Почему workflow падают в production и никто не узнаёт вовремя
Классическая ситуация выглядит так: workflow отработал ночью, что-то пошло не так на третьем шаге, никаких уведомлений не прилетело. Утром клиент пишет, что данные за прошлую ночь не приехали. Идёшь в логи, видишь красный execution с 02:47, а данные уже либо потеряны, либо нужно восстанавливать вручную из источника.
n8n хранит execution logs по умолчанию. Это хорошо. Но он не кричит. Он просто записывает падение и ждёт, пока ты сам придёшь и посмотришь.
Три источника, которые дают больше всего тихих падений на практике.
Внешние API вернули неожиданный JSON. Сервис обновил схему ответа, добавил вложенность или переименовал поле. Твой workflow ожидает data.items[0].id, получает data.result.items[0].id, нода с Set или Function падает, всё останавливается. Это особенно неприятно с третьесторонними интеграциями, которые не версионируют API и не присылают changelog.
Лимит памяти при обработке больших файлов. Один из частых сценариев: workflow тянет большой объём данных через API с пагинацией, собирает всё в один JSON и передаёт дальше. При достаточно большом итоговом объёме Node.js может исчерпать доступную память, и процесс упадёт без внятного сообщения в UI. В логах будет просто статус "error" без трейса. Найти причину в таких случаях удаётся только после включения подробного логирования на уровне хоста.
Изменился формат входных данных. Webhook начал присылать поле amount как строку вместо числа. Или timestamp в другом формате. Нода проходит, но дальше в цепочке арифметика ломается тихо: "150" + 50 = "15050" в JavaScript никаких ошибок не бросает.
Теперь про разницу между self-hosted и Cloud. На self-hosted ты полностью контролируешь ресурсы, но и мониторинг на тебе. Если контейнер упал из-за OOM, n8n Cloud об этом не знает. Базовое поведение в обоих случаях одинаковое: упал execution, записалось в лог, уведомления зависят от того, настроил ли ты Error Workflow. Большинство не настраивает. Именно поэтому тихие падения в production остаются проблемой независимо от способа деплоя.
Проблема особенно острая, когда на n8n построены воронки лидогенерации или AI-ассистенты поддержки клиентов: там тихое падение ночью означает потерянные лиды или клиентов без ответа.

Узнавать о проблемах от клиентов, худший способ мониторинга продакшн-автоматизации.
Что такое Error Trigger и как он работает
В n8n есть специальная нода под названием Error Trigger. Она не делает ничего сама по себе: просто ждёт, пока где-то рядом что-то сломается.
Принцип работы прямой. Создаёшь отдельный workflow, ставишь Error Trigger стартовой нодой, и этот workflow становится обработчиком ошибок. Потом идёшь в каждый рабочий workflow, открываешь его настройки и в поле "Error Workflow" указываешь только что созданный обработчик. Всё. Теперь, если рабочий workflow падает на любой ноде, n8n автоматически запускает Error Workflow и передаёт туда данные об ошибке.
Что именно приходит в Error Trigger, видно из объекта:
{
"execution": {
"id": "1234",
"url": "https://your-n8n.com/execution/1234",
"retryOf": null,
"error": {
"message": "Unexpected token in JSON",
"stack": "SyntaxError: Unexpected token..."
},
"lastNodeExecuted": "HTTP Request",
"mode": "trigger"
},
"workflow": {
"id": "42",
"name": "Order Processing"
}
}
Здесь есть всё, что нужно для диагностики: имя и ID упавшего workflow, ID конкретного execution с прямой ссылкой на него, нода где случилась ошибка, текст и стек ошибки, timestamp режим запуска. По ссылке из поля url можно сразу перейти в интерфейс n8n и увидеть упавший execution со всеми входными данными.
Теперь про ограничение, которое часто упускают. Error Workflow не глобальный перехватчик. Ты привязываешь его к конкретному workflow через настройки, и каждый рабочий workflow поддерживает только одну привязку к Error Workflow. Если у тебя 20 рабочих workflow и ты хочешь единый обработчик для всех, нужно либо прописать его в каждом руками, либо установить глобальный дефолт на уровне всего инстанса через раздел настроек. По документации n8n, индивидуальная настройка workflow имеет приоритет над глобальной, если она задана.
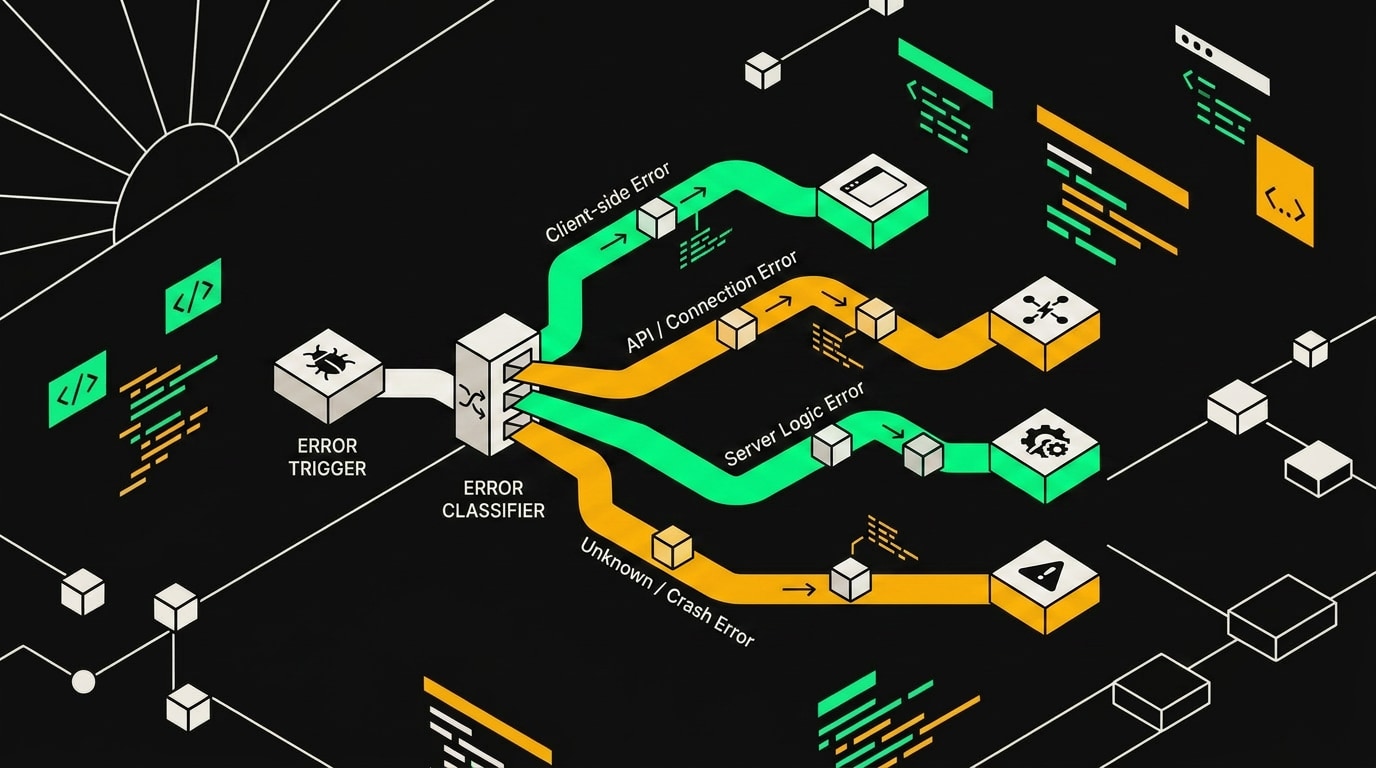
Error Trigger цепляется к любому воркфлоу в пространстве и перехватывает необработанные исключения.
Глобальный Error Workflow: одна точка сбора всех ошибок
В n8n есть настройка, которую большинство людей игнорирует месяцами: раздел настроек инстанса, где можно указать один workflow для перехвата падений всех остальных. Без этого каждый workflow живёт сам по себе, и ошибки либо уходят в никуда, либо ты прописываешь обработчик руками в каждом.
Я строю централизованный обработчик так. Стартовый узел: Error Trigger. Он получает объект с данными об упавшем workflow: название, ID, узел, на котором всё сломалось, и сообщение об ошибке. Дальше идёт Switch по полю, которое я добавляю в метаданные самих workflow через тег или переменную в имени, что-то вроде [CRITICAL] или [LOW] в названии. Switch смотрит на это, и критические ошибки летят в PagerDuty или Slack в канал #incidents, а всё остальное собирается в Google Sheets или Notion для разбора по утрам.
Главная выгода такого подхода даже не в централизации как таковой. Новый workflow, который кто-то создал вчера, автоматически попадает под мониторинг. Не надо ничего конфигурировать, не надо помнить добавить Error Trigger. Это меняет дефолт: раньше workflow по умолчанию молча падал, теперь по умолчанию о падении знаешь.
Но у схемы есть очевидная уязвимость. Если глобальный обработчик сам ломается из-за недоступности Slack API или кривого выражения в Switch, то все ошибки инстанса уходят в пустоту. Причём тихо. Ты об этом не узнаешь.
Решение в лоб: для самого Error Workflow прописывать отдельный обработчик, другой workflow попроще, который просто пишет в файл или базу данных. Что-то, что не зависит от внешних сервисов. Если нет желания городить второй уровень, то хотя бы гони метрику: внешний мониторинг типа UptimeRobot или Grafana должен видеть, что обработчик запускался в последние N часов. Если нет активности слишком долго и при этом в инстансе крутятся активные workflow, это уже сигнал.
Сам обработчик надо тестировать отдельно. У меня есть специальный workflow с именем [TEST] Error Generator, который намеренно падает по расписанию раз в сутки. Он проверяет, что цепочка уведомлений живая, и заодно служит smoke-тестом всей схемы.

Один глобальный error-воркфлоу рассылает алерты сразу в Telegram, Slack и на email без дублирования логики.
Алерты в Telegram: быстрый и рабочий способ
Telegram Bot API закрывает задачу алертов на 90% случаев. Порог входа низкий: создаёшь бота через @BotFather, получаешь токен, берёшь Chat ID своей группы или лички, и всё готово. Никаких платных планов, никакой регистрации сервисов.
Особенно важна одна деталь для self-hosted n8n без белого IP: бот отправляет сообщения сам в сторону Telegram, так что NAT и закрытые порты не мешают. Это не то же самое, что Telegram Trigger, где нужен публичный HTTPS для входящего webhook. Trigger на локальных инстансах работает через polling, и он нестабилен: пропускает события, теряет соединение после простоя. Для алертов используй именно исходящий бот, не Trigger.
В Error Workflow добавляешь ноду Telegram, указываешь Chat ID и составляешь сообщение. Формат MarkdownV2 даёт жирный текст и моноширинные блоки, но у него есть засада: спецсимволы ., (, ), - нужно экранировать обратным слешем, иначе Telegram вернёт ошибку 400. Если не хочешь с этим возиться, ставь просто Markdown (v1) или HTML, там правила проще.
Что точно должно быть в каждом алерте: имя workflow (иначе через неделю не вспомнишь, что упало), нода-виновник, первые 300 символов ошибки, прямая ссылка на execution и время по московскому поясу. Ссылка особенно ценна: кликнул, открыл, увидел полный стек прямо в n8n UI.
Вот рабочий шаблон для поля Message в ноде Telegram:
// Текст сообщения в Telegram-ноде (поле Message)
🔴 *Workflow упал*
*Workflow:* {{ $json.workflow.name }}
*Нода:* {{ $json.execution.lastNodeExecuted }}
*Ошибка:* {{ $json.execution.error.message.slice(0, 300) }}
*Ссылка:* {{ $json.execution.url }}
*Время:* {{ new Date().toLocaleString('ru-RU', {timeZone: 'Europe/Moscow'}) }}
$json.execution.url отдаёт прямую ссылку на конкретный execution автоматически. lastNodeExecuted показывает ноду, на которой процесс остановился. Это не всегда та нода, где реальная причина проблемы, но это хорошая точка входа для расследования.
Одна вещь, которую я добавляю поверх этого шаблона: поле с окружением. Если у тебя несколько инстансов (staging и prod), то без метки *Env:* PROD алерты из разных инстансов в одном чате сливаются в кашу. Добавь хардкодом или через переменную окружения через $env.

Алерт в Telegram приходит за секунды и содержит имя воркфлоу, время сбоя и текст исключения.
Логирование execution: что хранит n8n и как это читать
Открываешь раздел Executions в боковом меню, и там лежит история всех запусков. Фильтры по статусу: Error, Success, Waiting. Звучит просто, пока не обнаруживаешь, что половина упавших запусков туда вообще не попала.
По умолчанию n8n сохраняет не всё. В настройках (Settings -> Workflow -> Saving) три отдельных тумблера: Save Manual Executions, Save Successful Executions, Save Failed Executions. Save Failed включён по умолчанию, Save Successful, нет. Это разумно для базовой установки, но в production нужно сознательно решить, что ты хочешь видеть. Моя рекомендация: Failed включать всегда и везде, Successful, только если строишь аудит или дебажишь конкретный сценарий, иначе база пухнет быстро.
Retention period настраивается через переменную окружения EXECUTIONS_DATA_MAX_AGE (в часах). Если не выставить, логи хранятся вечно. На живом инстансе с десятками workflow через месяц это ощутимо.
Теперь о том, как читать упавший execution. Кликаешь на строку с ошибкой, открывается полная карта запуска. Каждая нода показывает Input и Output на момент выполнения. Точка разрыва выделена красным, и справа видно сообщение об ошибке. Но самое ценное, Input той ноды, где всё сломалось. Именно там понимаешь, какие данные пришли: пустой массив вместо объекта, неожиданный null в поле, строка там где ждали число. Это убирает большую часть гадания при отладке.
Отдельная история, SQLite против PostgreSQL. Self-hosted n8n по умолчанию ставится на SQLite, и для личного использования или небольшой команды это нормально. При росте числа активных workflow и частых запусках SQLite может начать тормозить на чтении истории выполнений: запросы к Executions замедляются, UI зависает при фильтрации. PostgreSQL решает это структурно, индексы работают как положено, конкурентные запросы не блокируют друг друга. Если у тебя production-инстанс на SQLite с растущей нагрузкой, миграция на PostgreSQL, это устранение будущей проблемы, а не оптимизация.
Try/Catch внутри workflow: обработка ошибок на уровне нод
Continue on Fail, это флажок в настройках любой ноды n8n. Когда он включён, провал ноды не останавливает весь workflow. Вместо этого n8n кладёт в output объект с полем error, и выполнение идёт дальше по цепочке.
Звучит удобно. Но здесь легко наступить на грабли, если включать эту опцию везде подряд.
Где Continue on Fail оправдан. Допустим, у вас есть шаг обогащения данных: вы дёргаете Clearbit или какой-то сторонний API, чтобы добавить к лиду дополнительную информацию. Если запрос упал, критичного ничего нет. Лид уже существует, сделка уже создана. Обогащение не получилось, ну и ладно, запишем в лог и двигаемся дальше. Такую логику удобно применять, например, в воронках квалификации лидов, где обогащение опционально.
Где Continue on Fail категорически не подходит. Транзакционные операции: списание, создание заказа, отправка подтверждения пользователю. Если нода списания упала, а workflow продолжил выполнение и отправил письмо "ваш заказ принят", у вас проблема хуже, чем просто упавший процесс. Частичное выполнение в таких сценариях опаснее полного падения, потому что полное падение хотя бы заметно.
Паттерн ветвления через IF
После ноды с Continue on Fail ставите IF-ноду с одним условием:
// Left Value:
{{ $json.error }}
// Condition: Is Not Empty
Если поле error не пустое, вы попали в True-ветку. Это ваш catch. Если пустое, идёте по False-ветке, нормальный флоу продолжается.
True-ветка может делать что угодно: слать уведомление в Slack, останавливать workflow через Stop and Error, или писать запись в Google Sheets с полями timestamp, workflow_id, error.message, error.stack. Последнее особенно полезно, если у вас batch-обработка, где несколько из сотни записей упали, но останавливать весь прогон из-за них нецелесообразно.
Комбинация: Continue on Fail + таблица ошибок
Конкретный пример, который я использую для импорта данных из разных источников. Каждая нода интеграции настроена с Continue on Fail. После каждой стоит IF по $json.error. True-ветка пишет строку в Airtable: что упало, когда, с каким сообщением, какой был входной payload (через $json предыдущей ноды). Раз в день можно открыть эту таблицу и посмотреть, где системно что-то трещит, а не разбираться с эпизодическими падениями вручную.
Это не замена нормальному Error Workflow, который настраивается на уровне всего workflow в n8n. Это дополнение для ошибок, которые вы сознательно решили не считать фатальными, но хотите отслеживать постфактум.
Одна деталь, которую легко пропустить: если у вас в цепочке несколько нод с Continue on Fail подряд, $json.error перезаписывается на каждом шаге. До IF-проверки доживает только ошибка последней ноды. Если нужно поймать ошибку конкретной ноды, IF ставьте сразу после неё, не откладывайте.
Внешний мониторинг: когда сам n8n недоступен
Есть один слепой угол во всех схемах алертинга внутри n8n. Error Trigger, catch-ноды, кастомные уведомления, всё это работает только пока работает сам n8n. Если инстанс упал, процесс завис или контейнер перестал отвечать, никакой workflow не сработает. Нужен watchdog снаружи.
Самый простой паттерн называется Heartbeat. Workflow по Schedule Trigger раз в 5 минут делает HTTP Request на внешний сервис-монитор. Пинг пришёл, сервис знает, что n8n жив. Пинг пропал дольше заданного порога, сервис сам шлёт алерт. Логика перевёрнутая по сравнению с обычным мониторингом, и в этом её сила.
Я настраиваю это через Healthchecks.io. Бесплатный тариф даёт до 20 checks, чего хватает для большинства self-hosted инсталляций. Создаёшь check, задаёшь период (5 минут) и grace period (например, 2 минуты), получаешь уникальный URL. В n8n добавляешь Schedule Trigger на каждые 5 минут, за ним HTTP Request с методом GET на этот URL. Всё. Если n8n не пришлёт пинг в течение 7 минут, Healthchecks.io отправит письмо, Slack-сообщение или SMS, смотря что настроишь.
UptimeRobot работает по другому принципу: он сам ходит на твой URL и проверяет HTTP-статус. Для мониторинга n8n-интерфейса это подходит, но не заменяет Heartbeat, потому что n8n может отвечать 200 на health-check, при этом не выполнять workflows из-за проблем с воркерами или очередью.
Второй подход: внешний скрипт проверяет n8n через API. Endpoint GET /api/v1/executions с параметрами status=error и фильтром по времени позволяет раз в N минут вытащить список упавших executions за последний час. Скрипт на Python или bash, cron на отдельной машине, и у тебя независимый наблюдатель. Нужен API-ключ с правами на чтение, создаётся в Settings → API.
Для тех, кто держит n8n в self-hosted и уже имеет Prometheus с Grafana: начиная с версии 1.x n8n экспортирует метрики через /metrics. Там есть счётчики выполнений по статусам, данные о воркерах, длина очереди. Подключаешь Prometheus scrape, строишь алерт в Grafana на рост n8n_workflow_failed_total или на отсутствие свежих данных вообще. Это самый информативный вариант, но и самый трудоёмкий в настройке.
Минимальная рабочая схема для небольшого проекта: Heartbeat на Healthchecks.io плюс UptimeRobot на основной домен. Двадцать минут настройки, ноль рублей в месяц, и ты узнаешь о падении раньше, чем это заметят пользователи.
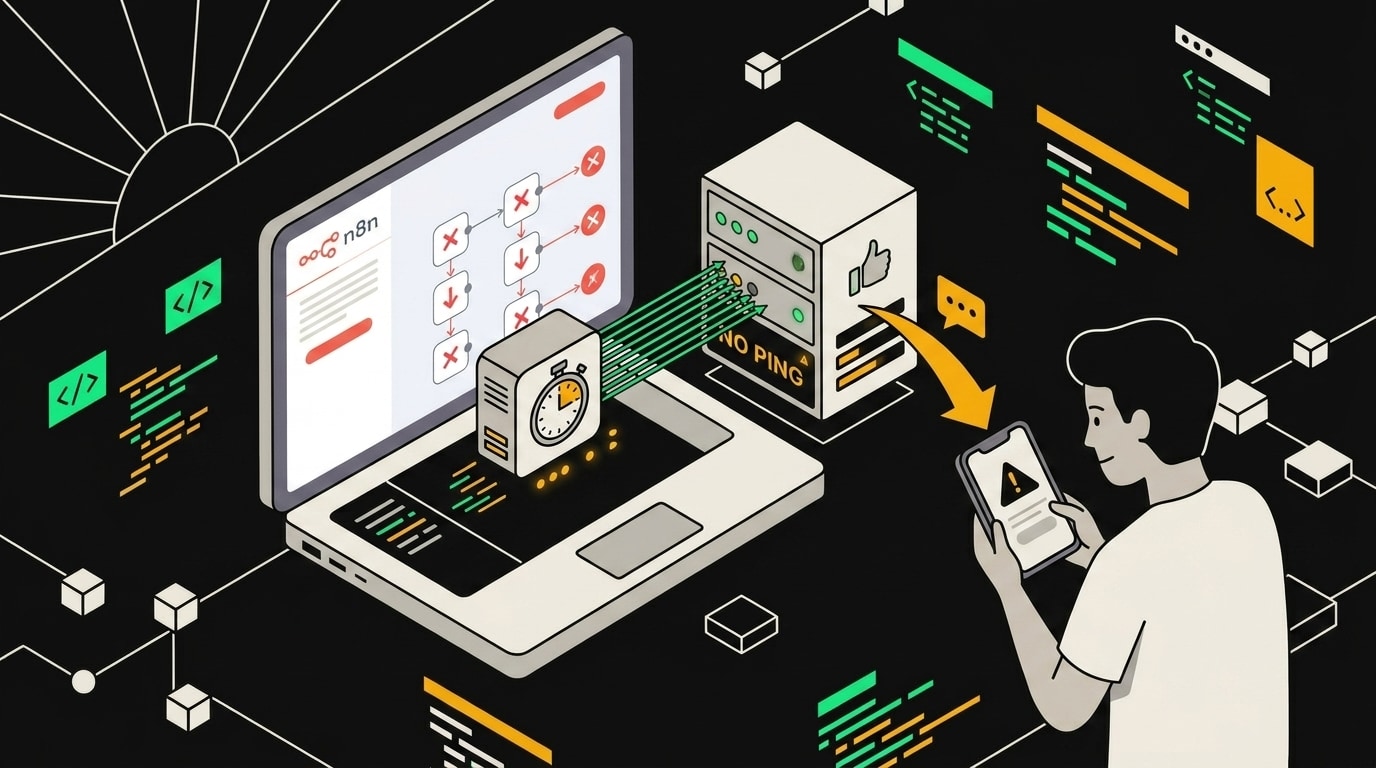
Heartbeat-пинг каждые пять минут позволяет внешнему watchdog заметить, что n8n вообще перестал работать.
Структура production-ready Error Workflow
Базовый паттерн, который я использую, выглядит так: Error Trigger собирает падение, Code-нода парсит и обогащает данные об ошибке, Switch разветвляет по типу, дальше параллельные ветки уведомлений. Каждый этап делает ровно одну вещь. Это важно, потому что Error Workflow сам не должен падать.
Классификация в Code-ноде
Первое, что нужно сделать с пришедшим событием, это понять, что именно сломалось. Вот нода, которую я ставлю сразу после Error Trigger:
const errorMsg = $json.execution.error.message.toLowerCase();
const workflowName = $json.workflow.name;
let severity = 'low';
let errorType = 'unknown';
if (errorMsg.includes('429') || errorMsg.includes('rate limit')) {
severity = 'medium';
errorType = 'rate_limit';
} else if (errorMsg.includes('401') || errorMsg.includes('403')) {
severity = 'high';
errorType = 'auth';
} else if (workflowName.toLowerCase().includes('payment')) {
severity = 'critical';
errorType = 'business_critical';
} else if (errorMsg.includes('json') || errorMsg.includes('unexpected token')) {
severity = 'medium';
errorType = 'data_format';
}
return [{ json: { ...$json, severity, errorType } }];
Логика намеренно плоская. Auth-ошибки (401/403) всегда high, потому что это либо протухший токен, либо кто-то отозвал доступ. Rate limit (429) это medium: неприятно, но не катастрофа. Всё, что касается payment-воркфлоу, идёт в critical независимо от типа ошибки. Бизнес-контекст важнее технического.
Switch по severity и маршрутизация
После Code-ноды Switch смотрит на поле severity и расходится на три ветки.
critical и high уходят в Telegram-бот и на email одновременно. Я не выбираю один канал. Если упал payment-воркфлов в воскресенье в 2 ночи, письмо на почту никто не увидит вовремя. Та же история с AI-ботами поддержки, которые обслуживают клиентов в нерабочие часы: тихое падение там стоит дороже всего.
medium и low пишутся только в Google Sheets или Notion-таблицу. Никаких пушей. Это данные для разбора на следующий рабочий день.
Retry для timeout-ошибок
Для errorType === 'timeout' добавляю отдельную ветку с HTTP Request-нодой, которая дёргает n8n API:
POST /api/v1/executions/{{ $json.execution.id }}/retry
Перезапуск делаю с задержкой в 60 секунд через Wait-ноду. Максимум две попытки. Если после второй снова timeout, уже лечу в Telegram.
Дедупликация алертов
Это больное место. Если воркфлоу падает каждые 30 секунд (например, зациклился scheduler), Error Workflow будет слать уведомления с той же частотой. Канал превращается в мусор, и реальные алерты теряются.
Решение через Static Data. В начале Error Workflow ставлю Code-ноду с такой проверкой:
const workflowId = $json.workflow.id;
const now = Date.now();
const cooldown = 15 * 60 * 1000; // 15 минут
const staticData = $getWorkflowStaticData('global');
const lastAlert = staticData[`last_alert_${workflowId}`] || 0;
if (now - lastAlert < cooldown) {
return []; // пустой массив останавливает выполнение
}
staticData[`last_alert_${workflowId}`] = now;
return [$json];
Static Data сохраняется между запусками одного воркфлоу. За 15 минут один и тот же упавший источник даст максимум один алерт. Цифру подбирайте под свой контекст: для критических воркфлоу я ставлю 5 минут, для фоновых синхронизаций 30.
Ещё один момент: Error Trigger сам по