

Почему webhook-события пропадают и когда это становится проблемой
По умолчанию n8n обрабатывает входящий webhook синхронно. Пришёл HTTP-запрос, запустился workflow, дождался ответа, закрыл соединение. Это работает нормально, пока событий немного.
Проблема начинается при всплеске. Допустим, у вас флеш-продажа на 20 минут, и Stripe шлёт сотни payment.succeeded в минуту. n8n получает первые запросы, запускает под каждый workflow, но process pool не резиновый. Новые запросы встают в очередь на уровне HTTP-сервера. Очередь растёт. Stripe ждёт ответ максимум 30 секунд, потом фиксирует таймаут и помечает доставку как неудавшуюся. При этом повторной попытки по умолчанию не будет: часть провайдеров умеет ретраить, но GitHub Webhooks и многие CRM просто дропают запрос и идут дальше.
То же самое происходит с CI/CD-системами при массовом пуше. Если в репозитории одновременно закрыли 80 pull request'ов, GitHub отправит 80 событий почти мгновенно. Каждое должно дёрнуть workflow, но если каждый workflow занимает несколько секунд (запрос к Jira, обновление в Slack), сервер захлёбывается.
Самое неприятное здесь: потеря происходит до того, как n8n успел зафиксировать execution. Вы заходите в историю запусков, там чисто. Никакого failed, никакого error. Событие просто не существует с точки зрения системы. Отлаживать это по логам n8n бессмысленно, нужно смотреть на стороне отправителя.
Это принципиально отличается от ошибок внутри workflow, где нода упала, выбросила исключение, execution записался со статусом error. Там хотя бы есть что разбирать. Здесь данные испаряются на входе, и единственный способ это заметить: сравнить количество событий в дашборде Stripe или GitHub с количеством executions в n8n за тот же период.
Пакетные вызовы от внешних CRM дают похожую картину, но с другим профилем нагрузки. Система вроде HubSpot или Salesforce при синхронизации может отправить несколько тысяч contact.updated за несколько минут. Это не спайк, а плотный поток. n8n справляется с началом, потом начинает проседать, и хвост потока срезается. Если вы строите на n8n AI-ассистента поддержки клиентов, именно такой сценарий с CRM-синхронизацией чаще всего становится первым узким местом.
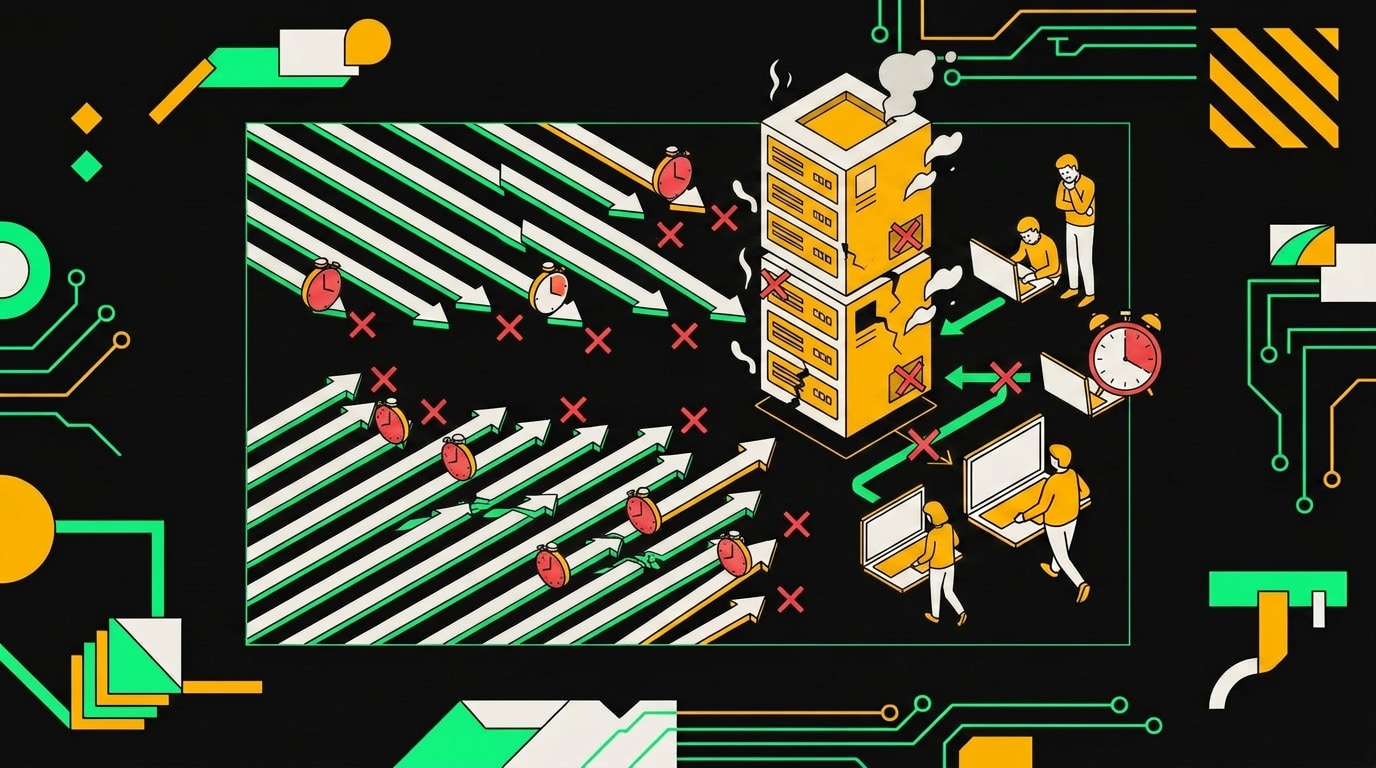
При пиковой нагрузке вебхук не успевает ответить за 30 секунд, и платёжный провайдер помечает транзакцию как неуспешную.
Архитектура Queue Mode в n8n: что это даёт и что требует
Queue Mode меняет модель выполнения радикально. В стандартном режиме один процесс делает всё: принимает webhook, планирует, исполняет. При росте нагрузки этот процесс становится узким местом, и никакое горизонтальное масштабирование не помогает, потому что SQLite и однопроцессный event loop просто не рассчитаны на параллельное исполнение десятков workflows.
Queue Mode разрезает этот монолит на две роли. Main-процесс принимает входящие запросы, кладёт job в очередь и на этом заканчивает. Worker-процессы сидят на другом конце и тянут jobs по мере готовности. Каждый worker независим: упал один, остальные продолжают работать.
Под очередью стоит BullMQ поверх Redis. Main пишет задания в Redis, workers читают оттуда, там же хранится состояние очереди. Redis 6.2 минимальная версия, BullMQ использует команды, которых в более ранних версиях нет.
Хранилище тоже меняется. SQLite в Queue Mode не работает. Нужен PostgreSQL: все execution records, их статусы и логи пишутся туда. Это важно не только потому что PostgreSQL держит конкурентную запись, но и потому что workers должны видеть общее состояние, а не каждый свою локальную базу.
Минимальный стек для Queue Mode выглядит так:
services:
n8n-main:
image: n8nio/n8n
environment:
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- QUEUE_HEALTH_CHECK_ACTIVE=true
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
n8n-worker:
image: n8nio/n8n
command: n8n worker
environment:
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
Обрати внимание: у worker нет открытых портов и он не обрабатывает webhooks. Команда n8n worker запускает именно consumer-процесс. Main и worker используют одинаковые переменные для Redis и Postgres, потому что работают с одной очередью и одной базой.
QUEUE_HEALTH_CHECK_ACTIVE=true включает endpoint /healthz на main-процессе, который проверяет соединение с Redis. Без этого load balancer или оркестратор не смогут нормально проверять готовность инстанса.
Queue Mode рекомендуется для self-hosted production, когда нагрузка такова, что стандартный режим не справляется: workflows долгие, webhooks идут пачками, или нужен zero-downtime при обновлениях (workers можно перезапускать по одному). При небольшом трафике можно обойтись обычным режимом и сэкономить на инфраструктуре. Актуальные рекомендации по порогу нагрузки смотри в официальной документации n8n, они уточнялись с каждым крупным релизом.
Главное требование, которое часто недооценивают: Redis должен быть persistent. Если Redis потеряет данные при рестарте, все pending jobs исчезнут вместе с ними. appendonly yes в конфиге Redis или managed Redis с persistence обязательны.
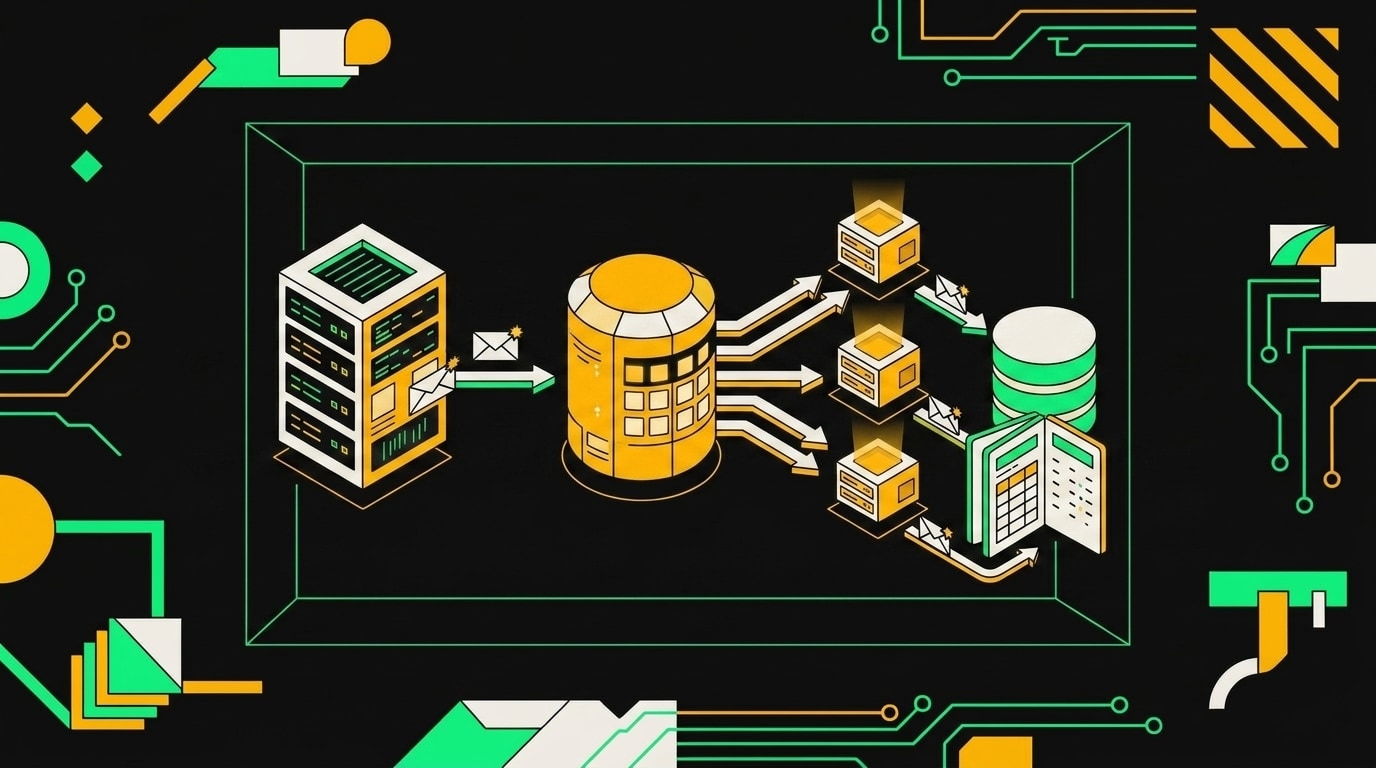
Продюсер кладёт задачу в Redis, воркеры забирают её асинхронно и записывают результат в БД уже без участия HTTP-запроса.
Настройка Redis и BullMQ под production-нагрузку
Redis без persistence в production-окружении для очередей задач, это замаскированная бомба замедленного действия. Падение процесса, OOM-killer, случайный redis-cli shutdown без SAVE, и все jobs, которые лежали в BullMQ-очереди на обработку, исчезают. Webhook пришёл, n8n его принял, положил в очередь, Redis упал, воркер поднялся: задача нигде. Клиент не получил ответа, данные не записались, алерт не ушёл.
Минимальный конфиг, с которого я начинаю:
# redis.conf для production
appendonly yes
appendfsync everysec
save 60 1000
maxmemory 2gb
maxmemory-policy noeviction
tcp-keepalive 300
appendonly yes включает AOF. appendfsync everysec, это компромисс: сброс на диск раз в секунду, максимальная потеря данных при краше составит одну секунду работы. Можно поставить always, но тогда каждая операция записи ждёт fsync, и производительность падает в разы. save 60 1000 добавляет RDB-снепшот: если за 60 секунд произошло больше 1000 изменений, Redis сбрасывает снепшот на диск. AOF восстанавливает данные точнее, RDB восстанавливается быстрее. Вместе они дают нормальную защиту.
maxmemory-policy noeviction, второй критичный параметр. По умолчанию Redis работает с политикой noeviction только если вы явно задали maxmemory. Без этой связки при исчерпании памяти Redis начнёт выбрасывать ключи по одной из eviction-стратегий, и jobs в очереди попадут под раздачу точно так же, как любые другие ключи. С noeviction Redis просто вернёт ошибку при попытке записать новые данные при полной памяти, это лучше, чем молчаливая потеря задач.
Под размер maxmemory ориентируйтесь на пиковую глубину очереди. Job в BullMQ занимает от 1 до нескольких килобайт в зависимости от payload. Очередь в 100 000 jobs с payload по 5 KB, это 500 MB только под данные очереди, плюс служебные структуры BullMQ, плюс другие ключи. 2 GB, разумная отправная точка для среднего инстанса n8n.
На стороне n8n две переменные окружения прямо влияют на поведение BullMQ при проблемных jobs:
QUEUE_BULL_MAX_STALLED_COUNT=2
QUEUE_RECOVERY_INTERVAL=5000
QUEUE_BULL_MAX_STALLED_COUNT определяет, сколько раз воркер может "потерять" job (взял в обработку, не прислал heartbeat, job считается зависшей) до того, как BullMQ переведёт её в failed. Значение 2 означает: два раза job уходит обратно в очередь на повтор, на третий, failed. По умолчанию там 1, и при кратковременной нестабильности сети между воркером и Redis задачи сразу падают в failed без шанса на ретрай.
QUEUE_RECOVERY_INTERVAL, интервал в миллисекундах, с которым BullMQ проверяет stalled jobs. 5000 ms, раз в пять секунд. Слишком маленькое значение создаёт лишнюю нагрузку на Redis при большой очереди.
Мониторить это всё в реальном времени удобнее всего через Bull Board. В n8n Enterprise встроен собственный UI для очередей, но в community-версии Bull Board разворачивается отдельным сервисом и даёт ту же картину: глубина очереди, active jobs, stalled, failed с трейсбеком. Если вы до сих пор определяете состояние очереди по логам grep, это потеря времени, которую не оправдывает ничто.
Масштабирование workers: сколько их нужно и как считать
По умолчанию один worker берёт 10 concurrent jobs. Это значение контролирует переменная QUEUE_WORKER_CONCURRENCY. Звучит просто, но именно здесь чаще всего ошибаются при планировании ёмкости.
Считать нужное количество workers удобно по одной формуле:
workers = (пиковый RPS × среднее время выполнения в секундах) / QUEUE_WORKER_CONCURRENCY
Конкретный пример: пиковая нагрузка 200 RPS, среднее время выполнения workflow 5 секунд, concurrency по умолчанию 10. Подставляем: 200 × 5 = 1000 слотов в полёте одновременно. Делим на 10, получаем 100 workers. Это не максимум на случай катастрофы, а базовая цифра для нормальной работы без накопления очереди.
Формула выводится из закона Литтла: среднее число задач в системе равно интенсивности входящего потока, умноженной на среднее время обслуживания. Ничего экзотического, просто теория очередей применительно к конкретному параметру concurrency.
В Kubernetes всё это масштабируется через HPA, и здесь есть нюанс. CPU workers почти всегда выглядит нормально: они ждут I/O, практически не нагружают процессор, и автоскейлер по CPU просто не среагирует вовремя. Правильная метрика для HPA: глубина очереди из Redis. Как только очередь начинает расти, это сигнал добавить pods. Настраивается через KEDA или кастомные метрики в Prometheus с экспортером для Redis.
Stateless-природа workers делает горизонтальное масштабирование очень дешёвым. Новый pod поднялся, подключился к Redis и сразу начал тянуть jobs. Никакого coordination overhead, никакого downtime. Можно добавлять workers прямо под нагрузкой и убирать обратно, когда пик прошёл, без каких-либо специальных процедур graceful handoff: текущий job досчитается до конца, и pod завершится чисто.
Одна вещь, которую стоит держать в голове при выборе concurrency: если workflow делает много HTTP-запросов или обращений к базе, высокая concurrency на один worker даёт хорошую утилизацию. Если workflow CPU-bound (генерация отчётов, обработка изображений), concurrency 10 может просто перегреть pod, и лучше снизить до 3-4, зато добавить больше pods.
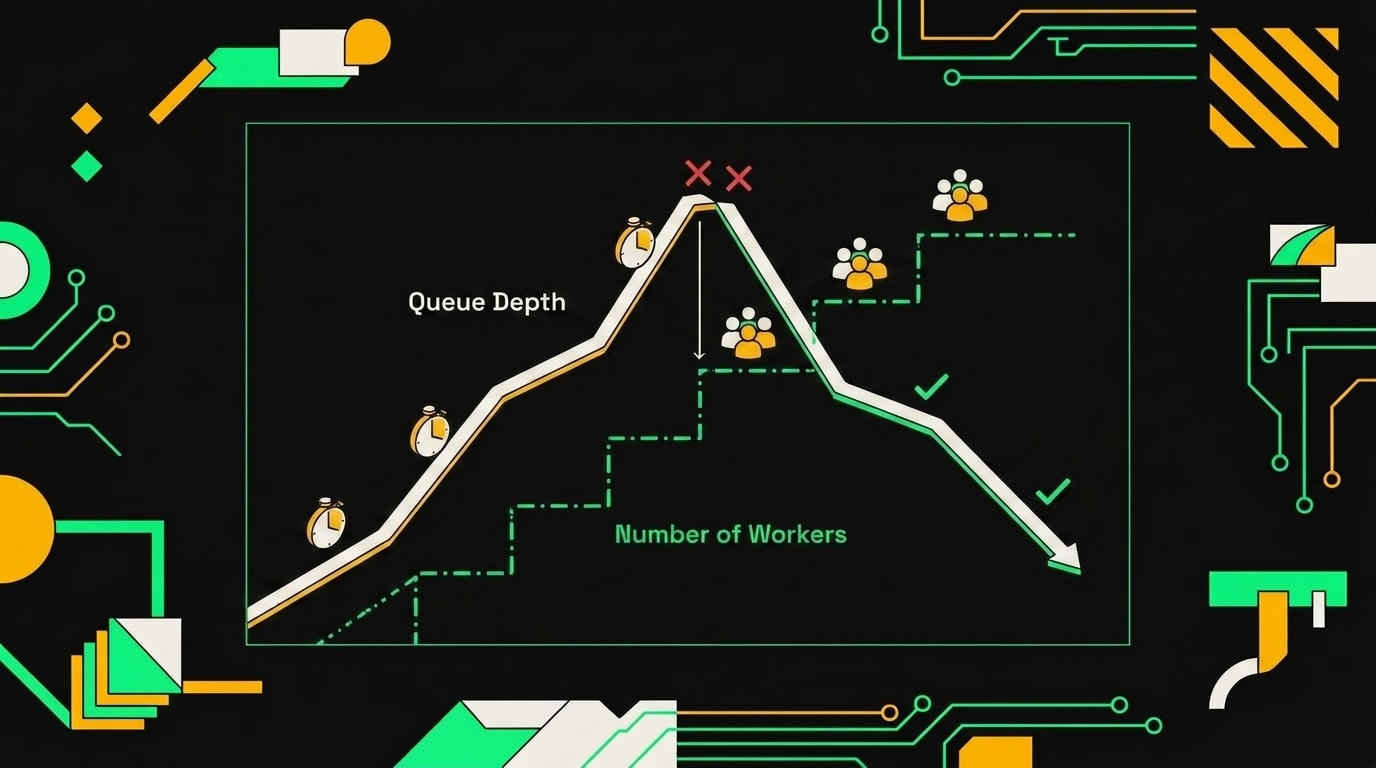
С четырьмя воркерами очередь вырастает до 12 000 задач за минуту, с шестнадцатью, стабилизируется около нуля.
Retry-политика и backpressure: как настроить повторные попытки без шторма
Самый быстрый способ уронить Redis-очередь под нагрузкой: настроить retry без jitter и смотреть, как все 500 упавших jobs пытаются перезапуститься ровно в одну секунду. Это называется thundering herd, и BullMQ не защищает от него автоматически.
Exponential backoff в BullMQ работает просто: первая повторная попытка через 1 секунду, вторая через 2, третья через 4. Каждый следующий retry удваивает задержку. Это убирает пиковую нагрузку при массовых сбоях, но только если jobs не стартовали одновременно. Если они стартовали в одну секунду (например, пришёл burst вебхуков), они и упадут в одну секунду, и начнут retry синхронно. Jitter разбивает эту синхронизацию: к задержке добавляется случайная дельта, и jobs рассыпаются по времени.
Базовая конфигурация через n8n-nodes-bullmq выглядит так:
{
"attempts": 5,
"backoff": {
"type": "exponential",
"delay": 1000
},
"removeOnComplete": 100,
"removeOnFail": 500
}
removeOnComplete: 100 означает, что Redis хранит только последние 100 завершённых jobs. Без этого параметра очередь растёт бесконечно и в какой-то момент Redis начинает есть всю доступную RAM. removeOnFail: 500 оставляет достаточно контекста для дебага, но не превращает failed-список в свалку за три месяца.
Через переменную окружения QUEUE_BULL_SETTINGS в n8n можно задать глобальные defaults: это удобно, если у тебя много workflows и ты не хочешь настраивать каждый нод вручную. Но программное управление через кастомный нод даёт больше контроля: разные workflows могут иметь разную политику retry в зависимости от критичности операции. Например, при построении воронки лидогенерации на n8n входящие лиды из форм часто приходят пачками именно в часы пик, и именно там retry без jitter бьёт сильнее всего.
Backpressure часто забывают, и зря. Если очередь в Redis уже содержит 10 000 jobs, добавление новых только откладывает проблему: workers не успевают, jobs копятся, память растёт. Правильное поведение main-инстанса в такой ситуации: отвечать клиенту кодом 429 (слишком много запросов) или 503, а не молча принимать job в очередь. Клиент получает сигнал и может реализовать собственный retry на своей стороне. Это честнее, чем тихо съедать запрос и давать клиенту ложное 200 OK.
Про 200 OK отдельно. Webhook-нод в n8n по умолчанию ждёт завершения workflow и только потом отвечает. При любой нагрузке это катастрофа: соединение висит, клиент ждёт таймаута, и у тебя образуется очередь не в Redis, а в открытых TCP-соединениях. Включи режим "Respond immediately" в webhook-ноде. Тогда n8n отвечает 200 OK сразу после постановки job в очередь, соединение закрывается, и workflow выполняется асинхронно. Клиент не ждёт, workers работают в своём темпе.
Практический порог для backpressure зависит от твоей инфраструктуры. 10 000 jobs как верхняя граница подходит для типичного сетапа с 4-8 workers. Если workers больше или jobs короткие (под секунду), порог можно поднять. Мониторь LLEN нужных ключей в Redis и настраивай алерт, когда очередь пересекает 70% от порога, а не 100%.
Dead Letter Queue: что делать с событиями, которые не обработались
Job падает в failed после последней retry-попытки. В BullMQ он там и остаётся: висит в failed-списке Redis, никуда не движется, никого не уведомляет. Если за этим списком никто не следит, событие просто исчезает из процесса.
В RabbitMQ ситуация лучше спроектирована. Там есть Dead Letter Exchange (DLX) на уровне брокера: очередь сама знает, куда отправить сообщение при отклонении или истечении TTL. В BullMQ такого нет, поэтому паттерн собирается вручную через слушатель события failed на worker-е и отдельную очередь-приёмник.
Разберу оба варианта.
RabbitMQ: DLX на уровне очереди
Самый чистый способ: при объявлении основной очереди сразу указать, куда уходят мёртвые сообщения.
// RabbitMQ: объявление DLX при создании основной очереди (Node.js amqplib)
await channel.assertQueue('n8n.events', {
durable: true,
arguments: {
'x-dead-letter-exchange': 'n8n.dlx',
'x-message-ttl': 60000,
'x-max-retries': 3
}
});
await channel.assertExchange('n8n.dlx', 'direct', { durable: true });
await channel.assertQueue('n8n.dlq', { durable: true });
await channel.bindQueue('n8n.dlq', 'n8n.dlx', '');
Что тут происходит: очередь n8n.events знает про n8n.dlx. Если сообщение отклонено (nack без requeue), истёк TTL или превышено количество доставок, RabbitMQ сам перекладывает его в DLX, а оттуда по биндингу в n8n.dlq. Никакого кода на уровне приложения для этой маршрутизации не нужно.
Обрати внимание: x-max-retries сам по себе не стандартный параметр RabbitMQ. Реальный механизм ограничения числа доставок здесь: x-delivery-limit (доступен в RabbitMQ 3.12+ через quorum queues) или ручной подсчёт через заголовок x-death в теле сообщения на стороне consumer-а.
Схема с n8n
Флоу выглядит так: n8n принимает входящий webhook, публикует событие в n8n.events через ноду RabbitMQ. Consumer обрабатывает. Если обработка падает, consumer делает nack с requeue: false. Сообщение уходит в DLQ.
Дальше запускается отдельный n8n-воркфлоу. Его триггер: нода RabbitMQ Trigger, подключённая к очереди n8n.dlq. Этот воркфлоу не пытается повторно обработать событие автоматически. Его задача: собрать данные и сообщить о проблеме.
Минимальная реакция в этом воркфлоу:
- Нода RabbitMQ Trigger читает сообщение из
n8n.dlq - Нода Slack отправляет уведомление с телом события, routing key и причиной (если она есть в заголовке
x-death) - Опционально: нода HTTP Request создаёт тикет в Linear или Jira
Сообщение в Slack должно содержать достаточно данных, чтобы человек мог вручную запустить повтор: само тело события, время первой попытки, количество смертей из заголовка x-death[0].count.
BullMQ: слушатель failed
Если брокер Redis, а не Rabbit, DLX нет. Но паттерн воспроизводится:
worker.on('failed', async (job, err) => {
if (job.attemptsMade >= job.opts.attempts) {
await dlqQueue.add('dead', {
originalJob: job.data,
error: err.message,
failedAt: new Date().toISOString()
});
}
});
dlqQueue здесь: отдельный экземпляр Queue из BullMQ, подключённый к тому же Redis. Событие failed стреляет на каждой неудачной попытке, поэтому проверка attemptsMade >= attempts обязательна: нужно класть в DLQ только после последней попытки, не после каждой.
Дальнейшая обработка аналогична: отдельный worker читает dlqQueue и отправляет уведомление.
Что точно не стоит делать
Не настраивай автоматический повтор из DLQ без анализа причины ошибки. Если событие умерло из-за бага в коде, повтор просто снова положит его в DLQ. Автоповтор имеет смысл только для временных сбоев (таймаут внешнего API, недоступность БД), и только если причину можно отличить программно по типу ошибки или коду ответа.
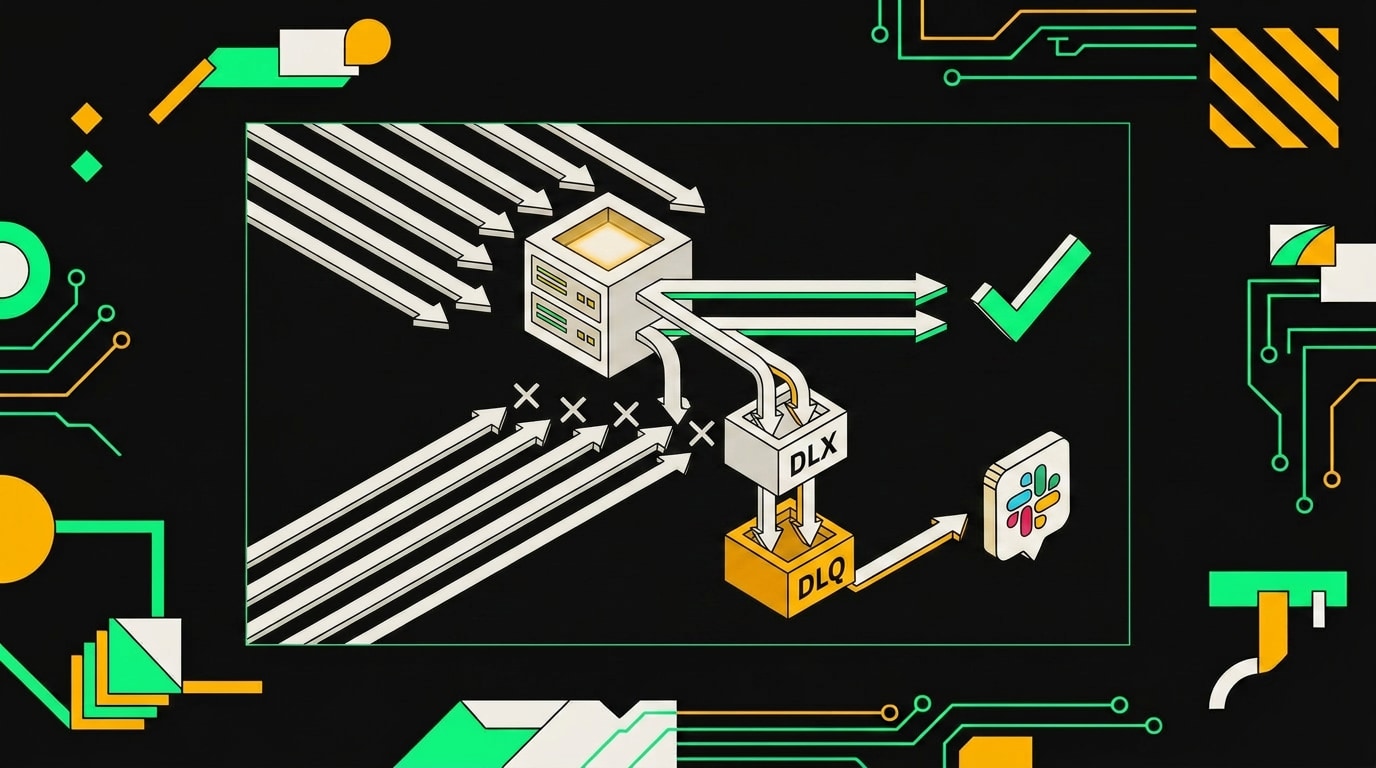
После третьего провала задача уходит в отдельную DLQ-очередь, откуда её можно разобрать вручную или перезапустить пакетно.
Idempotency: защита от дублирования при повторных доставках
Stripe повторяет доставку события до тех пор, пока не получит 2xx, и делает это на протяжении трёх суток. GitHub Actions при недоступности вашего эндпоинта тоже не молчит. Если обработчик упал, завис или ответил 500, тот же webhook придёт ещё раз. И ещё. Без защиты это означает дублированные списания, двойные письма или задвоенные записи в базе.
Решение прямолинейное: сохранять идентификатор события при первой обработке и при каждом следующем запросе сначала проверять, не обрабатывали ли мы это событие уже. У Stripe это заголовок Stripe-Event-ID, у GitHub X-GitHub-Delivery, у большинства других провайдеров есть аналогичный уникальный идентификатор в заголовках или теле запроса.
Хранить эти ключи удобно в Redis: запись занимает байты, операция SET NX атомарна, TTL выставляется сразу при записи. PostgreSQL тоже подходит, если Redis нет в стеке, но тогда нужно следить за уникальным индексом на колонке с event ID и вовремя чистить старые записи.
BullMQ упрощает задачу на уровне очереди: при добавлении job передаёте jobId равным идентификатору события.
await queue.add('stripe-event', payload, {
jobId: eventId // если job с таким ID уже есть, новый не создастся
});
Дедупликация происходит автоматически, пока job находится в состоянии waiting, active или delayed. После завершения защита пропадает, так что это не замена полноценному хранению обработанных ID, а дополнительный слой.
В n8n полноценную проверку можно собрать через Function-ноду в самом начале workflow. Схема: HTTP-запрос к Redis REST API (или нода n8n-nodes-redis) проверяет наличие ключа, Function-нода смотрит на результат и либо останавливает workflow пустым массивом, либо пропускает дальше.
// Function-нода n8n: проверка idempotency через Redis
const eventId = $input.first().json.headers['stripe-event-id'];
const redisKey = `processed:${eventId}`;
// Предполагается HTTP-запрос к Redis через отдельную ноду
// Если ключ существует - останавливаем workflow
if ($('Redis Check').first().json.exists) {
return []; // пустой output = workflow останавливается
}
// Иначе продолжаем и сохраняем ключ с TTL 86400 секунд
После этой ноды добавьте ещё один HTTP-запрос к Redis с командой SET processed:{eventId} 1 EX 86400. Именно EX 86400, то есть 24 часа. Хранить ключи дольше 72 часов нет смысла: Stripe к тому мо



