

Как это работает: архитектура решения за 2 минуты
Звонок завершился. Телефония бросает webhook на n8n. Дальше всё автоматически.
n8n здесь выступает оркестратором: он принимает запрос, вытаскивает аудиофайл, прогоняет его через Whisper large-v3 и затем отправляет полученный текст в LLM. Финальный шаг: запись результата через amoCRM API прямо в карточку сделки или контакта.
Три компонента, которые держат всю схему. Первый: n8n как центральная нервная система, которая склеивает все части и обрабатывает ошибки. Второй: Whisper large-v3, модель транскрибации от OpenAI, запущенная локально или через API, она понимает русскую речь с акцентами, перебиванием и фоновым шумом заметно лучше предыдущих версий. Третий: amoCRM API, куда всё и складывается.
В карточке менеджер видит четыре вещи: полный текст разговора, саммари на 3-5 предложений, тональность (позитивная, нейтральная, конфликтная) и конкретный следующий шаг, который LLM вытащил из контекста разговора. Не "клиент заинтересован", а "клиент просил перезвонить в пятницу после 15:00 с расчётом по трём позициям".
По времени обработки: конкретные цифры зависят от длины записи, нагрузки на сервер и способа запуска (API или self-hosted). На практике пайплайн обычно укладывается в несколько минут после завершения звонка, а менеджер видит заполненную карточку, не дожидаясь ручной работы.
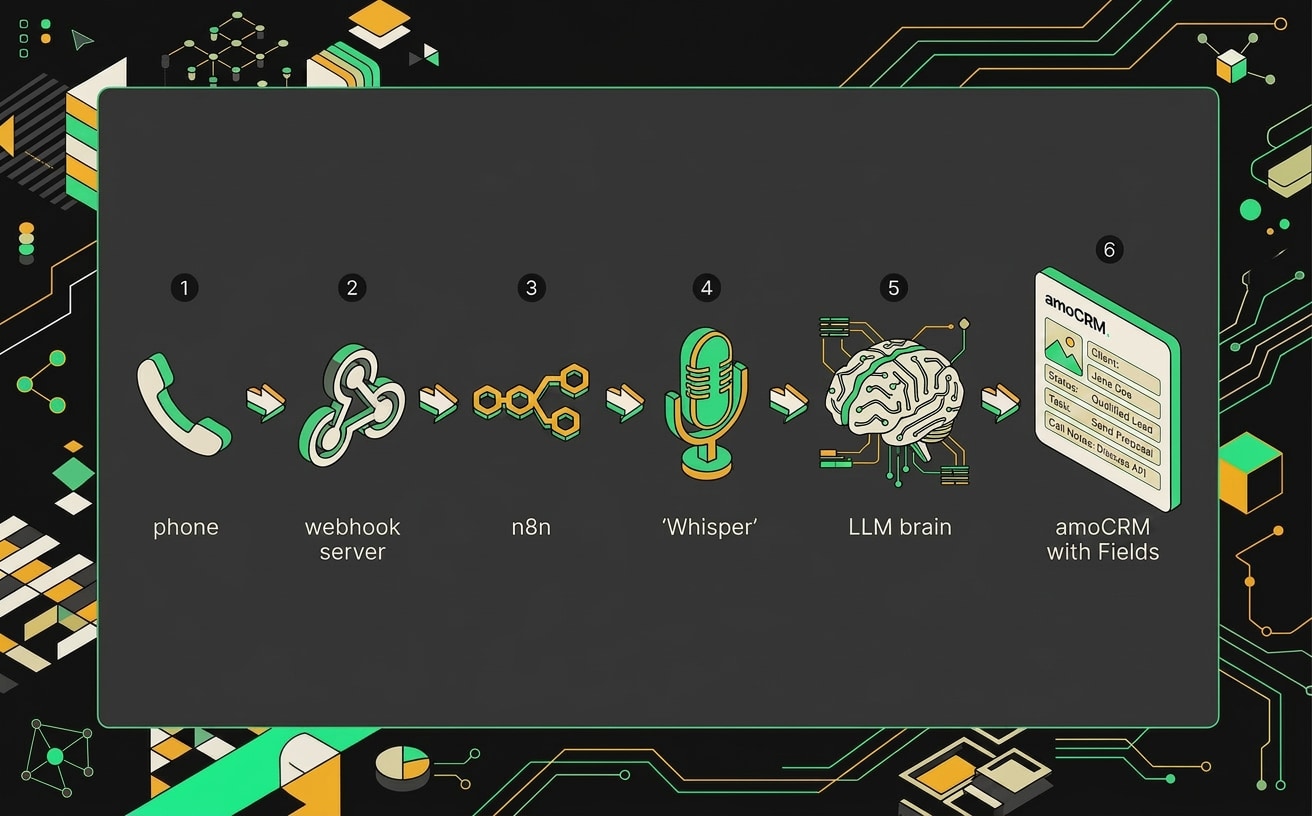
Общая архитектура пайплайна: аудиофайл проходит через шесть узлов от загрузки до финального отчёта в базе данных.
Что нужно подготовить до старта
Начну с того, что половина проблем при интеграции возникает не в коде, а в подготовке. Поэтому пройдёмся по каждому компоненту заранее, а не в момент, когда воркфлоу уже не работает.
amoCRM. Нужен аккаунт с правами администратора. Без них не получится создать интеграцию в разделе «Настройки -> Интеграции». Там регистрируешь приложение, получаешь client_id, client_secret и указываешь redirect_uri. Авторизация через OAuth 2.0: после первого кода авторизации получаешь пару токенов. Access Token живёт 24 часа, Refresh Token дольше, но тоже протухает при долгом неиспользовании. Оба храни в n8n Credentials (раздел "HTTP Request" или отдельный credential-тип). Не тащи их в переменные воркфлоу и тем более не хардкодь в узлах. Если токены утекут в логи n8n, придётся перевыпускать всё заново.
n8n. В 2026 году актуальная ветка 1.x. Self-hosted вариант предпочтителен, если данные звонков не должны покидать контур компании. В 1.x нативно работают AI-агенты и langchain-узлы, что понадобится позже при разборе транскрипта. Облачный n8n тоже подходит, но тогда проверь, что Whisper-запросы и вебхуки от телефонии укладываются в тайм-ауты плана.
Транскрипция. Два реалистичных варианта. Первый: OpenAI API, модель whisper-1, быстро и без инфраструктуры, но данные уходят к OpenAI. Второй: self-hosted Whisper через библиотеку faster-whisper с моделью large-v3, всё остаётся у тебя, но нужна GPU или мощный CPU. Для русской речи есть нюанс: качество на реальных звонках (шум, акцент, перебивания) заметно отличается от результатов на чистых датасетах. GigaAM от SberDevices обучен специально на русской речи и, по публикуемым результатам, показывает меньший WER на русскоязычном аудио. Если точность транскрипта критична, а в итоговом резюме будут имена клиентов и суммы сделок, GigaAM стоит рассмотреть отдельно.
Телефония. Нужна система, которая после завершения звонка отправляет webhook с URL записи. Mango Office, Sipuni, Zadarma это умеют. Уточни формат вебхука заранее: где именно лежит ссылка на файл, в каком поле передаётся номер телефона, есть ли подпись запроса для верификации. Sipuni, например, шлёт ссылку на запись с задержкой до нескольких минут после события call.completed. Это влияет на логику воркфлоу: файл нельзя скачивать сразу.
Когда всё это есть и проверено руками, можно открывать n8n и строить первый узел.
Настройка интеграции amoCRM: OAuth и получение токенов
Начну с того, что amoCRM использует OAuth 2.0 с нюансами, которые не всегда очевидны из документации. Разберём по шагам.
Создание интеграции
Заходишь в аккаунт amoCRM: Настройки -> Интеграции -> кнопка "Создать интеграцию". Указываешь название, разрешения (обычно нужны контакты, сделки, задачи) и, самое главное, redirect_uri. Это адрес, куда amoCRM отправит код авторизации после того, как пользователь даст доступ. Для локальной разработки можно указать https://localhost, но для production ставь реальный endpoint своего приложения.
После сохранения получаешь client_id и client_secret. Сохрани их сразу: client_secret показывается один раз.
Получение кода авторизации
Открываешь в браузере URL вида:
https://{subdomain}.amocrm.ru/oauth?client_id=xxxxxxxx&mode=post_message
После подтверждения доступа amoCRM редиректит на твой redirect_uri с параметром code в строке запроса. Этот код живёт 20 минут и одноразовый.
Обмен кода на токены
Делаешь POST-запрос:
POST https://example.amocrm.ru/oauth2/access_token
Content-Type: application/json
{
"client_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"client_secret": "your_client_secret",
"grant_type": "authorization_code",
"code": "def50200...",
"redirect_uri": "https://your-app.com/oauth"
}
В ответ получаешь два токена: access_token и refresh_token. Access Token живёт 24 часа, Refresh Token - 3 месяца. Если Refresh Token протухнет, придётся проходить весь браузерный флоу заново вручную.
Автообновление токенов в n8n
Вот где большинство спотыкается. В n8n нет встроенной логики автообновления для amoCRM через Header Auth, поэтому строишь её сам. Перед каждым блоком работы с API добавляешь HTTP Request ноду с grant_type refresh_token:
{
"client_id": "{{ $credentials.clientId }}",
"client_secret": "{{ $credentials.clientSecret }}",
"grant_type": "refresh_token",
"refresh_token": "{{ $node['GetStoredToken'].json.refresh_token }}"
}
Новый access_token из ответа передаёшь дальше по воркфлоу через Set ноду и используешь в заголовке Authorization: Bearer {token}.
Refresh Token тоже обновляется при каждом рефреше, поэтому его нужно сохранять обратно. Куда хранить? Варианта два: отдельная база (даже простая Google Sheet подойдёт для небольших проектов) или n8n-переменные через Static Data если используешь self-hosted версию. О типичных проблемах при двусторонней синхронизации данных между сервисами и хранилищами стоит почитать отдельно: там разобраны конфликты записей и race condition, которые возникают при параллельных обновлениях.
Хранение credentials в n8n
Если используешь community node для amoCRM (ищи n8n-nodes-amocrm на npm), там есть встроенный тип Credentials, который принимает client_id, client_secret и refresh_token напрямую. Это удобнее.
Для кастомного подхода через HTTP Request ноды создаёшь Credential типа "Header Auth": Name = Authorization, Value = Bearer your_access_token. Но тогда автообновление полностью на твоей совести, как описано выше.
Один практический момент: субдомен в URL (example.amocrm.ru) должен быть именно тем аккаунтом, для которого выдан токен. Токен не работает кросс-аккаунтово, даже если client_id совпадает.
Построение n8n воркфлоу: от webhook до транскрибации
Начну с того, как выглядит весь пайплайн в сборе, а потом пройдусь по каждому шагу.
Телефония присылает POST-запрос сразу после завершения звонка. Webhook нода в n8n принимает его и ждёт конкретные поля в теле: phone, record_url, duration, call_id. Без record_url дальше идти некуда, так что если поле пустое, я сразу роутю запрос в ветку с ошибкой и логирую в базу. Проверку лучше сделать прямо в Webhook ноде через Expression, не городить отдельную IF ноду для такой мелочи.
Шаг второй: скачиваем аудио. HTTP Request нода, метод GET, URL берём из {{ $json.record_url }}, Response Format выставляем в File. Это принципиальный момент: если оставить JSON или Text, Whisper получит бинарник в base64 или вообще мусор. Файл должен прийти как бинарные данные в поле data с правильным mimeType. Многие телефонии отдают mp3 или wav, Whisper жует оба формата нормально.
Шаг третий: транскрибация. Тут два варианта в зависимости от инфраструктуры.
Если работаешь через OpenAI API: нода OpenAI, раздел Audio, действие Transcribe. В параметрах выставляешь language: ru и response_format: verbose_json. Второй формат критичен: он возвращает не просто текст, а массив сегментов с таймстампами start и end. Это пригодится позже, когда будешь привязывать реплики к конкретным моментам звонка.
Если хочешь self-hosted faster-whisper: HTTP Request нода на локальный эндпоинт, обычно http://localhost:9000/asr. Тело запроса: multipart/form-data, передаёшь файл из предыдущей ноды через {{ $binary.data }}. Параметры те же: язык и verbose_json. Конкретное время обработки зависит от конфигурации сервера и длины записи, поэтому лучше замерить его на своём железе в процессе тестирования.
После транскрибации ставлю IF ноду с простым условием: длина текста больше 50 символов. Звонки короче этого порога обычно либо ошибочные соединения, либо молчание на линии, либо фоновый шум, который Whisper распознал как пустоту. Их незачем гнать дальше в LLM. Короткие транскрипты уходят в отдельную ветку: пишу в лог call_id, длину транскрипта и причину пропуска. Это помогает потом разбирать статистику брака.
Длинные транскрипты идут в пятый шаг: LLM нода для генерации саммари. На входе передаю полный текст транскрипта и метаданные звонка из первого шага: номер телефона, длительность, дату. Промпт и параметры LLM разберу в следующей секции.
Одна практическая деталь по всему воркфлоу: включи Continue on Error на HTTP Request ноде, которая скачивает аудио. Телефония иногда присылает record_url, по которому файл ещё не готов, запись всё ещё пишется на сервере. В таком случае лучше поймать ошибку, подождать через Wait ноду 30-60 секунд и повторить попытку, чем уронить весь воркфлоу. Кстати, именно некорректная обработка подобных краевых случаев при миграции данных через n8n, частая причина серьёзных инцидентов: разбор одного такого случая с потерей 2300 записей покажет, какие проверки нужно ставить заранее.
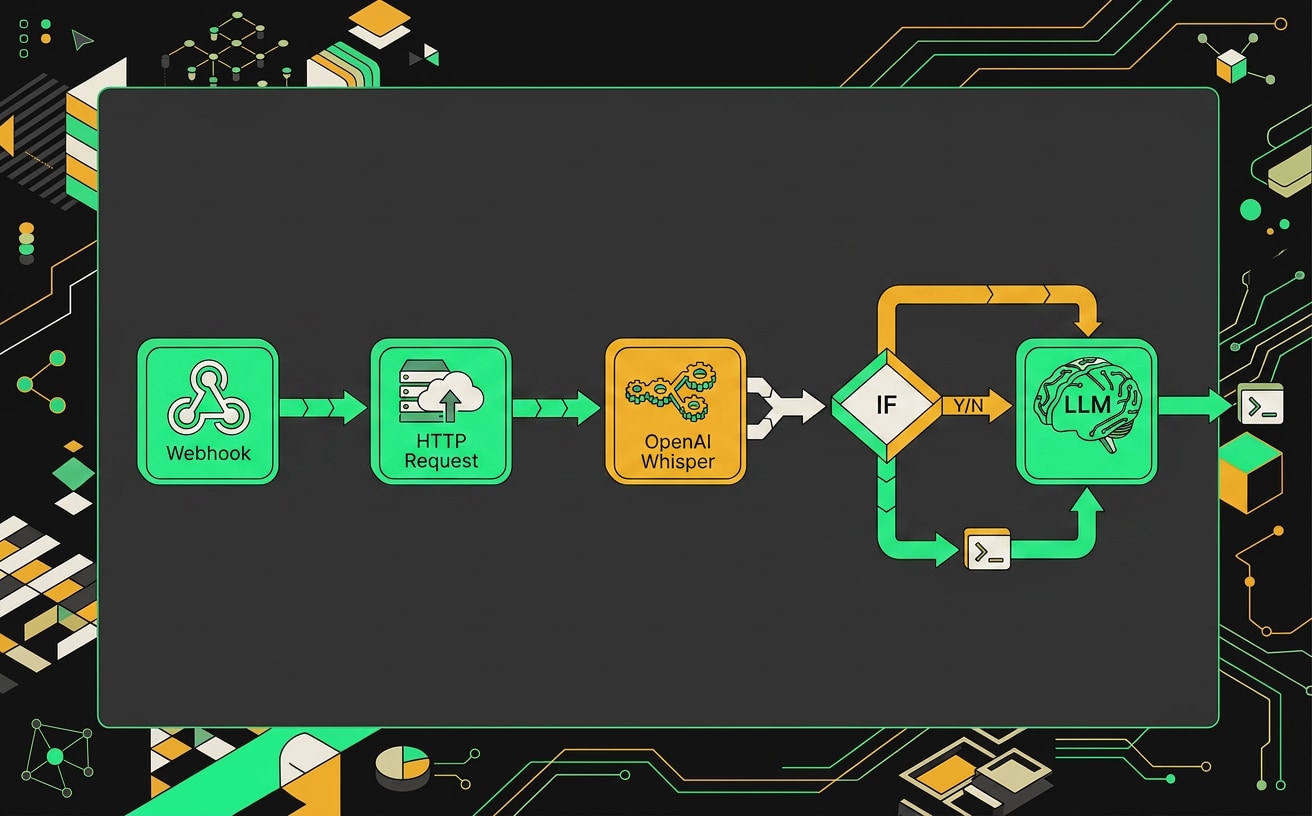
В n8n каждый шаг обработки звонка оформлен отдельным узлом, что позволяет перезапускать любой этап без потери промежуточных результатов.
Промпт для LLM: как получить структурированное саммари
Самая частая ошибка при работе с LLM в продакшне: просишь модель "напиши саммари", получаешь свободный текст, потом пытаешься его распарсить регулярками. Это работает до первого нестандартного ответа, а потом ломается в самый неподходящий момент.
Правильный путь: Structured Output. OpenAI добавила его в середине 2024-го, и с тех пор у меня в пайплайнах парсинг-ошибок нет буквально ноль. Модель возвращает JSON, который валидируется по схеме ещё до того, как попадает в твой код.
Для саммари звонков GPT-4o-mini справляется полностью. GPT-4o стоит примерно в 10 раз дороже за токен, и разница в качестве для этой задачи практически незаметна. Я перевёл на mini ещё в конце 2024-го и не пожалел.
Промпт строится из нескольких обязательных частей. System prompt задаёт роль и контекст: кто ты, какая компания, какие типовые продукты. Это критично, потому что без контекста модель будет интерпретировать отраслевые термины по-своему. User message содержит транскрипт и требование вернуть только JSON.
Вот рабочая структура промпта:
System:
Ты ассистент для анализа звонков менеджеров по продажам.
Верни JSON строго по схеме:
{
"summary": "краткое изложение разговора, 3-4 предложения",
"next_action": "конкретный следующий шаг для менеджера",
"sentiment": "positive | neutral | negative",
"key_topics": ["массив из 2-4 ключевых тем"]
}
User:
Вот транскрипт звонка:
{{transcript}}
Ответь только JSON, без пояснений.
Четыре поля покрывают всё, что нужно CRM: summary идёт в карточку сделки, next_action создаёт задачу менеджеру, sentiment обновляет статус лида, key_topics тегируют звонок для аналитики.
Отдельно про ограничение "не придумывать факты". Его нужно прописывать явно в system prompt: "Если информация не упомянута в транскрипте, пиши null или пустую строку, не додумывай". Без этого модель честно старается быть полезной и заполняет пробелы тем, что кажется вероятным. В CRM это катастрофа: менеджер видит задачу "перезвонить во вторник" и думает, что клиент сам об этом просил.
Ещё один момент по key_topics. Я ограничиваю массив 2-4 элементами намеренно. Больше тем обычно означает, что модель теряет фокус и добавляет очевидные вещи вроде "разговор" или "продажи". Меньше двух - скорее всего звонок был очень коротким, и тогда саммари в три-четыре предложения всё равно покроет всё нужное.

LLM возвращает готовый JSON с полями sentiment, summary и action_items, который сразу пишется в таблицу без дополнительного парсинга.
Запись результата в карточку amoCRM через API
После того как транскрипт готов и саммари сформировано, нужно всё это положить в CRM. У amoCRM есть отдельный эндпоинт для звонков: POST /api/v4/calls. Он делает кое-что полезное за вас: сам ищет контакт по номеру телефона и привязывает звонок к связанной сделке. Не нужно заранее знать ID контакта или сделки.
Минимальный запрос выглядит так:
POST https://example.amocrm.ru/api/v4/calls
Authorization: Bearer {access_token}
Content-Type: application/json
[{
"direction": "inbound",
"uniq": "{{call_id}}",
"duration": {{duration}},
"source": "Mango Office",
"link": "{{record_url}}",
"phone": "{{phone}}",
"call_result": "{{summary}}",
"call_status": 4
}]
Поле call_result берёт на себя саммари. Менеджер видит его прямо в ленте событий, без клика в карточку. call_status: 4 означает, что звонок состоялся (в документации amoCRM это значение соответствует статусу "Разговор"). uniq нужен для идемпотентности: если запрос уйдёт дважды, дубль не создастся.
Полный транскрипт в call_result не пихайте. Там будет 3000 символов сырого текста, и лента превратится в мусор. Транскрипт кладите отдельной заметкой:
POST https://example.amocrm.ru/api/v4/notes
Authorization: Bearer {access_token}
Content-Type: application/json
[{
"entity_id": {{contact_id}},
"entity_type": "contacts",
"note_type": 4,
"params": {
"text": "{{transcript}}"
}
}]
note_type: 4 это обычная текстовая заметка. Она прикрепляется к контакту и видна в хронологии.
Теперь о ситуации, когда контакт не нашёлся. API звонков в этом случае всё равно создаст запись, но она "повиснет" без привязки. Менеджер её не увидит. Лучше явно обработать такой кейс: сначала сделать GET /api/v4/contacts?query={phone}, и если массив результатов пустой, создать задачу:
POST https://example.amocrm.ru/api/v4/tasks
Authorization: Bearer {access_token}
Content-Type: application/json
[{
"task_type_id": 1,
"text": "Входящий от неизвестного номера: {{phone}}",
"complete_till": {{timestamp_plus_2h}},
"responsible_user_id": {{manager_id}}
}]
task_type_id: 1 это "Перезвонить". complete_till ставьте через 2 часа от момента звонка, иначе задача улетит в просроченные к следующему утру.
Один нюанс по авторизации: токены amoCRM живут 24 часа. Если ваш pipeline долгоживущий (демон, очередь), нужно хранить refresh token и обновлять access token заранее. Не ждите 401 в проде, чтобы это обнаружить. Если параллельно используете Bitrix24 или рассматриваете его как альтернативу, посмотрите на готовые интеграции Bitrix24 с внешними сервисами: там похожие паттерны работы с API и токенами разобраны на практических примерах.
Выбор модели транскрибации для русской речи: Whisper против альтернатив
Прежде чем писать код, нужно ответить на один вопрос: какая модель вообще справится с вашим аудио? Бенчмарки на чистых датасетах врут. Whisper large-v3 показывает низкий WER на студийных записях, но реальный колл-центр выглядит иначе: фоновый шум, акценты, «алло-алло-слышно меня», обрывы. Там качество заметно падает. Это уже другая история.
Разберу четыре варианта, которые реально используются в 2026 году на русском.
Whisper large-v3 (self-hosted). Хорош как универсальный вариант для тех, кто не хочет зависеть от внешних API и работает с многоязычным аудио. На русской речи без шума качество приличное, но специализированных моделей он не обходит.
GigaAM от SberDevices - обучен на большом объёме русской речи, по публикуемым результатам показывает меньший WER на русскоязычном аудио по сравнению с Whisper. Лицензия MIT, можно деплоить где угодно. Если качество транскрипции критично и аудио на русском, этот вариант стоит проверить в первую очередь.
OpenAI Whisper API (whisper-1). Нет инфраструктуры, нет GPU, просто HTTP-запрос. Цена $0.006 за минуту согласно актуальному прайсу OpenAI. При небольшом объёме звонков это дешевле, чем поднимать собственный сервер. Но данные уходят к OpenAI: если у вас чувствительные разговоры клиентов, этот момент надо решить на уровне договора и DPA.
faster-whisper на CTranslate2. Это не отдельная модель, а способ запускать Whisper-веса быстрее. На CPU ускорение в 2-4 раза по сравнению с оригинальной реализацией. Если нет GPU, но нужен self-hosted Whisper, берите faster-whisper, не оригинальный.
Теперь про экономику. При росте объёма звонков API-расходы растут линейно. На каком-то пороге аренда или покупка GPU-инстанса становится дешевле. Конкретный порог зависит от средней длины звонков и выбранного облачного провайдера, поэтому считайте под свои цифры.
Главное, что я рекомендую сделать до любых технических решений: скачайте 20 реальных звонков из вашей системы, прогоните через кандидатные модели и посчитайте WER вручную по ключевым словам. Не по всему тексту - это долго. Выберите 30-40 слов, которые критичны для вашей задачи: названия продуктов, типичные жалобы, команды оператора. Посчитайте, сколько раз модель их ошибается. Это займёт два часа и сэкономит недели переделок потом.
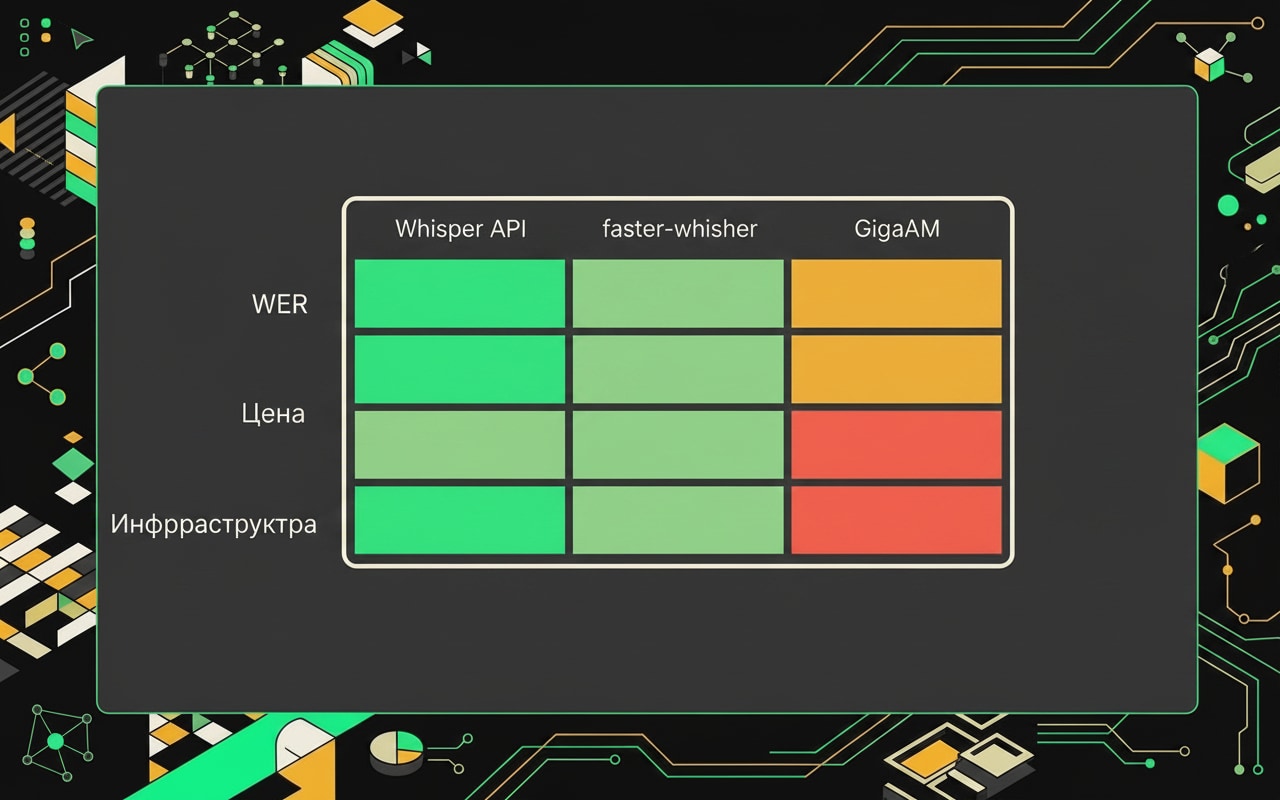
Whisper large-v3 показывает WER около 8% на русскоязычных звонках, тогда как base-модель даёт ошибку в три раза выше.
Обработка ошибок и edge cases
Большинство интеграций ломаются не в момент написания, а через три месяца. Именно столько живёт Refresh Token amoCRM. Когда он протухает, API начинает возвращать 401, и воркфлоу просто тихо падает: ни звонков, ни саммари, ни следа. Чтобы это не проходило незамеченным, добавь Error Trigger ноду в отдельный воркфлоу, который висит как глобальный перехватчик. При 401 от amoCRM он шлёт алерт в Telegram или Slack с именем упавшего воркфлоу и timestamp. Дальше уже ручной шаг: переавторизация через OAuth и обновление credentials в n8n.
Вторая частая проблема: телефония (особенно Манго, Билайн.Бизнес) отправляет webhook о завершении звонка раньше, чем файл записи физически доступен по ссылке. Скачиваешь URL, получаешь 404 или пустой ответ. Решение простое: после получения webhook ставь Wait ноду на 30 секунд, потом повторный HTTP-запрос на скачивание файла. Если снова ошибка, жди ещё 60 секунд и пробуй последний раз. Три попытки закрывают большинство таких случаев.
Фильтрация по длительности должна стоять в самом начале, сразу после триггера. Звонки короче 10 секунд это почти всегда недозвоны, сброс, ошибочный набор. Whisper на них тратить незачем: и токены уходят впустую, и в CRM появляется мусор вида "Алло. Алло. Отбой." Проверяй поле duration в данных webhook и выбрасывай такие звонки через IF ноду ещё до



