

Контекст кейса: задача клиента и почему выбрали связку n8n + GPT
Клиент — B2C-сервис, два отдела с независимой историей, и поэтому два CRM одновременно: Bitrix24 у одного, amoCRM у другого. Объединять их в одну систему никто не собирался — слишком дорого организационно. В итоге значительный поток лидов идёт из двух источников, обрабатывается разными командами, и никакой единой точки контроля нет.
Цифры до интеграции были честными и неприятными. Время первого ответа было достаточно высоким — это не катастрофа на бумаге, но в реальности означает, что человек, который только что оставил заявку и ещё тёплый, успевает остыть, открыть конкурента и забыть, зачем вообще заходил. Заметная доля лидов терялась на этапе квалификации — не потому что продукт плохой, а потому что менеджер физически не успевал разобраться, кто перед ним, и скидывал заявку в «разобраться потом».
Когда начали выбирать инструмент автоматизации, Make и Zapier отсекли быстро. Оба — облачные, оба имеют лимиты на операции, и оба поднимают закономерный вопрос: где физически обрабатываются данные клиентов. В 2026 году это уже не паранойя, а стандартная due diligence для любого российского B2C с персданными. n8n развернули self-hosted на VPS в РФ — данные не покидают контур, лимитов на количество операций нет, и это сразу снимает головную боль с масштабированием. Интеграция с Bitrix24 реализуется через встроенные возможности n8n, amoCRM закрыли через HTTP-запросы — там API достаточно предсказуемый, чтобы не страдать.
GPT-агент вместо правил — это был принципиальный момент. Заявки приходят в свободной форме: кто-то пишет «хочу узнать про тариф», кто-то — «мне нужно для малого бизнеса на троих человек, бюджет ограничен». Никакой regexp и никакое дерево условий это нормально не классифицирует. Нужна была модель, которая читает текст и понимает намерение, а не ищет ключевые слова. Плюс персональный первый ответ — не шаблонное «спасибо за заявку», а что-то, что показывает: заявку прочитали.

Ручное переключение между двумя CRM отнимает до 30% рабочего времени менеджера и порождает ошибки дублирования.
Архитектура решения: как связаны Bitrix24, amoCRM, n8n и LLM
Когда у клиента две CRM (а это, к моему удивлению, всё ещё типичная история — отдел продаж сидит в amoCRM, маркетинг и сервис в Bitrix24), первый вопрос — куда бить вебхуками. Я не делаю по экземпляру воркфлоу на каждую систему. Все события приходят в одну точку входа в n8n: ONCRMLEADADD из Bitrix24 и leads:add из amoCRM летят на /webhook/lead-ingest. Дальше Switch-нода смотрит на хедер X-Source (его я добавляю на стороне Bitrix через исходящий вебхук, у amo берётся из тела) и разводит по нормализаторам.
Нормализация — самое скучное и самое важное. Делаю её в Function-ноде, без отдельного сервиса, потому что это чистая трансформация без сайд-эффектов. Что выравниваю:
- Телефон —
libphonenumber-js, всё к E.164. Bitrix отдаёт массив объектовPHONE[], amo — плоское поле вcustom_fields_values. На выходеphone: "+79991234567". - UTM — у Bitrix они в
UF_*полях, у amo в кастомных полях лида с разными ID на разных аккаунтах. Держу маппинг в переменных окружения n8n, не в коде. - Источник — приводится к перечислению
{organic, paid, referral, direct, offline}. Сырое значение сохраняю вsource_rawдля отладки.
После нормализации лид — это плоский JSON одной формы, и дальше пайплайну плевать, откуда он пришёл.
LLM-часть рекомендую выносить в отдельный микросервис (например, на FastAPI), организовав взаимодействие с n8n по HTTP. Причин три: версионирование промптов независимо от воркфлоу, возможность переиспользовать агента из других мест (бот в Telegram, обработка писем), и нормальные юнит-тесты на питоне вместо тыканья в UI n8n. Агент в одном вызове может классифицировать лид, извлекать сущности и генерировать черновик первого ответа — конкретная реализация зависит от архитектурных решений по проекту. Ответ лучше структурировать как строгий JSON по схеме и валидировать через Pydantic; при невалидном ответе имеет смысл предусмотреть ретрай с пониженной температурой и явным указанием схемы в системном промпте.
Перед вызовом LLM стоит Redis в режиме очереди (BullMQ-совместимый формат, чтобы при необходимости вынести воркер из n8n). Зачем:
- Сглаживание пиков. Когда маркетинг запускает рассылку, за минуту прилетает много лидов. Без очереди можно упереться в rate limit OpenAI или словить таймауты в воркфлоу.
- Контроль стоимости. На очереди висит лимитер — не больше N токенов в минуту. Если упираемся, лиды просто ждут, а не теряются и не плодят повторные вызовы.
- Дедупликация. Bitrix иногда дёргает вебхук дважды на одно событие; ключ идемпотентности в Redis помогает отсекать дубли.
Запись обратно — самая хрупкая часть, потому что API двух CRM ведут себя по-разному. В Bitrix зову crm.lead.update с полями классификации и тегами, плюс crm.timeline.comment.add с черновиком ответа — менеджер видит его сразу в карточке. В amoCRM это PATCH /api/v4/leads/{id} для кастомных полей и POST /api/v4/leads/{id}/notes для черновика. На обе записи рекомендую ретрай с экспоненциальной задержкой — токен amo любит протухать, а Bitrix умеет отвечать 500 на ровном месте.
Решения агента имеет смысл логировать в PostgreSQL: входной нормализованный лид, версия промпта, модель, токены, итоговый JSON, время ответа, флаг успешной записи в CRM. Такая таблица — и аудит (через полгода клиент спрашивает «почему этот лид ушёл в мусор»), и материал для дообучения промптов. Регулярная выгрузка случаев, где менеджеры вручную переклассифицировали лида, позволяет прогонять новые версии промпта в офлайне — без этого любые правки превращаются в гадание.
Схематично поток выглядит так:
Bitrix24 ──┐
├─→ n8n /webhook/lead-ingest ─→ Normalize ─→ Redis Queue ─→ LLM Service ─┐
amoCRM ──┘ │
▼
PostgreSQL ←─ Log ←─ n8n Writer ─→ Bitrix24 / amoCRM API
Никакой магии — каждый блок делает одну вещь и его можно выдернуть и заменить отдельно. Например, в одном из проектов в этом году мы поменяли GPT-агента на локальную модель за пару дней, потому что интерфейс микросервиса остался тем же.
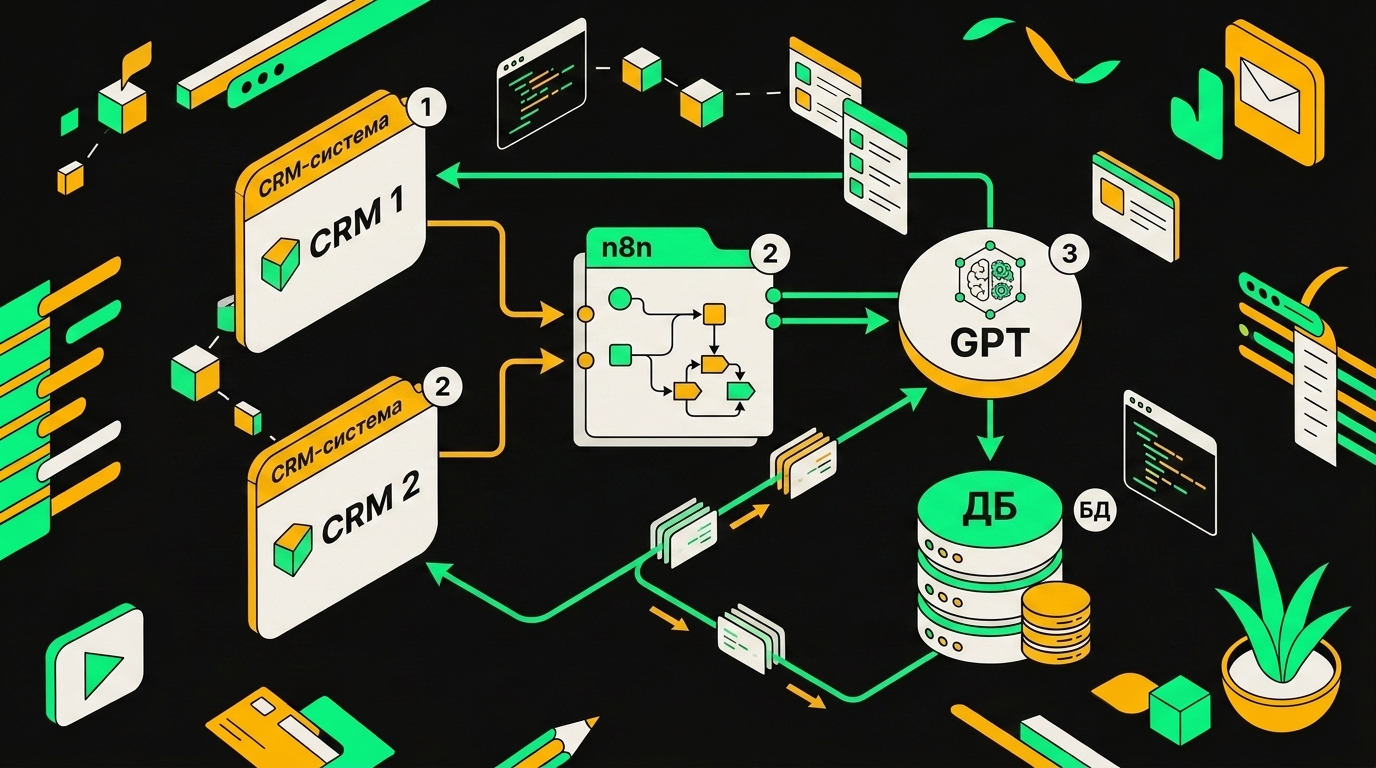
Данные из обеих CRM поступают в n8n, где GPT обогащает и маршрутизирует их в единый синхронизированный pipeline.
Настройка триггеров и аутентификации в Bitrix24 и amoCRM
Начну с Bitrix24, потому что там подвох вылезает раньше всего. Делаю входящий вебхук в разделе «Разработчикам» — права беру минимальные, только crm, без user, task и прочей мишуры. Дальше регистрирую обработчик события через REST-метод event.bind:
POST https://your-portal.bitrix24.ru/rest/1/<webhook_code>/event.bind.json
event=ONCRMLEADADD
handler=https://n8n.example.com/webhook/b24-lead
auth_type=0
Первая ловушка ждёт на стороне n8n. Bitrix24 шлёт payload в application/x-www-form-urlencoded — поля приходят сплющенным деревом вида data[FIELDS][ID]=123. Если в ноде Webhook оставить дефолтный режим, вы получите либо пустое тело, либо невалидный JSON. В настройках ноды стоит переключить Response Mode так, чтобы Битрикс получал 200 быстро — иначе он ретраит и плодит дубли — и убедиться, что n8n корректно парсит form-data в объект. Дальше — Function-нода, которая проверяет application_token (Битрикс отдаёт его в auth.application_token для каждого события):
// n8n Function node: верификация webhook от Bitrix24
const auth = $input.item.json.auth;
if (!auth || auth.application_token !== $env.B24_APP_TOKEN) {
throw new Error('Invalid Bitrix24 token');
}
return { json: $input.item.json.data.FIELDS };
Токен лежит в переменных окружения n8n, не в самом workflow — иначе при экспорте JSON он утечёт в репозиторий. Дополнительно вешаю на эндпоинт два слоя защиты: HMAC-подпись в заголовке (считаю SHA-256 от тела с общим секретом и сверяю в той же Function-ноде) и IP whitelist на уровне reverse-proxy. Список IP порталов Bitrix24 берётся из их CIDR-блоков, для облачных порталов он стабильный, для self-hosted — фиксированный адрес заказчика.
С amoCRM логика другая — там OAuth 2.0 и долгоживущая интеграция. В n8n использую встроенный credential-тип amoCRM OAuth2 API, прохожу авторизацию один раз, access_token живёт 24 часа, refresh_token — до тех пор, пока им пользуются. Здесь важный нюанс: согласно документации amoCRM, refresh_token может аннулироваться при длительном простое — рекомендую проверить актуальное поведение в официальной документации и настроить регулярное обновление токенов с запасом по времени. Удобно поставить отдельный workflow с Cron-триггером, который периодически выполняет лёгкий запрос (GET /api/v4/account): n8n при этом сам прозрачно обновит пару токенов и перезапишет credential.
Тестовую среду держу полностью отдельно от прода: бесплатный портал Bitrix24 с тестовыми лидами и trial amoCRM на 14 дней (этого хватает прогнать миграцию схемы и нагрузку). В n8n — отдельные credential-записи b24_dev / amo_dev и переменная окружения ENV=dev, по которой Switch-нода в начале workflow роутит данные на тестовый или боевой эндпоинт. Без этого разделения один невнимательный merge — и тестовые контакты улетают живому отделу продаж.
GPT-агент: промпт, инструменты и логика принятия решений
Внутри агента я разделил два слоя: классификация и генерация. Это не дань моде на «дешевле и дороже», а вопрос, где именно нужна голова, а где — реакция. На вход в воронку прилетает большой поток заявок, и гнать каждую через топовую модель — деньги на ветер. Поэтому первичный разбор лучше делать быстрой и дешёвой моделью (например, GPT-4o-mini): быстро, копеечно, и при правильном промпте даёт высокую точность классификации. А вот когда уже надо писать клиенту в чат — имеет смысл подключать более мощную модель, потому что разница в «живости» текста на коротких ответах всё ещё заметна, особенно на русском.
Для тех, кому нужен РФ-контур без танцев с VPN и прокладок — вместо OpenAI спокойно встаёт GigaChat Pro или YandexGPT 5.1 Pro. У меня в одном проекте крутится связка YandexGPT 5.1 Pro через AITunnel (на классификации) + GigaChat Pro на генерации. По качеству на ру-текстах сейчас они в одной лиге с 4o-mini/4.1, разница в нюансах тона. Function calling у обоих уже работает нормально, схему ответа держат. Подробнее о том, как выбрать модель и настроить GPT-агента для обработки заявок в мессенджерах, можно разобраться на примере Telegram-интеграции.
Семь категорий лида
Системный промпт жёстко фиксирует таксономию, чтобы модель не изобретала собственные ярлыки:
- hot — явный запрос на покупку, сроки, бюджет;
- warm — интерес есть, но без конкретики;
- cold — общий вопрос, информационный;
- spam — мусор, боты, реклама услуг;
- duplicate — повторное обращение того же клиента;
- b2b — корпоративный запрос, уходит в отдельную ветку;
- irrelevant — не наш профиль.
Без такой жёсткой сетки модель начинает изобретать промежуточные категории вроде «потенциально тёплый» — и весь даунстрим ломается.
Инструменты
У агента четыре функции, которые он вызывает сам:
get_client_history(phone, email)— поднимает все касания из CRM за последние 18 месяцев;find_duplicate(phone, email, text_hash)— ищет ту же заявку за последние 72 часа;score_lead(features)— отдельный скоринг по правилам (UTM, регион, источник), возвращает 0–100;draft_reply(category, context)— генерация черновика ответа уже на более мощной модели.
Логика такая: модель сначала вызывает find_duplicate, потом get_client_history, и только после этого выносит категорию. score_lead и draft_reply дёргаются по необходимости — например, для spam и irrelevant мы не тратим токены на черновик.
Температура
Для классификации рекомендую низкую температуру (около 0.2) — нужна детерминированность, одинаковый вход должен давать одинаковый выход. Для первого сообщения клиенту — выше (около 0.7), иначе текст звучит как отчёт робота. На последующих репликах в диалоге можно опустить, чтобы не «уплывало» от стиля компании.
Защита от галлюцинаций
Главное — strict JSON schema на выходе плюс валидация через AJV. Если модель выдала что-то не по схеме, имеет смысл предусмотреть один ретрай с уточняющим промптом, а если и он мимо — фолбэк на чисто правиловый классификатор. Этот фолбэк проще и тупее, но никогда не падает.
Минимальный конфиг запроса для классификатора:
{
"model": "gpt-4o-mini",
"response_format": {"type": "json_schema", "json_schema": {
"name": "lead_decision",
"schema": {
"type": "object",
"properties": {
"category": {"enum": ["hot","warm","cold","spam","duplicate","b2b","irrelevant"]},
"score": {"type": "integer", "minimum": 0, "maximum": 100},
"next_action": {"enum": ["call","email","skip","transfer"]},
"reply_draft": {"type": "string"}
},
"required": ["category","score","next_action"]
}
}}
}
reply_draft намеренно не в required: для мусорных категорий он просто не нужен, и я не хочу заставлять модель его придумывать. А score дублирует результат score_lead — это контрольная точка: если расхождение большое, заявка уходит на ручную проверку оператору. Такая сверка помогает отловить пограничные случаи, которые по отдельности обе системы классифицируют уверенно, но по-разному.
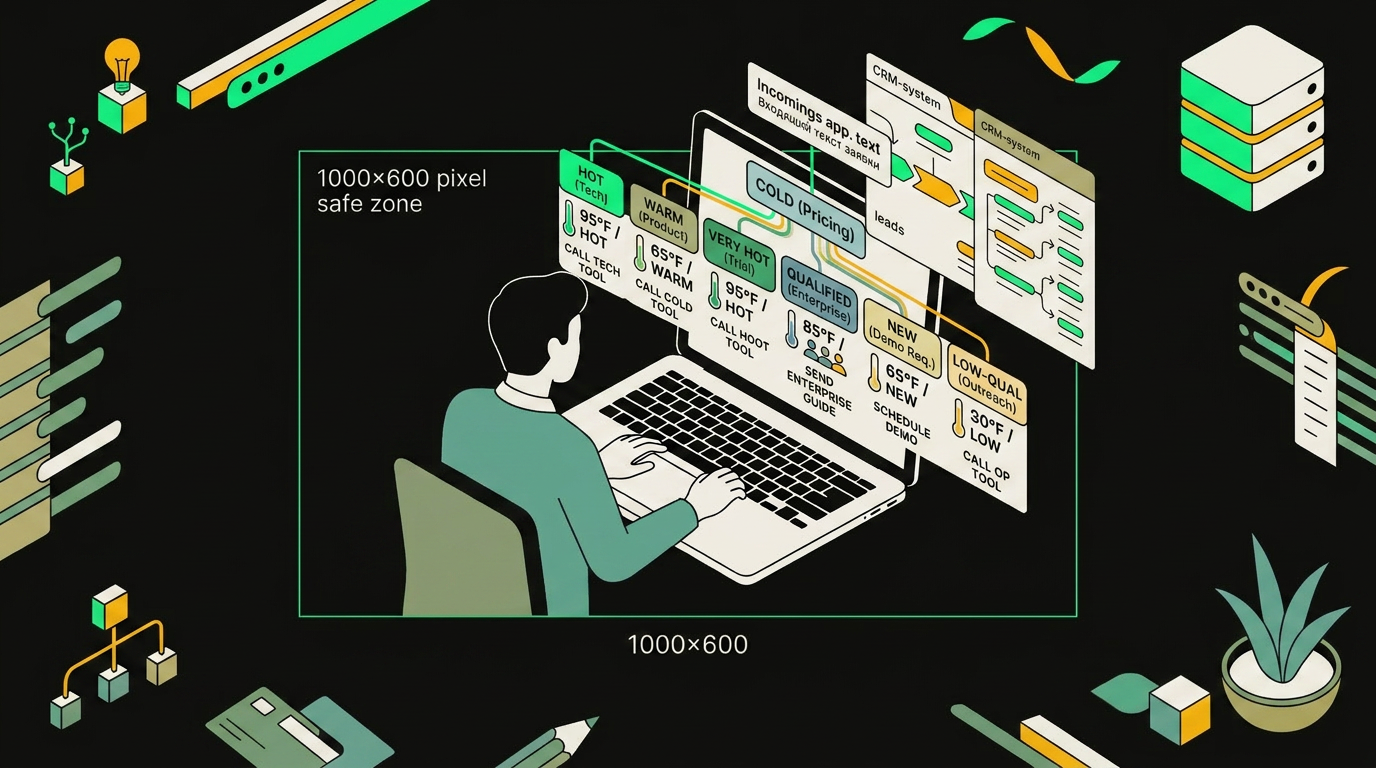
GPT анализирует атрибуты лида и по ветвям дерева решений присваивает категорию, приоритет и ответственного менеджера.
Дедупликация и синхронизация контактов между Bitrix24 и amoCRM
Главная боль любой двусторонней синхронизации — петли и зомби-дубли. У меня сейчас в продакшне лежит связка из десятка проектов, где Bitrix24 и amoCRM работают параллельно (отделы продаж исторически сидят в разных системах), и единственный способ не сойти с ума — жёсткие правила нормализации и идемпотентность на уровне external_id.
Поиск дубля сразу в обеих системах
Перед любым созданием контакта я гоняю две проверки параллельно: по телефону, приведённому к E.164, и по email в нижнем регистре с обрезанными плюс-алиасами. Делать только по телефону — мало: люди меняют номера, но email тащат годами. Только по email — тоже мало: B2C клиенты часто оставляют левую почту, а звонят с реального мобильного.
// Поиск дубля в Bitrix24
const phone = normalizePhone(item.phone);
const res = await $http.post('https://portal.bitrix24.ru/rest/1/TOKEN/crm.duplicate.findbycomm', {
type: 'PHONE', values: [phone], entity_type: 'LEAD'
});
return { duplicateId: res.result?.LEAD?.[0] || null };
Аналогичный запрос уходит в crm.duplicate.findbycomm с type: 'EMAIL' и в amoCRM через /api/v4/contacts?query=.... Если хоть в одной системе пришёл хит — я не создаю новый контакт, а ухожу в ветку обновления.
Кто мастер: тот, у кого деньги
Если контакт нашёлся в обеих CRM, начинается весёлое — чьи данные считать истиной. Я отказался от примитивных правил вида «у кого позже updated_at» — там вечно выигрывает та CRM, где менеджер только что переписал имя с ошибкой. Сейчас работает правило: мастер-системой считается та, где зафиксирована последняя успешная оплата. Тяну last_payment_at из сделок (статус «Оплачено» в Б24, соответствующий статус воронки в amo) и сравниваю timestamp'ы. Логика простая — кто реально работает с клиентом и доводит до денег, тот и владеет карточкой.
Маппинг полей через JSON-конфиг
Хардкодить соответствие полей в нодах n8n — путь в ад, особенно когда у клиента 40+ кастомных полей. Я храню маппинг отдельным конфигом и читаю его в Function-ноде:
{
"utm_source": { "b24": "UF_CRM_1701234567", "amo": 654321 },
"utm_medium": { "b24": "UF_CRM_1701234568", "amo": 654322 },
"source_label": { "b24": "SOURCE_ID", "amo": 654323 },
"manager": { "b24": "ASSIGNED_BY_ID", "amo": "responsible_user_id" }
}
Конфиг лежит в Git, при изменении полей в CRM правится одна строка, а не пять воркфлоу. UTM-метки тащу всегда — без них аналитика по каналам разваливается на стыке систем.
Конфликты решает не код, а человек
Когда расхождение в данных не критичное (другой регистр в имени, лишний пробел) — затираю по правилу мастера и забываю. Но если расходится телефон, email, ответственный или сумма последней сделки — это уже не для автомата. В этой ветке я зову GPT-агента: он получает оба JSON-объекта, формирует человекочитаемый diff и кидает его в Telegram руководителю отдела с инлайн-кнопками «Б24 → amo», «amo → Б24», «оставить как есть». Похожий подход к уведомлениям через Telegram-бота при конфликтах данных и ручном подтверждении решений хорошо себя показал и в других сценариях автоматизации.
⚠️ Конфликт по контакту #4471 (Иван П.)
phone: +79991234567 → +79997654321 [amo]
responsible: Петров → Сидорова [b24]
last_deal: 180 000 ₽ → 240 000 ₽ [b24]
GPT здесь не принимает решение — он только нормализует diff и подсвечивает поля, где расхождение похоже на реальную смену данных, а не на опечатку. Решение всегда за человеком, ответ возвращается в n8n через webhook и применяется к обеим системам.
Идемпотентность: external_id или смерть
Самая токсичная штука в двусторонней синхронизации — петли. Контакт создался в Б24 → ушёл в amo → amo прислал webhook «новый контакт» → создался ещё раз в Б24, и так до бесконечности. Лечится только одним способом: external_id источника пишется в обе CRM в отдельное поле (UF_CRM_EXTERNAL_ID в Б24 и кастомное поле в amo). Перед любой записью воркфлоу проверяет: если external_id уже есть в целевой системе — это эхо моей же синхронизации, тихо игнорирую. Если нет — это настоящее изменение от менеджера, обрабатываю.
Дополнительно держу Redis с TTL 60 секунд, куда кладу хеш {contact_id}:{updated_at} сразу после записи. Если за минуту прилетает webhook с тем же хешем — это снова я сам себе пишу, отбрасываю на входе. Эта мелочь спасает от гонок, когда обе CRM успевают отстрелить webhook быстрее, чем доедет первый ответ.

Алгоритм сравнивает email, телефон и имя контакта в обеих базах и автоматически сливает дубликаты в единую запись.
Обработка ошибок, лимитов API и стоимости LLM
Три источника боли в продакшн-интеграции CRM с LLM: ограничения API платформ, неконтролируемые расходы на модели и тихие деградации, которые ты замечаешь через час, а не через минуту. Разберём каждый.
Лимиты Bitrix24 и amoCRM — не симметричные задачи. Bitrix24 режет на уровне портала: актуальные лимиты стоит уточнять в документации, но типично это несколько запросов в секунду. Я ставлю Rate Limit ноду с небольшим запасом ниже документированного лимита — запас нужен потому, что метки времени между n8n и серверами Bitrix немного расходятся. На amoCRM лимит мягче, но здесь важна другая механика: ретраи с экспоненциальным бэкоффом. Несколько попыток с нарастающей задержкой — без этого при кратковременном спайке запросов ты теряешь события молча.
Стоимость GPT — это переменная, которую нужно контролировать как метрику, а не как строку в счёте. Бюджет кажется абстрактным, пока не видишь, как один плохо отфильтрованный поток лидов сжигает его за несколько часов. Я реализую это через счётчик в Redis с TTL на сутки: каждый вызов модели инкрементирует значение на фактическую стоимость токенов. Как только счётчик пробивает порог — воркфлоу автоматически переключает endpoint на более дешёвую модель. Не алерт, не письмо команде, а именно хард-свитч без участия человека. Качество классификации немного падает, но система продолжает работать, а не останавливается.
Отдельно про кеш классификаций. Большинство потоков лидов содержат повторяющиеся паттерны: одинаковые UTM-метки, похожие формулировки заявок, стандартные источники. Если хешировать входные данные лида и класть результат классификации в Redis с TTL 24 часа — в типичном B2C-потоке это заметно сокращает количество запросов к модели. Не нужно гонять через GPT сотый лид с «хочу купить квартиру в ипотеку» из одного и того же рекламного кабинета.
Алерты — это отдельная архитектура, не afterthought. Два триггера, которые я считаю обязательными:
- Ошибки выше порогового значения за скользящее окно → Telegram-уведомление с именем воркфлоу и последним stack



