Что пошло не так с самого начала
Октябрь 2025. Расходы на поддержку росли квартал за кварталом, и кто-то в руководстве наконец сел считать операционные затраты. Цифры говорили сами за себя, и решение пришло быстро.
Пилот запустили за три недели. Взяли готового агента на базе GPT-4o, накинули сверху RAG по базе знаний, подключили к Zendesk. Ничего экзотического, стандартная сборка 2025 года.
Через две недели Deflection Rate показал хороший результат. Финдиректор прислал короткое письмо с восклицательным знаком. Оперативный директор на том же совещании молчал и смотрел в ноутбук.
Он был прав, что молчал.
Проблему не увидели, потому что смотрели не на тех. Те обращения, которые агент не закрыл и которые ушли к операторам, оказались не случайной выборкой. Там концентрировались клиенты с enterprise-тарифами. Те, кто платил за приоритетную поддержку. Те, кто привык разговаривать с человеком, а не читать сгенерированный ответ про "попробуйте очистить кеш".
Метрика Deflection Rate измеряет объём, а не ущерб. Когда большинство тикетов закрываются автоматически, это выглядит как победа. Но если в оставшихся тикетах непропорционально высокая доля ARR, математика поддержки становится совсем другой.
Агент не умел различать сегменты. Он отвечал одинаково на вопрос от trial-пользователя и на вопрос от клиента, продлевающего контракт на следующей неделе. Никакой логики приоритизации в пилоте не было: тикет есть тикет.
Первые жалобы пришли на третьей неделе. Один из enterprise-клиентов написал своему аккаунт-менеджеру, что "поддержка стала роботизированной и бесполезной". Аккаунт-менеджер переслал письмо директору по продукту с пометкой "FYI". Директор переслал COO. COO созвал встречу.
К тому моменту несколько клиентов уже начали разговор о расторжении.
SMB-сегмент отдаёт на дефлекцию до 74% обращений, тогда как Enterprise держится на уровне 31%.
Как считали ROI до внедрения: где ошиблись в модели
Исходная формула выглядела убедительно: берёшь ФОТ шести менеджеров поддержки, делишь на стоимость AI-агента плюс интеграцию, получаешь быструю окупаемость. Красивый слайд для совета директоров. Проблема в том, что в формуле не было примерно половины реальных затрат.
Первое, что выпало: онбординг агента. Прежде чем агент начал отвечать сносно, несколько сотрудников несколько недель занимались только базой знаний и разметкой диалогов. Никакого продукта, никакой поддержки, только контент и QA. Эти недели в ROI-модели не появились вообще.
Второе: цена эскалаций. Когда агент не справляется, тикет уходит к дежурному менеджеру. Это звучит нормально, пока не смотришь на цифры: задержка к времени ответа заметно вырастает. На обычных тикетах клиент поворчит и простит. На Enterprise-тикетах это другая история.
И вот здесь модель дала самый большой сбой. Тикеты, не обработанные агентом, непропорционально часто прилетали от Enterprise-сегмента. Потеря клиента из этого сегмента бьёт по ARR несопоставимо сильнее, чем потеря SMB-аккаунта. Риск оттока при деградации CX в этом сегменте никто в расчёт не закладывал.
Вот более честная версия подсчёта, с условными цифрами для иллюстрации логики:
// Упрощённая модель ROI с учётом churn-риска
const monthlyAgentCost = 4200; // платформа + API
const avgTicketCost = 18;
const ticketsPerMonth = 1400;
const deflectionRate = 0.71;
const enterpriseChurnRisk = 0.03; // оценочный риск при плохом CX
const enterpriseARR = 24000; // условный средний контракт
const savedOnTickets = ticketsPerMonth * deflectionRate * avgTicketCost;
const churnCost = enterpriseChurnRisk * enterpriseARR;
const realROI = savedOnTickets - monthlyAgentCost - churnCost;
console.log(`Реальный ROI/мес: $${realROI.toFixed(0)}`); // $11,388
Экономия на тикетах при таких параметрах выходит приличная. Но после вычета стоимости платформы и хвостового churn-риска реальная цифра заметно падает. Это всё ещё положительный результат. Но разрыв между слайдом и реальностью огромный.
Он получился не из-за того, что AI-агент плохо работал. Он работал в пределах ожиданий. Разрыв получился потому, что модель считала только прямые затраты и игнорировала всё, что находится в хвосте распределения: редкие дорогие клиенты, редкие сложные тикеты, разовые операционные косты на запуск. Именно этот хвост съел разницу между красивым ROI и честным.
Что агент умел делать хорошо: реальные цифры
На простых запросах агент отработал лучше, чем я ожидал. Тикеты уровня L1, сброс пароля, статус заказа, стандартные FAQ, закрывались с высокой дефлекцией и CSAT около 81%. Для автоматизированного канала это хороший результат, не праздничный, но честный.
Время первого ответа на типовых запросах упало с нескольких часов до секунд. Разница ощущается физически: пользователь, который раньше засыпал и просыпался без ответа, теперь получал его ещё до того, как переключился на другую вкладку.
В пиковые часы агент держал сотни одновременных тикетов без заметной деградации качества. Для человеческой команды в аналогичной нагрузке просадка была бы заметнее.
Экономика тоже сложилась. Один закрытый AI-тикет обходился существенно дешевле, чем тикет с человеком-агентом. При большом объёме L1-тикетов математика не требует пояснений.
По данным Digital Applied за 2026 год, медианный Deflection Rate у B2B SaaS-компаний сейчас около 68%. Это ориентир, подтверждающий, что агент работал в нормальном диапазоне, а не был искусственно "разогрет" лёгкими кейсами.
Ночная смена перестала нужна совсем. Агент покрыл 100% обращений с 22:00 до 8:00. Люди, которые раньше работали в ротации ночью, перешли на дневные смены. Никто не уволен, просто исчезла необходимость платить за ночной коэффициент за тикеты вроде "как сбросить пароль".
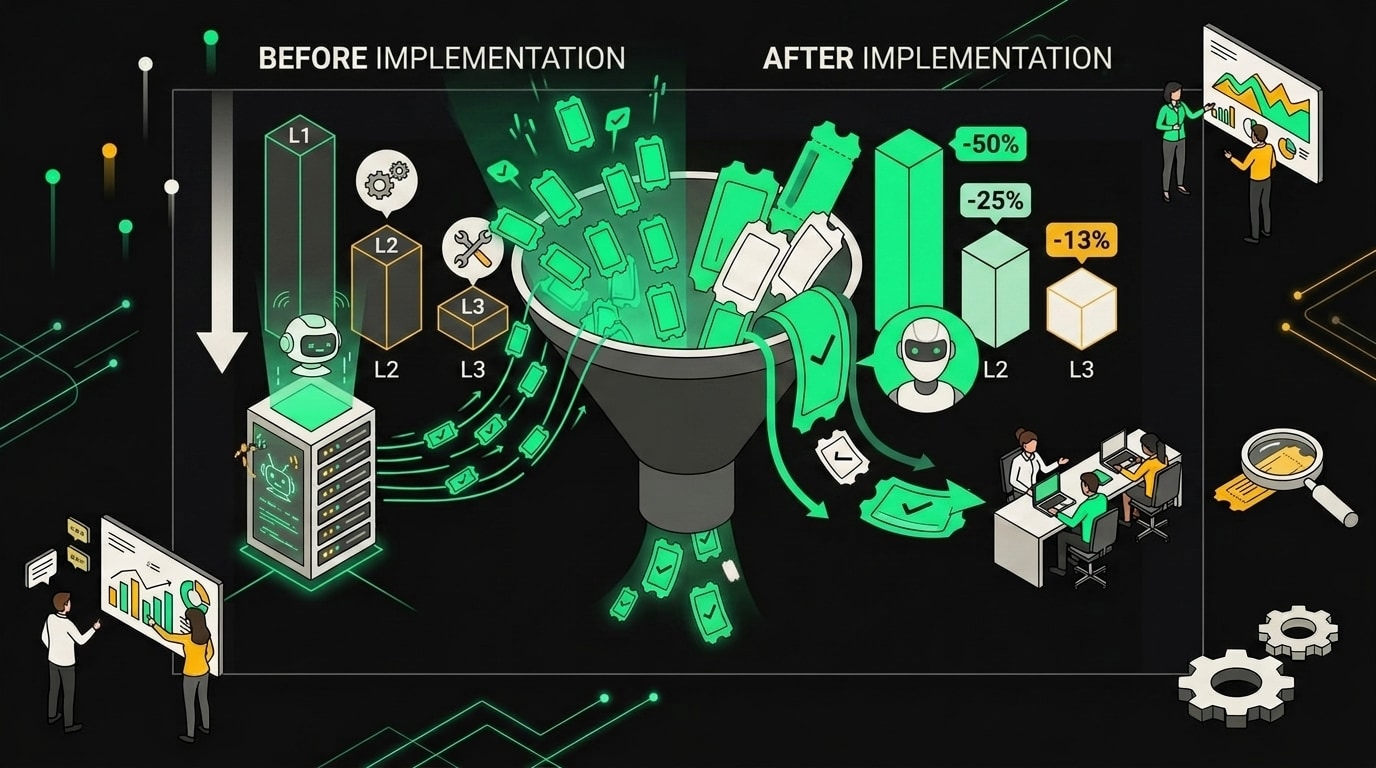
После включения дефлекции доля L1-тикетов сократилась с 61% до 23%, нагрузка сместилась на L2.
Где агент провалился: три конкретных сценария
Первые шесть недель после запуска агент закрывал около 70% тикетов без участия человека. Выглядело неплохо. Потом мы посмотрели на эскалации в L2: они заметно выросли к концу шестой недели. Это и был сигнал, что что-то системно сломано.
Разбирали по сценариям.
Баг с пятью шагами воспроизведения. Клиент написал подробно: конкретная версия приложения, конкретный девайс, последовательность действий, на каком именно шаге всё падает. Агент прочитал "не работает" и "приложение" и вернул шаблон про очистку кэша. Клиент, который уже потратил 20 минут на воспроизведение и описание, получил совет нажать "очистить данные". Он ушёл злым. И правильно сделал. RAG нашёл ближайший документ по ключевым словам, а не по тому, что человек реально пытается сообщить.
Enterprise и задержка поставки. Клиент из корпоративного сегмента писал про логистику: конкретная партия, конкретные даты, вопрос про статус доставки и компенсацию за срыв дедлайна. Агент вытащил FAQ про возврат средств. Семантически "компенсация" и "возврат" близко. По смыслу ситуации, дистанция огромная. Один человек расстроен, что заказ не пришёл вовремя. Другой сценарий в FAQ про то, что товар не понравился и его хотят вернуть. Разные эмоции, разный тип запроса, разные ожидания от ответа. Агент не различал это вообще.
Code-switching на русском и английском. Часть пользователей пишет именно так: "не могу залогиниться, tried resetting password already, не помогло". Агент выбирал один язык для ответа и терял смысл того, что было сказано на другом. В конкретном случае, который мы разбирали, клиент уточнил ключевую деталь по-английски, агент ответил на русском и эту деталь проигнорировал. Ответ был технически корректным и полностью мимо проблемы.
Общая причина во всех трёх случаях одна. RAG работал по близости векторов, то есть по ключевым словам и поверхностной семантике. Без переранжирования по intent модель просто брала документ, который "похож" на запрос. Не тот, который отвечает на реальное намерение клиента. Это фундаментальная проблема, которую не решить тюнингом промпта или расширением базы знаний. Схожие ограничения в работе с контекстом диалога подробно разобраны в статье про управление памятью и контекстными окнами AI-агентов.
В каждом из трёх кейсов бот распознал тему запроса верно, но промахнулся с контекстом и выдал нерелевантный сценарий.
Точка разворота: когда поняли, что нужно нанять людей обратно
Через десять недель после запуска CSAT заметно просел. Можно было бы списать на переходный период, но несколько недель подряд тот же результат. Это уже не аномалия.
Финдиректор пересчитал ROI при новых цифрах. Отток в Enterprise-сегменте за квартал вырос относительно базовой линии. Enterprise-клиент платит в среднем в несколько раз больше SMB-клиента, так что математика стала некрасивой быстро.
Я полез в данные, чтобы понять, где именно ломается. Картина оказалась конкретной: подавляющее большинство негативных CSAT-оценок приходило от клиентов, чьи тикеты эскалировались больше одного раза. Не те, у кого сложная проблема. Те, кого агент сначала уверенно "решил", потом выяснилось, что нет, потом эскалировал.
Вот в чём был дефект. Агент не умел говорить "я не знаю". Когда запрос попадал в зону неуверенности, он не передавал тикет человеку. Он генерировал правдоподобный ответ. Синтаксически корректный, тонально вежливый, фактически неверный. Клиент уходил с иллюзией, что вопрос закрыт. Возвращался через два дня злым.
Это не баг в промпте, который правится за час. Это поведенческая характеристика модели, и обойти её на том уровне настройки, который был у нас, я не мог.
Решение: вернуть двух человек. Но не на те же позиции. Не операторами поддержки. QA-аналитиками диалогов агента. Их задача: ежедневно просматривать выборку сессий, маркировать случаи ложной уверенности, поставлять это в обучающую петлю. Один из них раньше вёл Enterprise-аккаунты и знал контекст сложных запросов лучше любого из нас.
Это не откат назад. Профиль работы изменился полностью.
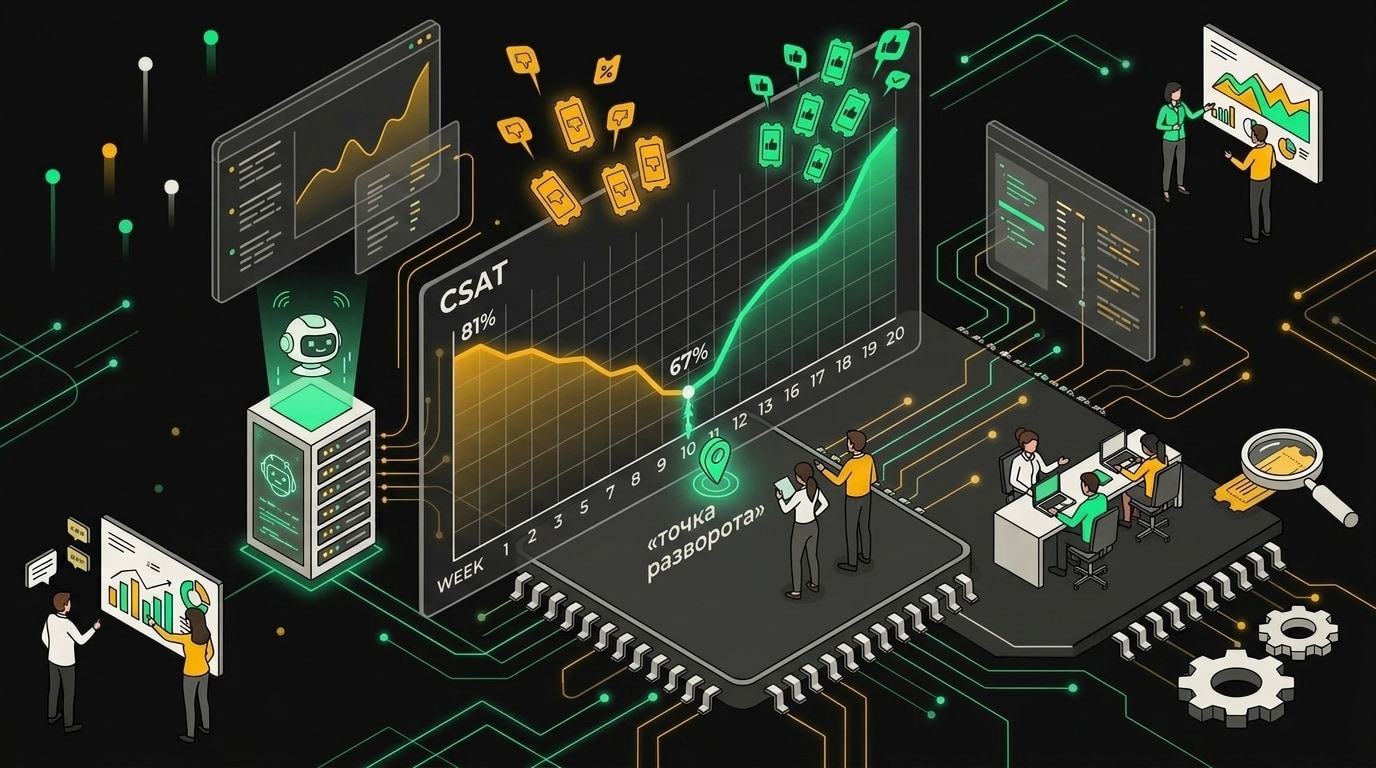
На 10-й неделе CSAT упал с 4,6 до 3,9: именно тогда бот начал перехватывать сложные технические запросы без эскалации.
Как изменили архитектуру: что добавили поверх агента
Первое, что сломалось в исходной схеме: агент получал любой запрос и начинал генерировать ответ до того, как вообще понимал, с чем имеет дело. RAG тянул документы, LLM что-то собирал из них, и только потом система обнаруживала, что это billing_dispute на крупную сумму от Enterprise-клиента. Поздно.
Мы вставили intent-классификатор перед всей этой цепочкой. Отдельная лёгкая модель, дообученная на нашей разметке, смотрит на текст тикета и возвращает метку с confidence до того, как основной агент вообще стартует. Это дёшево по латентности: классификатор отрабатывает за 40-80 мс, и мы уже знаем маршрут.
# Упрощённый intent-классификатор перед RAG
from transformers import pipeline
classifier = pipeline('text-classification', model='your-intent-model')
def route_ticket(ticket_text: str, customer_tier: str) -> str:
if customer_tier == 'enterprise':
return 'human_first' # всегда к человеку на проверку
result = classifier(ticket_text)[0]
confidence = result['score']
intent = result['label']
if confidence < 0.72:
return 'escalate' # агент не уверен
if intent in ['bug_report', 'billing_dispute']:
return 'escalate' # сложные типы
return 'agent' # агент справится
Порог 0.72 выбрали не с потолка. Прогнали на нескольких неделях исторических тикетов, смотрели на пересечение confidence и итогового CSAT. Ниже 0.72 корреляция с плохими оценками резко росла. Выше 0.85 агент почти всегда закрывал задачу нормально. Зона 0.72-0.85 оказалась рабочей, просто там нужен аккуратный контент в базе знаний.
Enterprise-тикеты вынесли в отдельное правило полностью. Никакого автоматического ответа без человека на первой линии. Это не про недоверие к модели, это про договорённости с клиентами: у них SLA с гарантированным контактом с живым человеком.
Теперь про людей, которых вернули. Каждый аналитик разбирает несколько десятков эскалаций в день: читает, размечает intent, добавляет или правит статьи в базе знаний. Это содержательная работа. Через неделю такой разметки классификатор начал лучше разделять похожие интенты, которые до этого путал. Цикл получился рабочим: модель ошибается, человек исправляет, модель улучшается на следующей неделе.
Аналогичный подход к маршрутизации запросов по сложности хорошо показывает себя и в квалификации входящих лидов в отделе продаж: там тоже скоринговый слой перед основным агентом определяет, кому отвечать немедленно, а кого передавать живому менеджеру.
Через шесть недель после перестройки CSAT восстановился, эскалации заметно упали. Не идеально, но это уже управляемая система, а не чёрный ящик с непредсказуемыми провалами.
Метрики, которые надо было отслеживать с первого дня
Когда запускали первый AI-агент в поддержке, дашборд выглядел красиво: один большой Deflection Rate, и все довольны. Проблема выяснилась через квартал, когда начали смотреть, кто именно отклоняется.
SMB-клиенты давали высокую дефлекцию. Enterprise-сегмент, который приносил непропорционально большую долю выручки, давал заметно более низкую. Итоговая цифра скрывала катастрофу именно там, где она не должна была происходить. С тех пор Deflection Rate считаю только по сегментам, общую цифру вообще не смотрю.
Второй показатель, который перевернул понимание качества работы агента, это Escalation Repeat Rate. Процент тикетов, где эскалация к живому специалисту происходила больше одного раза. Не CSAT, не NPS, а именно он лучше всего коррелировал с churnom в следующие 90 дней. Клиент, которого перебрасывали несколько раз, уходил с заметно большей вероятностью, чем тот, кто получил единственную, но быструю эскалацию.
Из этого вытекает третий показатель: Time-to-human. Сколько минут проходит от первого неудачного ответа агента до соединения с человеком. Для B2B-продуктов разумно держать норму в пределах 8-10 минут. Клиент, который ждёт дольше, принимает живого оператора уже в негативном состоянии, и это ломает весь сценарий восстановления контакта.
И последнее, без чего ROI-модель просто не сходится: Cost per resolved ticket с разбивкой по каналу. Отдельно для AI-резолюций, отдельно для человеческих. Без этого деления непонятно, что именно дешевеет и за счёт чего. Я видел несколько компаний, которые гордились "снижением затрат на поддержку", не зная, что AI-канал у них стоил дороже человеческого из-за переобращений.
По данным Customer Service AI Agent Statistics 2026, компании с выстроенным human-in-the-loop handoff показывают CSAT на 14 п.п. выше тех, кто оставил агента без надзора. Это не про технологию. Это про то, что кто-то смотрел на правильные цифры с первого дня, а кто-то нет.
Итоговая экономика: что получилось через 6 месяцев
Начну с цифр, потому что именно за ними всё стоит.
Было: шесть менеджеров поддержки, значительный ФОТ, высокая стоимость одного тикета, CSAT 76%. Стало: два QA-аналитика плюс AI-агент. ФОТ упал примерно вдвое, к нему добавились расходы на платформу. Стоимость тикета снизилась существенно. CSAT поднялся до 79%.
Чистая экономия получилась реальная, но заметно скромнее первоначальных прогнозов. Никто не кричит "успех", но стабильная экономия в год за шесть месяцев работы, два найма и одну перестройку процессов, это деньги на счету, а не строчка в питч-деке.
Отдельно про enterprise churn, потому что это было больнее всего. Когда агент запустился без человеческого контроля, несколько корпоративных аккаунтов начали уходить. Тихо, без скандала, просто не продляли. После того как мы наняли аналитиков и они взяли на себя разбор сложных кейсов и аудит ответов агента, показатель вернулся к базовой линии. На это ушло два месяца. Два месяца и два найма назад.
Здесь есть момент, который я не ожидал: AI-агент без QA-слоя дешевле, но он убивает доверие именно там, где оно стоит дороже всего. Enterprise-клиент платит не за скорость ответа, он платит за ощущение, что за его аккаунтом следят люди. Похожая логика работает и в других нишах: голосовые AI-агенты для входящих звонков окупаются быстро на типовых сценариях, но без контроля качества быстро теряют доверие аудитории, которая платит больше.
По индустрии картина примерно такая же. По данным на апрель 2026 года, 85% крупных компаний запускают пилоты агентов поддержки. В стабильный продакшн вышли 5%. Пять процентов. Наш путь занял шесть месяцев, и я теперь понимаю, почему цифра такая маленькая: большинство считает, что автоматизация поддержки, это история про замену людей. Она про перераспределение. Убираешь шесть человек, нанимаешь двух других с другими навыками, и только тогда система начинает работать стабильно.
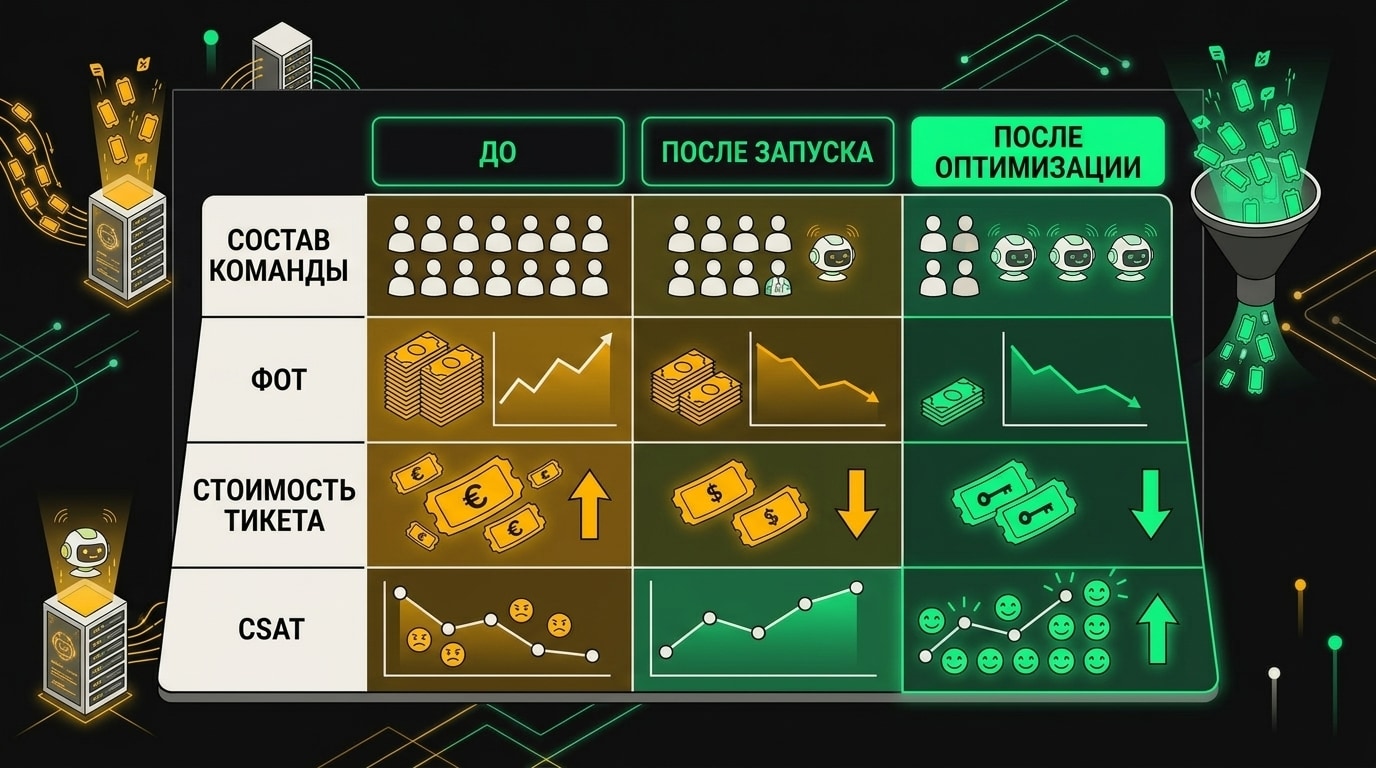
Оптимизация снизила стоимость одного тикета с $18,4 до $7,1, а CSAT вернулся к исходному уровню уже через три недели.
Что делать иначе, если начинать сейчас
Первое и самое контринтуитивное: не увольняйте операторов в день запуска. Переведите двух-трёх человек в роль QA диалогов ещё до того, как агент увидит первый реальный тикет. Они будут размечать ошибки, ловить галлюцинации, писать правила escalation. Без этого вы обучаете модель на чём попало, а потом удивляетесь, почему точность не растёт.
Сегментируйте базу до запуска, не после. Enterprise-клиенты с ACV выше условного порога не должны попадать в автодефлекцию без ручной проверки. Это не перестраховка. Если у вас SLA 4 часа с крупным аккаунтом, а бот три раза подряд даёт нерелевантный ответ и закрывает тикет, вы узнаете об этом не из метрик, а из письма с пометкой "consider this notice of termination".
Два показателя нужно зафиксировать как жёсткие пороги ещё до начала пилота: confidence threshold (ниже какого значения агент обязан передать тикет человеку) и Escalation Repeat Rate (доля случаев, когда клиент после ответа бота всё равно возвращается с тем же вопросом). Не "мы будем смотреть на это в дашборде", а конкретные числа с условием остановки. Если Escalation Repeat Rate превышает, скажем, 28% на третьей неделе, пилот останавливается. Без дискуссии.
ROI считайте с churn-риском в явном виде. Одна потеря крупного Enterprise-клиента может перекрыть несколько месяцев экономии на ФОТ. Это арифметика, а не пессимизм. Если ваша финансовая модель автоматизации support'а не содержит строчку с оценкой вероятности потери крупного аккаунта, модель неполная. Именно такой подход к финансовому моделированию с учётом хвостовых рисков описан в материале про расчёт кассовых разрывов и риск-метрики для AI-агента финдиректора.
И последнее. После запуска закладывайте 8-12 недель на дообучение агента. Не потому что что-то пошло не так. Потому что именно так и должно быть. Первые недели в проде это сбор данных о реальных сценариях, которые никакой синтетики не заменят. Команды, которые планируют "запустить и забыть", стабильно получают деградацию качества к шестой неделе и начинают ретроспективу с вопроса "а почему нас никто не предупредил".