

Зачем вообще буферизировать сообщения в Telegram-боте
Вот типичная картина: пользователь открывает бота и пишет что-то вроде:
"привет" "мне нужна помощь" "точнее, хочу узнать про тарифы" "ну и ещё про возврат" "и да, у меня промокод есть"
Пять сообщений за 12 секунд. Каждое прилетает как отдельный webhook, каждое триггерит свой workflow, каждое уходит отдельным запросом в LLM. AI-агент добросовестно отвечает на "привет" приветствием, на "мне нужна помощь" уточняющим вопросом, и дальше всё окончательно превращается в кашу. Контекст разорван, пользователь получает три ответа вместо одного, и никто не доволен.
Это не редкий случай. Это стандартное поведение людей в мессенджерах. Мы пишем мыслями, не абзацами.
Теперь считаем деньги. В 2026 году GPT-4o стоит около $2.50 за миллион входящих токенов и $10 за исходящие. Если каждое из пяти коротких сообщений тащит за собой полный системный промпт, историю диалога и ответ, вместо одного сводного запроса, расходы на обслуживание среднего бота с несколькими сотнями активных пользователей вырастают в разы. Не абстрактно "вырастают", а буквально умножаются на количество фрагментов, которые можно было бы склеить.
Дебаунс решает задачу прямолинейно: вместо того чтобы реагировать на каждое входящее сообщение немедленно, бот ждёт паузы в N секунд, накапливает всё, что пришло от пользователя за это время, склеивает в один блок и только потом отправляет в LLM. Пользователь получает один связный ответ. Агент видит полный контекст запроса с первого раза. Токены тратятся на результат, а не на обработку промежуточного потока сознания.
Та же логика буферизации входящих сообщений пригодится, если вы строите AI-ассистента поддержки клиентов на n8n: там пользователи тоже пишут несколькими короткими репликами подряд, и без дебаунса каждая реплика запускает отдельный вызов LLM.

Пять сообщений, отправленных подряд, объединяются в единый запрос к языковой модели вместо пяти отдельных вызовов.
Как работает дебаунс: логика и таймер
Принцип простой. Приходит событие, запускаем таймер на 3 секунды. Приходит следующее событие, сбрасываем таймер и запускаем снова. Когда 3 секунды прошли без новых событий, выполняем действие один раз.
В Telegram это выглядит так: пользователь набирает "хочу заказать пиццу", потом удаляет и пишет "хочу пиццу маргариту", потом добавляет "с грибами". Три сообщения за 8 секунд. Без дебаунса бот трижды дёрнет LLM или базу данных. С дебаунсом: одно обращение, после последнего сообщения.
Окно паузы обычно выбирают в диапазоне 3-6 секунд. Конкретное значение подбирается под аудиторию: быстро печатающие пользователи комфортно работают с коротким окном, для голосовых сообщений или медленных диалогов его можно увеличить. Рекомендуется проверить выбранное значение на реальном трафике, поведение сильно зависит от конкретного сценария.
Дебаунс часто путают с троттлингом, и это разные вещи. Троттл говорит: "выполняй не чаще раза в N секунд". Дебаунс говорит: "выполняй только когда поток событий прекратился". Если пользователь шлёт сообщения непрерывно 2 минуты, троттл сработает ~24 раза (при интервале 5 секунд), дебаунс сработает ровно один раз в конце.
Теперь про реализацию в n8n. Встроенной ноды дебаунса нет, это решается через Code-ноду. Таймер нужно где-то хранить: конкретно нужен идентификатор пользователя и timestamp последнего события. Два варианта хранилища:
Static Data (встроено в n8n) подходит для простых случаев. Данные живут в памяти процесса, при рестарте сервиса сбрасываются. Для бота с небольшой нагрузкой и некритичной потерей состояния при деплое это нормально.
Redis нужен, если бот работает в production с реальными пользователями. Данные персистентны, и можно использовать TTL ключей напрямую: создаём ключ debounce:user_id со временем жизни 3 секунды, при каждом новом сообщении обновляем TTL. Отдельный воркер проверяет, истёк ли ключ. Это чище, чем считать дельты вручную.
Логика в Code-ноде в обоих случаях одна:
const userId = $input.item.json.message.from.id;
const now = Date.now();
const debounceMs = 3000;
const storage = $getWorkflowStaticData('global');
if (!storage.debounce) storage.debounce = {};
storage.debounce[userId] = now;
// Ждём паузу, потом проверяем
await new Promise(r => setTimeout(r, debounceMs));
if (storage.debounce[userId] === now) {
// Этот вызов последний в серии, идём дальше
return $input.item;
} else {
// Пришло новое событие, молча останавливаемся
return [];
}
Конструкция return [] говорит n8n остановить выполнение ветки без ошибки. Именно так отфильтровываются "промежуточные" сообщения серии.
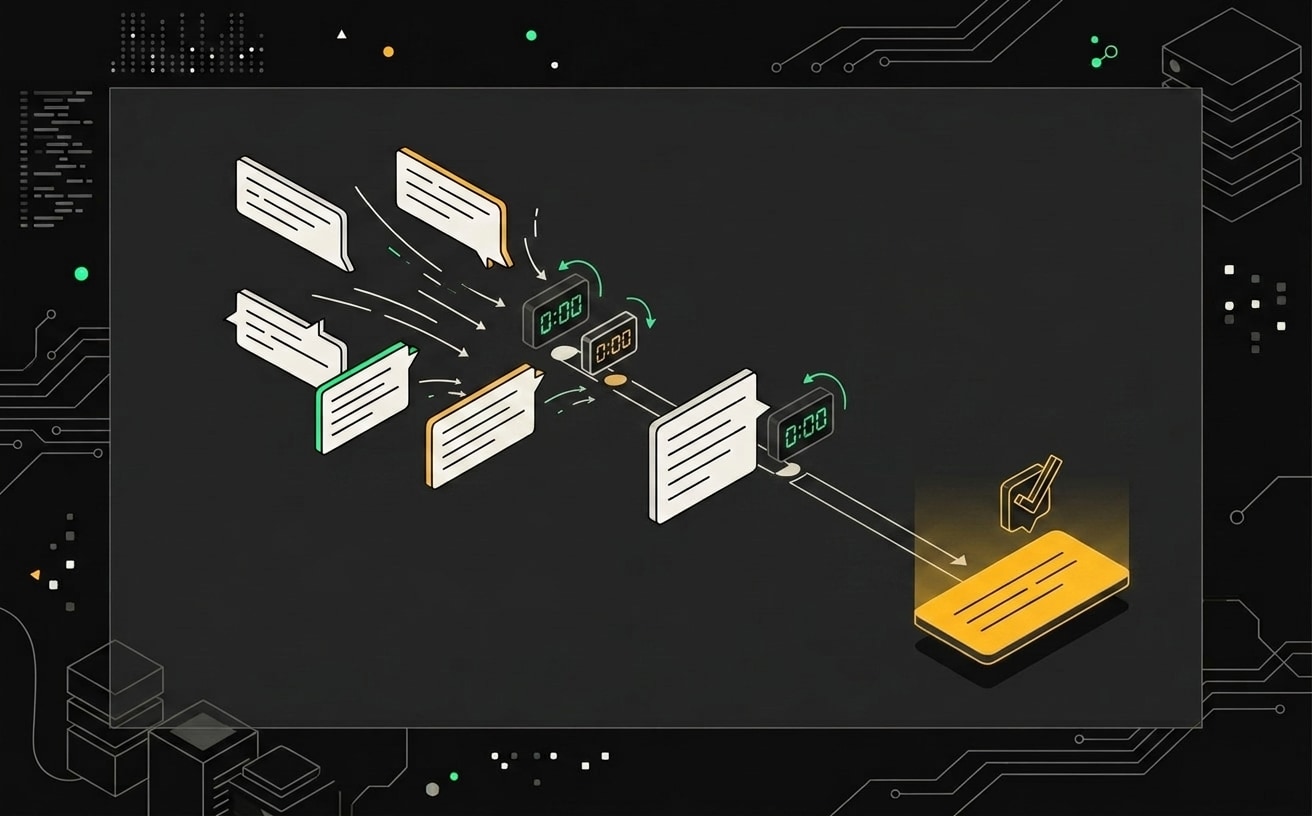
Каждое входящее сообщение сбрасывает таймер ожидания, и реальная обработка начинается только после паузы в активности пользователя.
Архитектура решения в n8n: два workflow вместо одного
Самая частая ошибка при реализации debounce в n8n: пытаться уместить всё в один workflow. Это не работает по фундаментальной причине.
Telegram отправляет обновление на webhook и ждёт ответа. Если ответа нет в течение примерно 10 секунд, он повторяет запрос. А значит, любая «пауза» внутри workflow с Telegram Trigger приводит к дублированию: бот получит одно сообщение, но обработает его два или три раза.
Поэтому архитектура разбивается на два независимых workflow.
Workflow 1: приёмник. Telegram Trigger → Code-нода → конец. Задача этого workflow одна: как можно быстрее принять сообщение, записать его в буфер и завершиться. В Code-ноде я пишу текст сообщения и Unix-timestamp в статическую переменную (через $vars или внешнее хранилище, об этом в следующей секции). Всё. Никакой обработки, никакого AI, никакого ожидания.
Workflow 2: обработчик. Schedule Trigger → Code-нода (проверяет буфер) → AI Agent → Telegram Send. Здесь происходит реальная работа. Code-нода смотрит: есть ли в буфере необработанное сообщение, и прошло ли с момента его записи нужное время (например, 15 секунд). Если оба условия выполнены, она забирает сообщение, помечает его как обработанное, и дальше идёт AI Agent. Если нет: workflow просто завершается без действий.
Интервал Schedule Trigger подбирается под ваше окно дебаунса. Разумная отправная точка: запускать триггер раза в два чаще, чем само окно агрегации, чтобы не добавлять лишнюю задержку. Точное значение стоит проверить под реальную нагрузку.
Эта схема работает потому, что приёмник никогда не блокируется. Он отвечает Telegram мгновенно.
Есть альтернатива: один workflow с Wait-нодой. Технически это собирается, и для простых случаев вполне подойдёт. Но Wait-нода создаёт отдельное «ожидающее» выполнение на каждый входящий запрос. При активном чате, где пользователь печатает быстро, параллельно висит несколько таких выполнений. В n8n Community Edition это легко упирается в лимит concurrency, и часть сообщений просто теряется. Два workflow с Schedule Trigger таких проблем не создают: обработчик запускается по расписанию и сам решает, есть ли ему что делать.
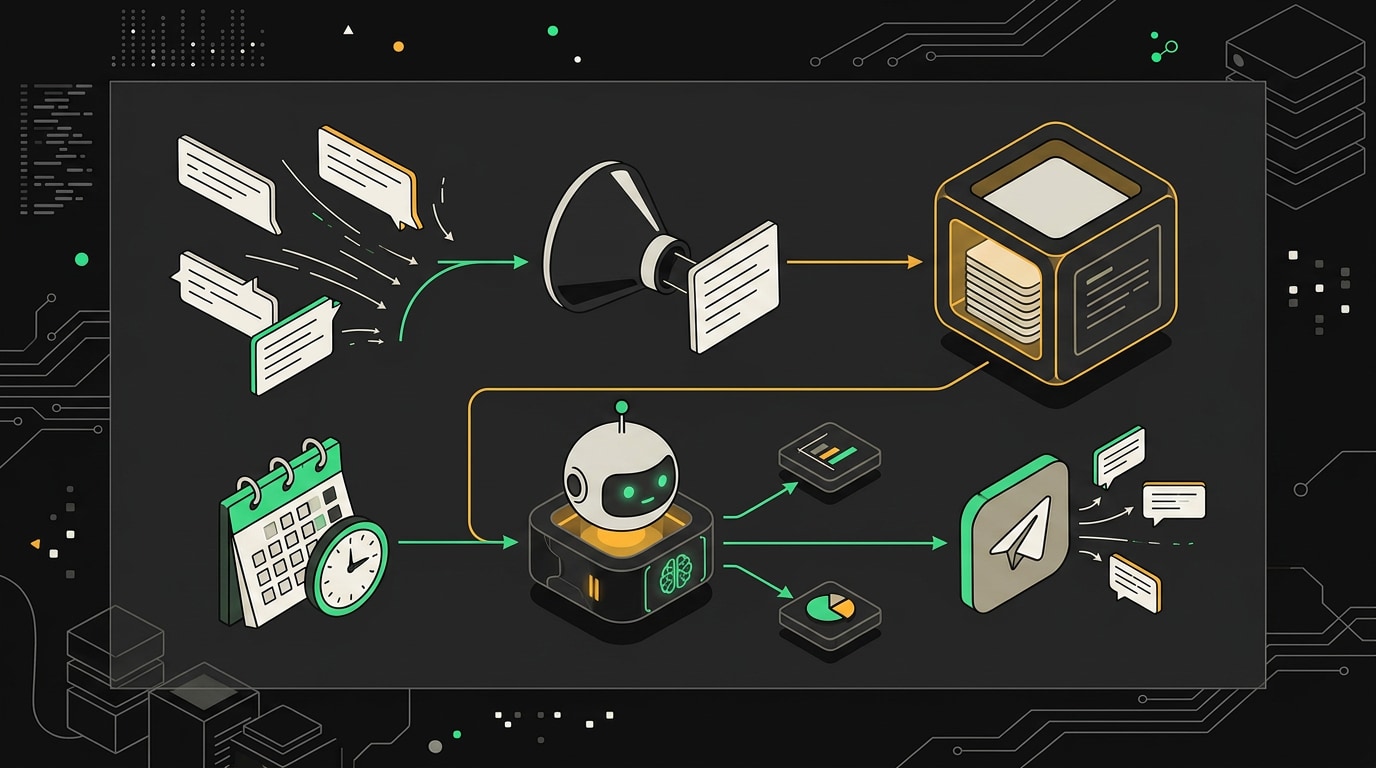
Первый воркфлоу принимает сообщения и пишет в очередь, второй запускается по таймеру и отправляет накопленный пакет в AI.
Хранилище для буфера: Static Data vs Redis
Когда накапливаешь сообщения в буфер, нужно где-то их хранить между запусками workflow. В n8n для этого два реальных варианта.
Static Data встроен в n8n и работает без какой-либо настройки. Технически это объект в памяти процесса n8n, который сохраняется между отдельными запусками одного workflow. Звучит удобно. Но есть жёсткое ограничение: перезапустил контейнер или упал процесс - данные исчезли. Никакой персистентности между деплоями.
Redis требует отдельного контейнера или облачного инстанса вроде Upstash. Зато даёт реальную надёжность: данные переживают перезапуск, на ключах можно выставить TTL (например, автоматически удалять буфер чата через час неактивности), и работает корректно при нескольких worker-процессах.
Выбор между ними проще, чем кажется. Если у вас self-hosted n8n с одним worker и умеренный трафик, Static Data вполне справится. Но если вы на n8n Cloud или запустили queue mode с несколькими workers, берите Redis без колебаний. Static Data хранится в памяти конкретного процесса и между workers не синхронизируется. Один worker запишет буфер, второй его не увидит, и логика агрегации сломается тихо, без ошибок.
Структура буфера в обоих случаях одинакова: объект, где ключ - это chatId, а значение содержит массив сообщений и таймстамп последнего из них.
// Пример структуры данных в Static Data
{
"123456789": {
"messages": ["привет", "можешь помочь?", "срочно"],
"lastTs": 1746700000000
}
}
lastTs тут несёт двойную нагрузку: по нему определяем, сколько времени прошло с последнего сообщения, и именно с ним сравниваем текущий Date.now(), чтобы решить - сбрасывать буфер или ждать ещё. Поле messages - просто массив строк в порядке поступления. Никакой сложной схемы, всё читается с первого взгляда.
Один практический момент по Redis: если ставите TTL на ключи, делайте его заметно длиннее вашего окна агрегации. Если окно 30 секунд, TTL должен быть хотя бы 5-10 минут. Иначе Redis может удалить ключ прямо в середине диалога, если пользователь сделал паузу.
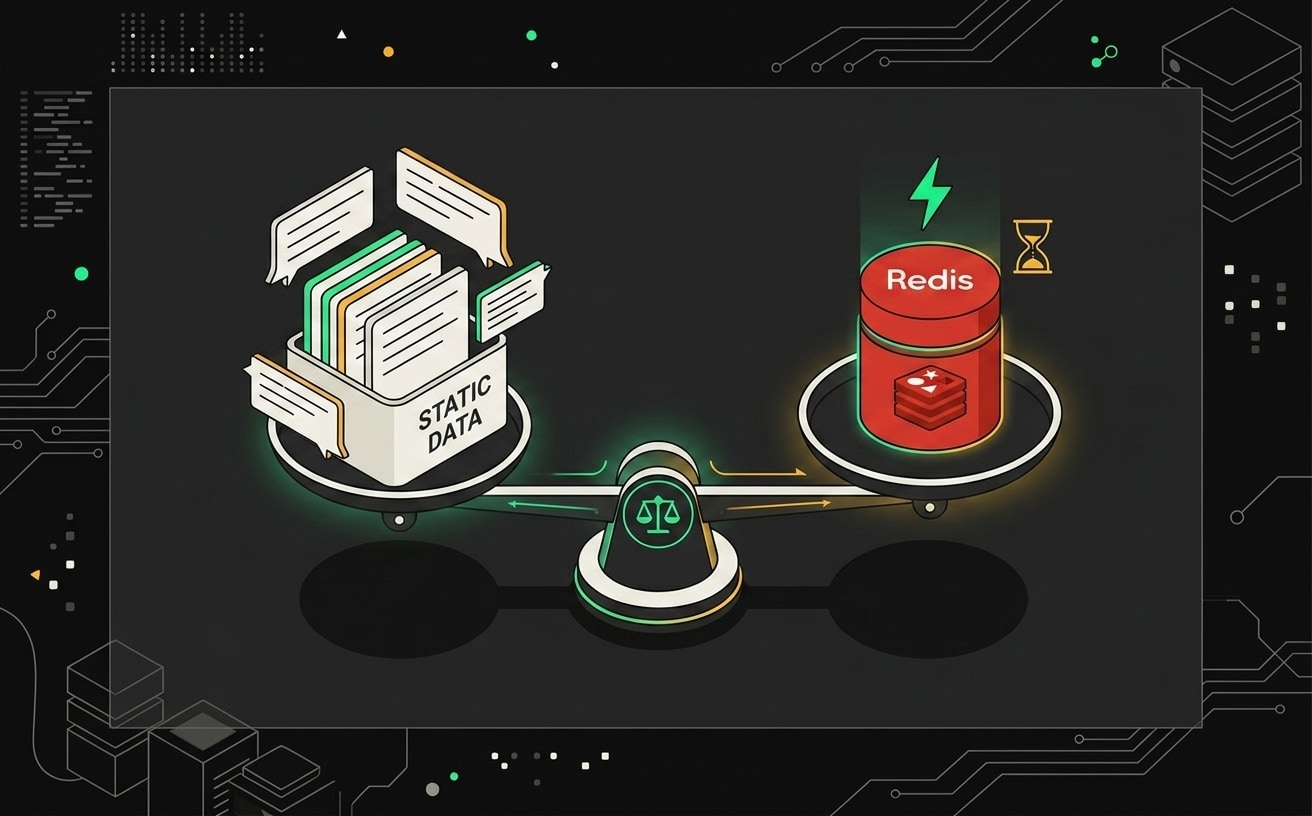
Static Data проще в настройке, но не работает при горизонтальном масштабировании, тогда как Redis решает эту проблему ценой дополнительной инфраструктуры.
Code-нода приёмника: пишем сообщение в буфер
Вся логика укладывается в одну Code-ноду. Никаких внешних баз, никакого Redis. Только $getWorkflowStaticData('global') и несколько строк кода.
Сначала вытаскиваем chatId и text из входящего апдейта. Telegram присылает числовой идентификатор, поэтому сразу переводим его в строку через .toString(). Иначе при записи в объект JavaScript молча превратит ключ в строку сам, но потом при чтении из Static Data можно поймать несовпадение типов, которое съест час отладки.
const staticData = $getWorkflowStaticData('global');
const chatId = $json.message.chat.id.toString();
const text = $json.message.text;
if (!staticData.buffer) staticData.buffer = {};
if (!staticData.buffer[chatId]) {
staticData.buffer[chatId] = { messages: [], lastTs: 0 };
}
staticData.buffer[chatId].messages.push(text);
staticData.buffer[chatId].lastTs = Date.now();
return [{ json: { status: 'buffered', chatId } }];
$getWorkflowStaticData('global') возвращает объект-ссылку. Это принципиально: мы мутируем его напрямую, и n8n сам запишет изменения в хранилище после завершения ноды. Не нужно делать отдельный "set"-вызов. Просто меняешь поля объекта и выходишь из ноды.
Структура буфера: один ключ на чат. Внутри массив messages и метка lastTs. Метка нужна триггерной ноде-флашеру, которая будет решать, прошла ли пауза. Date.now() даёт миллисекунды в UTC без лишних зависимостей.
Нода возвращает { status: 'buffered', chatId }. Этот ответ уходит в Telegram-вебхук мгновенно, пользователь не ждёт обработки. Именно здесь и смысл всей схемы: приём и обработка разделены во времени. Приёмник только складывает сообщение в буфер и отвечает, а агрегация и отправка в LLM происходят отдельным воркфлоу по таймеру.
Один момент, который легко пропустить: если пользователь отправит сообщение без text (стикер, фото, голосовое), $json.message.text будет undefined. Минимальная защита: добавить if (!text) return [{ json: { status: 'skipped' } }]; перед push. Иначе в буфер попадут undefined-значения, и потом при сборке итогового промпта получишь строку "undefined undefined undefined".
Code-нода обработчика: проверяем таймер и собираем очередь
Schedule Trigger запускает обработчик по расписанию. Каждый раз одна и та же Code-нода просыпается, смотрит в буфер и решает: есть что отправлять или нет.
Логика простая. Для каждого chatId в буфере проверяем, сколько миллисекунд прошло с последнего сообщения. Если больше DEBOUNCE_MS (в примере 4000 мс), пользователь перестал печатать. Берём все накопленные фрагменты, склеиваем в одну строку и отправляем дальше по workflow. Запись из буфера сразу удаляем, чтобы не обработать её повторно на следующем прогоне.
const DEBOUNCE_MS = 4000;
const staticData = $getWorkflowStaticData('global');
const now = Date.now();
const results = [];
if (!staticData.buffer) return [];
for (const [chatId, data] of Object.entries(staticData.buffer)) {
if (now - data.lastTs >= DEBOUNCE_MS && data.messages.length > 0) {
results.push({
json: {
chatId,
combinedText: data.messages.join('\n')
}
});
delete staticData.buffer[chatId];
}
}
return results;
Несколько вещей, которые здесь работают именно так, а не иначе.
$getWorkflowStaticData('global') возвращает один объект, который живёт между запусками. Это не переменная в памяти процесса, а персистентное хранилище n8n. Поэтому delete staticData.buffer[chatId] реально удаляет запись, а не просто обнуляет локальную копию.
Цикл проходит по всем chatId за один прогон. Это принципиально: если в буфере накопились записи для трёх разных пользователей, функция вернёт три элемента массива. Каждый пойдёт в AI отдельным item. Один пользователь с длинным сообщением не заблокирует остальных.
data.messages.join('\n') собирает фрагменты через перенос строки. Если человек отправил "привет", потом "хочу заказать пиццу", потом "маргариту", AI получит одним куском:
привет
хочу заказать пиццу
маргариту
Это лучше, чем пробел: модель видит границы реплик.
Когда results пустой, нода возвращает []. Schedule Trigger запустился, проверил буфер, никого не нашёл. Дальше ставим IF-ноду с условием {{ $json.chatId }} не пусто, и если пусто, ветка просто завершается. AI не вызывается, токены не тратятся. На коротком интервале это критично: без такой проверки workflow будет гонять запросы в LLM вхолостую 24 часа в сутки.
Граничный случай: что если между двумя прогонами пришло сразу много сообщений? Ничего страшного. data.messages накапливает их все, lastTs обновляется при каждом входящем. Пока пользователь пишет, таймер сбрасывается. Как только замолчал на 4 секунды, следующий прогон триггера всё подберёт.
Подключаем AI Agent и отправляем ответ
После Code-ноды у нас есть объект с chatId и combinedText. Теперь подключаем AI Agent.
В System Prompt пишем прямо: входящий текст содержит несколько сообщений одного пользователя, собранных за короткий промежуток времени и объединённых в один блок. Агент должен воспринимать это как единый запрос, а не как отдельные реплики. Без этого объяснения модель иногда отвечает на последнее предложение, игнорируя всё, что было выше.
В поле User Message передаём {{ $json.combinedText }}. Агент получает полный контекст разговора сразу, одним куском.
Дальше ответ AI Agent идёт в ноду Telegram "Send Message". В поле Chat ID пишем {{ $json.chatId }}. Здесь есть нюанс: если Code-нода отдаёт несколько объектов (несколько разных пользователей накопили сообщения одновременно), нужна нода Split In Batches между Code и AI Agent. Она разобьёт массив на отдельные items, и каждый chatId обработается независимо. Без неё AI Agent возьмёт только первый элемент.
Про typing action: перед запросом к LLM добавляем Telegram "Send Chat Action" с методом typing. Пользователь видит индикатор "печатает...", пока модель думает. Особенно это заметно при медленных моделях или длинных ответах. Подключается просто: нода sendChatAction с тем же chatId, затем сразу AI Agent.
Финальная цепочка выглядит так: Code → Split In Batches → sendChatAction → AI Agent → Send Message. Минималистично и работает.
Граничные случаи и типичные баги
Самый неприятный баг, который я видел в продакшне: два параллельных запуска Schedule Trigger читают Static Data одновременно и оба находят одну и ту же запись в буфере. Оба решают, что пора флашить. В итоге AI-агент получает один и тот же набор сообщений дважды, а иногда ещё и отвечает пользователю дважды. Фикс простой: в настройках workflow обработчика выставляйте concurrency = 1. Это заставит n8n выстраивать запуски в очередь, а не гонять их параллельно.
Static Data не переживает перезапуск. Если сервер упал или вы задеплоили новую версию workflow, буфер обнулится. Сообщения, которые уже пришли но ещё не ушли в обработку, просто исчезнут. Если это критично для вашего сценария, добавьте в workflow приёмника параллельную ветку: пишите каждое сообщение в Postgres сразу при получении. Буфер в Static Data тогда работает как кэш, а база как источник истины при восстановлении.
Отдельно про бесконечный рост буфера. Если пользователь пишет быстро и много (или бот получает системные события в цикле), таймер в 10-15 секунд никогда не сработает "чисто": пока вы ждёте паузу, новые сообщения снова сдвигают окно. Буфер растёт, задержка растёт. Добавьте жёсткий лимит поверх таймера: если сообщений накопилось больше 20 или с первого сообщения прошло больше 30 секунд, флашим принудительно, не дожидаясь тишины. В Function-ноде это выглядит примерно так:
const MAX_MESSAGES = 20;
const MAX_AGE_MS = 30000;
const now = Date.now();
const firstTs = buffer[0]?.ts ?? now;
const shouldFlush =
buffer.length >= MAX_MESSAGES ||
(now - firstTs) > MAX_AGE_MS;
И последнее: Telegram даёт вашему webhook ровно 5 секунд на ответ. Если workflow приёмника не завершится за это время, Telegram посчитает доставку неуспешной и начнёт повторять запрос. Внутри workflow приёмника не должно быть никаких HTTP-запросов, обращений к базе или тяжёлой логики. Только: принять сообщение, дописать в буфер, ответить 200. Всё остальное делает отдельный workflow по расписанию.
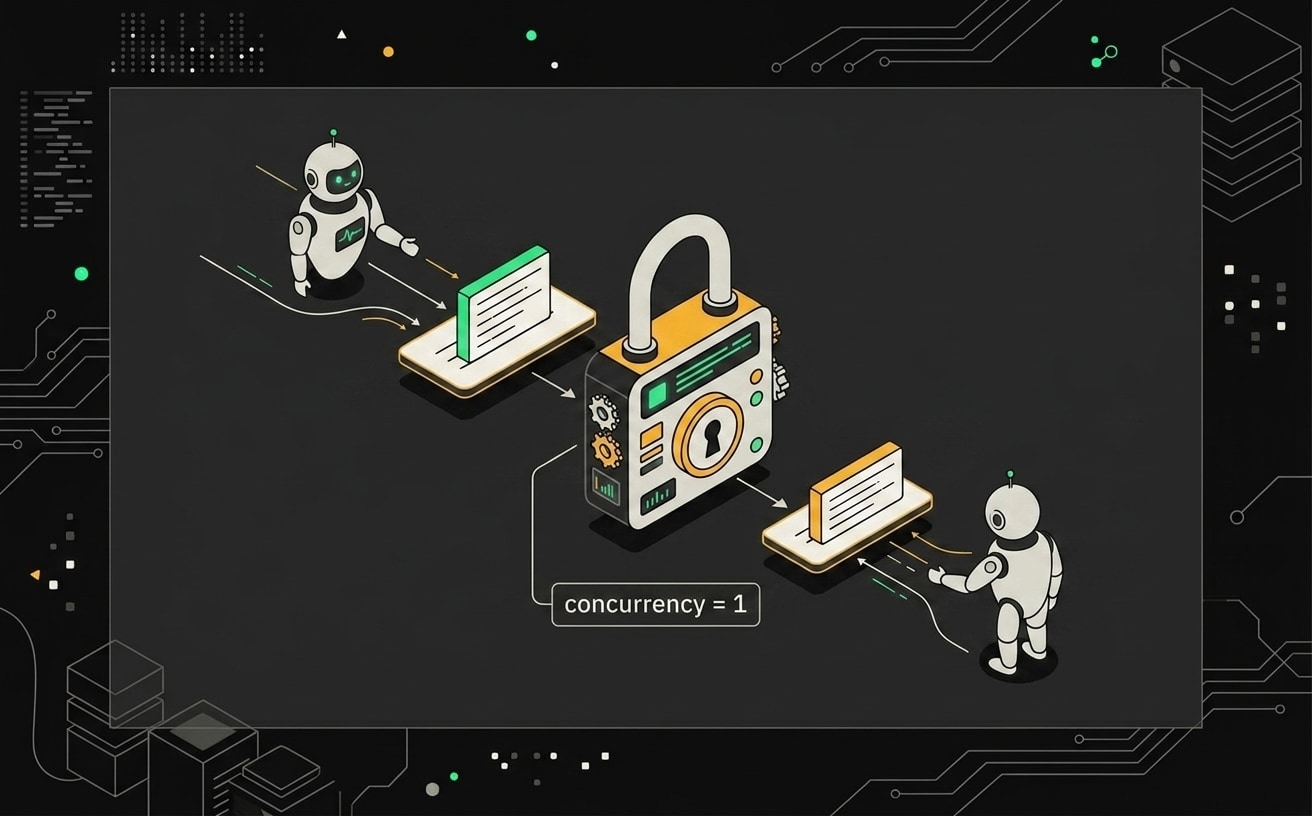
Без явной блокировки два одновременных запроса могут прочитать одно и то же состояние и запустить дублирующий вызов AI.
Тестирование и отладка в n8n
Первое, что я делаю перед любым полноценным запуском: переключаю Telegram Trigger на Test Webhook URL и отправляю сообщения вручную прямо в бота. Никакого деплоя, никакого ожидания. n8n перехватывает запрос, показывает структуру входящих данных, и сразу видно, правильно ли парсится message.text и есть ли chat.id там, где ожидается.
Но здесь есть ловушка, которую я сам долго не замечал. В режиме тестового прогона Static Data не сохраняется между запусками. Каждый раз буфер пустой. Это значит, что протестировать логику накопления сообщений через Test Webhook не получится: нода Code или Function просто не увидит историю. Решение простое: тестируйте обработчик буфера отдельно, через Mock Input. Вставляете туда JSON с имитацией заполненного staticData и прогоняете логику изолированно.
Логирование содержимого буфера в начале каждого прогона обработчика я считаю обязательным. Вот почему: если два сообщения пришли с интервалом в 100 мс, второй вызов может стартовать до того, как первый успел записать данные. Без явного console.log(JSON.stringify($getWorkflowStaticData('global'))) в самом начале ноды вы никогда не поймёте, был ли race condition или просто TTL сбросил буфер раньше времени. Я добавляю эту строку всегда, даже в продакшн-версии, потому что в Execution History она потом помогает восстановить хронологию.
Про Execution History отдельно. n8n хранит историю запусков, и её нужно периодически проверять с конкретной целью: убедиться, что обработчик не вызывает AI-ноду при пустом буфере. Каждый такой лишний вызов стоит токенов. Я однажды обнаружил, что за ночь накопились лишние executions с пустыми запросами к LLM, потому что условие проверки длины буфера стояло после ноды, а не до. Фильтруйте в Execution History по статусу и смотрите, что именно передаётся в AI-ноду. Если видите пустые массивы или undefined в поле с историей сообщений, это сигнал переставить IF-ноду выше по цепочке.
Когда дебаунс не нужен и чем его заменить
Дебаунс решает конкретную задачу: подождать, пока пользователь закончит печатать. Но это условие выполняется далеко не всегда.
Если бот работает с SLA на ответ меньше 3 секунд, дебаунс физически не вписывается в требования. Пауза съедает часть



