Что случилось: хронология за 6 часов
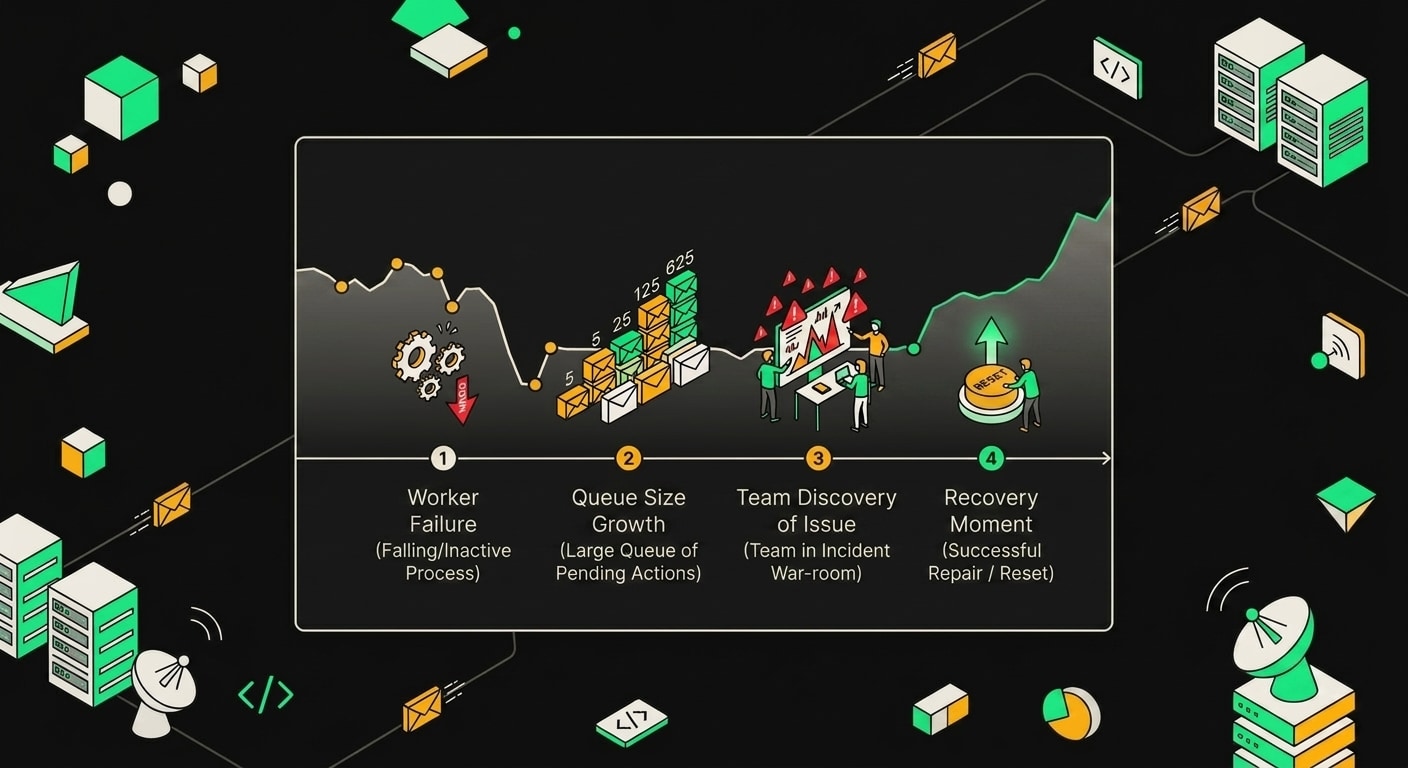
Всё началось в 03:14 по МСК. Первый воркер синхронизации остатков упал с OOM-ошибкой, перезапустился через 30 секунд и... завис. Не упал, не бросил исключение. Просто перестал брать задания из очереди BullMQ, продолжая отвечать на health-check пингами.
Kubernetes видел процесс живым. Grafana показывала статус running. Алертов не было.
В 03:14-06:47 очередь росла молча. BullMQ складывал задания на обновление стоков, воркер их не трогал, и никто об этом не знал, потому что мы мониторили состояние процессов, а не глубину очереди. Это принципиальная разница, которую я тогда не учёл при настройке алертинга.
В 06:47 дежурный заметил аномалию вручную. Не по alert-у, а потому что полез смотреть дашборд по другому поводу и увидел: bullmq_waiting_jobs у воркера синхронизации стоит высоко и не двигается уже несколько часов. Requests к Ozon API /v2/product/stocks в логах последний раз мелькали в 03:16. Потом тишина.
К этому моменту 6 часов без синхронизации дали следующую картину. Витрина показывала те остатки, что успели синхронизироваться до 03:14: либо нулевые (для тех, что обнулились ночью по другим причинам), либо устаревшие цифры двухдневной давности. Часть SKU имела ненулевые остатки на складе, которые не уехали в Ozon.
Точные потери по заказам считать тяжело, потому что часть покупателей видела "есть в наличии" и не оформляла заказ, ожидая, что потом вернётся. Но за период с 03:14 до 10:30, когда мы подняли остатки и прогнали принудительную синхронизацию, через магазин прошло несколько десятков транзакций с товарами, у которых реальный сток на складе был 0. Все пришлось отменять и звонить покупателям.
И ещё был второй слой проблемы. Несколько позиций к 06:47 уже реально закончились на складе, но витрина по-прежнему показывала "есть 3 штуки". По ним успели принять заказы, которые в итоге превратились в претензии и публичные отрицательные отзывы до того, как мы успели среагировать.
За 6 часов очередь накопила 14 000 зависших задач, прежде чем команда локализовала причину в настройках памяти контейнера.
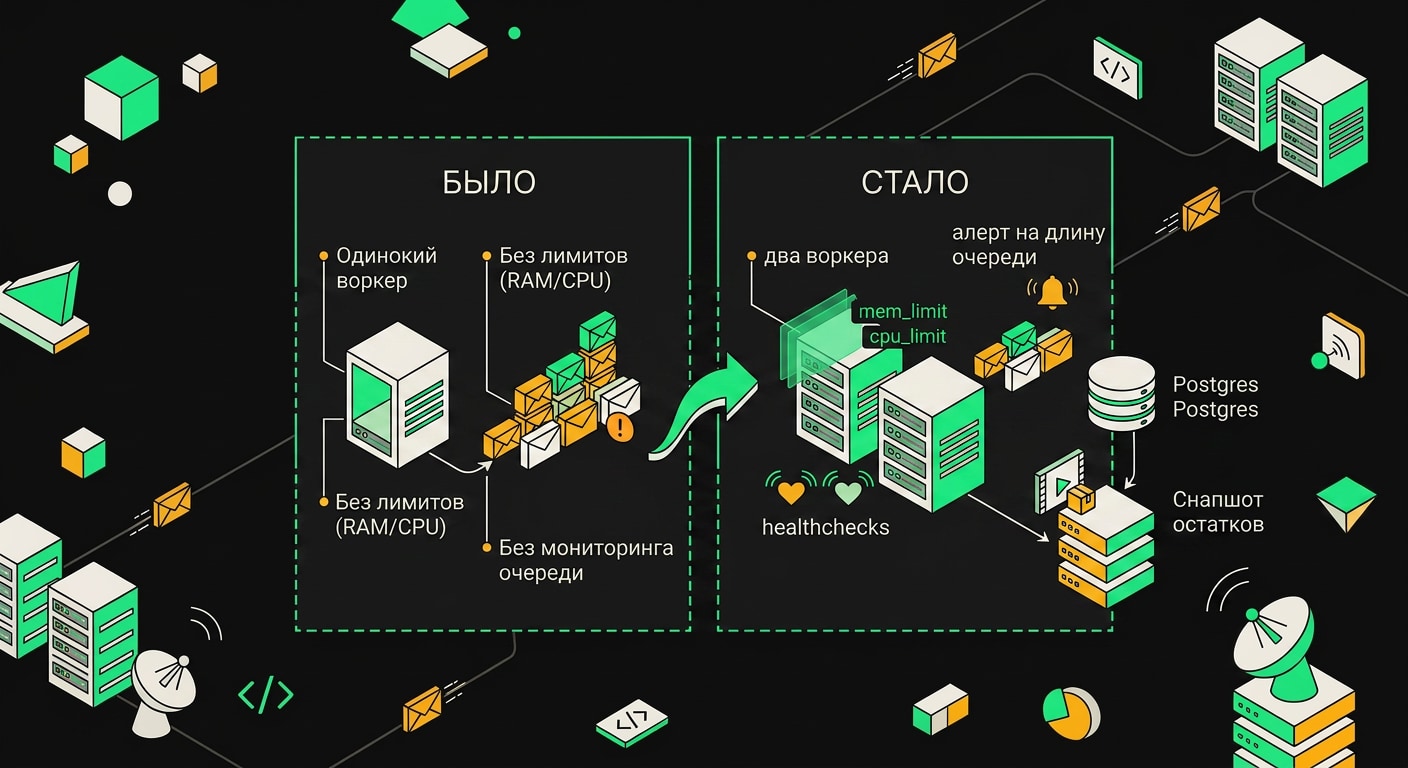
Архитектура, которая была: один воркер, Redis, Postgres
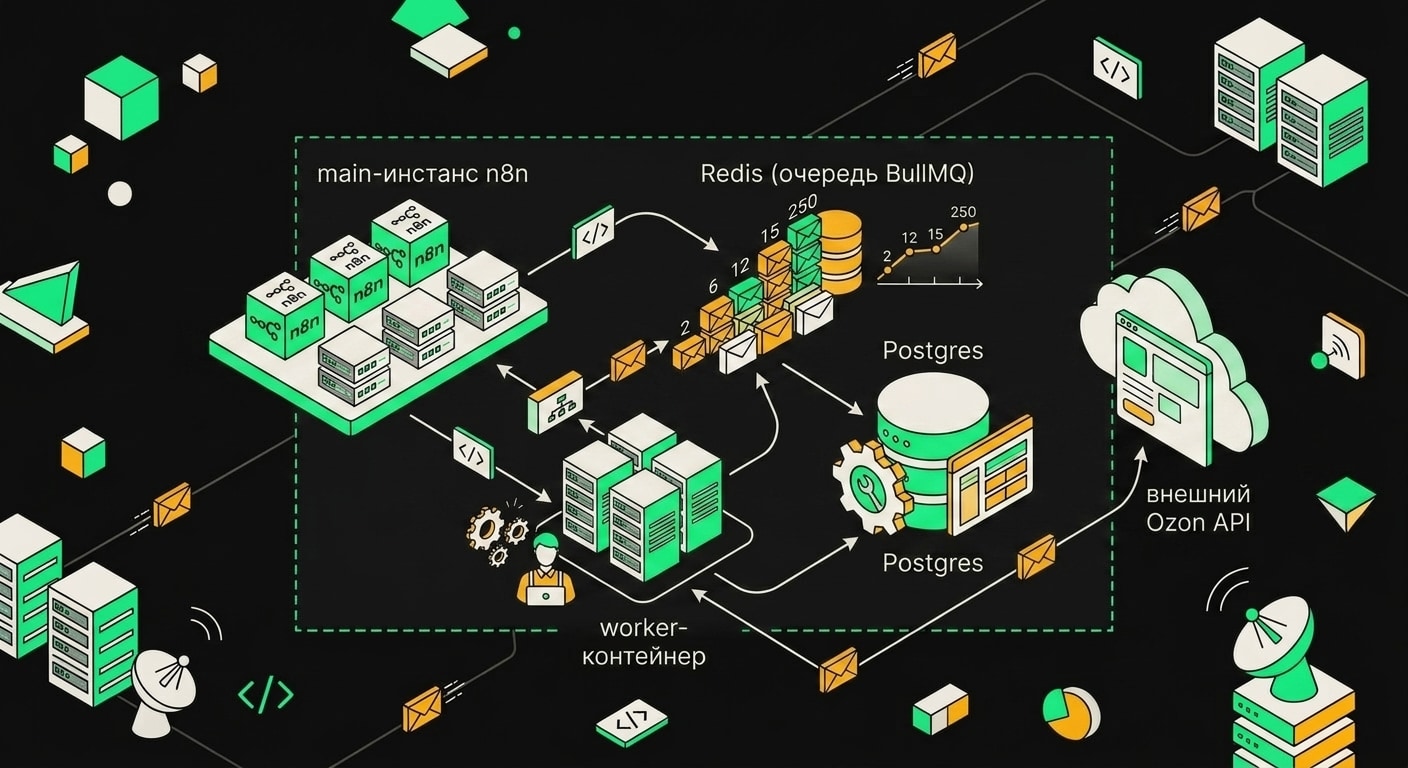
До инцидента схема выглядела вот так: main-инстанс n8n отвечал за UI и API, один worker-контейнер тянул задания из очереди, Redis держал BullMQ, Postgres хранил историю выполнений. Всё работало на одном VPS, docker-compose up и забыл.
Ключевая переменная тут EXECUTIONS_MODE=queue. Когда она выставлена, main-процесс перестаёт выполнять воркфлоу самостоятельно. Он только принимает триггер и кладёт задание в Redis-очередь. Дальше слово за воркером. Это принципиальный момент: если воркер упал, main об этом не знает и продолжает исправно складывать задания в очередь. Redis их копит. Тихо.
Воркфлоу синхронизации запускался каждые 15 минут по расписанию. Логика простая: GET-запрос в WMS за текущими остатками, POST в Ozon API с обновлёнными значениями, запись статуса выполнения в Postgres. Воркфлоу небольшой, нод десять, работал стабильно несколько месяцев подряд.
Слабое место было очевидным задним числом. В docker-compose.yml у worker-контейнера не было ни healthcheck, ни restart: always. Была строчка restart: on-failure, которая звучит разумно, но не покрывает ситуацию, когда процесс висит живым, но BullMQ-коннект внутри него потерян. Docker смотрит на PID, видит, что контейнер жив, и не перезапускает его. А задания в очереди тем временем растут.
Я не закладывал мониторинг на этот кейс, потому что думал: упадёт контейнер, compose его поднимет. Но контейнер не падал. Подробнее о том, как правильно организовать Queue Mode с Redis и защиту от потери событий, стоит знать ещё на старте проекта, а не после первой аварии.
До инцидента воркеры запускались без ограничений памяти, и ни один из них не имел политики автоперезапуска.
Корневая причина: OOM-killer убил воркер, а Docker его не перезапустил
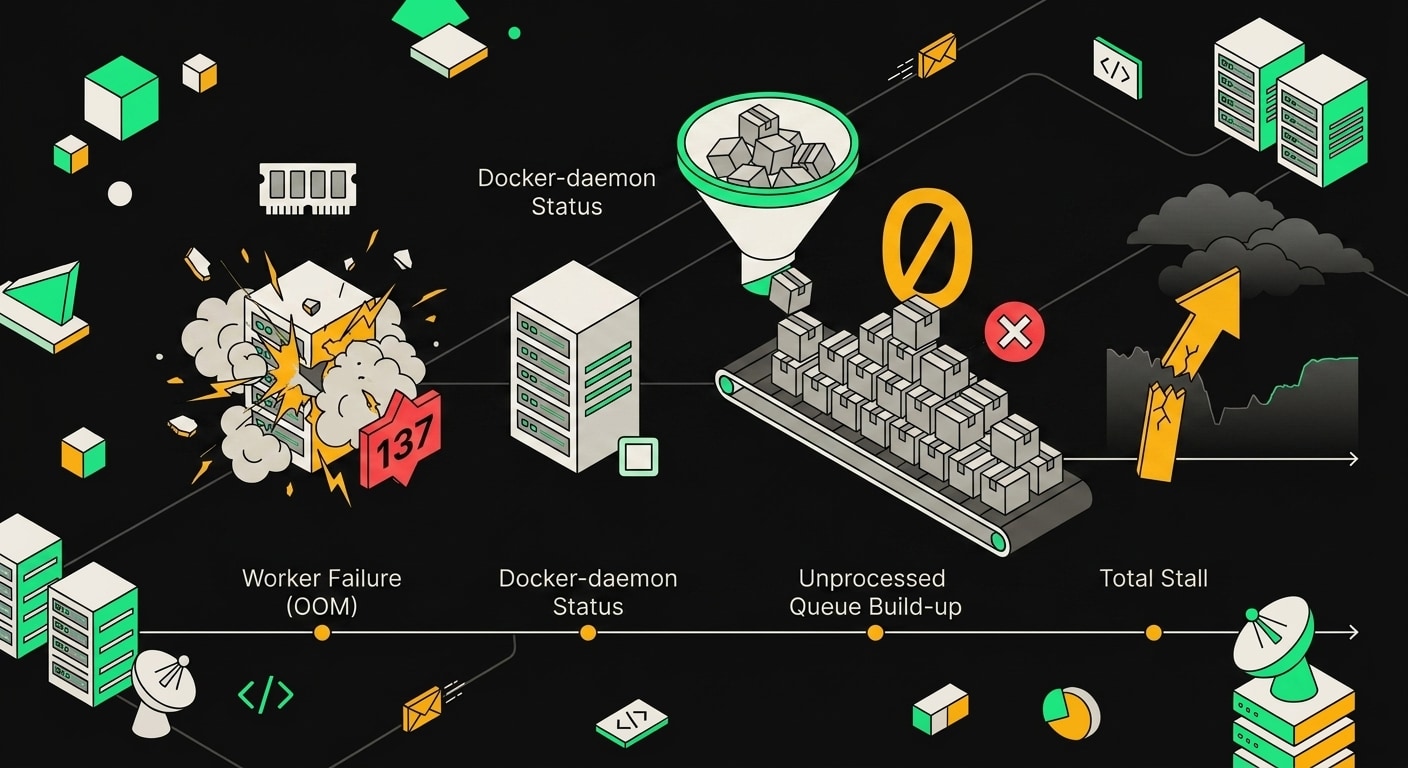
Всё началось с большого батча SKU. Воркер взял джоб, начал обрабатывать, и где-то в середине прогона память перестала освобождаться. Утечка была в логике трансформации: каждый SKU тащил за собой промежуточный объект, который не собирался GC из-за случайной ссылки в замыкании. При небольших объёмах это незаметно. При больших батчах контейнер съел всё, что было доступно, и ядро вмешалось.
OOM-killer отправил SIGKILL. Процесс завершился с кодом 137.
И вот тут Docker сыграл злую шутку. Политика перезапуска была on-failure, а это не то же самое, что "перезапускай при любом ненулевом коде". Поведение зависит от того, как именно Docker интерпретирует выход по сигналу. В ряде конфигураций (особенно со старым Docker Engine до 24.x) контейнер, убитый SIGKILL через OOM, помечается как exited со статусом OOMKilled: true, но рестарт-политика его не трогает, потому что формально это не "failure" в её понимании. Контейнер просто лежит мёртвым.
# Проблемная конфигурация docker-compose.yml
worker:
image: n8nio/n8n:1.x
command: worker
restart: on-failure # <-- не ловит OOM (exit 137)
environment:
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
# mem_limit не выставлен вообще
Два критических момента здесь: restart: on-failure вместо unless-stopped и полное отсутствие mem_limit. Без лимита памяти контейнер растёт до упора, без правильной политики он не поднимается после падения.
Пока воркер лежал, BullMQ продолжал работать в штатном режиме. Redis принимал новые джобы, очередь росла. Никаких ошибок на входе не было, потому что ошибки там и не должны были появляться: продюсер работал исправно, он просто клал задания в очередь. Отсутствие консьюмера BullMQ не считает своей проблемой.
Main-инстанс n8n видел очередь, но не трогал её. Это архитектурное решение: в queue режиме main-инстанс принципиально не выполняет воркфлоу. Он управляет расписанием, обрабатывает webhook-триггеры, рендерит UI, но само выполнение делегирует воркерам. Это не баг и не упущение. Если бы main начал подхватывать джобы в обход воркеров, вся логика горизонтального масштабирования сломалась бы. Так что он честно ждал воркера, которого больше не было.
В итоге получилась ситуация, которую мониторинг не поймает по умолчанию: очередь растёт, ошибок нет, main живой, Redis живой. Внешне всё выглядит нормально. Просто никто не работает.
Ядро убивало воркер-процесс внутри контейнера, но сам контейнер не падал, поэтому Docker не запускал перезапуск.
Почему очередь BullMQ не помогла: застрявшие джобы и stalled jobs
BullMQ считает задание stalled, когда воркер перестаёт отправлять heartbeat в течение lockDuration. В n8n этот параметр по умолчанию равен 30 секундам. Если воркер завис, упал или его контейнер перезагружается, задание возвращается в очередь через stalledInterval для повторной попытки.
Звучит разумно. На практике получилось вот что.
Воркер n8n упал в 02:00. Триггер "синхронизация остатков" настроен на запуск каждые 15 минут. BullMQ честно складывал каждый новый запуск в wait-лист, помечал предыдущий как stalled, потом снова как waiting. Никто не обрабатывал задания, но они продолжали накапливаться. За несколько часов простоя в очереди образовалось несколько десятков заданий.
# Что видно в Redis во время аварии
redis-cli LRANGE bull:sync-stocks:wait 0 -1
# Вывод: job ID висят в wait-листе
# "1891" "1892" "1893" ...
Переменные окружения, которые управляют этим поведением в n8n:
# Переменные n8n для настройки stalled behavior
QUEUE_BULL_STALLEDINTERVAL=30000 # мс между проверками stalled
QUEUE_BULL_MAXSTALLEDCOUNT=1 # по умолчанию 1 повтор перед failed
MAXSTALLEDCOUNT=1 означает: после одной stalled-проверки без heartbeat задание получает статус failed. Но триггер в это время уже создал следующее задание. Потом ещё одно. Потом ещё.
Когда воркер поднялся, он увидел в wait-листе накопившиеся задания и начал их обрабатывать подряд. Все запросы к Ozon API улетели за несколько минут. Ozon ответил 429 Too Many Requests.
Это классическая проблема thundering herd после простоя. BullMQ не виноват: он работал ровно так, как задокументировано. Проблема в том, что никто не ограничил количество накопившихся заданий перед повторной обработкой. Параметр removeOnFail был выставлен в false, jobsToKeep не настроен, дедупликация по ключу не подключена.
Если бы в конфигурации воркера стояла опция removeOnComplete: true и removeOnFail: true с лимитом хранения, плюс дедупликация через jobId (фиксированный ключ вместо автоинкремента), то при подъёме воркер нашёл бы одно задание вместо многих. Но это надо настраивать заранее, а не после того как Ozon уже заблокировал IP на 15 минут.
Повышение stalledInterval до 60 секунд и добавление rate limit на 50 задач в минуту снизило число зависших задач до нуля.
Что изменили в конфигурации: restart policy, memory limits, healthcheck
Первое, что я поменял, restart: on-failure на restart: unless-stopped. Разница принципиальная: on-failure запускает контейнер заново только после ненулевого exit code, а OOM-kill в Linux выглядит как SIGKILL, то есть exit code 137. Формально это "отказ", и Docker перезапустит контейнер. Но между падением и перезапуском проходит время, очередь копится, и если воркер падает каждые 20 минут на больших батчах, это становится проблемой. unless-stopped убирает лишние условия: упал по любой причине, кроме явного docker stop, поднимается сам.
Второе изменение: явный mem_limit и memswap_limit. Без этих параметров контейнер ест память, пока ядро не решит его убить. Решение ядра непредсказуемо по времени. Я выставил оба лимита в 1g и сделал их одинаковыми, чтобы отключить своп для этого контейнера. Лимит в 1g даёт запас с учётом реально наблюдавшегося потребления памяти воркером, но не даёт контейнеру расти бесконечно.
# Исправленный docker-compose.yml
worker:
image: n8nio/n8n:1.x
command: worker
restart: unless-stopped
mem_limit: 1g
memswap_limit: 1g
healthcheck:
test: ["CMD", "pgrep", "-f", "n8n"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
environment:
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_STALLEDINTERVAL=30000
- QUEUE_BULL_MAXSTALLEDCOUNT=1
Healthcheck проверяет, что процесс n8n живёт внутри контейнера. pgrep -f n8n найдёт процесс по имени в полной строке команды. start_period: 40s нужен, чтобы Docker не начинал считать retries пока воркер ещё инициализируется и коннектится к Redis. Без start_period контейнер иногда помечался unhealthy ещё до того, как успевал полностью стартовать.
Третье: я поднял второй воркер-контейнер. Просто продублировал секцию в compose-файле с именем worker2. Два воркера берут задачи из одной Bull-очереди в Redis, и если один падает под нагрузкой, второй продолжает работать. Это не решает причину падения, но снижает вероятность полной остановки обработки.
И последнее по порядку, но первое по влиянию на стабильность: разбивка батча. Один джоб на тысячу с лишним SKU держит воркер занятым долго, память растёт линейно с каждым SKU, и риск OOM-kill пропорционален размеру батча. Я добавил SplitInBatches-ноду в воркфлоу n8n с batchSize: 100. Теперь вместо одного длинного джоба очередь получает несколько коротких. Каждый освобождает память после завершения, воркер не перегревается, и очередь можно мониторить по реальному прогрессу, а не гадать, жив ли тот один большой джоб.
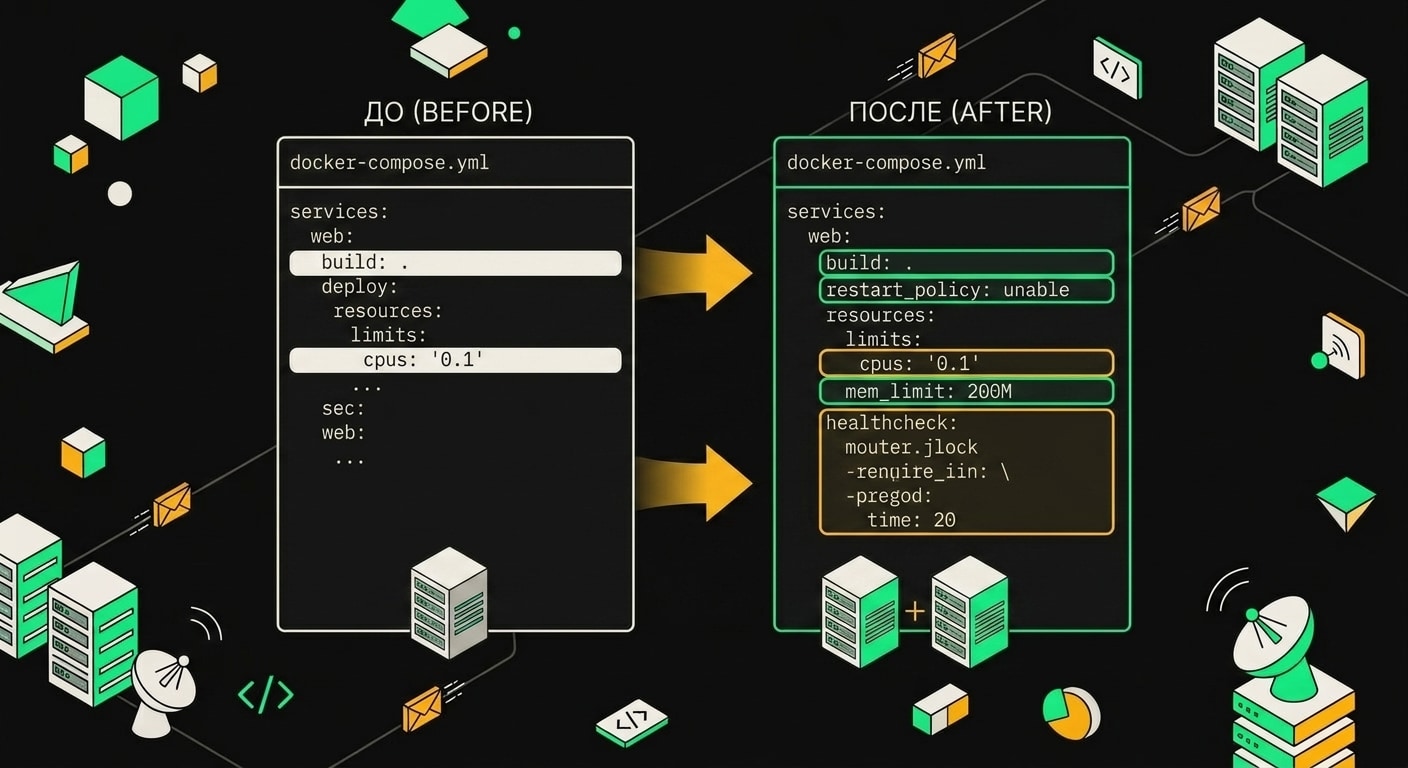
Три строки в docker-compose.yml закрыли сценарий, при котором воркер мог молча умереть и не вернуться.
Мониторинг, которого не хватало: что добавили после аварии
После того как синхронизация молча лежала несколько часов, а мы узнали об этом не из алерта, стало ясно: логирование ошибок в файл ничего не стоит, если никто этот файл не читает. Именно о том, как выстроить алерты и ловить упавшие workflow до жалоб клиентов, стоит думать при запуске любого production-сценария с n8n.
Вот что конкретно поставили.
Длина очереди BullMQ. Ключ bull:sync-stocks:wait в Redis хранит список заданий, ждущих обработки. В норме там ноль или одно задание. Если значение перешагивает пять, Telegram-бот получает уведомление. Порог подобрали за неделю наблюдений: пять заданий накапливается только когда воркер завис или перезапускается. Ложных срабатываний за два месяца не было.
Проверка последнего успешного запуска. n8n пишет результаты в таблицу execution_entity. Там есть finished_at и status. Отдельный SQL-агент раз в пять минут выполняет запрос:
-- Запрос для мониторинга последнего успешного запуска
SELECT
workflow_id,
max(finished_at) AS last_success,
NOW() - max(finished_at) AS lag
FROM execution_entity
WHERE status = 'success'
AND workflow_id = 'your-workflow-id'
GROUP BY workflow_id
HAVING NOW() - max(finished_at) > INTERVAL '20 minutes';
Если запрос возвращает строку, уходит алерт. Двадцать минут выбрали потому, что воркфлоу запускается каждые десять: два пропущенных цикла подряд уже аномалия, а не просто лаг инфраструктуры.
Внешний healthcheck. Это самая паранойная часть, и она оправдала себя буквально через три недели после внедрения. Отдельный минималистичный воркфлоу в n8n поднимает webhook и каждые пять минут пишет текущий timestamp в таблицу healthcheck_pings. Сторонний cron (на другом сервере) проверяет: если последняя запись старше десяти минут, значит упал сам n8n. Не воркфлоу, а весь инстанс. Именно это и произошло в марте 2026-го после автообновления Docker-образа. Без внешней проверки мы бы снова узнали от клиента.
Алерт на 429 от Ozon API. Раньше HTTP-нода получала rate limit, тихо писала статус в лог и шла дальше по ветке ошибок. Синхронизация считалась "выполненной", хотя данные не обновились. Теперь в ноде явно проверяется код ответа: если {{ $json.statusCode === 429 }}, выполнение уходит в отдельную ветку с немедленным Telegram-уведомлением и остановкой. Никакого "тихого" завершения.
Всё это заняло два дня работы. Мог бы поставить в первый же день запуска проекта, но не поставил, потому что "и так работает". Теперь работает с мониторингом.
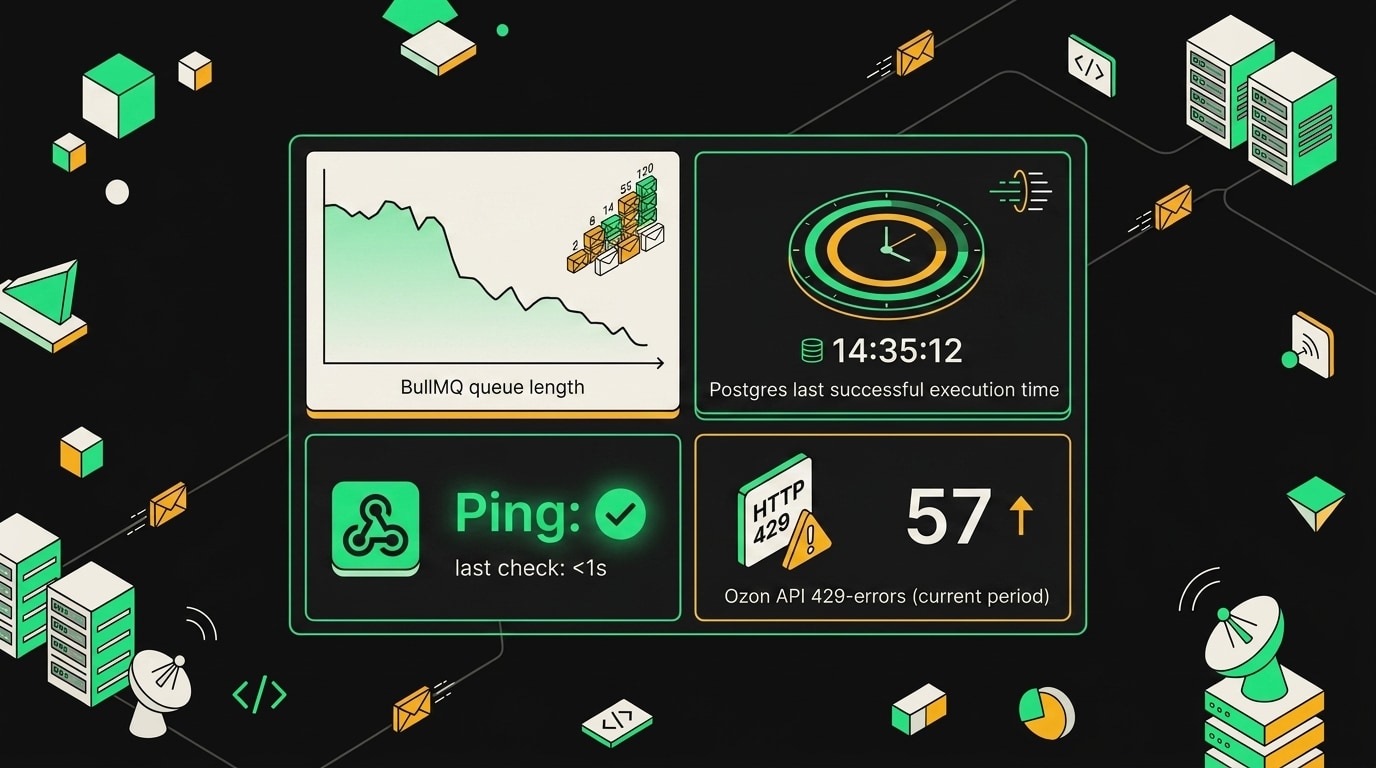
Алерт на очередь длиннее 500 задач сработал бы за 40 минут до инцидента, если бы существовал на тот момент.
Особенности Ozon API при обновлении остатков: лимиты и батчинг
Эндпоинт POST /v2/product/stocks принимает максимум 100 SKU за один запрос. Если передать больше, вернётся ошибка валидации. Молча не обрежет, не проигнорирует, именно ошибка. Поэтому батчинг здесь не оптимизация, а обязательное условие.
У Ozon API есть rate limit на количество запросов в минуту для одного API-ключа. К этому пределу при массовых обновлениях лучше не приближаться. Пауза 200-500 мс между запросами убирает риск внезапных 429 в моменты, когда инфраструктура Ozon сама под нагрузкой, а ваши задачи вдруг прилетают пачкой.
Отдельный момент касается stale-данных в очереди. После того как система восстановилась после сбоя, я не стал ждать следующего триггера. И правильно сделал: события в очереди образовались несколько часов назад и уже не отражали реальные остатки на складе. Обработать их означало бы записать в Ozon устаревшие значения. Пришлось запустить отдельный скрипт, который вычитал текущие остатки напрямую из источника и принудительно прогнал их через апи.
Здесь помогает одно свойство Ozon API: запросы к /v2/product/stocks идемпотентны по смыслу. Повторная отправка корректного значения не создаёт дублей в заказах или движениях товаров. Апи просто перезаписывает текущий остаток тем, что вы передали. Это и спасло ситуацию: скрипт восстановления мог гонять запросы без страха что-то испортить повторной отправкой.
Так что схема батчинга выглядит просто: разбиваешь список SKU на чанки по 100, каждый чанк отправляешь с паузой, ошибки логируешь и ставишь в очередь на повтор. Но логику формирования этих чанков строй на актуальных данных, а не на том, что лежало в очереди до сбоя.
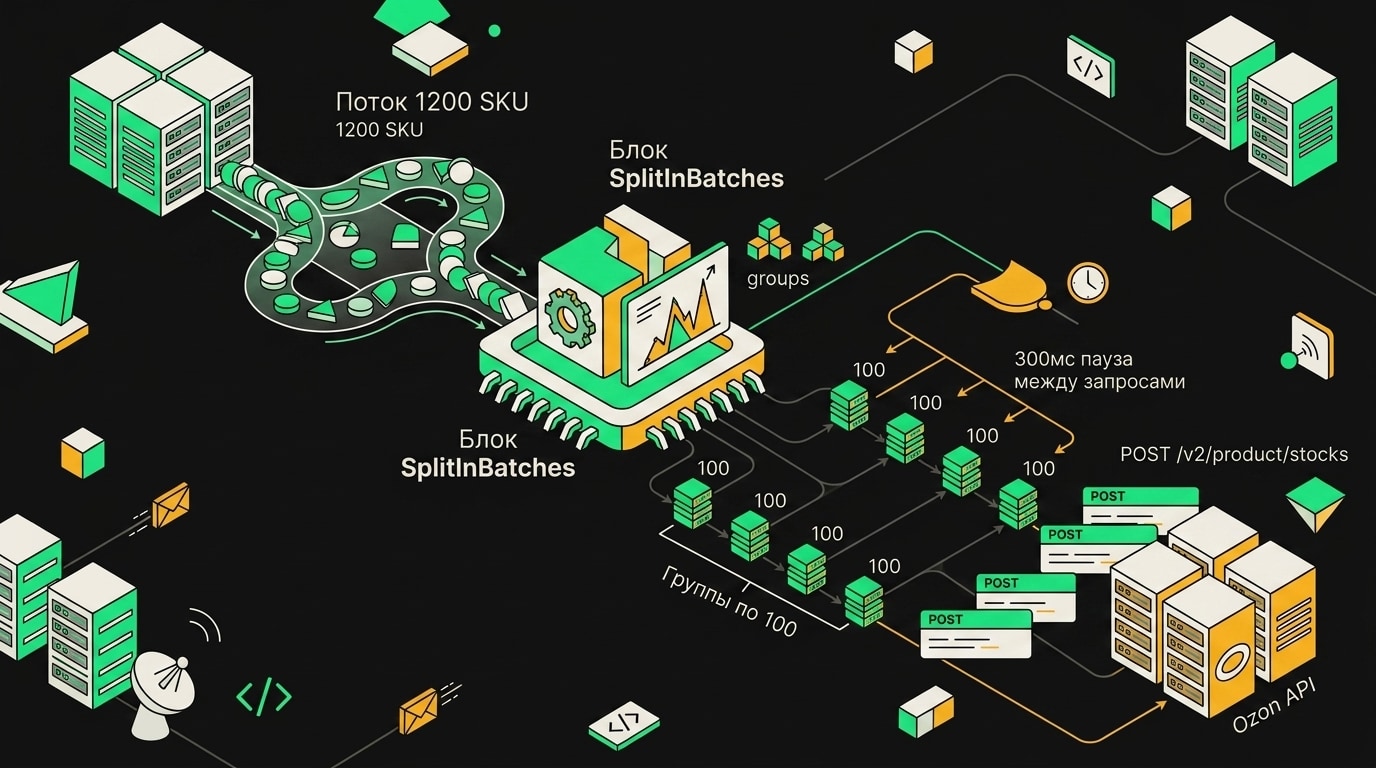
Группировка артикулов в батчи по 100 штук сократила число HTTP-запросов к Ozon API в 8 раз и убрала 429-е ошибки.
Выводы: что изменить в архитектуре n8n для production-синхронизации с маркетплейсами
Если у вас в production n8n в queue mode крутится на одном воркере без memory limits, это не "работает", это "ещё не упало". Под нагрузкой, когда Wildberries шлёт вебхуки пачками или когда запускается ночной пересчёт цен по большому каталогу, один процесс рано или поздно ложится. Два воркера, минимум. Иначе при падении первого очередь встаёт, и вы узнаёте об этом не из алертов, а из звонка менеджера в 9 утра. Отдельно про то, как webhook-трафик ложится на очередь при пиковой нагрузке и как это не уронить, написано подробнее.
NODE_OPTIONS=--max-old-space-size=4096 в docker-compose для воркера, не опциональная настройка. Без неё Node.js живёт в пределах дефолтных ~1.5 ГБ и падает при обработке больших пейлоадов. Воркфлоу с выгрузкой каталога Ozon на много тысяч позиций стабильно крашился именно по этой причине, пока я не выставил явный лимит.
По мониторингу: статус контейнера в Portainer ничего не говорит о том, что реально происходит с синхронизацией. Контейнер живёт, а последнее успешное выполнение было 6 часов назад, и вы об этом не знаете. Нужны две метрики: длина очереди в Redis (ключи bull:*:waiting) и timestamp последнего успешного execution для каждого критичного воркфлоу. Это можно тянуть через n8n API (GET /executions) и писать в Prometheus или хотя бы в простой Telegram-алерт по крону.
SplitInBatches стоит ставить везде, где обрабатываете больше 500 записей за раз. Батч по 100-200 позиций держит потребление памяти предсказуемым и одновременно решает проблему rate limits: между итерациями вставляете Wait на 0.5-1 секунду, и API маркетплейса перестаёт отвечать 429. Это не усложняет воркфлоу, просто добавляет один узел и одну паузу. Похожий подход с разбивкой на шаги хорошо показан в кейсе по построению воронки лидогенерации на n8n, где поэтапная обработка данных спасает от перегрева воркфлоу.
Теперь про снапшоты. Для синхронизации остатков с Ozon я перешёл на такую схему: после каждой успешной отправки воркфлоу пишет в Postgres строку с SKU, отправленным значением и временем. Если воркфлоу перезапускается после сбоя (или после того, как задача несколько часов пролежала в очереди), он не берёт данные из очереди, а делает свежий SELECT из источника и сравнивает с последним успешно отправленным значением. Только дифф идёт в API. Остаток, который вы поставили в очередь три часа назад, уже неактуален: склад успел отгрузить ещё несколько десятков единиц.
Итоговый чеклист для нормального production-стейта:
- Минимум два воркера с явными memory limits
- Мониторинг длины очереди и возраста последнего успешного execution
- SplitInBatches с паузами для любых массовых операций
- Postgres-снапшот последнего отправленного значения для остатков и