Что произошло: хронология за 40 минут
Миграция была плановой. Контрагенты из старой базы переезжали в Bitrix24 через n8n-workflow, запущенный вручную по webhook. Несколько тысяч записей, нерабочее время, никаких наблюдателей рядом.
Первые минуты всё шло штатно.
Затем Bitrix24 API начал отдавать таймауты под нагрузкой. n8n воспринял их как сбои и включил retry-логику. Часть уже обработанных записей пошла по второму кругу. В этот момент workflow фактически потерял идемпотентность, но никто этого не видел.
Позже сработала upsert-нода. Ключ, по которому она искала совпадения, оказался неверным. Вместо добавления новых контрагентов нода начала перезаписывать существующих, подставляя пустые поля из входящих данных. ИНН, телефоны, адреса обнулились. У части записей вместе с полями потянулась история сделок.
Оператор заметил аномалию примерно через 40 минут. Увидел пустые карточки в CRM, остановил workflow вручную. К этому моменту 2300 контрагентов были повреждены.
Итог: 2300 записей без ИНН, телефонов и адресов. Частичная потеря истории сделок. И workflow, который отработал 40 минут без единого алерта.
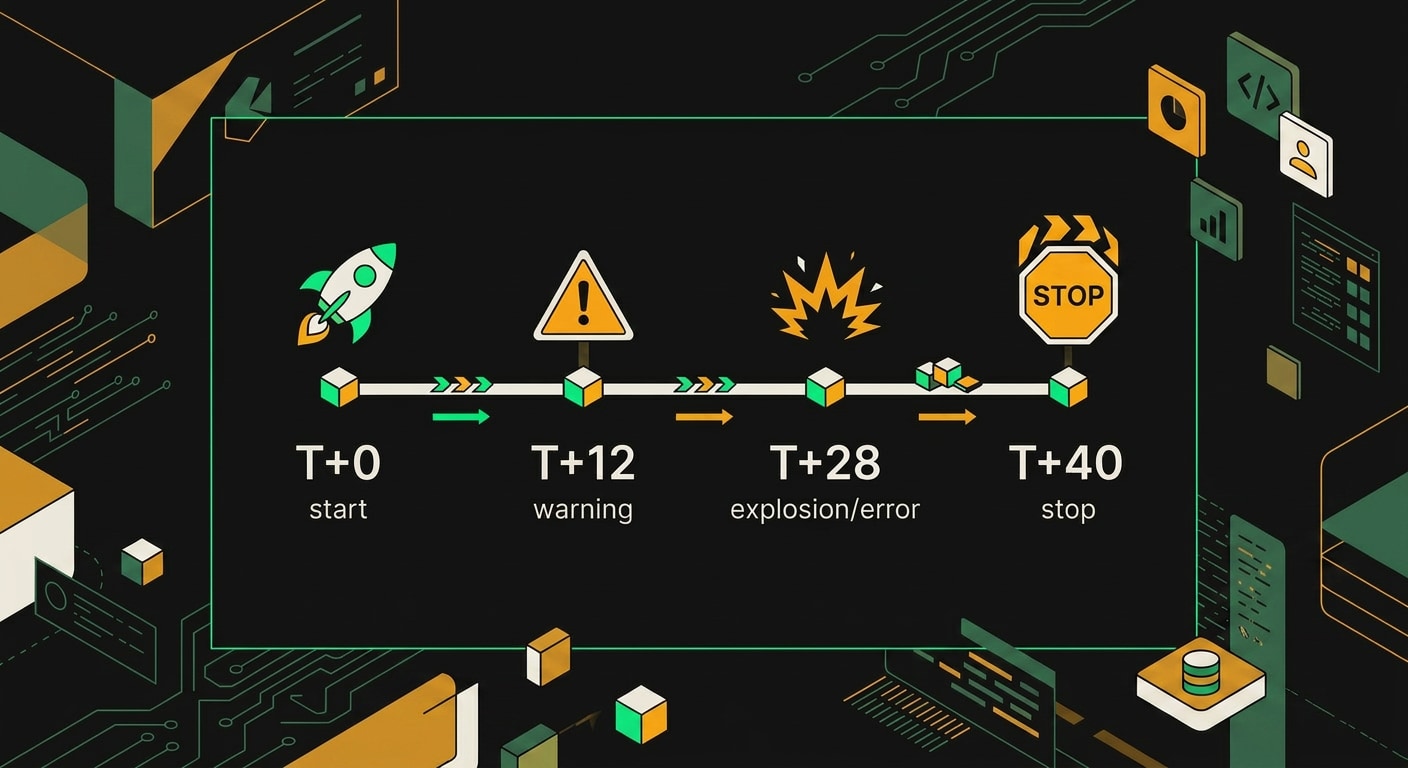
За 40 минут автоматические retry превратили единичный баг в массовое затирание записей на всём продакшн-стенде.
Корневая причина: upsert по неверному ключу
Выяснилось, что нода "Update Contact" в n8n искала запись по полю NAME. Кто-то при настройке миграции решил, что название компании и есть достаточный идентификатор. В тестовой базе с небольшим числом строк это работало: все имена там были уникальными. В боевой базе с большим числом контрагентов обнаружились записи "ООО Ромашка" с разными ID и похожие дубли вроде "ИП Иванов".
Bitrix24 при поиске по NAME возвращает первую запись из выборки. Какую именно первую, зависит от внутренней сортировки CRM, и это не детерминированно. Нода брала эту запись и перезаписывала её данными из текущей строки CSV. "ООО Ромашка" с одним ID получала телефон и адрес "ООО Ромашка" с другим ID. И наоборот, на следующей итерации.
Дальше хуже. Исходный CSV из старой базы содержал пустые ячейки там, где данных никогда не было. n8n не фильтровал их и передавал в API как null. Bitrix24 API принимал null без возражений и молча обнулял поля. Телефоны исчезали без единой ошибки в логах.
// Проблемный вариант: поиск по NAME
{
"operation": "update",
"filter": { "NAME": "{{ $json.company_name }}" },
"updateFields": {
"PHONE": "{{ $json.phone }}",
"ADDRESS": "{{ $json.address }}"
}
}
А потом Bitrix24 под нагрузкой начал отдавать HTTP 504. n8n поймал таймаут, сработал retry, и тот же upsert с теми же данными прошёл повторно. Там, где первый проход уже обнулил телефон, второй проход фиксировал это обнуление как правильное состояние. Урон был двойным, а в логах стояло только "retry succeeded".
Правильное решение: внешний ID из исходной системы, который должен был жить в пользовательском поле UF_CRM_EXTERNAL_ID с первого дня миграции. И проверка на пустые значения перед передачей в API, с фолбэком на уже существующее значение из CRM. Подробнее о том, как устроены интеграции Bitrix24 с внешними сервисами и какие узкие места возникают при передаче данных, написано отдельно.
// Правильный вариант: поиск по внешнему ID
{
"operation": "update",
"filter": { "UF_CRM_EXTERNAL_ID": "{{ $json.external_id }}" },
"updateFields": {
"PHONE": "{{ $json.phone || $('Fetch Original').item.json.phone }}",
"ADDRESS": "{{ $json.address || $('Fetch Original').item.json.address }}"
}
}
Фолбэк $('Fetch Original').item.json.phone здесь ссылается на результат отдельной ноды, которая забирает текущее состояние записи из CRM перед обновлением. Если в CSV пришёл null, в поле остаётся то, что уже хранится в Bitrix24. Это добавляет один дополнительный запрос на каждую строку, но для миграции это приемлемая цена за то, что данные не исчезают.
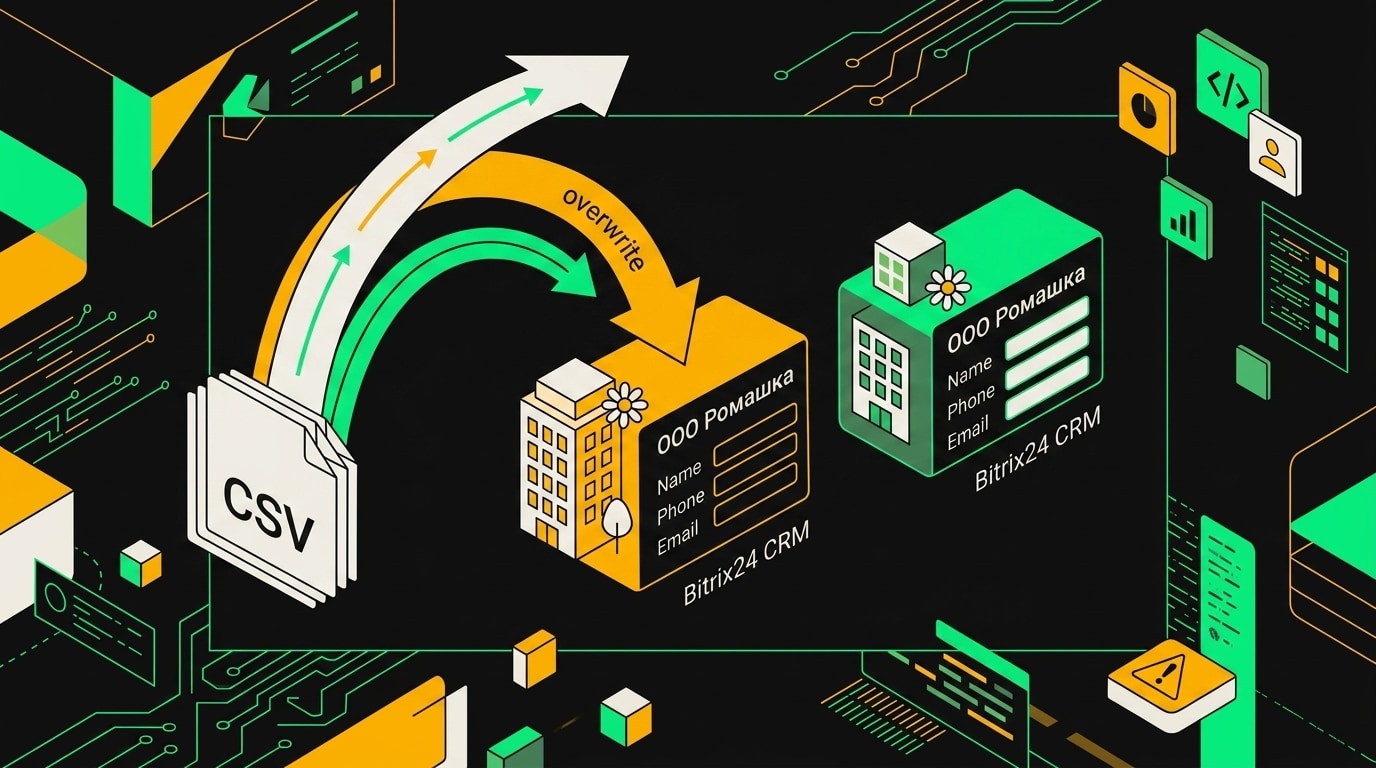
Когда составной ключ подобран неправильно, upsert молча перезаписывает чужие строки вместо того чтобы вставить новую.
Почему retry усилил урон, а не спас
Bitrix24 REST API режет входящий трафик жёстко: 2 запроса в секунду на пользователя. При превышении прилетает 503 или 504. Это не мягкое throttling, после которого можно сразу повторить. Это сигнал: сервер уже перегружен твоим потоком.
n8n на 503 реагирует предсказуемо: запускает retry. По умолчанию три попытки, интервал несколько секунд. Звучит разумно, пока не смотришь на то, что именно повторяется.
Проблема в том, что retry в этом workflow не проверял, выполнилась ли предыдущая операция. Идемпотентных ключей не было. Запрос на обновление записи улетал повторно вне зависимости от того, успел Bitrix24 его обработать до того, как вернул ошибку, или нет. А 503/504 в HTTP не означает "операция не выполнена". Он означает "сервер не ответил в срок". Это разные вещи.
В итоге часть записей получила обновление два, а некоторые три раза подряд. Причём каждый раз с данными из retry-очереди, которые к тому моменту уже не соответствовали актуальному состоянию источника. Workflow к тому моменту мог продвинуться дальше, данные в очереди устарели, но retry честно гнал именно их.
Это классическая ловушка destructive-операций без idempotency. Retry спасает при read-запросах или при POST с уникальным ключом, который сервер проверяет на дубли. При PATCH или UPDATE без такого ключа retry превращается в умножитель урона, а не в страховку.
Вывод здесь некомфортный, но прямой: retry без idempotency на операциях, которые меняют данные, опаснее, чем его полное отсутствие. Без retry запись просто не обновится. С ним она обновится несколько раз с неправильными данными.
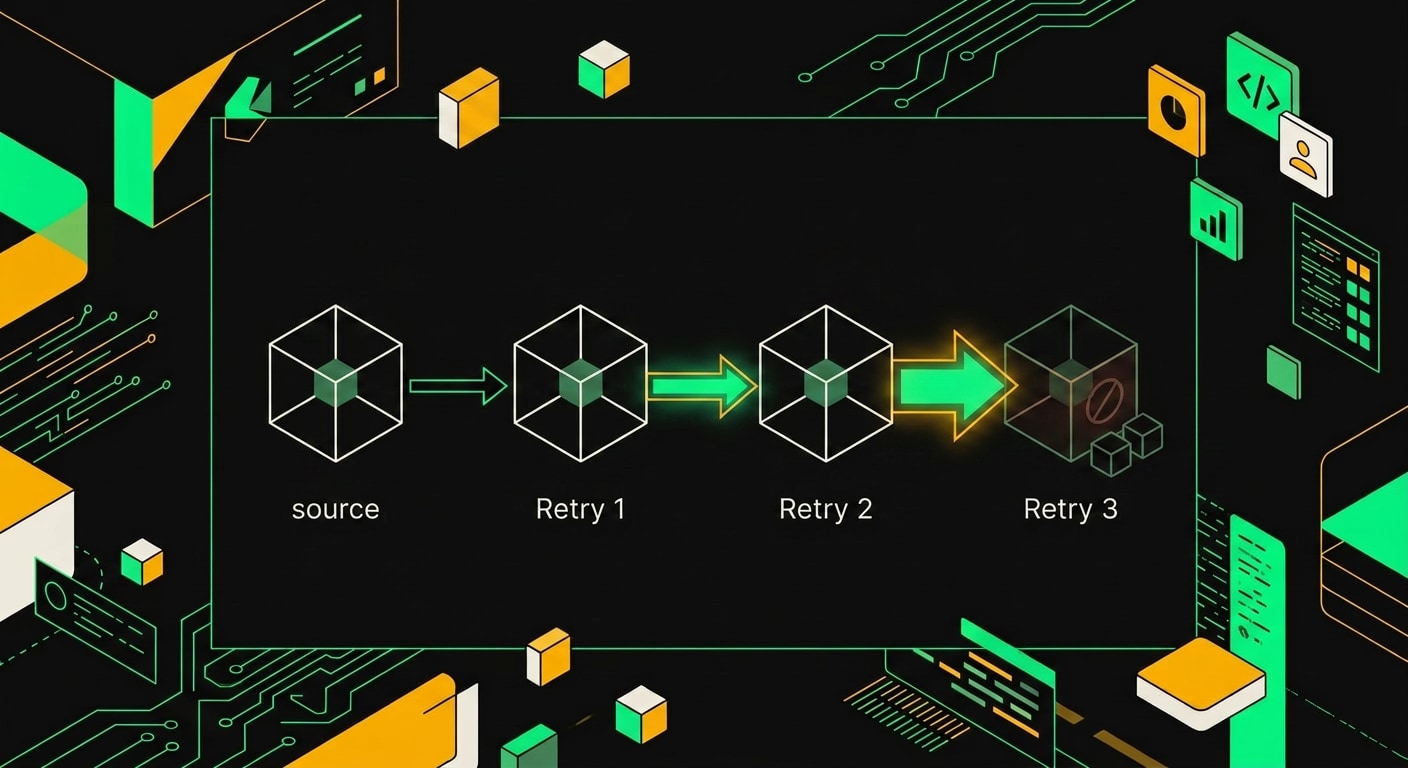
Каждый retry с тем же некорректным ключом бьёт по тем же чужим строкам, и счётчик потерянных записей растёт линейно со временем.
Как восстанавливали данные
Резервная копия была. Это хорошая новость. Плохая: копия была не свежей, и изменения за несколько дней никуда не делись из реальности. Менеджеры за это время вносили данные, двигали сделки, обновляли контакты. Откатиться к бэкапу означало потерять всё это.
Поэтому первым шагом вытащили из Bitrix24 список повреждённых записей. Использовали метод CRM.COMPANY.LIST с фильтром по DATE_MODIFY за последние сутки: получили выборку того, что вообще трогал скрипт миграции. Это дало отправную точку.
Дальше попытались сопоставить повреждённые записи с оригинальным CSV миграции по полю UF_CRM_EXTERNAL_ID. Там, где это поле сохранилось и не затёрлось в процессе падения, сопоставление сработало. Написали скрипт, который прогнал эту логику по всему массиву. Часть записей удалось восстановить автоматически за несколько часов.
Оставшиеся записи либо не имели UF_CRM_EXTERNAL_ID, либо поле оказалось пустым после повреждения. Автоматически сопоставить не получилось. Эти записи ушли менеджерам: несколько дней они открывали карточки, сверяли с почтой, звонками, таблицами в Google Sheets и восстанавливали руками.
Потратили значительное число человеко-часов. Это не считая времени разработчика на написание и отладку скрипта восстановления. Если переводить в деньги, получается сумма, которая перекрывает стоимость нормально спроектированной миграции с запасом.
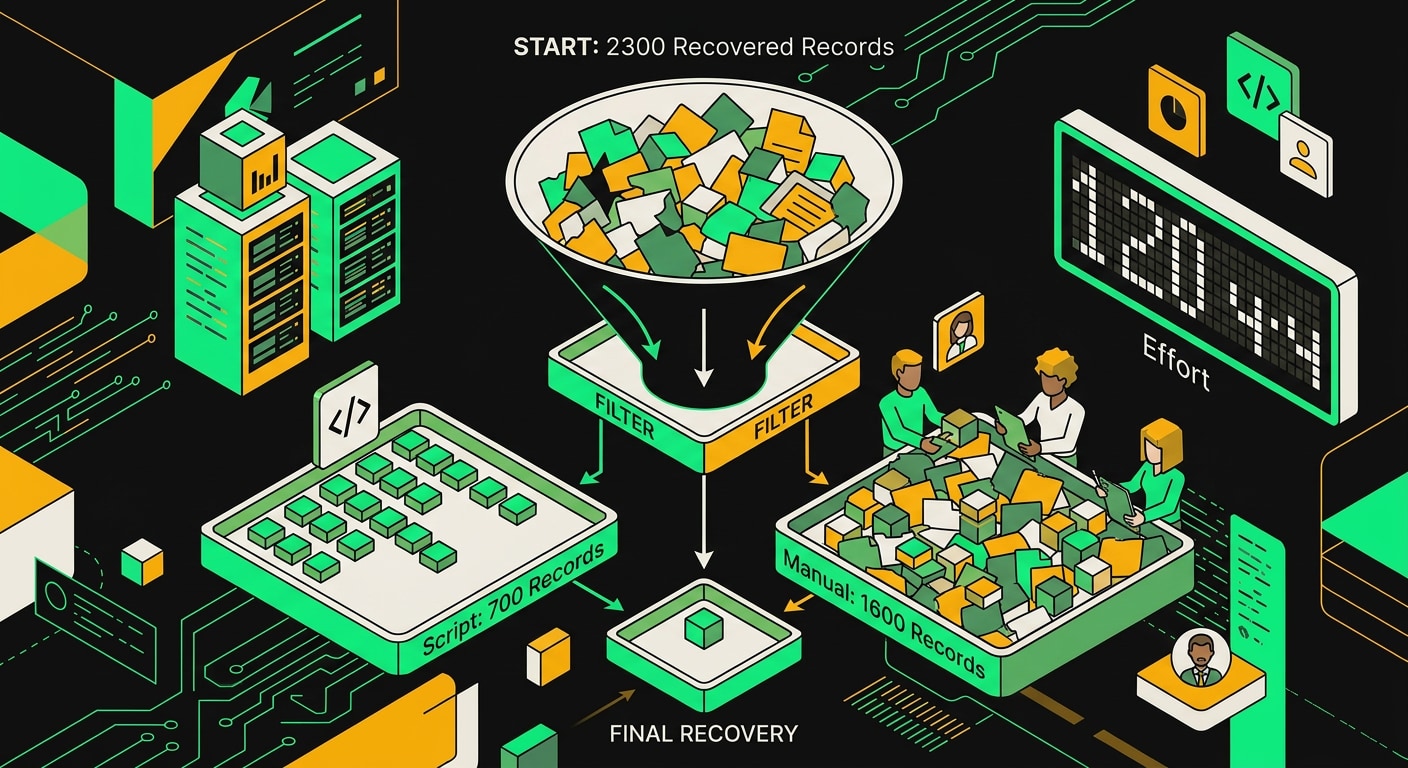
Чем позже обнаружена проблема, тем уже горлышко воронки: часть строк оказалась перезаписана дважды и восстановлению не поддаётся.
Что нужно было сделать до запуска миграции
Большинство проблем, которые я разбирал в этом проекте, решались ещё до первого API-вызова. Просто никто не сделал домашнюю работу.
Внешний идентификатор с самого начала. В Bitrix24 нет встроенного поля "ваш внутренний ID из другой системы". Поэтому первым шагом создаю пользовательское поле UF_CRM_EXTERNAL_ID в разделе CRM -> Настройки -> Пользовательские поля. Тип: строка, уникальное. И заполняю его до старта миграции, в отдельном проходе. Если поле появляется одновременно с основной загрузкой, вы теряете единственный надёжный способ найти запись повторно и обновить её, а не создать дубль.
Data audit перед стартом, не после. Беру исходный CSV, гружу во временную таблицу и прогоняю простую проверку:
-- Проверка уникальности в исходном CSV
SELECT company_name, COUNT(*) as cnt
FROM migration_source
GROUP BY company_name
HAVING COUNT(*) > 1;
-- Если результат не пустой, миграцию не запускать
Звучит банально. Но в реальном проекте именно этот запрос показал несколько десятков компаний с одинаковым company_name и разными адресами. Без этой проверки все они слились бы в случайную одну запись, и никто бы не заметил до звонка клиента.
Dry-run на 50 записях. Не на тестовой копии, а на боевом Bitrix24, но с намеренно выбранными безопасными компаниями (тестовые аккаунты или неактивные). После каждого UPDATE делаю GET-запрос к той же записи и сравниваю, что вернулось, с тем, что отправил. Если поля разошлись, останавливаюсь и разбираюсь. 50 записей хватает, чтобы поймать проблемы с кодировкой, типами полей и форматом телефонов, которые на одной-двух записях не воспроизводятся.
Pre-condition на пустые поля. Это отдельная боль. Если в источнике у компании пустое поле phone или address, нельзя передавать в Bitrix24 null или пустую строку: это перетрёт существующее значение, которое кто-то вручную занёс в CRM. В n8n решается нодой IF перед UPDATE:
// Нода IF: продолжать только если external_id не пустой
{{ $json.external_id !== null && $json.external_id !== '' }}
Ту же логику применяю к phone, address и любому полю, которое в источнике может быть пустым. Если поле пустое, просто не включаю его в тело запроса. Не передаю "PHONE": "". Не передаю вообще.
Snapshot в день миграции. Полный выгруз всех контактов и компаний через API, в JSON, с timestamp в имени файла. Не полагаюсь на резервную копию недельной давности, которую кто-то настроил в хостинге. За неделю менеджеры успевают занести множество новых сделок, и откат к старому бэкапу превращается в отдельную катастрофу. Скрипт выгрузки на n8n занимает 20 минут написания и 10 минут работы. Это дешевле любого разбора полётов после.
Правильная архитектура upsert в n8n + Bitrix24
Покажу рабочую схему. Пять шагов, никакой магии.
Шаг 1: GET перед любым изменением
Каждый upsert начинается с поиска по UF_CRM_EXTERNAL_ID. В n8n это HTTP Request нода с методом crm.contact.list и фильтром { "UF_CRM_EXTERNAL_ID": "{{ $json.external_id }}" }. Результат либо пустой массив, либо запись. Дальше IF-нода: если result[0] существует, идём в UPDATE, иначе в CREATE. Просто и явно.
Не надо пытаться угадать, есть ли запись, по косвенным признакам. Один лишний GET-запрос дешевле, чем дублирующий контакт в CRM.
Шаг 2: мерж данных перед UPDATE
Вот где большинство схем ломается. Если слепо отправить только поля из источника, вы затрёте всё, чего нет в CSV или вебхуке: заметки менеджеров, теги, связанные сделки. Нужно мержить аккуратно, беря из источника только непустые поля:
// Нода Merge: берём только непустые поля из источника
const source = $('Parse CSV').item.json;
const existing = $('GET Existing').item.json.result[0] || {};
const merged = {
...existing,
...Object.fromEntries(
Object.entries(source).filter(([k, v]) => v !== null && v !== '')
)
};
return { json: merged };
Порядок важен: сначала раскладываем existing, потом поверх него кладём непустые поля из source. Пустая строка и null из источника не перезапишут реальное значение в Bitrix.
Шаг 3: идемпотентный ключ операции
Перед отправкой в Bitrix генерирую ключ операции: MD5 от external_id + временна́я метка запуска миграции. Не от текущего времени, а от времени запуска всего флоу. Это позволяет при повторном запуске того же батча получить тот же ключ и найти лог.
const crypto = require('crypto');
const migrationTs = $('Start Migration').item.json.startedAt; // фиксированная метка
const opKey = crypto
.createHash('md5')
.update(`${$json.external_id}__${migrationTs}`)
.digest('hex');
return { json: { ...$json, _opKey: opKey } };
Этот ключ пишу в лог перед запросом и после. Если флоу падает на середине, вижу ровно, на каком _opKey остановились.
Шаг 4: верификация после UPDATE
После каждого UPDATE делаю ещё один GET той же записи и сравниваю три-четыре контрольных поля: email, телефон, UF_CRM_EXTERNAL_ID, статус. Если хоть одно расходится с тем, что отправлял:
const sent = $('Build Payload').item.json;
const got = $('Verify GET').item.json.result;
const checks = ['EMAIL', 'PHONE', 'UF_CRM_EXTERNAL_ID'];
const mismatches = checks.filter(field => {
// Bitrix возвращает массивы для EMAIL и PHONE
const sentVal = JSON.stringify(sent[field]);
const gotVal = JSON.stringify(got[field]);
return sentVal !== gotVal;
});
if (mismatches.length > 0) {
throw new Error(`Mismatch on fields: ${mismatches.join(', ')} for opKey ${sent._opKey}`);
}
Error-нода ловит это и пишет в отдельный лог (я использую Google Sheets или простой webhook в Telegram). Флоу дальше не идёт. Ни в коем случае не игнорируйте расхождения и не пишите continue в catch-блоке.
Шаг 5: rate limiting руками
Bitrix24 REST API режет запросы на уровне 2 запроса в секунду для облачных тарифов (с 2024 года лимиты стали жёстче на некоторых планах). Не рассчитывайте на автоматический retry в n8n: он есть, но срабатывает с экспоненциальной задержкой и ломает логику батчевой обработки.
Просто ставьте Wait-ноду на 500 мс после каждого запроса к API. Для батча из 10 000 записей это добавит около 1.5 часа к общему времени. Это приемлемо. Дублирующие записи или потерянные обновления из-за 429-ошибок обходятся дороже.
Схема получается линейной: GET → IF → (CREATE или Merge → UPDATE) → Verify GET → Wait → следующая запись. Никаких параллельных веток с общим состоянием, никакого "попробуем и посмотрим".
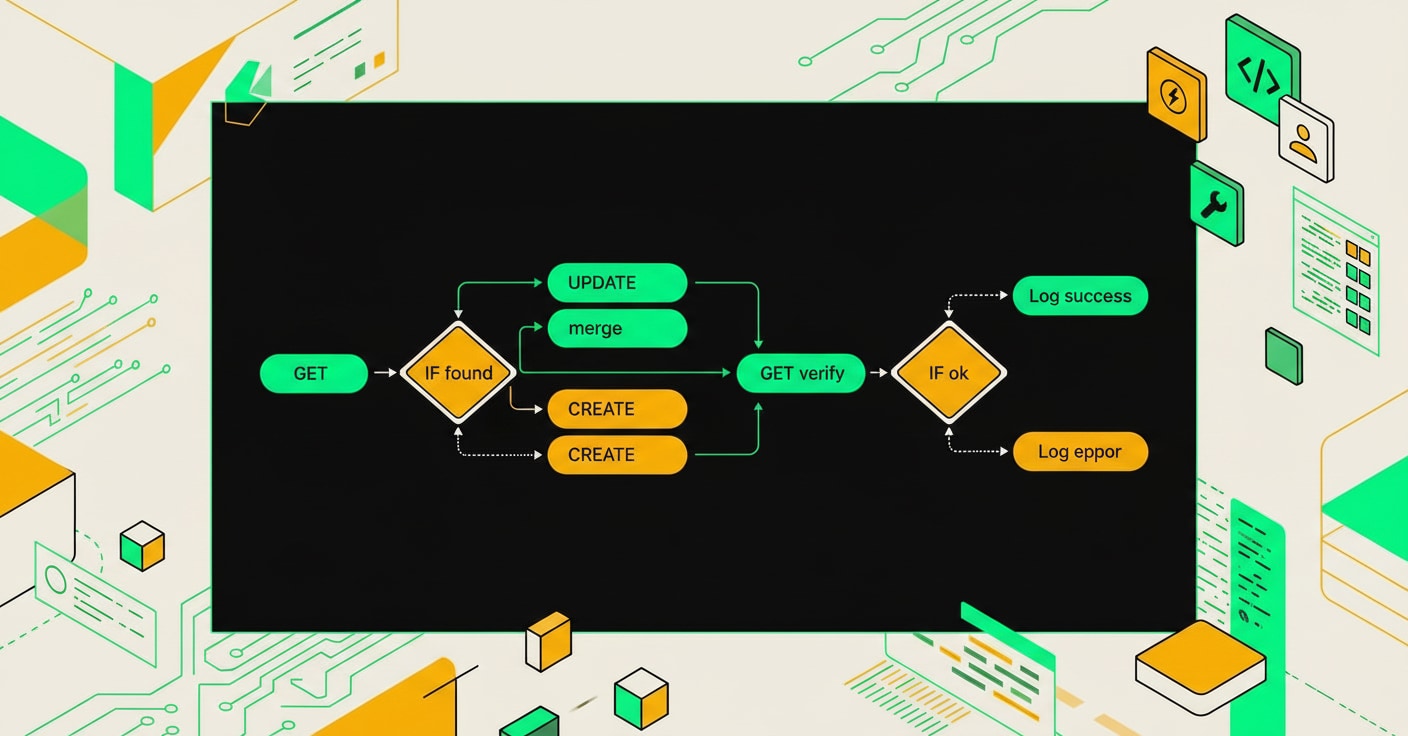
Три шага перед деплоем upsert-логики сокращают вероятность коллизии ключей практически до нуля.
Настройка retry и обработки ошибок в n8n
По умолчанию n8n включает retry для всех нод. Это разумно для GET-запросов, но для UPDATE и DELETE это ловушка. Если нода обновляет запись в CRM и падает на середине, повторная попытка может записать дублирующий статус, обнулить поле или запустить второй webhook. Поэтому первое, что делаю в любом production-воркфлоу: отключаю retry на всех нодах записи и оставляю его только там, где операция идемпотентна по природе.
В настройках ноды это Settings → On Error → Retry on Fail: off. Для GET-нод можно оставить 2-3 попытки с интервалом 5 секунд. Для POST/PUT/DELETE: ноль.
Continue On Fail для критических нод
Для нод записи в CRM ставлю Continue On Fail: false. Это означает, что при ошибке весь воркфлоу остановится, а не поедет дальше с пустыми данными. Звучит жёстко, но альтернатива хуже: воркфлоу молча завершается "успехом", а запись в базе не создана.
Error Trigger Workflow
Это отдельный воркфлоу, единственная нода которого: Error Trigger. Он ловит сбои основного и делает что-то полезное с контекстом ошибки.
Минимальная схема: Error Trigger → Set (форматируем сообщение) → Telegram или Google Sheets. В Sheets удобнее: пишем туда workflow_name, node_name, error_message, timestamp, execution_id. Потом можно посмотреть паттерны: какая нода падает чаще всего и в какое время.
Подключить его к основному: в основном воркфлоу открываю Settings → Error Workflow и указываю ID.
Circuit Breaker через Static Data
n8n не имеет встроенного circuit breaker, но $getWorkflowStaticData позволяет хранить состояние между запусками. Вешаю это в Code-ноду прямо перед критическим блоком записи:
// Circuit Breaker через Static Data
const staticData = $getWorkflowStaticData('global');
staticData.errorCount = (staticData.errorCount || 0) + 1;
if (staticData.errorCount > 10) {
throw new Error('Circuit breaker: слишком много ошибок подряд, workflow остановлен');
}
// Сброс счётчика при успешной операции
// staticData.errorCount = 0;
Строку сброса раскомментирую и ставлю в конце воркфлоу, после последней успешной записи. Логика простая: если 10 запусков подряд упали с ошибкой, что-то сломалось системно. Пусть воркфлоу остановится и ждёт, пока человек разберётся, а не продолжает долбиться в недоступный API или писать мусор в базу.
Порог 10 выбираю под конкретный воркфлоу. Для критических финансовых операций ставлю 3.
Лог каждого UPDATE
Каждое обновление пишу в отдельную Google Sheets или Postgres-таблицу. Минимальный набор полей: external_id, timestamp, status (success/fail), old_value, new_value. Это решает сразу два вопроса: можно откатить изменения вручную, если что-то пошло не так, и можно аудировать, кто и что менял.
В n8n это делается через Google Sheets → Append Row после каждой Update-ноды. Перед этим: Code-нода, которая достаёт старые значения из предыдущего GET и пакует их в строку лога.
Да, это добавляет нодам и времени выполнения. Но первый раз, когда лог помогает восстановить несколько сотен испорченных записей, вопрос "стоит ли это делать" закрывается навсегда.
Схожая проблема с потерей истории операций возникает при двусторонней синхронизации amoCRM и Google Sheets: там тоже критичен порядок записи и наличие журнала изменений.
Чек-лист перед любой массовой миграцией через n8n
Прежде чем запустить workflow на всю базу, прохожу этот список. Пропущенный пункт однажды стоил мне трёх часов ручного восстановления данных в HubSpot. Больше не пропускаю.
Уникальный внешний ключ задан и проверен в обеих системах. Не "скорее всего есть", а именно проверен запросом. В исходнике и в целевой системе поле должно называться одинаково, иметь одинаковый тип и не содержать null. Если в Salesforce это external_id__c, а в базе источника это ext_id с пробелами в части строк, миграция разложит данные по случайным записям.
Data audit пройден. Прогоняю два SQL-запроса: GROUP BY key HAVING COUNT(*) > 1 на дубли и WHERE key IS NULL OR key = '' на пустые значения. Нашёл хоть одну строку по первому или второму запросу, останавливаюсь и чищу до старта.
Snapshot целевой системы сделан в день миграции. Не вчера. Именно сегодня, за час до запуска. CRM умеет делать экспорт в CSV за 5 минут, этого достаточно. Без снапшота rollback превращается в угадайку.
Dry-run на 1% данных выполнен и сверен вручную. Беру первые N записей через Limit в n8n, запускаю workflow, открываю 5-10 записей в целевой системе руками и сравниваю с источником. Автоматика здесь не заменяет глаза: именно руками вижу, что поле phone перезаписалось пустой строкой, хотя в источнике там был номер.
Retry отключён для write-операций, Circuit Breaker включён. Retry на обновление записи означает, что при таймауте та же запись запишется дважды или три раза с разными значениями. В n8n отключаю retryOnFail на всех узлах с HTTP Request или CRM-коннекторами внутри loop. Circuit Breaker реализую через счётчик ошибок: если за последние 50 итераций больше 5 ошибок, workflow останавливается с уведомлением.
Post-update verification настроена. После каждого обновления тут же делаю GET-запрос на ту же запись и сравниваю ключевое поле с ожидаемым значением. Узел IF с условием actualValue !== expectedValue пишет расхождение в отдельную Google Sheet. По итогу миграции смотрю именно в этот лист, а не надеюсь, что всё прошло чисто.
Rollback-скрипт написан и протестирован. Скрипт должен работать до старта миграции. Тестирую его на 10 записях из dry-run: накатываю, откатываю, проверяю что данные вернулись. Если rollback не проверен, он не существует.
**Команда предупреждена о временном