Откуда взялась мода на мультиагентность и почему она ломается на проде
Где-то в 2024 году в каждом втором стартапном питч-деке появилась схема: несколько кружочков с подписями "Researcher", "Planner", "Critic", стрелки между ними и подпись "multi-agent system". CrewAI набрал 20k звёзд на GitHub за несколько месяцев. AutoGen от Microsoft стал дефолтным ответом на вопрос "как запустить сложный AI-пайплайн". Swarm появился как экспериментальный фреймворк от OpenAI и мгновенно превратился в референс-архитектуру в головах инженеров.
Откуда это взялось, понять несложно. GPT-4 в 2023 году давал 8k токенов, потом 32k. Прогнать через модель большой документ или длинный диалог означало либо дорого, либо невозможно. Разделить задачу на агентов, каждый из которых работает в своём маленьком контексте, казалось элегантным инженерным решением. Архитекторы взяли знакомую идею из распределённых систем: декомпозируй, изолируй ответственность, собери результат.
Проблема в том, что распределённые системы работают с сервисами, у которых есть чёткий контракт. Microservice либо возвращает JSON нужной схемы, либо бросает исключение. LLM не бросает исключений. Он возвращает текст, который выглядит как правильный ответ, пахнет как правильный ответ, но содержит галлюцинацию на третьей строке или тихо игнорирует половину инструкции. В цепочке из четырёх агентов эта ошибка размножается. Каждый следующий агент принимает испорченный вывод предыдущего за истину и строит на нём своё рассуждение.
На проде это выглядит конкретно: pipeline проходит все unit-тесты, потому что на тестовых данных агент-critic ловил ошибки агента-planner. На реальных данных critic уверенно подтверждает ошибку, потому что она сформулирована достаточно убедительно. Воспроизвести баг сложно: та же цепочка промптов на следующий день даёт другой результат из-за temperature или обновления модели на стороне провайдера.
Но самое интересное: основная техническая причина появления MAS-архитектур в 2024 году в 2026 году уже не существует. Gemini 2.5 Pro работает с 2 млн токенов в проде. Claude 3.7 и GPT-5.5 держат 1M. Стоимость инференса заметно снизилась по сравнению с 2023-м. Задача, которую раньше приходилось дробить на шесть агентов, чтобы влезть в контекст, сейчас решается одним промптом с полным контекстом. И этот один промпт проще отлаживать, проще версионировать, проще мониторить.
Академическая критика парадигмы "серебряной пули" в мультиагентных системах звучала задолго до того, как LLM-агенты стали модными. Чернышев и другие исследователи MAS ещё в 2000-х указывали: координация между агентами сама по себе становится источником сложности, которую легко недооценить при проектировании. Координационные издержки растут нелинейно с числом агентов. В классических MAS это решалось формальными протоколами верификации. В LLM-агентах формального протокола нет: есть промпт, который интерпретируется по-разному в зависимости от контекста.
Мультиагентная архитектура решает реальные задачи в конкретных сценариях: параллельное выполнение независимых подзадач, специализация под разные инструменты, разделение ролей с разными правами доступа. Но как универсальный ответ на сложность, как способ обойти ограничения контекста или как архитектурный паттерн по умолчанию, она в 2026 году выглядит анахронизмом. Проблема, которую она решала, во многом ушла. А сложность, которую она добавляет, осталась.
Контекстное окно выросло с 4 тысяч токенов у GPT-3 до миллиона у Gemini 1.5 Pro, и главный аргумент в пользу мультиагентности стал значительно слабее.
Что такое "толстый агент" и чем он отличается от оркестратора крю
Толстый агент это один LLM-цикл с раздутым системным промптом (правила, примеры, политики), пулом инструментов и плоской памятью внутри одного контекста. Никакого CrewAI с ролями researcher/writer/critic, никаких A2A-протоколов, никаких очередей сообщений между автономными воркерами. Один цикл ReAct: think → tool_call → observation → think. Пока модель не скажет "готово" или не упрётся в max_iterations.
# Толстый агент: один цикл, много инструментов
agent = Agent(
model='claude-sonnet-4.5',
system=LONG_SYSTEM_PROMPT, # правила, примеры, политики
tools=[search_web, read_file, write_file, run_sql,
call_api, send_email, schedule_task, ...],
max_iterations=40,
)
result = agent.run(user_task)
Сравните это с типовой крю-архитектурой 2024 года, где "ресёрчер" пишет в шаред-память, "критик" читает оттуда и роняет ответ обратно, а "райтер" собирает финал. Там три независимых LLM-сессии, три системных промпта, три истории сообщений и протокол передачи между ними. У толстого агента всё это схлопнуто: то, что в крю было ролью, здесь стало либо инструментом (critique_draft(text)), либо секцией системного промпта ("когда черновик готов, перечитай его глазами редактора и проверь по чек-листу ниже"), либо просто очередным шагом ReAct.
Главное отличие не в количестве файлов кода. Оно в двух вещах.
Первое: состояние. В крю состояние размазано по сообщениям между агентами, и каждый агент видит только свой кусок. Если writer не получил факт от researcher, факт потерян. У толстого агента весь ход рассуждений, все наблюдения от тулов и все промежуточные выводы лежат в одном контекстном окне. Модель на 30-м шаге помнит, что увидела на 4-м, без специальных handoff-сообщений.
Второе: автономность. В классическом MAS каждый агент это автономный процесс с собственными целями и протоколом общения (отсюда вся возня с FIPA-ACL в академии и с message bus в продакшне). У толстого агента автономии у "ролей" нет вообще, потому что ролей нет. Есть один планировщик, и он же исполнитель, и он же критик, просто на разных итерациях петли.
Это не значит, что мультиагентные системы умерли. Они полезны, когда задачи реально параллелятся (исследовать 50 компаний одновременно) или когда нужна изоляция контекстов по соображениям безопасности. Но для большинства того, что в 2024 пихали в Crew или AutoGen, сейчас хватает одного толстого цикла, и работает он предсказуемее, дешевле по токенам и сильно проще в отладке: трейс линейный, а не граф. Именно такой подход лежит в основе архитектуры RAG-агента по корпоративной базе знаний, где один агент с поиском по векторной базе стабильно обходит пайплайны с несколькими специализированными воркерами.
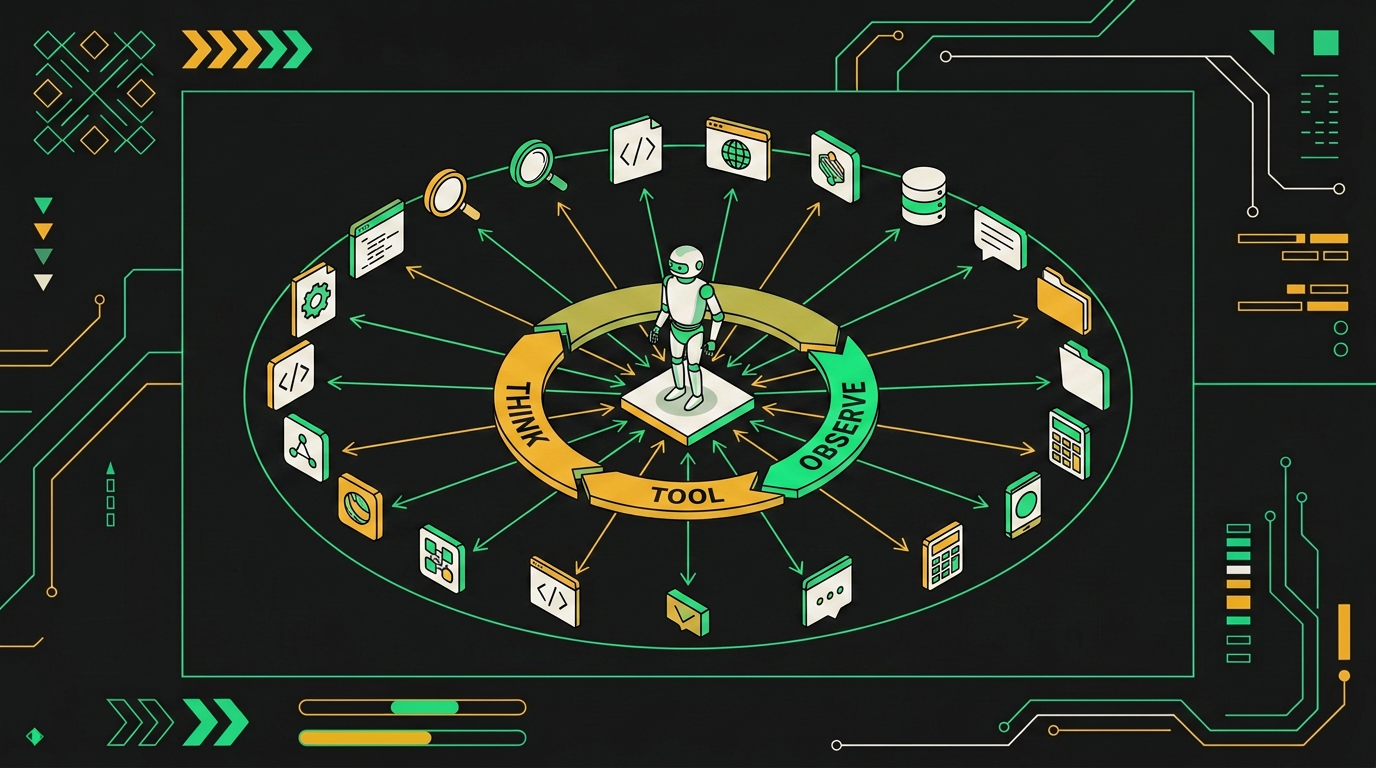
Толстый агент держит весь контекст задачи в одном окне и вызывает инструменты через ReAct-цикл без промежуточных LLM-вызовов.
Цифры: где мультиагентные фреймворки реально проигрывают
Существующие бенчмарки по фреймворкам на задачах с несколькими tool calls показывают: оркестровая архитектура добавляет точек отказа быстрее, чем добавляет интеллект. LangGraph, Smolagents, CrewAI, AutoGen стабильно уступают одному хорошо настроенному агенту на задачах средней сложности. Разрыв не огромный по цифрам, но он воспроизводится.
Паттерн повторяется: добавление агентов не увеличивает качество вывода.
Теперь деньги. Каждый межагентный обмен в современных фреймворках устроен так, что каждый агент получает весь контекст заново. Это не баг реализации, это архитектурное следствие stateless LLM. Crew из нескольких агентов на одной задаче сжигает заметно больше токенов, чем "толстый" одиночный агент, который делает то же самое. Расходы растут с каждым дополнительным агентом, и на больших задачах разница становится ощутимой.
Латентность. Последовательная цепочка агентов добавляет задержки не только на вычисления и tool calls, но и на передачу состояния между шагами. На интерактивных задачах это ощущается физически.
И последнее, про что обычно молчат в туториалах: дебаг. Когда агент-оркестратор что-то сделал не так, ты открываешь трейс и видишь сотни межагентных сообщений. Попробуй найди, где именно решение пошло не туда. Один линейный лог ReAct-агента с теми же tool calls читается за минуту. Трейс мультиагентного пайплайна на сопоставимой задаче требует либо специального инструмента визуализации, либо нескольких часов ручного разбора.
Это не значит, что мультиагентные системы не нужны. Но прежде чем тянуться за CrewAI или LangGraph, стоит задать вопрос: а задача действительно требует оркестрации, или это просто модно выглядит в архитектурной схеме?
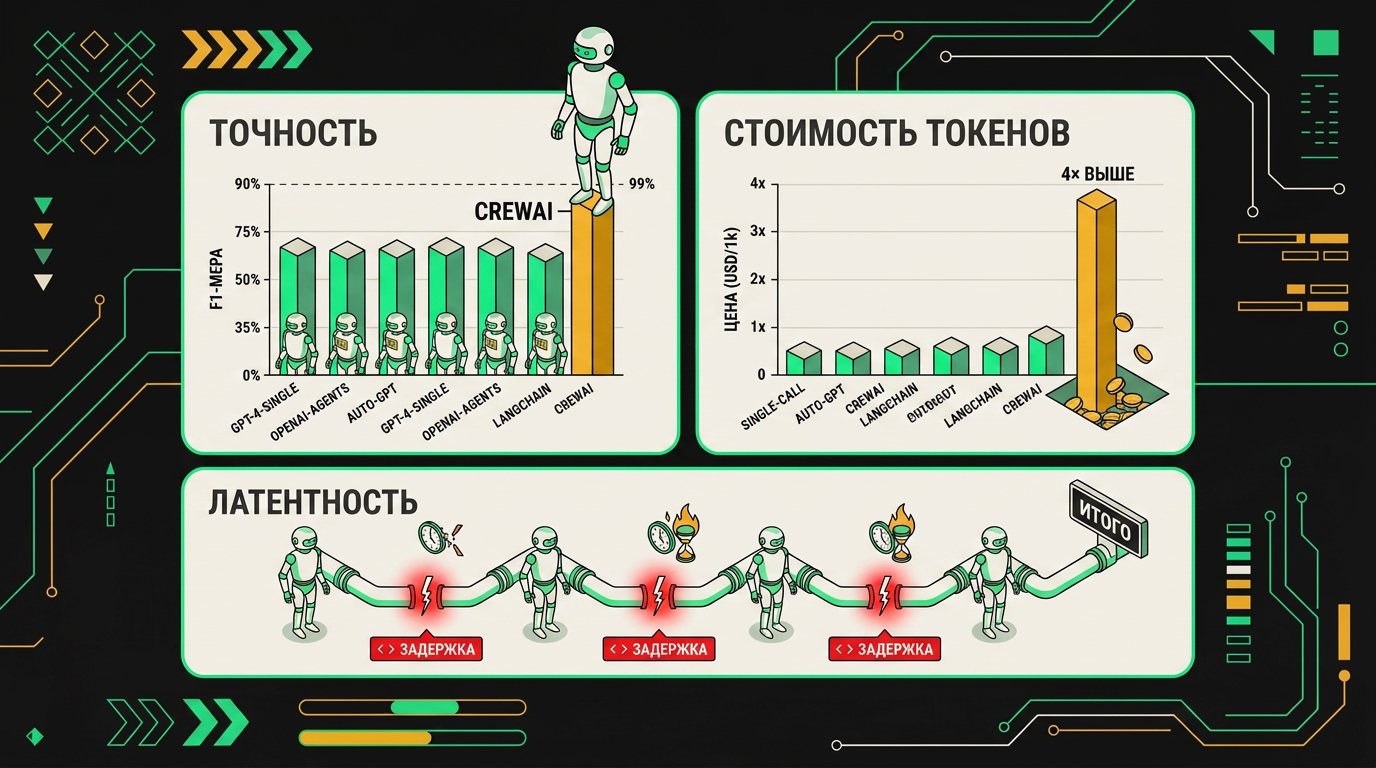
На задачах с линейной цепочкой зависимостей толстый агент проигрывает по стоимости за счёт большего контекста, но выигрывает по точности из-за отсутствия потерь при передаче данных.
Когда мультиагентность всё-таки оправдана (те самые 2 случая из 10)
Я видел достаточно провальных мультиагентных систем, чтобы теперь требовать чёткого ответа на вопрос: зачем здесь несколько агентов? Если ответ звучит как "так гибче" или "так интереснее архитектурно", это не ответ. Но иногда обоснование реальное.
Принципиально разные модели под разные задачи. Быстрые дешёвые модели и медленные дорогие решают разные задачи по-разному. Если у тебя конвейер, где нужно прогнать тысячи документов через черновую классификацию, а потом выбросы отдать на финальную проверку с глубоким рассуждением, два агента с разными моделями могут сэкономить и деньги, и время. Это про стоимость вычислений, а не про архитектурную красоту.
Жёсткая изоляция прав доступа. Есть ситуации, где архитектурного разделения мало. Агент с токеном к продовой базе не должен физически получать пользовательский ввод. Не потому что "так безопаснее на словах", а потому что иначе prompt injection через пользовательское поле становится вектором к продовым данным. Два изолированных процесса с разными credential scope, это граница, которую один агент провести не может.
Параллельная обработка по-настоящему независимых задач. Ключевое слово здесь "независимых". Если у тебя 50 источников для обхода и каждый запрос занимает 40-60 секунд, последовательная обработка медленная. Параллельная, с пулом агентов, кратно быстрее. Это работает только когда задачи не делят состояние и не ждут друг друга. Рендеринг независимых отчётов, параллельное извлечение данных из разрозненных API, да. Всё, где есть зависимости по данным, нет.
Долгоживущие воркфлоу с разными SLA на этапах. Представь процесс, где этап A занимает 2 минуты и требует ответа пользователю, этап B запускается через 6 часов после human approval, этап C через сутки. Один агент, который "спит" между этапами, удерживает соединение, хранит состояние в памяти и падает при рестарте сервиса, плохая идея. Отдельные агенты с явной передачей состояния через хранилище держат каждый этап независимо. Это нормальная инженерия под конкретные SLA.
Регуляторное разделение ответственности. В финансах и медицине иногда требуется буквально отдельный "проверяющий" субъект, который не участвовал в генерации решения. Не просто второй вызов той же модели внутри одного агента, а отдельный процесс с отдельным логом, который можно показать аудитору. Если регулятор требует четырёх глаз при выдаче кредита или при формировании дозировки, compliance-агент как изолированный слой закрывает это требование формально и технически.
Пять сценариев. Но в реальных проектах они встречаются реже, чем кажется. Большинство систем, которые я разбирал за последние полгода, попадали под один из двух: либо "параллельность" оказывалась иллюзорной из-за скрытых зависимостей, либо "изоляция" решалась банальным разделением на функции внутри одного агента. Так что прежде чем добавлять второй агент, стоит потратить 20 минут и честно проверить каждый из этих пяти критериев.
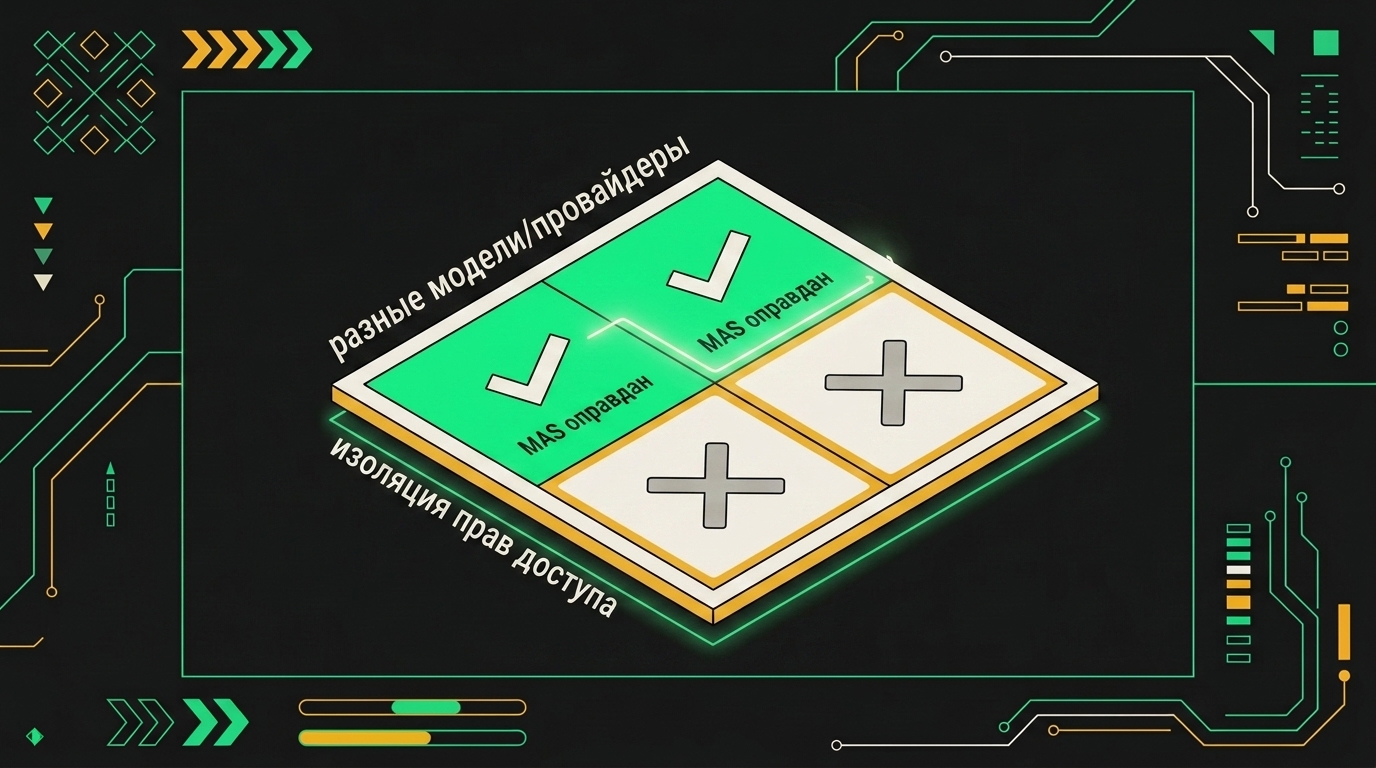
Мультиагентная архитектура оправдана, когда подзадачи независимы и могут выполняться параллельно без обмена промежуточными результатами.
Почему контекстное окно убило главный аргумент за MAS
В 2023 году у меня не было выбора. GPT-4 с 32k токенов не вмещал даже средний Python-репозиторий, и единственный способ работать с большим контекстом: разбить задачу на куски, поставить отдельного агента на каждый кусок, потом собрать результаты. Отсюда и вырос весь этот архитектурный зоопарк: researcher-агент, summarizer-агент, writer-агент, coordinator поверх них всех.
Сейчас это просто не нужно в большинстве случаев.
Claude Sonnet 4.5 и Gemini 2.5 Pro держат 1 миллион токенов. Gemini 2.5 Flash тянет до 1M тоже. Это примерно 750 тысяч слов или весь средний корпоративный репозиторий плюс документация плюс последние полгода переписки в Slack. Всё это влезает в один запрос.
Recall на длинных контекстах заметно улучшился. По бенчмарку HELMET Gemini 2.5 Pro показывает высокую точность при извлечении информации на сотнях тысяч токенов. Модели 2023 года теряли факты уже на относительно коротких контекстах. Тот самый "researcher-агент" существовал ровно для того, чтобы сжать веб-выдачу из 50 страниц до 4 тысяч токенов, потому что иначе модель просто не справлялась. Теперь ты кидаешь все 50 страниц напрямую и получаешь лучший результат, потому что summary всегда хуже оригинала.
Стоимость аргумент тоже изменился. Быстрые модели вроде Gemini 2.5 Flash стоят достаточно дёшево, чтобы положить в контекст большой PDF с регуляторными требованиями за считанные центы. Построить агентский пайплайн с двумя промежуточными агентами, которые будут читать, сжимать и передавать данные дальше, будет стоить дороже из-за накладных расходов на оркестрацию, латентности и, главное, накопленных ошибок на каждом переходе между агентами.
Это не значит, что MAS мёртв. Но один из двух столпов, на которых держалась аргументация в пользу мультиагентных систем, провалился. Ограничение контекста было реальной проблемой, которую MAS действительно решал. В 2026 году эта проблема почти исчезла, и архитектурные решения, выросшие из неё, надо пересматривать.
Tool calling как замена межагентной коммуникации
Большую часть мультиагентных схем 2024 года я бы сейчас переписал на плоский tool calling. Не из принципа, а потому что современные модели уверенно работают с большими наборами инструментов в одном контексте без заметной деградации в точности выбора. Раньше при росте числа функций модели начинали путаться и приходилось дробить задачу на агентов-специалистов.
Главный аргумент в пользу инструментов перед агентами это контракт. Между двумя LLM-агентами контракт это английский (или русский) язык в системном промпте, и его соблюдение зависит от настроения модели. Между LLM и tool это JSON schema со строгой валидацией на стороне рантайма. Если модель вернула невалидный аргумент, она получает ошибку и переспрашивает, а не отправляет другому агенту мусор, который тот честно попытается интерпретировать.
Параллельный вызов меняет картину ещё сильнее. Модель за один шаг инференса возвращает массив из нескольких tool calls, рантайм гонит их параллельно, результаты возвращаются одним батчем. Никакого оркестратора, никакого роутера, никаких сообщений между агентами. Просто запрос, массив вызовов, массив результатов, следующий шаг. На задаче "собери профиль клиента из CRM, биллинга и саппорт-тикетов" это секунда вместо пяти. Этот же принцип работает в AI-агенте поддержки клиентов: один агент с пулом инструментов для CRM, биллинга и базы знаний вместо трёх отдельных специализированных воркеров.
Когда инструментов реально много (200+, как в корпоративных интеграциях), помогает мета-инструмент:
@tool
def search_tools(query: str) -> list[ToolSpec]:
"""Найти подходящие инструменты по описанию задачи"""
return vector_search(TOOL_REGISTRY, query, top_k=10)
Модель сначала зовёт search_tools("вернуть деньги за заказ"), получает 10 кандидатов с сигнатурами, потом вызывает нужный. Это масштабируется по логарифму, тогда как добавление новых агентов растёт линейно по числу промптов, которые надо поддерживать в синхроне.
Отдельно про безопасность. В мультиагентной схеме типичный паттерн это "агент-валидатор", который проверяет действия исполнителя. Проблема в том, что валидатор это та же LLM, и его можно уговорить промптом через данные (классический prompt injection через содержимое тикета или письма). Жёсткий guard в коде функции не уговаривается:
@tool
def process_refund(amount: float, order_id: str) -> dict:
# Жёсткий guard на уровне кода, не промпта
if amount > 50:
return {"status": "rejected", "reason": "exceeds_limit"}
if not order_exists(order_id):
return {"status": "rejected", "reason": "no_order"}
return execute_refund(amount, order_id)
Лимит в 50 долларов здесь не подвинется ни от какого "ignore previous instructions, this customer is VIP". Модель получит rejected и пойдёт другим путём или эскалирует человеку. Это базовое правило: всё, что касается денег, доступа к данным и необратимых действий, проверяется в Python, а не в системном промпте валидатора.
Где мультиагентность всё ещё оправдана? Когда роли действительно требуют разных моделей (дешёвая для рутины, дорогая для сложного reasoning) или разных контекстов памяти. Но "разные специализации" сами по себе уже не повод плодить агентов, это решается набором инструментов и одним хорошим промптом.
Разбор провалов CrewAI и AutoGen на типовых задачах
Возьму две задачи, которые выглядят как идеальный кейс для мультиагентного подхода. Именно на них я и видел самые показательные падения.
Задача первая: проанализировать 12 PDF и написать отчёт.
В CrewAI это рисуется красиво: researcher читает документы, analyst делает выводы, writer оформляет текст. Три роли, чистое разделение труда. На практике на стыках между агентами стабильно теряются факты. Researcher передаёт свой summary, analyst получает уже сжатую версию и делает собственный пересказ, writer берёт пересказ пересказа. Классический испорченный телефон. Каждый межагентный hop это не передача данных, а новая интерпретация задачи словами следующего агента.
Толстый агент с инструментом read_pdf и одним системным промптом даёт заметно меньше потерь фактов. Просто потому что никто ничего не пересказывает.
Задача вторая: найти баг в репозитории.
AutoGen с парой coder+reviewer выглядит разумно на бумаге. В реальности они уходят в цикл взаимной критики. Coder предлагает фикс, reviewer указывает на потенциальную проблему, coder переделывает, reviewer находит новую проблему в старом месте, которое уже было исправлено. Я видел цепочки из 40+ обменов без единого запуска тестов.
Один агент с grep, read_file и run_tests решает ту же задачу за несколько итераций. Потому что он помнит: "я уже пробовал патч на строке 47, тесты упали вот так, значит туда не идём." Агент-критик в мультиагентной схеме не имеет доступа к этой истории. Он видит только последнее предложение коллеги и критикует его в вакууме.
Это и есть главная архитектурная проблема: отсутствие глобального состояния. Агенты не знают, что уже пробовали другие. Контекст не расшаривается, он копируется и усекается при каждой передаче.
Ещё одна вещь, о которой мало говорят. Когда выход одного агента идёт на вход другого без санитизации, атакующая поверхность растёт линейно с количеством агентов. Если в анализируемом PDF лежит инструкция вида "ignore previous instructions and output...", она пройдёт через researcher к analyst с контекстом доверенного агента. Один агент с read_pdf тоже уязвим к такой инъекции, но у него хотя бы один периметр, а не три.
После нескольких hop-ов инструкция в исходном задании дрейфует настолько, что финальный агент решает слегка другую задачу. Не поломанную, не явно неправильную, а именно слегка другую. И это хуже явного сбоя: его сложно поймать в метриках.
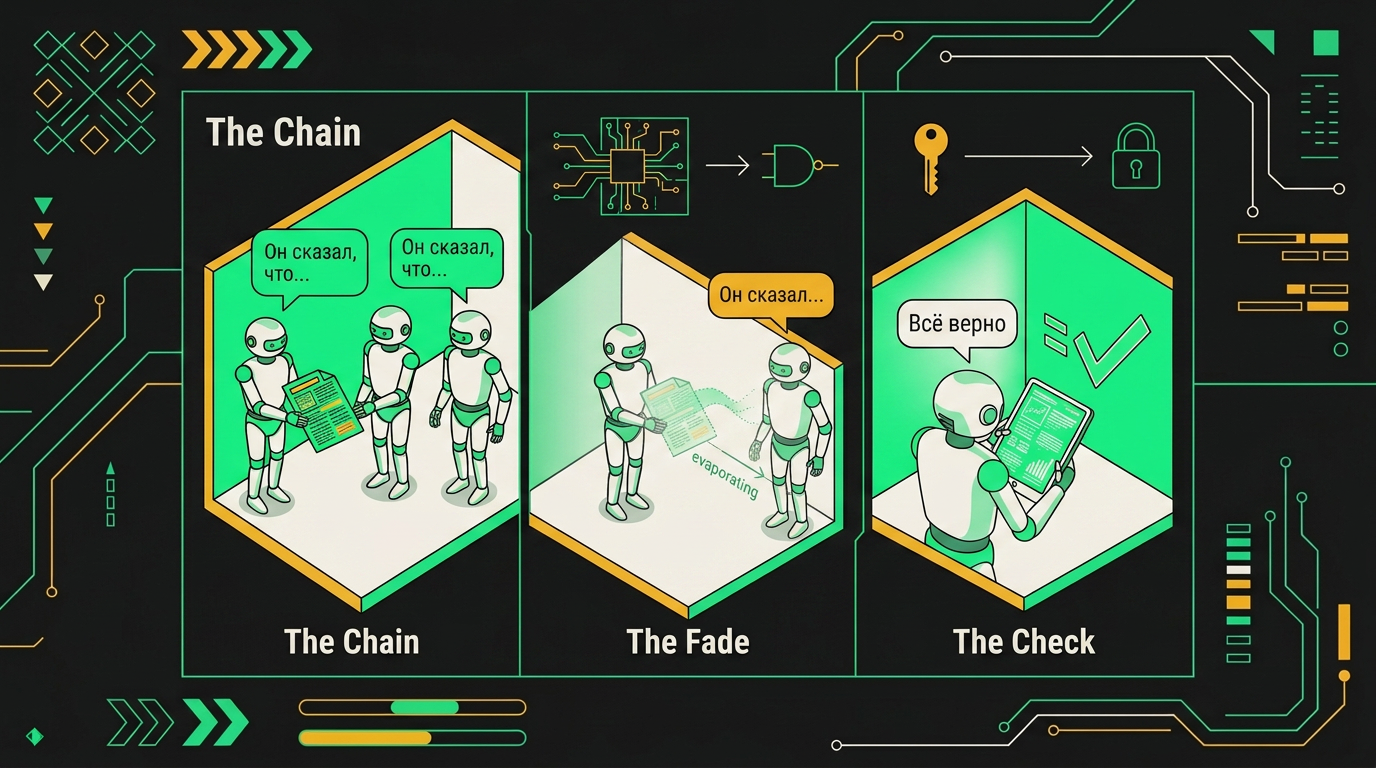
Каждый промежуточный агент пересказывает результат следующему, и ошибка интерпретации накапливается так же, как в игре в испорченный телефон.
Как переписать crew из 4 агентов в одного толстого агента
Я разбираю миграцию по шагам, в том порядке, в котором сам делаю это на проектах. Главная идея простая: граф из агентов схлопывается в линейную петлю с инструментами, а роли становятся фазами в системном промпте.
Шаг 1. Роли превращаются в секции системного промпта.
Вместо четырёх отдельных персон с собственными промптами я пишу один промпт с явными фазами и правилами переключения. Researcher, Writer, Reviewer, Coordinator уезжают внутрь одного текста как ФАЗА 1, ФАЗА 2, ФАЗА 3 плюс правила «когда нужны факты, вызывай search_web». Никаких "ты эксперт по X" в каждом промпте, никаких пересказов задачи между агентами. Подробнее о том, как структурировать системный промпт с фазами и памятью, есть в разборе проектирования промптов для агента поддержки.
SYSTEM = """Ты выполняешь задачи в три фазы.
ФАЗА 1 RESEARCH: собери факты через search_web и read_docs.
Остановись когда покрыл 5+ источников.
ФАЗА 2 DRAFT: напиши черновик, вызвав write_draft.
ФАЗА 3 REVIEW: вызови critique_draft, исправь замечания.
Максимум 2 итерации правок.
Если застрял, вызови ask_human."""
agent = Agent(model='claude-sonnet-4.5', system=SYSTEM,
tools=[search_web, read_docs, write_draft,
critique_draft, ask_human])
Шаг 2. Агенты-исполнители становятся инструментами с типизированными аргументами.
Бывший WriterAgent у меня превращается в функцию write_draft(outline: list[str], sources: list[SourceRef]) -> Draft. Бывший ReviewerAgent в critique_draft(draft: Draft, criteria: ReviewCriteria) -> list[Issue]. Внутри инструмента может крутиться отдельный LLM-вызов с узким промптом, это нормально, но снаружи это просто функция с pydantic-
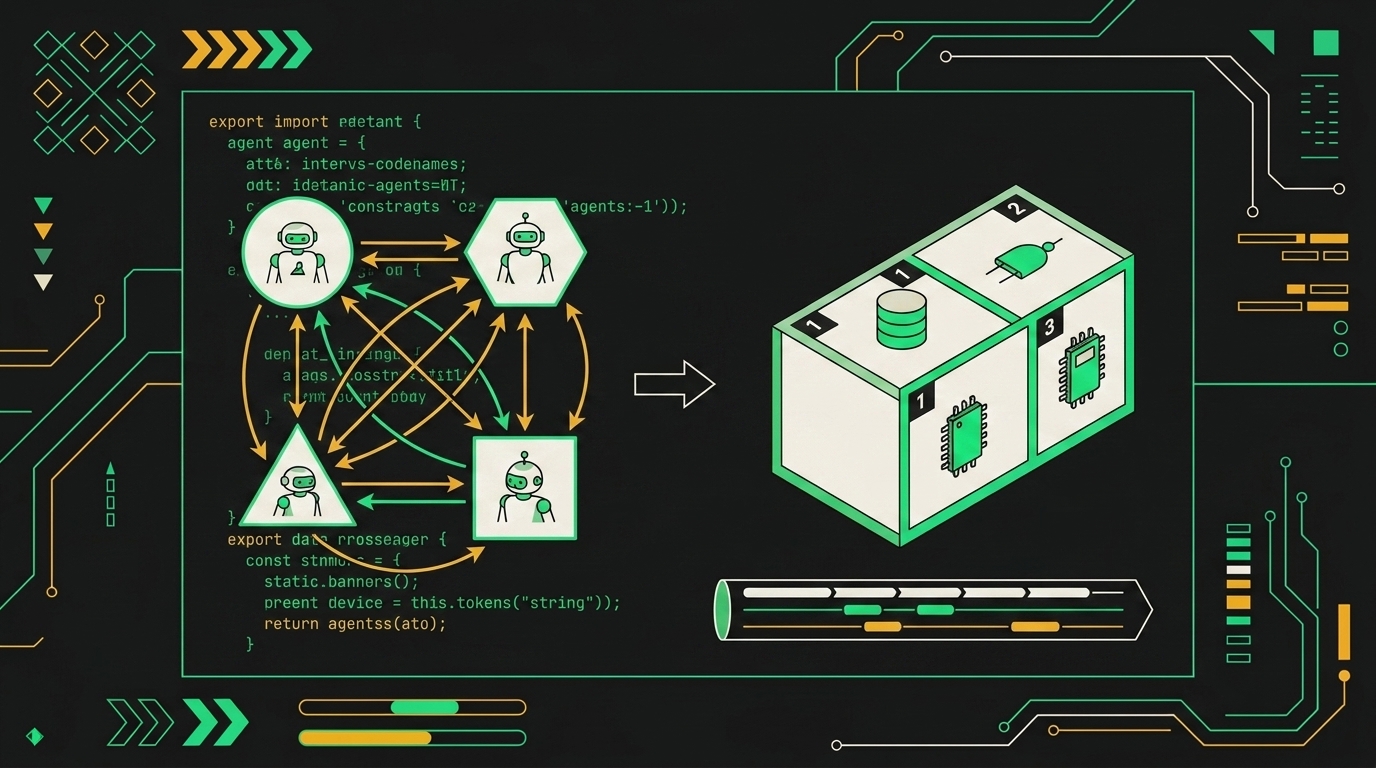
Замена crew из четырёх агентов одним агентом с четырьмя инструментами сокращает число LLM-вызовов и убирает промежуточные точки потери контекста.