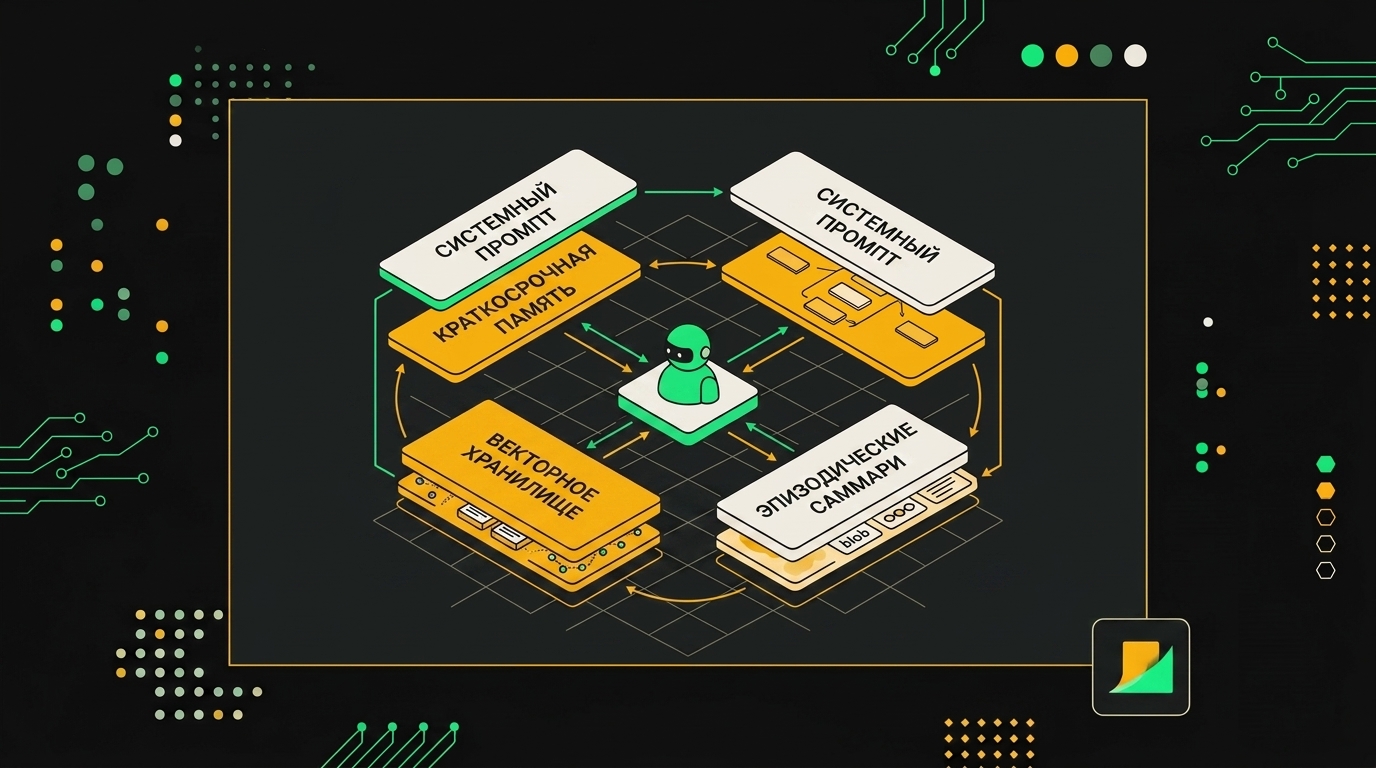
Каждый уровень обрабатывает свой горизонт времени: от миллисекунд рабочей памяти до постоянного хранилища фактов.
Лимиты токенов в 2026: что реально влезает и сколько это стоит
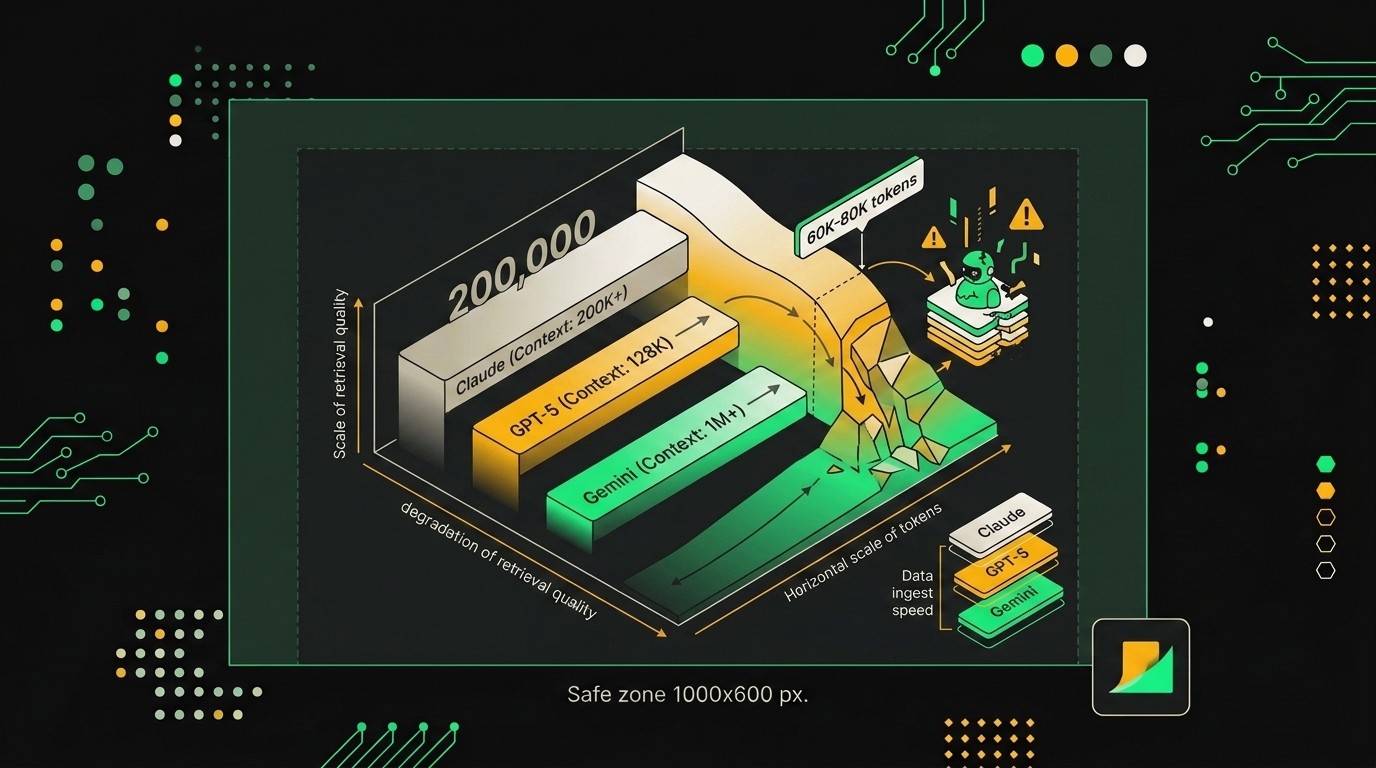
Цифры на витринах выглядят красиво. Claude Sonnet 4.5 с окном 200K, GPT-5 раскачали до 256K, Gemini 2.5 Pro формально держит 2M токенов и в маркетинге это звучит как "загружай весь репозиторий и спрашивай". На практике я давно перестал верить заявленным лимитам как рабочей характеристике.
Деньги первыми выдают разрыв между рекламой и реальностью. Один вызов Opus с промптом на 200K входных токенов обходится примерно в $3, и это только вход, без генерации ответа. Цена входа растёт нелинейно: удвоил контекст, получил больше чем удвоенный счёт за счёт более дорогих тарифов на длинные окна у части провайдеров. Если вы видите в логах стоимость одного запроса $0.50 и выше у чат-бота, это почти всегда не "сложный кейс", а утечка контекста: кто-то забыл подрезать историю или прицепил весь PDF целиком.
Теперь про качество. Заявленный контекст и эффективный контекст это разные вещи. Бенчмарк RULER и классический needle-in-haystack показывают, что после 32K у большинства топовых моделей рассуждение начинает плыть, а на 60-80K извлечение факта из середины окна проседает заметно. Эффект "lost in the middle" никуда не делся за два года, его просто маскируют усреднёнными метриками. Если вам нужен надёжный ответ по конкретному фрагменту, держите релевантный кусок в первых или последних ~20K токенов, а не где-то в районе токена 140000.
Арифметика для продакшена обычно отрезвляет лучше любой теории. Считаем чат с 1000 DAU, по 20 ходов в среднем, и историей в 8K токенов, которую мы тащим заново на каждом ходу:
1000 × 20 × 8000 = 160M токенов в день
Это грубая прикидка, реальные цифры зависят от длины реплик и частоты сессий. При входной цене ~$2.50/1M и без кеширования повтор одного и того же контекста может выедать заметную долю бюджета. Prompt caching у Anthropic и OpenAI режет эту цифру в 5-10 раз, но включается только если вы аккуратно строите префикс и не меняете системный промпт от запроса к запросу.
Я везде ставлю жёсткий budget check перед отправкой. Не на уровне "а вдруг превысим лимит модели", а на уровне "а влезаем ли мы в свой собственный потолок качества и цены":
import tiktoken
enc = tiktoken.encoding_for_model('gpt-4o')
def budget_check(messages, max_input=120_000, reserve_output=8_000):
total = sum(len(enc.encode(m['content'])) for m in messages)
available = max_input - reserve_output
if total > available:
return total, total - available
return total, 0
# возвращает (использовано, превышение)
Я ставлю max_input заметно ниже потолка модели. Граница, за которой деградация и цена начинают бить по продукту сильнее, чем дополнительный контекст помогает, у каждого проекта своя, но я её всегда выставляю явно. Если функция возвращает превышение, дальше работает суммаризатор истории или ретривер: режем старое, оставляем последние 4-6 ходов целиком, остальное сжимаем в краткое summary на 500-800 токенов. Дёшево, предсказуемо, и пользователь не замечает разницы.
Простое правило, к которому я пришёл: считайте окно модели не как объём, в который надо запихнуть максимум, а как бюджет, из которого вы тратите минимум необходимого. Каждый лишний килотокен в истории это деньги и шум для ответа одновременно.
После ~60% заполнения окна большинство моделей начинают «забывать» факты из середины контекста, что подтверждено в исследовании Lost in the Middle (2023).
Vector store: Pinecone, Qdrant, Weaviate, pgvector в реальной нагрузке
Тестировал четыре движка на одном датасете: 20M векторов 1536-dim из OpenAI text-embedding-3-small, фильтры по tenant_id и created_at, нагрузка от 50 до 12K QPS. Машины одинаковые там, где это применимо: c7i.4xlarge для self-hosted, индекс HNSW с M=16, ef=128.
Qdrant на одиночном узле показал хорошую latency, в частности P50 и P99 на уровне единиц миллисекунд при этой конфигурации. Из self-hosted вариантов это лучшее, что я видел без шардирования. Rust-движок, payload-индексы по метаданным реально работают (в отличие от ранних версий Weaviate, где фильтр после ANN убивал latency). Минус один: когда переходишь на распределённый режим с шардами, операционка становится заметной, особенно ресайз кластера под нагрузкой.
Pinecone в serverless держит высокий QPS с latency в пределах десятков миллисекунд. Платишь за каждый запрос и за хранение, но получаешь нулевой ops. BYOC (bring your own cloud) появился для тех, кому compliance не разрешает данные за пределы своего AWS-аккаунта. Если у тебя B2B SaaS с enterprise-клиентами, это та фича, ради которой Pinecone выбирают, а не latency.
Weaviate уверенно справляется с несколькими тысячами QPS. Звезда здесь не скорость, а hybrid search из коробки: BM25 + dense, нормализация через RRF, всё конфигурится в схеме без дописывания reranker-слоя. Если тебе нужен поиск по документам с точными вхождениями (имена, артикулы, даты), Weaviate экономит неделю интеграции.
pgvector с HNSW (версия 0.7+, она уже год как стандарт) показал P50 в районе 8-10ms на 4M векторов. Это совершенно приемлемо, если Postgres у тебя уже крутится. Транзакции, джойны с бизнес-таблицами, бэкапы, репликация, мониторинг, всё бесплатно с точки зрения когнитивной нагрузки команды.
Где у меня проходит граница принятия решения:
- pgvector хватает до ~5M векторов, ~200 QPS, dim 1536. Если у тебя RAG над корпоративной базой знаний на 50K документов, не выдумывай отдельный сервис.
- Qdrant или Pinecone нужны, когда фильтры по метаданным идут поверх 50M+ векторов или когда мульти-тенант требует жёсткой изоляции коллекций. На pgvector это упирается в planner и партиционирование, и боль начинается раньше, чем кажется.
- Weaviate беру, когда hybrid search это требование, а не пожелание.
Отдельный слой, который часто забывают: Redis как семантический кеш запросов к LLM. Кладёшь embedding входящего вопроса, ищешь по cosine similarity среди недавних с высоким порогом (настраивай под свой домен, слишком низкий порог вернёт неподходящий кешированный ответ, слишком высокий даст нулевой hit rate), возвращаешь сохранённый ответ. На моих продовых дашбордах это срезает 30-60% вызовов в OpenAI, окупается за неделю даже при текущих ценах на gpt-4.1 и Claude Sonnet 4.5. Кеш живёт отдельно от основного vector store, с TTL, инвалидация по тегам контента.
Практический рецепт на 2026: начинай с pgvector, выноси в Qdrant когда P99 на фильтрованных запросах переваливает за 50ms, ставь Redis-кеш перед LLM с первого дня.

Pinecone, Weaviate и pgvector дают принципиально разные компромиссы между скоростью вставки и точностью поиска при одинаковой размерности эмбеддингов.
Стратегии sliding window и summary buffer
Самый тупой подход работает удивительно долго: берём последние K сообщений, остальное выкидываем. Я начинал с K=20 на gpt-4o-mini и для болталки этого хватало неделями. Проблема вылезает в первом же длинном диалоге, где на 5-м ходу пользователь сказал "у меня диабет 2 типа", а на 25-м спросил рецепт. Контекст ушёл. Модель радостно советует торт.
Token-based window, следующий шаг. Считаем не реплики, а реальные токены через tiktoken или встроенный counter провайдера. Реплики бывают разные: одна строка "ок" и простыня на 2000 токенов с дампом JSON. Резать по числу сообщений в такой ситуации значит либо упереться в лимит, либо выкинуть полезное.
Summary buffer устроен сложнее. Старая голова диалога сжимается в одно system-сообщение, хвост из последних K ходов едет как есть. Я обычно держу хвост в 6-10 ходов, этого достаточно, чтобы модель видела актуальный микроконтекст (что пользователь говорил минуту назад), а саммари держит долгосрочные факты.
async def compress_history(messages, target_tokens=2000):
if count_tokens(messages) < target_tokens * 2:
return messages
head, tail = messages[:-6], messages[-6:]
summary = await llm.summarize(
head,
instruction='Сохрани решения, имена, цифры, обещания. Опусти small talk.'
)
return [{'role': 'system', 'content': f'Резюме: {summary}'}] + tail
Триггер на пересжатие я ставлю заметно раньше потолка, ориентировочно около трети-половины бюджета окна. Если упереться в потолок и сжимать на каждом следующем ходу, латентность скачет, плюс саммари деградирует от повторных пересказов пересказа (испорченный телефон в чистом виде). Запас позволяет сжимать редко, качество стабильнее.
Иерархическое сжатие полезно для агентов, которые живут долго. Уровни у меня обычно такие: последний час идёт полным текстом, события за сутки сжаты на 1:5, всё что старше недели лежит как набор фактов. Для чат-бота поддержки это избыточно, для персонального ассистента, который помнит про вас три месяца, обязательно.
Отдельно про формат памяти. Свободный текст вида "пользователь сказал, что предпочитает Python и работает в финтехе" против JSON {"languages": ["python"], "domain": "fintech"} дают существенную разницу по токенам на одном и том же объёме фактов. Плюс структуру можно валидировать, мерджить, дедуплицировать. Свободный текст плодит дубликаты: на 50-м ходу саммари содержит "любит Python" три раза в разных формулировках.
Главная ловушка summary buffer, на которую я налетал не раз: модель сжимает то, что выглядит как small talk, а на самом деле там было решение. Пользователь 30 ходов назад сказал "ладно, делаем через Postgres, не Mongo". Звучит как реплика без веса. Саммаризатор её выкидывает. Через 50 ходов агент предлагает Mongo, потому что в его контексте про Postgres ничего нет. Лечится явной инструкцией саммаризатору ("сохрани решения, обещания, цифры, имена") и отдельным слотом decisions в структурированной памяти, который никогда не пересжимается.
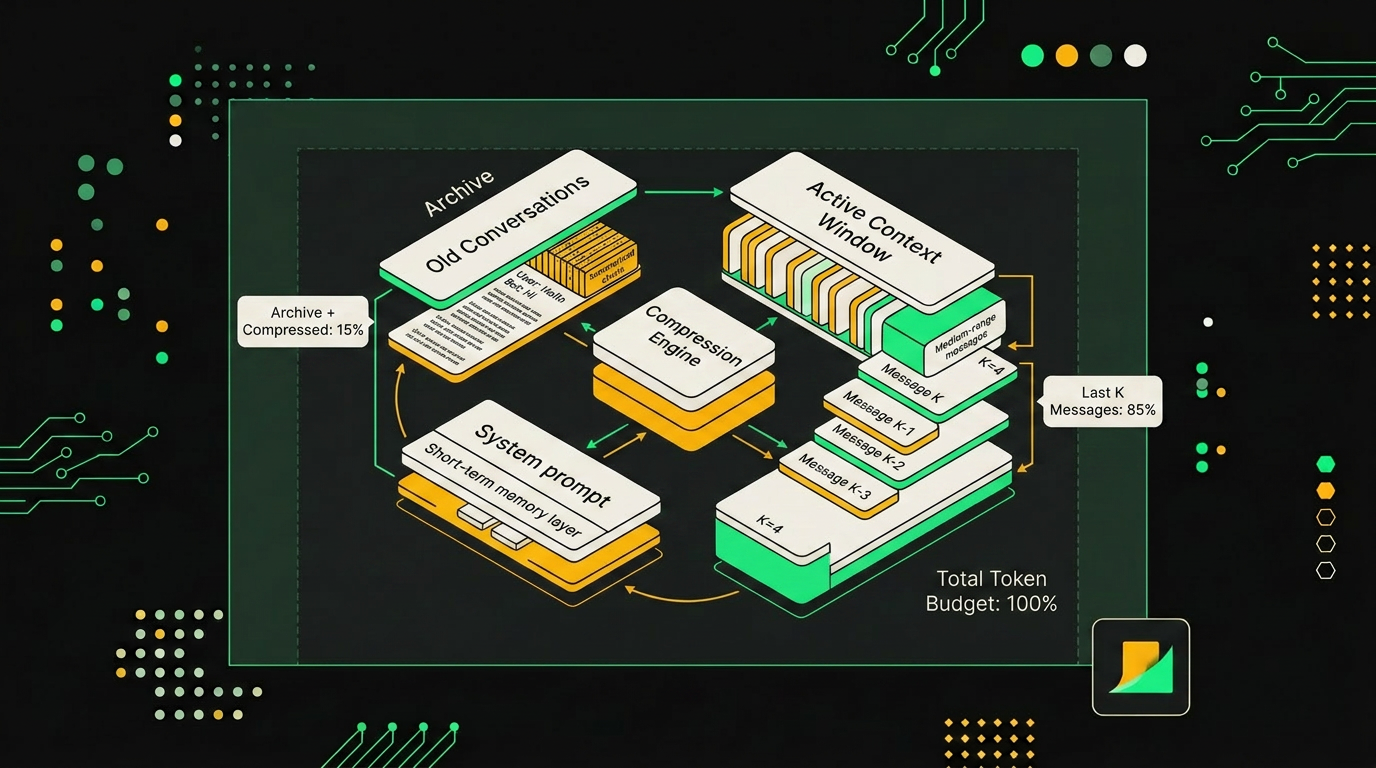
Буфер суммаризации сохраняет смысл длинного разговора в 5-10 раз компактнее, чем прямое усечение токенов.
Чанкинг и embeddings: где теряется смысл
Большая часть провалов RAG, которые я разбирал в этом году, упиралась не в LLM и не в промпт. Смысл терялся раньше, на этапе нарезки документов и векторизации. Модель просто не получала нужный фрагмент в контекст, а дальше уже неважно, GPT там или Claude.
Базовый рецепт, который у меня работает по умолчанию для технической документации: чанки 256-512 токенов с overlap 50-100. Меньше 256 рвёт логику абзаца, больше 512 размывает эмбеддинг, и косинус начинает врать. Overlap нужен именно потому, что граница чанка почти всегда проходит через смысловую связку ("...как описано выше | этот параметр включает..."), и без перекрытия вы теряете антецедент.
Fixed-size нарезка по токенам это дефолт от лени. Как только переходишь на semantic chunking, режущий по границам параграфов, заголовков и сменам темы, recall@5 заметно улучшается на тех же данных и той же модели эмбеддингов. Разрыв между фиксированной нарезкой и семантической стабильно воспроизводится на доменных корпусах, хотя конкретные цифры зависят от типа текста.
Отдельная история, которая стрельнула в 2025 и сейчас стала почти стандартом, late chunking от Jina. Идея простая: эмбеддишь весь документ через long-context модель, получаешь токен-уровневые векторы с полным контекстом, и только потом усредняешь их по чанкам. Ссылки вида "см. раздел 3.2", местоимения, сокращения, всё это сохраняет привязку к документу. На юридических текстах и API-референсах разница с обычным чанкингом заметна невооружённым глазом.
По моделям эмбеддингов на май 2026 расклад такой. Для английского и общих задач рабочая тройка: OpenAI text-embedding-3-large (3072 dim, дорого но стабильно), Cohere embed-v4 (хорош на длинных документах), BGE-M3 если нужна мультиязычность из коробки. Для русского картина другая. На доменных текстах (медицина, право, внутренняя документация на русском) BGE-M3 и e5-mistral стабильно опережают OpenAI по метрикам вроде nDCG@10. Разрыв воспроизводится на нормальных eval-сетах с русскими запросами и смешанной терминологией, хотя величина зависит от домена.
Второй этап, без которого я RAG в прод не выпускаю, это reranking. Достаёшь top-50 кандидатов из векторного поиска, прогоняешь через cross-encoder, оставляешь top-3 или top-5. bge-reranker-v2 локально, Cohere Rerank если не хочется держать GPU. Precision@3 существенно поднимается, и это самый дешёвый по усилиям буст, который вообще есть в пайплайне.
И последнее, про что забывают чаще всего: гибридный поиск. Dense-векторы плохо ловят точные совпадения. Артикул "BX-4471-A", версия "v2.18.3", фамилия в редком написании, имя CLI-флага, всё это BM25 находит мгновенно, а эмбеддинг размазывает по соседям. Решение, RRF-фьюжн dense и sparse результатов. В Qdrant это делается одним запросом:
from qdrant_client import QdrantClient
from qdrant_client.models import Prefetch, FusionQuery, Fusion
results = client.query_points(
collection_name='docs',
prefetch=[
Prefetch(query=dense_vec, using='dense', limit=50),
Prefetch(query=sparse_vec, using='bm25', limit=50),
],
query=FusionQuery(fusion=Fusion.RRF),
limit=10,
)
Два префетча, RRF их склеивает по рангам, на выходе top-10, который потом идёт в reranker. На запросах с кодами и версиями гибридный поиск стабильно выигрывает у чистого dense по precision на старших позициях. Если работаете с техдокой, каталогами или кодом, это не опция, это базовая настройка.
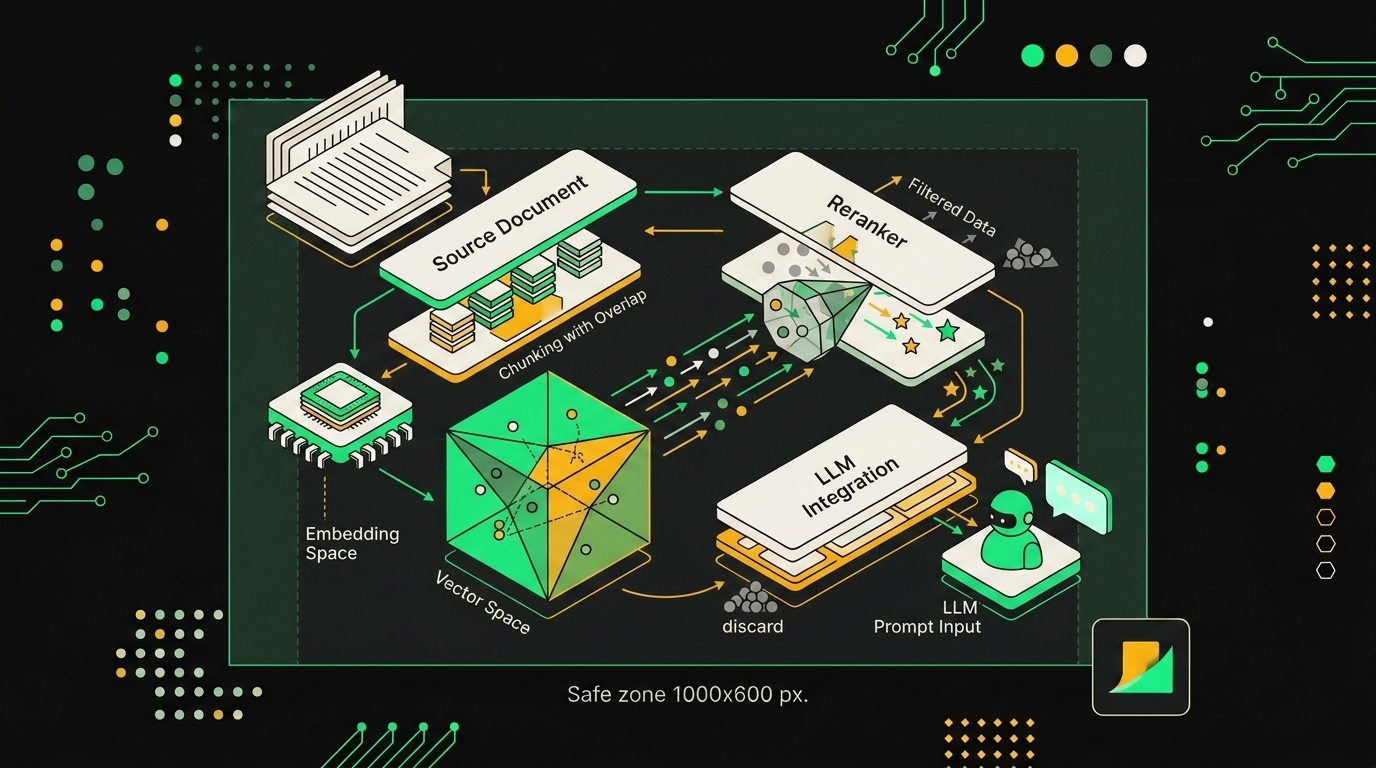
Оверлап в 10-15% от размера чанка снижает потери контекста на границах фрагментов без заметного роста объёма индекса.
Контроль затрат: бюджеты, кеши, маршрутизация моделей
Жёсткий потолок по токенам на сессию я ставлю по умолчанию во всех продакшен-агентах. Дошли до лимита, дальше два варианта: либо принудительная компрессия истории через summarizer, либо новая сессия с переносом только структурированного state. Без этого один сломанный tool call может съесть дневной бюджет за полчаса. Видел такое на проде: агент ушёл в цикл "list_files → read_file → list_files" и накрутил серьёзную сумму за ночь.
Semantic cache на Redis окупается быстрее всего на support-ботах. Hit rate 25-40% это типичная картина, потому что пользователи задают одни и те же вопросы перефразированными формулировками. Считаю просто: эмбеддинг входа, поиск ближайшего по cosine выше настроенного порога, если попали, отдаём кешированный ответ. Инфраструктура (Redis Stack + embedding-модель) при достаточном трафике отбивается за неделю.
Маршрутизация моделей. Более дешёвая модель берёт основную долю трафика, дорогая включается только когда роутер возвращает низкий confidence или задача классифицирована как "multi-step reasoning". Сам роутер это небольшая модель локально. На больших объёмах своя железка дешевле, чем гонять каждый запрос через API-классификатор, хотя конкретная точка окупаемости зависит от ваших цен на железо.
Что логирую по каждому вызову:
tokens_in,tokens_outотдельно (входные часто дороже из-за prompt caching)cache_hit(boolean) и тип кеша: semantic или promptretrieval_recallесли используется RAG, считаю по ground truth на eval-сетеcost_per_sessionагрегатом, не per-calltool_calls_countчтобы ловить циклы
Порог для алёрта по cost_per_session выставляйте под свой продукт. Когда срабатывает, в большинстве случаев это бесконечный цикл tool calls, реже модель застряла в reasoning-петле. Лечится hard cap на количество tool-вызовов за сессию и таймаутом на общее время рассуждения.
Prompt caching у Anthropic и OpenAI это самая недооценённая оптимизация. Системный промпт на 4K токенов с описанием инструментов, политик и few-shot примерами при кешировании даёт скидку до 90% на повторных вызовах. Условие одно: префикс должен быть побайтово идентичен. Поэтому динамические части (timestamp, user_id, контекст сессии) выношу в конец промпта, статика идёт первой. На агенте с высоким дневным трафиком это может быть разница в несколько раз по стоимости дня.

Семантический кэш с порогом схожести 0.92 сокращает число платных вызовов LLM на 30-40% в типичных сценариях поддержки.
Когда vector store вреден: антипаттерны RAG
Векторный поиск стал рефлексом. Любой вопрос → embed → top-k → LLM. И это ломается чаще, чем принято признавать.
Самый дурацкий случай: "сколько у меня заказов за апрель". Никакая similarity не даст правильный ответ, потому что вопрос аналитический, а не семантический. Top-5 чанков по косинусу вернут пять похоже звучащих абзацев из разных мест, а реальный ответ это SELECT COUNT(*) FROM orders WHERE .... Я видел проекты, где над этим страдали месяцами, прикручивая reranker, hybrid search, MMR, пока кто-то наконец не сказал: "ребята, это SQL". Router на входе, который классифицирует запрос на factual/analytical/lookup, экономит больше, чем любая оптимизация индекса.
Второй антипаттерн: маленькая база. Если у вас 200-500 документов общим объёмом мегабайт пять, в 2026 нет смысла поднимать Pinecone или Qdrant. Gemini 2.5 Pro съест миллион токенов контекста за один вызов, отдаст ответ с цитатами, и сделает это точнее,