

Зачем нужна двусторонняя синхронизация и где она ломается
Начну с конкретики. Есть три сценария, где люди приходят к двусторонней синхронизации между CRM и Google Sheets не от хорошей жизни.
Первый — менеджеры ведут лиды в таблице, потому что так удобнее: фильтры, сортировка, массовое редактирование пятидесяти полей за раз без кликов по карточкам. CRM при этом выступает системой хранения, а Sheets — интерфейсом работы. Второй — финансы и аналитика требуют данные в таблицах для отчётности, но хотят видеть актуальные статусы сделок, а не вчерашний экспорт. Третий — нужно разово перегнать и отредактировать несколько тысяч записей: обновить сегменты, проставить теги, почистить дубли.
Во всех трёх случаях людям кажется, что задача простая. Это иллюзия.
Односторонняя выгрузка и двусторонка — это принципиально разные задачи. Экспорт из CRM в Sheets — тривиально. Обратная запись из Sheets в CRM — уже сложнее. Но настоящая двусторонняя синхронизация, где изменения в обоих направлениях должны корректно мержиться — это отдельный класс проблем. Нужно отвечать на вопрос: если запись изменилась одновременно в двух местах, что считается правдой?
Риски здесь вполне конкретные. Потеря данных — классика: пишешь в Sheets поверх поля, которое только что обновилось в CRM, и одно из изменений просто исчезает без предупреждения. Дубли — если логика создания записей не проверяет существование по уникальному ключу, каждый прогон синхронизации добавляет новых лидов вместо того чтобы обновлять старых. Бесконечные циклы — изменение в CRM триггерит запись в Sheets, запись в Sheets триггерит обновление в CRM, и так по кругу, пока не кончится лимит запросов или деньги на тарифе. Рассинхрон полей — поля называются по-разному, типы данных не совпадают, кто-то переименовал колонку в таблице, и маппинг молча сломался.
Теперь про Zapier и аналоги. На объёмах до тысячи записей и при редких изменениях это работает. При базе от десяти тысяч записей начинаются системные проблемы. Zapier обрабатывает триггеры последовательно, у него жёсткие лимиты на количество задач в месяц и потолок по частоте опроса — обычно раз в пятнадцать минут на базовых тарифах. Массовое обновление в таблице генерирует столько триггеров, что очередь встаёт колом. Нет встроенного механизма разрешения конфликтов — только примитивное «последнее изменение побеждает». Нет транзакционности: если синхронизация упала на середине, половина записей обновлена, половина нет, и узнаешь об этом не сразу.
Это не значит, что задача нерешаема. Но решается она не через no-code коннекторы, а через нормальную архитектуру с очередями, идемпотентными операциями и явной логикой разрешения конфликтов.

Несогласованность данных между amoCRM и Google Sheets возникает без механизма двусторонней синхронизации.
Архитектура интеграции: pull, push и гибридные схемы
Прежде чем писать первую строчку кода, нужно ответить на один вопрос: кто кому звонит? Ответ определяет всю архитектуру.
amoCRM умеет только push. Настраиваешь вебхук на событие — изменение сделки, контакта, компании — и CRM сама стучится на твой эндпоинт при каждом триггере. Никакого поллинга, никаких кронов на вашей стороне. Плюс очевиден: минимальная задержка, ты узнаёшь об изменении за секунды. Минус тоже очевиден: нужен публичный HTTPS-эндпоинт, который всегда доступен и умеет быстро принять POST — иначе амо может посчитать доставку неудачной.
Google Sheets — история другая. Sheets по умолчанию сам инициативы не проявляет. Есть два варианта: повесить onEdit-триггер в Apps Script, который срабатывает при ручном редактировании ячейки, или опрашивать API по расписанию. onEdit работает только для ручных правок — программные изменения через API он не ловит, это частая ловушка. Периодический pull через cron проще в отладке, но добавляет задержку до следующего запуска.
Прямое соединение двух этих систем — хрупкая конструкция. Вебхук от амо пришёл, ты пишешь в Sheets, Sheets отвечает с таймаутом, вебхук считается неудавшимся, амо повторяет, получаешь дубли. Поэтому между двумя API нужен буфер — очередь сообщений. Redis с его списками или RabbitMQ для более сложной маршрутизации. Схема простая: вебхук принял сообщение, положил в очередь, вернул 200 за миллисекунды. Воркер берёт сообщения из очереди и уже спокойно работает с Sheets API без давления со стороны таймаутов амо.
Отдельный вопрос, который большинство обходит стороной до первого конфликта данных: field-level ownership. Для каждого поля нужно явно зафиксировать, какая система является источником истины. Телефон клиента — амо главный, Sheets только читает. Прогноз продаж на квартал — Sheets главный, амо получает данные оттуда. Дата следующего контакта — зависит от процесса. Без этого документа через месяц получишь ситуацию, где оба сервиса перезаписывают друг друга и непонятно, какое значение правильное.
На практике хорошо работает гибридная схема. Критичные поля — статус сделки, сумма, ответственный менеджер — идут через push в реальном времени, очередь их обрабатывает сразу. Всё остальное — дополнительные поля, аналитические теги, агрегаты — собирается батчем раз в час. Это снижает нагрузку на Sheets API, у которого квота 300 запросов в минуту на проект, и даёт запас на пиковые периоды.
Очередь задач выступает буфером между источниками изменений и гарантирует надёжную доставку обновлений в обе системы.
Лимиты API: главный подводный камень
Когда я первый раз делал синхронизацию amoCRM → Google Sheets, всё работало идеально. На стейджинге. С двадцатью сделками. В проде на третий день интеграция легла, и я полез разбираться с лимитами — оказалось, это самая недооценённая часть всей задачи.
Цифры, которые надо держать в голове:
- amoCRM: 7 запросов в секунду на одну интеграцию, 50 запросов в секунду на весь аккаунт. Если у клиента ещё крутятся другие интеграции — ваши 7 это всё, что у вас есть.
- Google Sheets API v4: 300 read + 300 write запросов в минуту на проект, и отдельно 60 в минуту на конечного пользователя. Вот это «60 на пользователя» бьёт чаще всего, особенно если все запросы идут от одного сервис-аккаунта.
Простая арифметика отрезвляет. Допустим, у вас 1000 сделок, и вы пишете их по одной строке за запрос. На стороне Sheets это 1000 запросов / 60 в минуту = ~16-17 минут только на запись. Если батчить через batchUpdate и класть по 500 строк за вызов — две операции, пара секунд. Разница не в проценты, в порядки.
Что я делаю на практике:
- Всегда батчинг. Для Sheets —
spreadsheets.values.batchUpdateилиspreadsheets.batchUpdateдля структурных изменений. Для amoCRM — пакетные эндпоинты на 250 объектов за раз. - Разделение нагрузки по сервис-аккаунтам. Лимит 60/мин на пользователя обходится тем, что чтение идёт с одного аккаунта, запись — с другого. Это дешёвый горизонтальный шардинг.
- Exponential backoff с jitter. Без джиттера при массовом 429 все ретраи приходят синхронно и снова получают 429. Случайная добавка размазывает пики.
- Мониторинг 429 и 503. Я считаю количество ретраев на каждую операцию и алерчу, если их доля переваливает за 5%. Это сигнал, что упёрлись в потолок и пора пересматривать архитектуру, а не докручивать таймауты.
Минимальная реализация ретрая, которую я ношу с собой из проекта в проект:
// Exponential backoff для Google Sheets API
async function withRetry(fn, maxAttempts = 5) {
for (let i = 0; i < maxAttempts; i++) {
try { return await fn(); }
catch (e) {
if (e.code !== 429 && e.code !== 503) throw e;
const delay = Math.pow(2, i) * 1000 + Math.random() * 1000;
await new Promise(r => setTimeout(r, delay));
}
}
throw new Error('Max retries exceeded');
}
Важный момент: ретраить нужно только идемпотентные операции или те, где вы точно знаете, что повторное применение безопасно. batchUpdate с явными диапазонами — безопасно. Слепой append после таймаута — нет, можно получить дубли. Я в таких случаях сначала читаю состояние, потом решаю, нужен ли повтор.
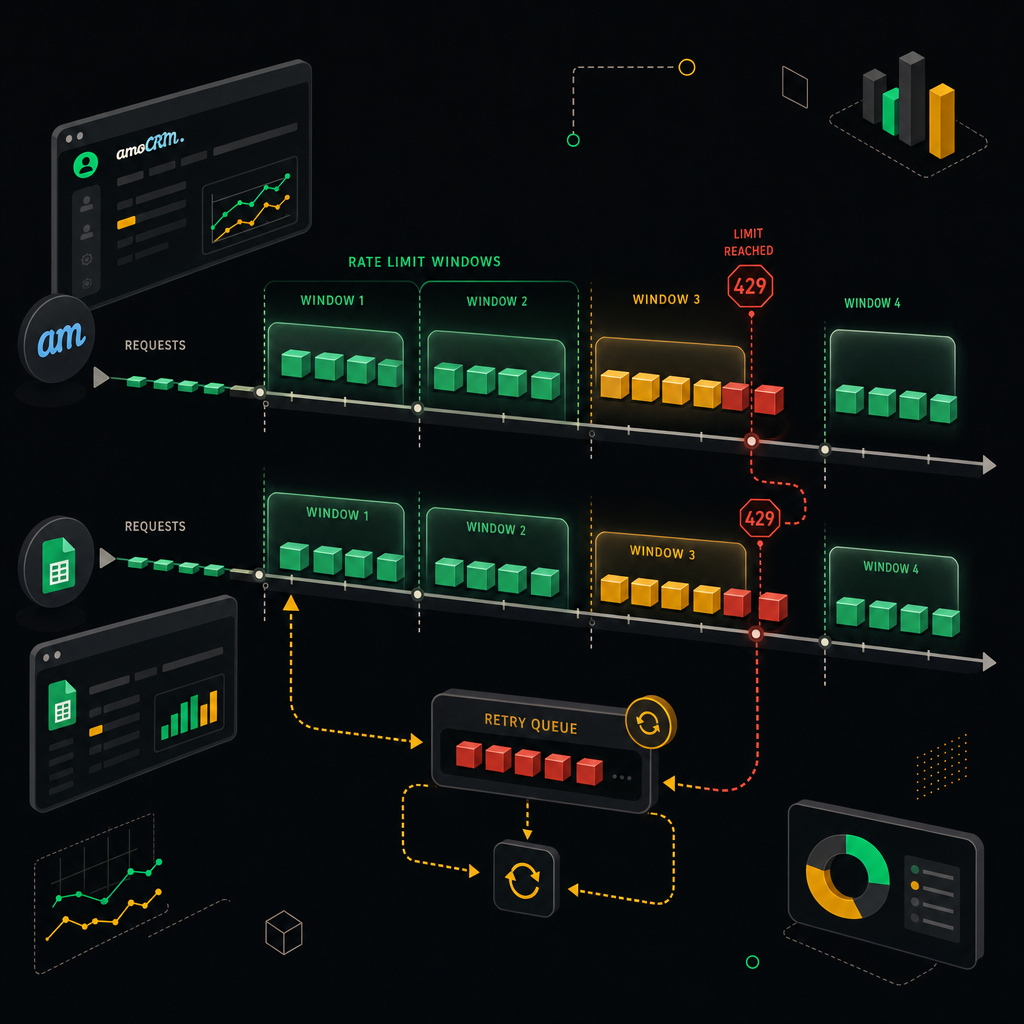
Батчинг запросов позволяет укладываться в ограничения API и снижает риск блокировки при массовых операциях.
Разрешение конфликтов: кто прав, когда правки одновременно
Двунаправленная синхронизация amoCRM ↔ Google Sheets рано или поздно ловит классику: менеджер поменял сумму сделки в карточке, а РОП в этот же момент дописал комментарий в таблице. Вебхук и крон-задача стартуют почти одновременно, и без чёткой стратегии один из них затрёт чужую работу. Я разбираю это так.
Четыре стратегии, между которыми приходится выбирать
- Last-write-wins (LWW) — простейший вариант: побеждает запись с более свежим
updated_at. Работает, пока правки не пересекаются по полям. На практике даёт потери: если два человека редактировали разные поля одной строки, всё равно один результат стирается. - Source-priority — у источника есть приоритет. Например, amoCRM всегда главнее по полям сделки (сумма, статус, ответственный), а Sheets — по аналитическим колонкам (теги когорт, метки РОПа). Простая, предсказуемая, но требует жёсткой схемы полей.
- Manual review — конфликтные строки уходят в отдельный лист
_conflictsс обеими версиями, человек решает руками. Использую для денежных полей и юридически значимых данных. - Field-level merge — мерджим по полям, а не по строкам. Это даёт максимум автоматики, но требует знать
updated_atна уровне каждого поля либо хеши предыдущего состояния.
В реальных проектах я почти всегда комбинирую: LWW по умолчанию, source-priority для критичных полей, manual review как сейф-нет.
Как ловить реальные изменения
Просто доверять updated_at нельзя — Sheets обновляет временную метку даже при открытии формулой, а amoCRM иногда триггерит вебхук без фактической смены данных. Поэтому я храню рядом с каждой строкой хеш значимых полей:
const crypto = require('crypto');
function rowHash(record, fields) {
const payload = fields.map(f => String(record[f] ?? '')).join('|');
return crypto.createHash('sha1').update(payload).digest('hex');
}
function resolveConflict(amoRecord, sheetRecord) {
if (amoRecord.updated_at > sheetRecord.updated_at) return amoRecord;
if (sheetRecord._source_priority === 'high') return sheetRecord;
return { ...amoRecord, ...sheetRecord, _conflict: true };
}
Если хеш rowHash не изменился с прошлой синхронизации — пропускаю запись, даже если updated_at свежий. Это позволяет отфильтровать «фантомные» апдейты и заметно разгружает квоты Google API.
Блокировка строки на время записи
Гонки на уровне миллисекунд лечатся служебной колонкой _sync_lock. Перед записью ставлю туда метку worker_id:timestamp, после — снимаю:
async function withRowLock(rowId, workerId, fn) {
const lock = `${workerId}:${Date.now()}`;
const ok = await tryAcquireLock(rowId, lock); // CAS-операция
if (!ok) throw new Error('row is locked');
try {
return await fn();
} finally {
await releaseLock(rowId, lock);
}
}
Локи держу не дольше 10–15 секунд и всегда с TTL: упавший воркер не должен заморозить строку навсегда. Для Sheets CAS я эмулирую через valueInputOption=USER_ENTERED + повторное чтение ячейки — нативных транзакций там нет.
Журнал изменений
Без аудит-лога споры «почему у меня сумма обнулилась» неразрешимы. Я веду отдельную таблицу (или BigQuery, если объёмы большие) с записями вида:
ts | row_id | source | field | old_value | new_value | hash_before | hash_after | resolution
resolution — это какая стратегия сработала: lww, priority:amo, manual, skipped:no_change. По этому логу за пять минут восстанавливается любой инцидент, и видно, какие поля чаще всего конфликтуют — это вход для тюнинга правил.
Удаления — отдельная боль
Hard delete в двунаправленной синхронизации почти всегда плохая идея. Если сделка удалена в amoCRM, а в Sheets строка ещё жива — следующий цикл может «воскресить» её обратно. Я делаю так:
- В amoCRM сделки не удаляю, а перевожу в архивный статус.
- В Sheets ставлю
_deleted_atи прячу строку фильтром, физически не удаляя. - Синхронизатор уважает
_deleted_at: если он есть с любой стороны и свежееupdated_atпротивоположной стороны — строка считается удалённой везде. - Раз в N дней отдельный джоб переносит «мёртвые» строки в архивный лист и чистит основной.
Hard delete оставляю только для явных команд оператора через интерфейс — и всегда с записью в audit log, чтобы было кого спросить.
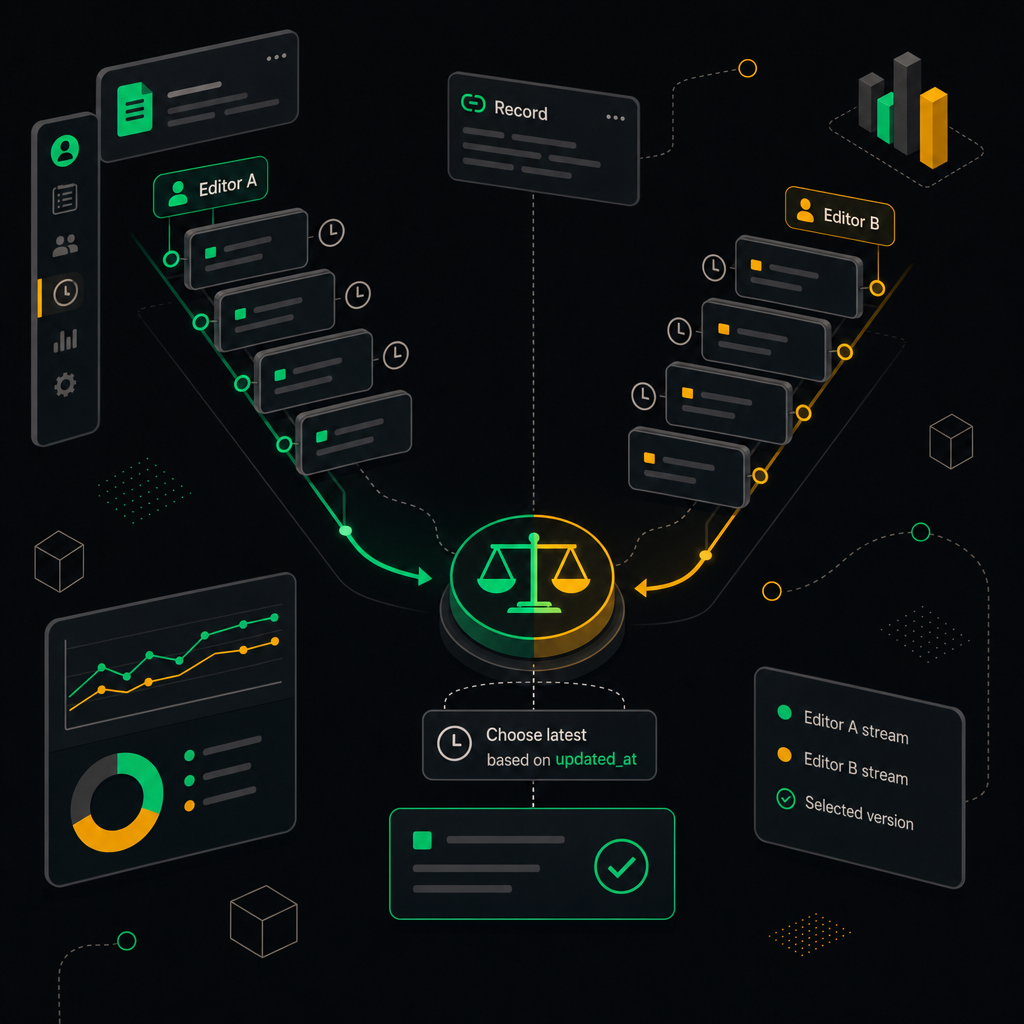
Сравнение временных меток updated_at определяет победившую версию записи при одновременном редактировании в обеих системах.
Защита от бесконечных циклов обновлений
Двусторонняя синхронизация amoCRM ↔ Google Sheets ломается на ровном месте: webhook из amo пишет строку в Sheets, onEdit ловит изменение и пушит обратно в amo, amo отправляет новый webhook — и поехали. Подобные петли способны быстро исчерпать квоты API. Чинится это не одним «глобальным флагом», а несколькими слоями, каждый из которых страхует следующий.
Слой 1. Метка происхождения операции. В каждый запрос на запись я проставляю _sync_origin — куда именно мы сейчас пишем и откуда пришли данные. Когда обработчик webhook'а получает событие с тем же _sync_origin, что и наш последний коммит, он его молча игнорирует. Этого достаточно, чтобы убить 90% циклов, но только если обе системы честно возвращают метаданные. amo, например, не возвращает.
Слой 2. Дебаунс по собственным записям. Раз метаданным верить нельзя, держу in-memory карту недавних операций. Если за последние несколько секунд мы сами писали в эту сущность с таким же содержимым — событие отбрасываем как эхо.
const recentWrites = new Map();
function shouldSkip(entityId, hash) {
const last = recentWrites.get(entityId);
if (last && last.hash === hash && Date.now() - last.ts < 3000) return true;
recentWrites.set(entityId, { hash, ts: Date.now() });
return false;
}
Размер окна дебаунса нужно подбирать под конкретную систему: слишком маленькое — пропустит эхо-события, слишком большое — отфильтрует легитимные правки. Карту чищу таймером раз в минуту, иначе она течёт.
Слой 3. Хеш до записи. Перед каждым update считаю SHA-1 от нормализованного payload'а и сравниваю с хешем текущего состояния. Если совпало — не пишу вообще. Это убивает остаточные циклы, где данные ходят по кругу, но фактически не меняются (например, amo нормализует телефон +7 (999) → 79990000000 и присылает обратно «изменение», которого нет).
Слой 4. Идемпотентность по external_id. На каждой строке Sheets держу external_id — UUID, сгенерированный при первом создании записи. Любая операция создания проверяет наличие такого ID на стороне получателя: есть — это update, нет — insert. Без этого при сбое сети получаешь дубли, которые потом дерутся друг с другом за «правду» и снова порождают петлю.
Все четыре слоя нужны одновременно. Я несколько раз пытался убрать «лишний» — и каждый раз через неделю ловил цикл на каком-нибудь экзотическом сценарии: массовый импорт, ручная правка во время webhook'а, рестарт скрипта с потерянной in-memory картой. Дешевле оставить избыточность.
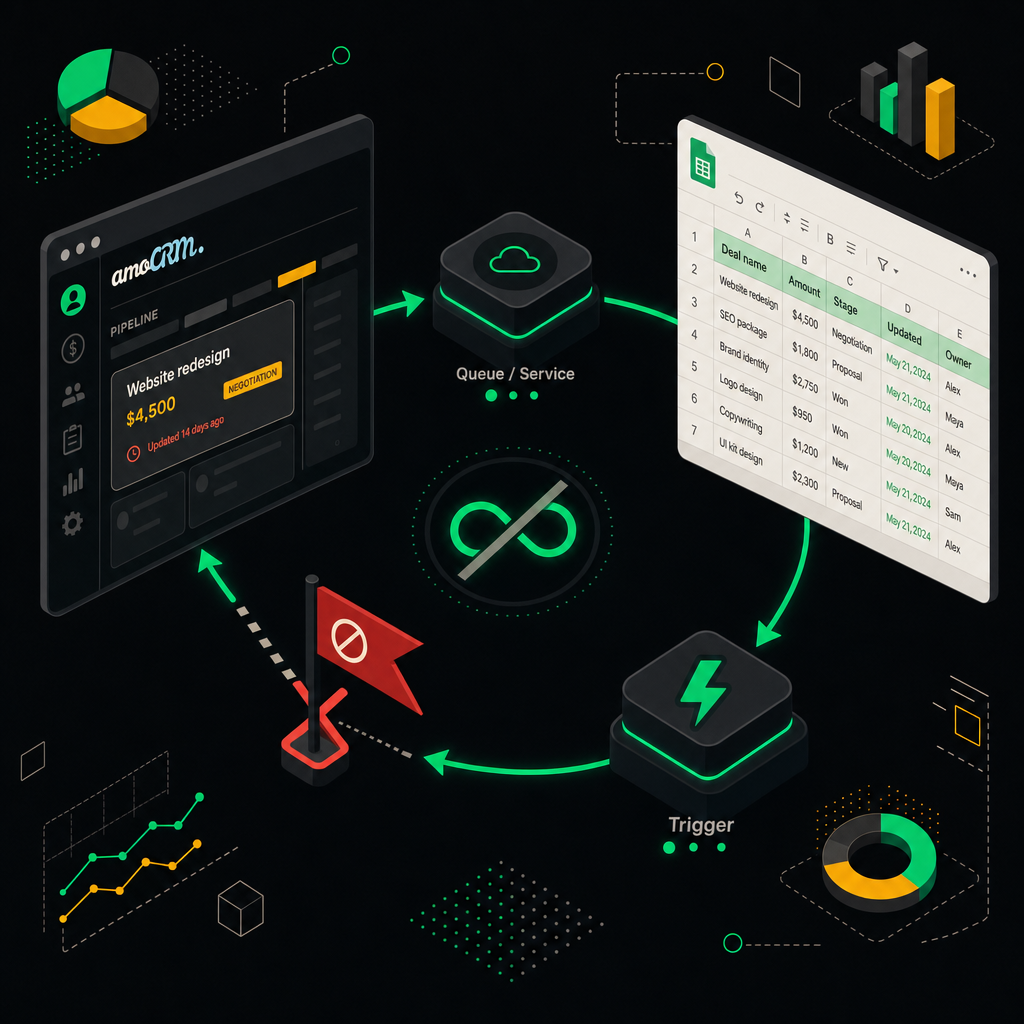
Sync-флаг блокирует повторную отправку события в источник, из которого пришло исходное изменение, разрывая петлю обновлений.
Маппинг полей и типов данных
Первое, с чем ломаешься при интеграции amoCRM и Google Sheets — типы данных не совпадают нигде. Буквально нигде. Разберём по частям.
Кастомные поля
amoCRM возвращает кастомные поля в custom_fields_values — массив объектов, где у каждого есть field_id, field_name и values. У values тоже массив, потому что мультиселект. Для простого select там один элемент с value (текстовое название) и enum_id (числовой идентификатор варианта). Для numeric — строка с числом, не число. Для date — unix timestamp в секундах.
Важно: если поле не заполнено, оно может отсутствовать в массиве или возвращаться иначе — поведение стоит проверить для конкретной версии API и типа поля, не полагаясь на предположения. Строй маппинг с учётом этого, иначе будешь обращаться к undefined.
Даты
amoCRM отдаёт даты как unix timestamp — например, 1703980800. Google Sheets понимает либо serial number (количество дней с 30 декабря 1899), либо строку формата YYYY-MM-DD. Конвертация:
// unix timestamp → serial number для Sheets
function unixToSerial(unix) {
const date = new Date(unix * 1000);
const serial = (date - new Date(Date.UTC(1899, 11, 30))) / 86400000;
return serial;
}
Если хочешь просто читаемую строку — new Date(unix * 1000).toISOString().split('T')[0]. Но тогда Sheets не сможет нормально сортировать и фильтровать по дате без дополнительного форматирования колонки.
Multiselect
В amo это массив объектов — каждый вариант отдельным элементом. В плоской таблице это некуда класть, поэтому стандартное решение: склеивать через запятую.
const multiselectValue = field.values
.map(v => v.value)
.join(', ');
Теряешь enum_id, зато читаемо. Если потом нужно фильтровать по конкретному значению в Sheets — либо храни в отдельных столбцах (плохо масштабируется), либо используй REGEXMATCH в формулах. Золотой середины нет, выбирай под задачу.
Телефоны и email
Это тоже массивы, но с типами. Структура у контакта:
"values": [
{"value": "+79001234567", "enum_code": "MOB"},
{"value": "+74951234567", "enum_code": "WORK"}
]
Если нужен один номер — бери первый или фильтруй по enum_code. Если нужны все — опять через запятую, но тогда типы теряются. Компромисс: два столбца, phone_mob и phone_work, и явно раскладывай по типам. Для большинства задач достаточно.
Связи сущностей
Сделка в amoCRM связана с контактами и компанией через _embedded. Там лежат массивы с id связанных сущностей, но не сами данные — только идентификаторы. Чтобы получить имя контакта или название компании, нужен отдельный запрос.
Либо делаешь два прохода: сначала тянешь все сделки, потом батчем запрашиваешь уникальные contact_id и company_id, строишь lookup-таблицу в памяти и джойнишь:
const contactsMap = new Map(
contacts.map(c => [c.id, c])
);
deals.forEach(deal => {
const primaryContact = deal._embedded?.contacts?.[0];
deal._contact = contactsMap.get(primaryContact?.id) ?? null;
});
Либо используешь параметр with=contacts,companies при запросе сделок — согласно документации amoCRM, это позволяет получить связанные данные прямо в _embedded, без дополнительных запросов. Но там доступен ограниченный набор полей без кастомных значений контакта. Для большинства Sheets-интеграций этого хватает — но поведение стоит проверить, так как ответ API может зависеть от конфигурации аккаунта.
В итоге плоская строка таблицы для сделки выглядит примерно так: поля сделки + имя первого контакта + телефон + email + название компании. Если контактов несколько — либо берёшь только первого, либо дублируешь строку для каждого контакта. Второй вариант ломает агрегацию, поэтому первый — чаще.

Явный маппинг типов полей исключает ошибки преобразования данных при передаче между amoCRM и Google Sheets.
Дубли и нормализация при двустороннем потоке
Самая частая причина, по которой двусторонняя синхронизация превращается в свалку — это дубли. Причём не потому что люди не думают об этом, а потому что думают слишком поздно, уже когда в amoCRM три Ивана Петрова и непонятно, который из них настоящий.
Начну с нормализации, потому что без неё дедупликация вообще не работает. Телефон +7 (916) 123-45-67, 79161234567 и 89161234567 — это один и тот же номер, но строковое сравнение этого не знает. Перед любым поиском по телефону я привожу всё в E.164: убираю пробелы, скобки, тире, заменяю восьмёрку на +7, добавляю плюс. Только после этого сравниваю. То же самое с email — нижний регистр, trim, и всё.
С ИНН проще, там формат жёсткий, но и его надо проверять на длину и контрольные цифры, иначе в поле прилетает 123 и создаётся новая сущность вместо обновления существующей.
Fuzzy-match по имени — инструмент последней надежды, который следует применять осторожно: только когда нет телефона и email, и только с высоким порогом сходства. Иначе Сергей Иванов и Сергей Иванченко окажутся одним контактом, и это будет хуже, чем дубль.
В amoCRM есть встроенный контроль дублей, и его надо включать. Но он работает только при создании через интерфейс и стандартный API-метод POST /contacts. Если делаешь массовую вставку из Google Sheets через batch-запросы — amoCRM этот контроль не применяет. Проверял лично. Залить 500 строк из таблицы и получить 500 новых контактов вместо 200 обновлённых — классическая история.
Поэтому стратегия одна: upsert через явный поиск перед созданием. Алгоритм выглядит так: нормализуешь ключевое поле → ищешь через GET /contacts?query=... → если нашёл, делаешь PATCH на существующий ID → если не нашёл, только тогда POST. Да, это два запроса вместо одного. Да, это медленнее. Но это единственный способ не плодить мусор.
При потоке из нескольких источников одновременно добавляется проблема гонки: два события



