

Что такое воронка лидогенерации на n8n и зачем её строить
Воронка лидогенерации — это не маркетинговая абстракция, а конкретная цепочка действий с данными: захватил контакт → проверил, что он живой → добавил контекст → положил в CRM → запустил прогрев. Пять шагов, и каждый либо автоматизирован, либо кто-то делает это руками каждый день.
n8n закрывает всю эту цепочку внутри одного инструмента. Это визуальный low-code редактор с self-hosted режимом — вы разворачиваете его на своём сервере или в Docker, и данные никуда не утекают по дороге. Больше 400 встроенных интеграций плюс нода HTTP Request, которая подключает вообще всё, что отдаёт API.
Сравнение с Zapier и Make упирается в одну вещь: модель ценообразования. Zapier считает выполнения (tasks), Make считает операции — при росте объёмов вы платите экспоненциально больше. n8n при self-hosted — фиксированная стоимость сервера, сколько бы воронок и лидов у вас ни было. Это меняет расчёт, особенно когда воронка начинает работать в плюс и объёмы растут.
Практически: MVP-воронку из 5-7 нод можно собрать за относительно короткое время. Вебхук принимает форму, JavaScript-нода валидирует email, HTTP Request дёргает Hunter или Clearbit для обогащения, ещё один HTTP Request кладёт запись в CRM, финальная нода отправляет приветственное письмо. Это не пет-проект для резюме — это работающая инфраструктура.
Что нужно для старта: инстанс n8n (облачный trial или Docker на VPS за $5-10 в месяц), любая форма захвата лидов с вебхуком или интеграцией, CRM с API (HubSpot, Pipedrive, Notion — неважно) и SMTP или email-сервис вроде SendGrid. Всё остальное — логика внутри воронки, которую вы контролируете сами.

Пять последовательных узлов n8n образуют полный путь лида от захвата до передачи в CRM.
Подготовка: чек-лист перед стартом за 1 день
Прежде чем открывать n8n и тащить ноды на канвас — остановись. Час плохой подготовки съедает день отладки. Я прошёл через это достаточно раз, чтобы теперь начинать с одного и того же ритуала.
Источник лидов. Реши это в первую очередь, потому что от ответа зависит архитектура всего потока. Tilda и Webflow отдают данные через webhook — значит, триггер будет Webhook node. Facebook Lead Ads работает через собственный API с подпиской на события — там отдельная история с верификацией. Typeform имеет нативную интеграцию в n8n. Это разные точки входа, разные форматы payload, разная обработка ошибок. Смешивать их в одном воркфлоу на старте не стоит — сначала один источник, потом масштабируешь.
CRM. HubSpot, Pipedrive, Bitrix24, AmoCRM — у всех есть ноды в n8n, но у каждого свои причуды с аутентификацией. Зайди в настройки своей CRM прямо сейчас и создай API-ключ или OAuth-приложение. Не завтра утром перед запуском, а сейчас. В Pipedrive это два клика, в Bitrix24 — уже квест с входящим вебхуком и правами пользователя.
Аккаунты и доступы. Тебе понадобятся: Google Sheets (создай отдельную таблицу для лидов, не используй рабочую), Slack или Telegram для уведомлений о новых лидах и ошибках, email-сервис — SendGrid или SMTP, если планируешь автоответы. Всё это должно быть готово до того, как ты напишешь первую ноду.
Credentials в n8n — отдельный разговор. Никогда не вставляй API-ключи прямо в параметры ноды. Это не паранойя, это базовая гигиена: ключи в нодах видны в экспорте воркфлоу, они попадают в логи, их легко случайно расшарить. Все секреты — только через Settings → Credentials. Создай credential для каждого сервиса заранее, дай им понятные имена вроде HubSpot Production или Telegram Bot Leads. Потом просто выбираешь из дропдауна.
Распределение времени на день сборки. Я разбиваю на четыре блока по два часа:
- 2 часа — захват лидов: настройка webhook или триггера, парсинг входящего payload, первичная валидация полей
- 2 часа — обогащение: подтягивание данных из внешних источников, нормализация форматов, дедупликация
- 2 часа — запись в CRM и уведомления: создание контакта, назначение ответственного, Slack/Telegram нотификация
- 2 часа — тесты: прогон реальных данных, проверка крайних случаев, сломанные payload, дубли, пустые поля
Это не жёсткий таймбокс, но без него первые два блока легко растягиваются до конца дня, и тесты остаются на потом. А потом — это обычно никогда.
Шаг 1. Настройка точки входа: Webhook-триггер для захвата лидов
Любой воркфлоу начинается с триггера, и для входящих лидов я почти всегда беру именно Webhook-ноду. Она универсальна: ловит JSON откуда угодно — лендинг, форма, мобильное приложение, чат-бот.
Создаём Webhook-ноду
Кидаю на холст ноду Webhook и настраиваю:
- HTTP Method:
POST(GET оставляем для тестов и редких случаев с query-параметрами) - Path: осмысленный, например
lead-capture-main. Не оставляйте дефолтный UUID — потом замучаетесь искать в логах - Response Mode:
On Received— отвечаем форме сразу 200 OK, а обработку гоним дальше асинхронно. Если форма ждёт результата (например, показать «спасибо, вы записаны»), переключайте наLast Node
После сохранения n8n даёт два URL:
Test URL: https://n8n.example.com/webhook-test/lead-capture-main
Production URL: https://n8n.example.com/webhook/lead-capture-main
Разница принципиальная. Test URL работает только когда вы нажали «Listen for test event» в редакторе — удобно отлаживать, видно payload в интерфейсе. Production URL живёт постоянно, но только если воркфлоу активирован тумблером в правом верхнем углу. Классическая ошибка: настроили форму на test-урл, ушли на прод — лиды молча пропадают.
Подключаем форму
В Tilda идём в настройки формы → «Webhook» → вставляем production URL. Tilda по умолчанию шлёт application/x-www-form-urlencoded, поэтому в Webhook-ноде ставлю Content-Type → Accept all или явно прошу JSON через настройки формы (в Typeform это делается из коробки).
Ожидаемый payload, под который дальше затачиваем весь пайплайн:
{
"name": "Иван Петров",
"email": "ivan@example.com",
"phone": "+79991234567",
"utm_source": "google",
"form_id": "landing_main"
}
form_id советую закладывать сразу, даже если форма пока одна. Через месяц их станет пять, и роутинг по form_id спасёт от копипаста воркфлоу.
Альтернативные триггеры
Webhook — не единственный вариант. Что использую в зависимости от задачи:
- n8n Form Trigger — когда лень делать лендинг. n8n сам поднимает форму по URL, пишете поля в ноде и получаете готовый захват
- Facebook Lead Ads Trigger — для лидформ из Meta Ads, забирает заявки через Graph API без посредников
- Gmail Trigger / IMAP Email — если заявки падают на почту (типичная история с партнёрскими площадками), парсим тело письма регуляркой дальше по флоу
Защита эндпоинта
Открытый webhook — приглашение спамерам залить вам в CRM мусор. Минимум, что включаю:
В разделе Authentication ноды выбираю Header Auth и задаю креды (например, заголовок X-Webhook-Secret со случайным токеном на 32 символа). Тот же токен прописываю в настройках формы или серверного прокси, который шлёт данные.
Если на источнике нельзя задать кастомный header (привет, некоторые конструкторы), использую запасной вариант — токен в query-параметре + проверка в IF-ноде сразу после webhook:
{{ $json.query.token === $env.WEBHOOK_SECRET }}
Несовпадение → ветка с Respond to Webhook и кодом 401. Заодно полезно поставить Cloudflare или rate limiting на уровне реверс-прокси, но это уже инфраструктурная история.
После этого шага у нас есть рабочая точка входа, которая принимает JSON с лидом и готова передать его дальше — на валидацию.

Webhook-нода принимает POST-запрос с полями формы и запускает автоматизированную воронку.
Шаг 2. Валидация и нормализация данных лида
Сырые данные из формы — это всегда боль. Кто-то пишет телефон через дефисы, кто-то с восьмёркой в начале, кто-то залипает капсом в email. Если кидать это в CRM как есть, через неделю получите кашу из дублей и невалидных контактов. Поэтому сразу после приёмной ноды я ставлю слой нормализации.
Set: приводим поля к единой схеме
Первым делом — нода Set. Здесь я выравниваю всё под одну схему: email прогоняется через toLowerCase(), имя триммится от пробелов, телефон уходит дальше на отдельную обработку. Заодно добавляю служебные поля: source, created_at, utm_*. Чем строже схема на входе — тем меньше боли потом в маппинге на CRM.
IF/Switch: фильтрация мусора
Дальше — IF-нода с проверкой обязательных полей. Если нет email или телефона, лид уходит в отдельную ветку (обычно — в Slack-канал «битые лиды», чтобы маркетинг видел проблему с формой). Email дополнительно валидирую регуляркой:
^[^\s@]+@[^\s@]+\.[^\s@]{2,}$
Простую, но достаточную, чтобы отсеять test@test, qwe@qwe.qwe и прочий хлам, который боты любят кидать.
Code node: нормализация телефона
С телефонами Set уже не справляется — нужна логика. Кидаю Code node на JavaScript:
// Code node: нормализация телефона
const phone = $input.item.json.phone.replace(/\D/g, '');
const normalized = phone.startsWith('8') ? '+7' + phone.slice(1) : '+' + phone;
return { json: { ...$input.item.json, phone: normalized } };
Сначала вычищаю всё, кроме цифр, потом привожу российскую восьмёрку к +7. Для международных номеров логику можно расширить через libphonenumber-js, но для 90% потоков этого хватает — на выходе формат E.164, который без вопросов жуёт любая CRM и SMS-шлюз.
Поиск дубликатов до создания
Перед тем как лететь в CRM с Create Contact, делаю Search Contact by email. Если контакт уже есть — иду по ветке обновления (дописать новый источник, инкрементнуть счётчик касаний), если нет — создаю с нуля. Это спасает от ситуации, когда один и тот же человек заполнил форму трижды за вечер и менеджер получил три задачи на один контакт.
Аудит в Google Sheets
И последнее: параллельной веткой пишу сырой payload в Google Sheets — до всех преобразований. Когда через месяц прибежит маркетолог с воплем «куда делся мой лид Иван», у меня будет ровно то, что пришло с формы, с таймстемпом и raw-телом запроса. Дёшево, сердито, и пару раз меня уже спасало от долгих разборок «кто виноват — n8n или фронт».

Function-нода проверяет обязательные поля, очищает номер телефона и приводит email к нижнему регистру.
Шаг 3. Обогащение лида внешними данными
Голый лид из формы — это почти ничего. Имя, email, может телефон. Чтобы скорить его осмысленно, нужен контекст: кто человек, в какой компании работает, сколько там людей. Всё это можно получить автоматически, прежде чем лид вообще попадёт к менеджеру.
HTTP Request к сервисам обогащения
В n8n это делается через ноду HTTP Request. Передаёшь email — получаешь обратно должность, домен компании, индустрию, численность сотрудников.
Базовый запрос к Apollo.io выглядит так:
POST https://api.apollo.io/v1/people/match
Content-Type: application/json
{
"email": "{{ $json.email }}",
"api_key": "{{ $credentials.apolloApiKey }}"
}
В ответе придёт объект с title, organization.name, organization.num_employees и десятком других полей. Дальше разбираешь это через Set-ноду и тащишь нужное в основной объект лида.
Что использовать в 2026: сравнение сервисов
Clearbit стал дорогим и менее удобным для независимого использования. Реальные альтернативы сейчас:
| Сервис | Цена (примерно) | Сильная сторона |
|---|---|---|
| Apollo.io | от $49/мес, есть freemium | Большая база, хороший API |
| Lead411 | от $99/мес | Верифицированные прямые номера |
| Lusha | от $36/мес | Простой API, быстрая интеграция |
| Hunter.io | от $34/мес | Лучший для верификации email |
Для большинства задач Apollo достаточно — база большая, API стабильный, freemium позволяет проверить до старта платежей. Hunter беру отдельно только если нужна верификация доставляемости.
Формула скоринга
После обогащения считаю скор прямо в n8n через ноду Code:
const email = $json.email;
const title = ($json.apollo?.title || '').toLowerCase();
const employees = $json.apollo?.organization?.num_employees || 0;
let score = 0;
// Корпоративный домен — плюс, gmail/yahoo — минус
const freeProviders = ['gmail.com', 'yahoo.com', 'hotmail.com', 'mail.ru'];
const domain = email.split('@')[1];
score += freeProviders.includes(domain) ? -20 : 30;
// Должность
if (['ceo', 'founder', 'cto', 'vp', 'director', 'head'].some(r => title.includes(r))) {
score += 40;
} else if (['manager', 'lead', 'senior'].some(r => title.includes(r))) {
score += 20;
}
// Размер компании
if (employees > 500) score += 30;
else if (employees > 50) score += 20;
else if (employees > 10) score += 10;
return [{ json: { ...$json, leadScore: score } }];
Лид набрал 80+ — горячий, уходит в CRM с высоким приоритетом. Ниже 30 — попадает в нурчинг-последовательность. Пороги настраивай под свою воронку, это стартовая точка.
Кэширование: не тратить запросы дважды
Обогащение платное, и гонять один и тот же email в Apollo дважды — деньги на ветер. Перед каждым запросом к внешнему API проверяю кэш.
Если у тебя уже есть Postgres — делаю ноду Postgres с запросом:
SELECT enrichment_data
FROM lead_enrichment_cache
WHERE email = '{{ $json.email }}'
AND created_at > NOW() - INTERVAL '30 days';
Нашлось — беру из кэша, пропускаю HTTP Request. Не нашлось — иду в API, сохраняю результат. Срок жизни кэша 30 дней обычно разумный компромисс между свежестью данных и экономией.
Если Postgres нет и не хочется поднимать — n8n Data Tables подойдут для небольших объёмов. До ~10k записей работает нормально, дальше начинает тормозить.
Rate limit и retry-логика
Apollo и Lusha ограничивают количество запросов — актуальные лимиты уточняйте в документации своего плана. Если обрабатываешь список лидов пачкой, без паузы можно упереться в 429.
Схема обработки:
- После HTTP Request ставлю IF-ноду: проверяю
$response.statusCode === 429 - Если да — нода Wait с задержкой. Первая попытка: 5 секунд, вторая: 15, третья: 45. Это и есть экспоненциальный backoff
- Реализую через счётчик попыток в объекте лида:
$json.retryCount
// В Code-ноде перед повтором
const retryCount = $json.retryCount || 0;
const waitSeconds = Math.pow(3, retryCount) * 5; // 5, 15, 45...
return [{
json: {
...$json,
retryCount: retryCount + 1,
waitSeconds
}
}];
После трёх неудачных попыток лид уходит в отдельную ветку — логирую в Slack или отдельную таблицу для ручного разбора. Просто молча дропать лиды потому что API не ответил — плохая идея.

HTTP-запрос к внешнему API добавляет данные о компании лида перед расчётом скорингового балла.
Шаг 4. Маршрутизация и отправка в CRM
К этому моменту у меня на руках обогащённый лид: email, скоринг, продукт, регион, source. Дальше — развилка.
Разветвление по сценарию
Ставлю Switch-ноду сразу после скоринга. У меня обычно три ветки по температуре:
hot(score ≥ 70) — создаём сделку, ставим задачу менеджеру на сегодня, дёргаем уведомление в Slackwarm(40–69) — кладём в nurture-последовательность, задача менеджеру на +2 дняcold(< 40) — только контакт в CRM, дальше работает email-цепочка
Если продуктов несколько или есть регионы — добавляю второй Switch ниже по дереву. Не пытайтесь всё засунуть в одну ноду через выражения — потом сами не разберётесь, что куда уходит.
Upsert контакта: найти или создать
В CRM почти всегда нужен upsert по email, иначе плодятся дубли. Логика простая:
- HubSpot/Pipedrive Search — ищу контакт по email
- IF-нода — проверяю, вернулся ли результат
- Ветка «найден» → Update Contact (мержу новые поля, не затирая существующие)
- Ветка «не найден» → Create Contact
Если в n8n нужной ноды нет или не хватает полей — иду через HTTP Request прямо в API. Для HubSpot, например, удобнее использовать эндпоинт /crm/v3/objects/contacts/batch/upsert — один вызов вместо двух, плюс атомарно.
Round-robin распределение менеджеров
Чтобы лиды не сваливались на одного бедолагу, использую счётчик в staticData воркфлоу. Code-нода:
// Round-robin распределения менеджеров
const managers = ['mgr_1', 'mgr_2', 'mgr_3'];
const counter = $getWorkflowStaticData('global').counter || 0;
$getWorkflowStaticData('global').counter = counter + 1;
return { json: { assignee: managers[counter % managers.length] } };
Обратите внимание: поведение staticData при рестартах воркфлоу зависит от конфигурации вашего инстанса n8n и типа хранилища — уточните это в документации перед использованием в продакшене. Если менеджеров много и нужны веса (Петя берёт 50%, остальные по 25%) — заменяйте массив на «развёрнутый»: ['mgr_1','mgr_1','mgr_2','mgr_3']. Топорно, но работает.
Полученный assignee подставляю в поле owner сделки и в assigned_to задачи.
Ответ во webhook
Самое неочевидное, что многие забывают: фронтенду нужен фидбек. Если форма отправки лида ждёт ответ, я возвращаю в Respond to Webhook не просто { ok: true }, а полезную нагрузку:
{
"status": "ok",
"crm_contact_id": "={{ $json.id }}",
"crm_deal_id": "={{ $('Create Deal').item.json.id }}",
"assignee": "={{ $('Round Robin').item.json.assignee }}"
}
CRM ID потом пригодится фронту для last-touch аналитики, а assignee — чтобы сразу показать клиенту имя и фото менеджера: «С вами свяжется Анна». Конверсия в ответный звонок от такого пустяка растёт ощутимо.
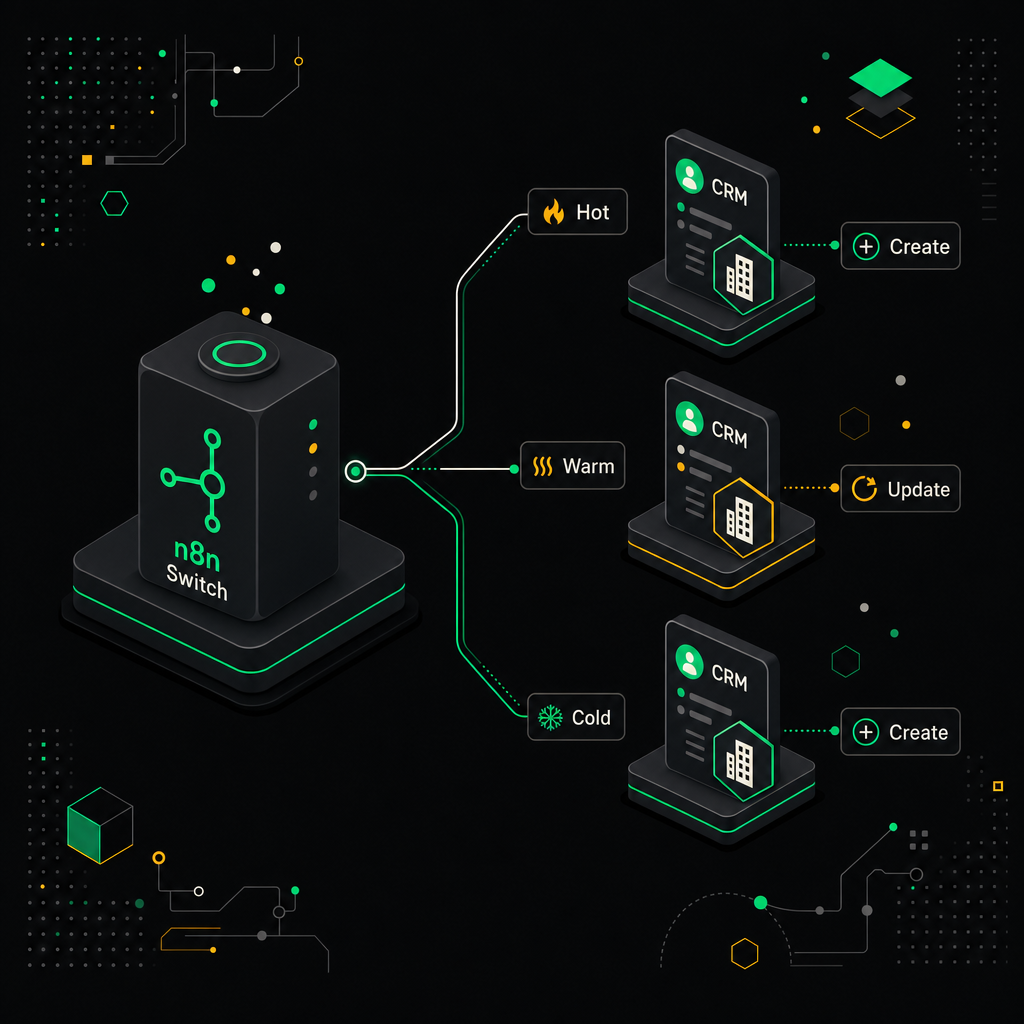
Switch-нода направляет горячих, тёплых и холодных лидов в разные пайплайны HubSpot.
Шаг 5. Уведомления команды и автоответ лиду
Когда лид квалифицирован и попал в CRM, у тебя есть примерно 5 минут, чтобы система отработала раньше, чем конкурент. Здесь два параллельных потока: команда узнаёт о горячем лиде мгновенно, лид получает ответ и не чувствует себя брошенным в пустоту.
Уведомление менеджера в Slack или Telegram
Добавь ноду Slack (или Telegram Bot, если команда там) сразу после записи в CRM. Никакого текста в духе «новая заявка» — это мусор в канале. Делай карточку:
🔥 Hot Lead: {{ $json.name }}
Компания: {{ $json.company }}
Бюджет: {{ $json.budget }}
Источник: {{ $json.utm_source }}
CRM: {{ $json.crm_link }}
Менеджер видит всё за секунду, не открывая CRM. Ссылка на карточку — прямо в сообщении. Для Telegram я обычно ставлю parse_mode: HTML и оборачиваю имя в <b> — читается лучше в мобильном.
Автоответ лиду через Email
Здесь принципиальный момент по таймингу: не отправляй письмо в ту же миллисекунду, когда пришла форма. Можно поставить ноду Wait на небольшую задержку — это выглядит естественнее, чем мгновенный ответ, который явно выдаёт автоматику. Оптимальное значение задержки подбирайте экспериментально для своей аудитории.
В Email-ноде (Gmail, SMTP или SendGrid — разницы в конфигурации почти нет, только в авторизации) шаблон строится через Expressions:
Тема: {{ $json.name }}, получили вашу заявку
{{ $json.name }}, спасибо — всё пришло.
Наш менеджер свяжется с вами в течение 15 минут
по номеру {{ $json.phone }}.
Пока ждёте — вот три кейса по вашей теме: [ссылка]
Персонализация по имени и телефону работает, потому что лид видит: его данные дошли корректно, не просто «заявка принята».
SMS через Twilio для критичных лидов
Если скоринг выдал оценку выше порога — например, enterprise-лид с бюджетом от 500к — добавь ветку с Twilio SMS. Не вместо email, а параллельно. SMS читают быстро. Текст короткий:
{{ $json.name }}, ваша заявка принята.
Иван из команды позвонит вам через 10 минут.
Если неудобно — ответьте на это сообщение.
Twilio-нода принимает To как {{ $json.phone }} — убедись, что номер пришёл в формате E.164 ещё на этапе нормализации данных в шаге 2.
Что проверить перед запуском
Прогони тестовый лид и посмотри на три вещи: пришло ли уведомление в Slack раньше email лиду (должно), сработала ли задержка на автоответе, корректно ли подставились все переменные — особенно $json.crm_link, который часто приходит пустым, если CRM-нода не вернула ID созданной записи.
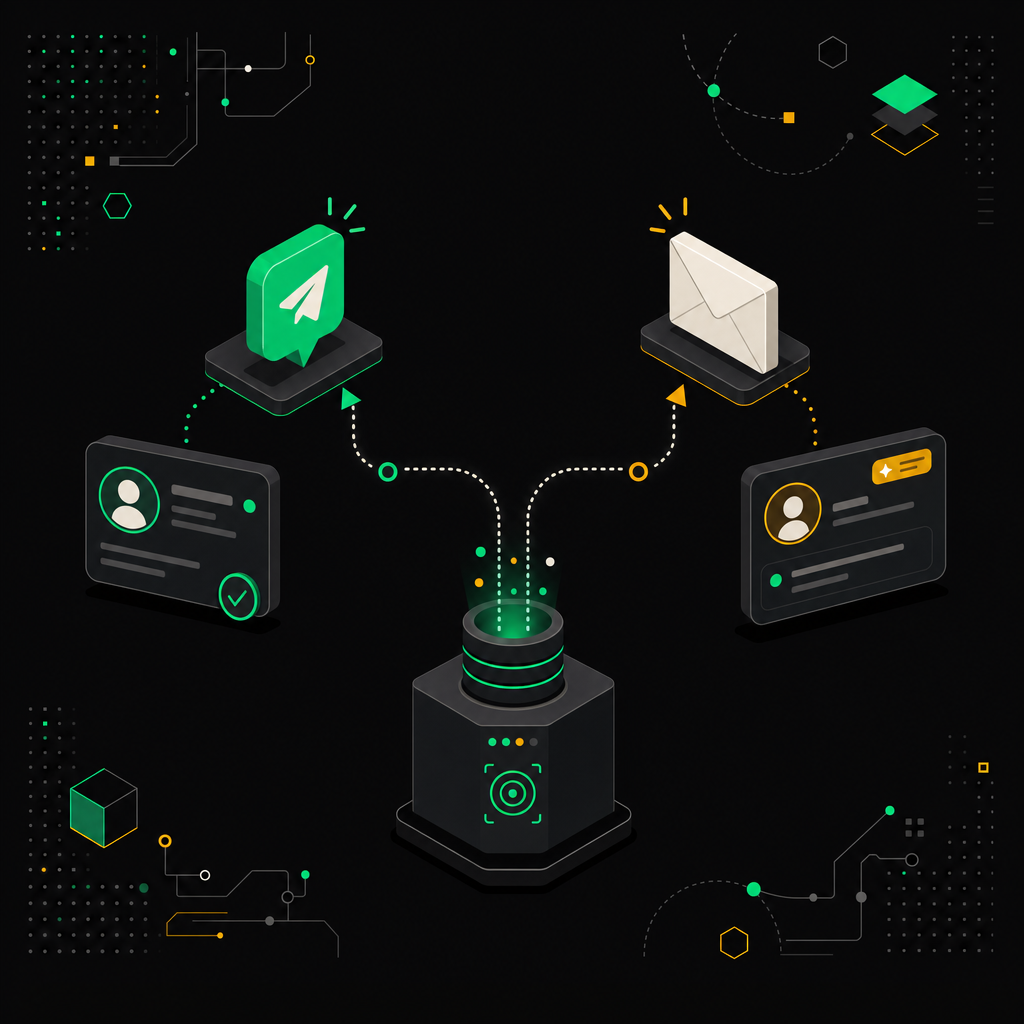
Два параллельных потока одновременно уведомляют менеджера в Slack и отправляют приветственное письмо лиду.
Шаг 6. Прогрев лидов: drip-кампания внутри n8n
Drip-кампания — это единственное место в воронке, где можно всё испортить избыточной автоматизацией. Пять писем за два дня, и лид уходит навсегда. Поэтому начну с логики, а потом с механики.
Запуск — Schedule Trigger с cron-выражением 0 14 * * *. Каждый день

Wait-ноды задают интервалы в 1, 3 и 7 дней между касаниями автоматической email-последовательности.



