Зачем вообще нужна оркестрация агентов, а не один большой промпт
Есть соблазн просто добавить ещё один инструмент в system prompt. Потом ещё один. Потом написать 200 строк инструкций, которые объясняют модели, когда вызывать какой tool. Я видел это десятки раз, и каждый раз заканчивается одинаково.
Проблема проявляется где-то после пятого-седьмого инструмента. Модель начинает путаться в выборе: вместо search_docs вызывает search_web, вместо create_ticket лезет в update_ticket. Это не баг конкретной модели, это физика: чем длиннее контекст выбора, тем хуже дискриминация между близкими по смыслу опциями. Сильные модели справляются лучше, но деградация при большом числе инструментов наблюдается практически у всех.
Конкретный пример. Агент поддержки с 30 функциями в одном промпте: поиск по базе знаний, создание тикетов, эскалация, генерация ответа, обновление CRM, отправка email... Команда провела три недели, тюня системный промпт, добавляя комментарии вроде "используй этот инструмент ТОЛЬКО если...". Точность выбора tool при этом остаётся ощутимо ниже, чем при разбивке на специализированных агентов. После разбивки на три агента (triage, который классифицирует запрос и решает, нужна ли эскалация; retrieval, который тянет контекст из базы знаний и CRM; writer, который формирует итоговый ответ) качество выбора инструментов заметно улучшается. Каждый агент при этом работает с существенно меньшим числом инструментов.
Но оркестрация не панацея, и её часто применяют там, где она только мешает.
Линейный ETL-пайплайн: забрал данные, трансформировал, положил в хранилище. Один агент справится. Задача с единственным источником данных без ветвлений по условиям: тоже один. Мультиагентная архитектура для таких случаев добавит сложность без какой-либо пользы, потому что координация стоит денег в прямом смысле.
Каждый межагентный вызов несёт дополнительную латентность плюс токены на передачу контекста. Если агент-оркестратор должен передать соседнему агенту результат предыдущего шага, этот результат нужно сериализовать, поместить в новый запрос, получить ответ. При длинных цепочках агентов накладные расходы на координацию становятся ощутимыми. Для интерактивных сценариев это критично.
Критерий перехода к мультиагентности у меня простой. Три условия, хватит одного из них:
- Задача требует разной экспертизы, и лучше описать её через отдельные роли с разными промптами.
- Разные части задачи хочется запускать на разных моделях: например, дешёвый классификатор на входе и дорогой генератор только там, где нужно.
- Есть реальный параллелизм: несколько подзадач можно выполнять одновременно, и последовательность их не связывает.
Если ни один из этих критериев не выполнен, монолит будет и быстрее, и дешевле, и проще в отладке.

Монолитный агент держит все инструменты в одном контексте, тогда как мультиагентная система распределяет ответственность между специализированными узлами.
MCP в мае 2026: что изменилось за полтора года
Anthropic выпустила MCP в ноябре 2024, и полтора года в мире AI-инструментов срок немаленький. За это время протокол успел обрасти несовместимыми форками, потом собраться обратно, пережить одну заметную CVE и превратиться из "экспериментального стандарта от одной компании" в то, что сейчас реально поддерживают Claude Desktop, Cursor, Zed, Windsurf, ChatGPT через свои коннекторы и n8n с нативной нодой.
Ревизия спецификации ноября 2025 изменила несколько важных вещей. Главное: stdio как транспорт для удалённых серверов официально уступил место streamable HTTP. Stdio остался для локальных процессов, где он и должен жить, а для всего, что работает по сети, теперь есть нормальный HTTP-стриминг с поддержкой долгих соединений. В той же ревизии добавили structured tool output (инструменты возвращают типизированные структуры) и elicitation: механизм, при котором tool в процессе работы может запросить у пользователя дополнительные данные, не прерывая весь флоу и не заставляя модель придумывать их самостоятельно.
SDK к маю 2026 покрывают Python, TypeScript, Go, C#, Java, Kotlin и Swift. Для большинства задач это уже не вопрос "есть ли биндинг для моего языка".
Теперь про неприятное. Летом 2025 раскрыли CVE в эталонной реализации SQLite-сервера из официальных примеров. Anthropic закрыла её с пометкой "won't fix", аргументировав тем, что эта реализация изначально была учебным примером небезопасной интеграции, а не production-решением. Аргумент понятный, но тысячи людей уже скопировали этот код в свои проекты. Практический вывод простой: MCP-сервер с доступом к файлам или базе данных должен жить в sandbox. Не "желательно", а по умолчанию.
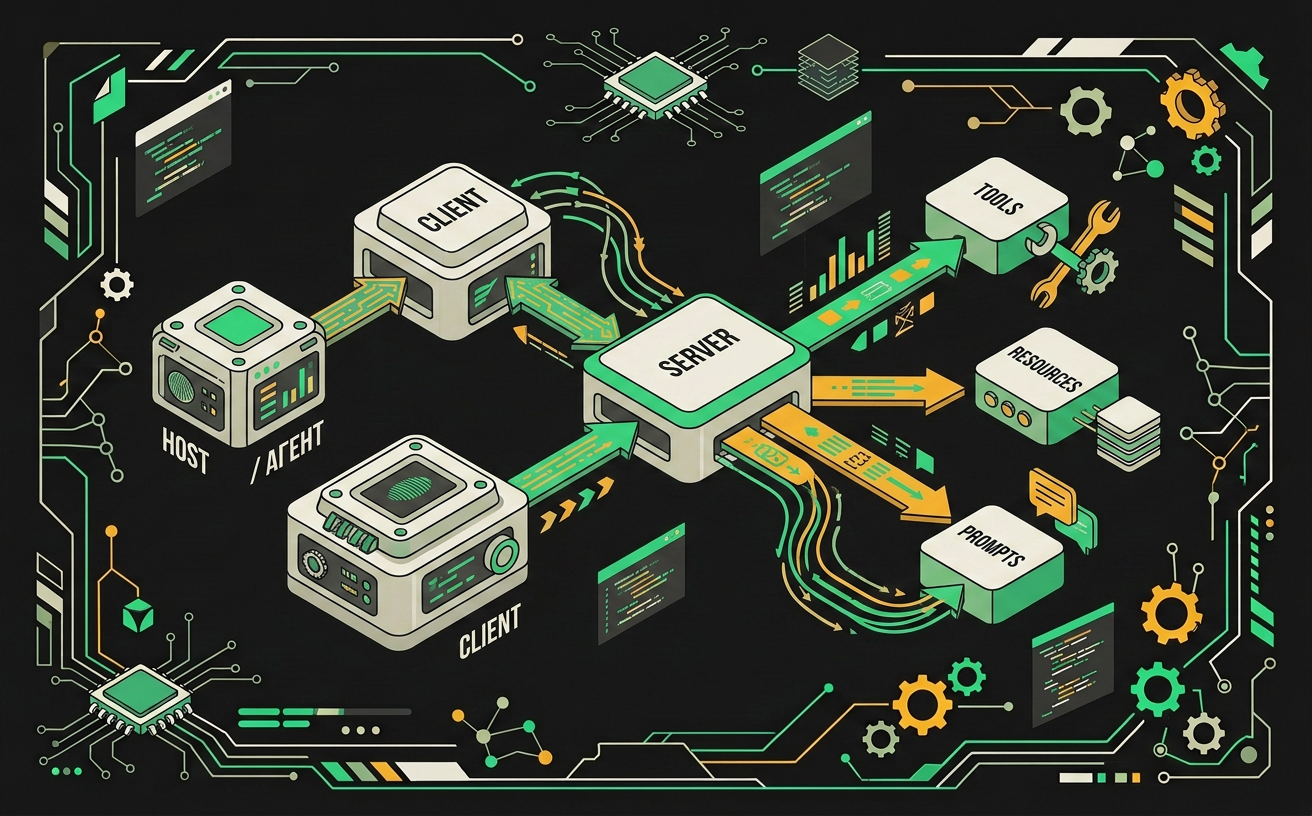
MCP-хост управляет жизненным циклом клиентов, каждый из которых держит соединение ровно с одним MCP-сервером, предоставляющим инструменты, ресурсы и подсказки.
Паттерны оркестрации: какой выбрать под задачу
Когда я проектирую мульти-агентную систему, первый вопрос не «какие агенты», а «как они связаны». Топология решает больше, чем промпты. Ниже пять рабочих паттернов и то, где каждый ломается.
Sequential pipeline. Цепочка: выход одного агента уходит на вход следующему. Классика для редакционного конвейера: ресёрчер собирает источники, драфтер пишет черновик, фактчекер сверяет цифры, редактор причёсывает. Дёшево, предсказуемо, легко логировать. Минус один: любая ошибка на третьем шаге означает прогон с первого, если нет промежуточных чекпоинтов. Я ставлю pipeline там, где порядок шагов известен заранее и не зависит от контента.
Supervisor. Координатор смотрит на запрос, режет его на подзадачи, раздаёт воркерам, потом склеивает ответы. Паттерн вытягивает кейсы с непредсказуемым составом работ: пользовательский запрос «собери мне отчёт по конкуренту X» может потребовать веб-скрейпинга, анализа финансов, разбора отзывов, или всего вместе, или ничего из этого. Supervisor решает на лету. Цена: координатор сам становится узким местом, и его промпт со временем разрастается до монстра.
Hierarchical. Supervisor над supervisor'ами. Оправдан, когда воркеров много и они естественно группируются по доменам (например, «команда данных», «команда контента», «команда коммуникаций»). Один верхнеуровневый координатор не тащит контекст на 15 агентов, поэтому делим. Если воркеров мало, иерархия только добавит латентность и токены.
Fan-out/fan-in. Параллельный запуск нескольких воркеров с одинаковой ролью, потом агрегация. Типичный кейс: сравнение цен у пяти поставщиков, опрос трёх LLM с голосованием, проверка одного факта по нескольким источникам. Время выполнения = max(воркеры), а не sum. Главное, чтобы подзадачи были по-настоящему независимыми, иначе вы платите за иллюзию параллельности.
Collaborative (network). Агенты общаются peer-to-peer, без центра. Звучит красиво в статьях, на практике пожирает токены и любит зацикливаться: A спрашивает B, B уточняет у C, C возвращается к A с новым вопросом. Я использую этот паттерн только с жёстким лимитом раундов и явным правилом выхода. Если у вас нет хорошей причины именно для peer-to-peer, не лезьте сюда.
Короткое дерево решения, которым я пользуюсь сам:
- Шаги фиксированы и порядок известен → pipeline.
- Задача распадается на независимые куски → fan-out/fan-in.
- Состав подзадач зависит от запроса → supervisor.
- Воркеров много и они группируются → hierarchical.
- Нужен реальный диалог равных без центрального арбитра → network, но с лимитами.
И ещё. Эти паттерны комбинируются. Реальная продакшн-система у меня сейчас выглядит так: верхний supervisor решает маршрут, внутри одной из веток сидит pipeline из четырёх шагов, а на этапе сбора данных раскрывается fan-out на восемь источников. Чистых топологий в живых проектах почти не бывает.
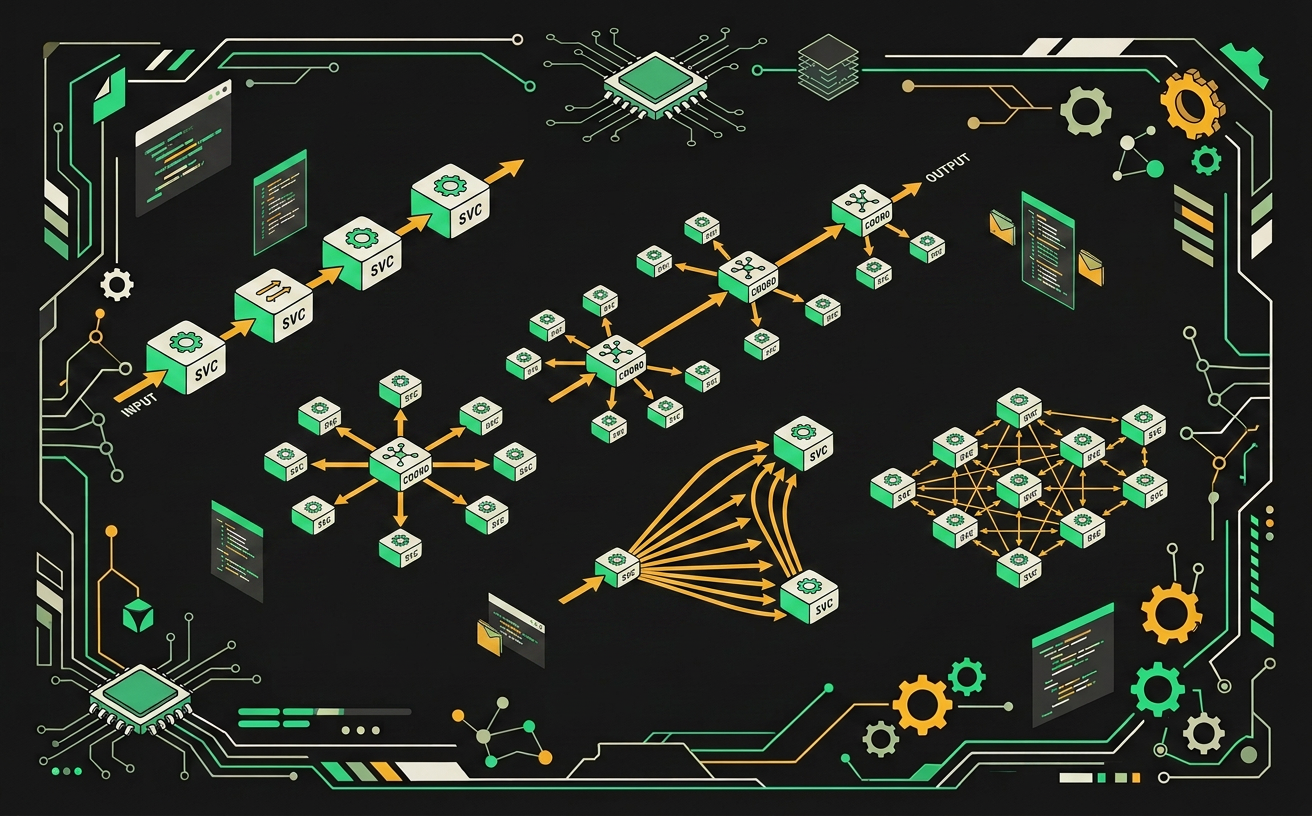
Каждый паттерн оркестрации оптимален для своего класса задач: pipeline хорош для линейных цепочек, а fan-out резко сокращает время при параллельно независимых подзадачах.
Почему именно n8n как оркестратор, а не код на LangGraph
Я пробовал оба пути. LangGraph даёт полный контроль: пишешь граф на Python, описываешь состояния, переходы, кастомную память между сессиями. Но когда в проекте пять агентов, каждый вызывает свои инструменты, а между ними надо отследить, где именно всё сломалось в 2 часа ночи, код превращается в проблему. Ты смотришь в стектрейс и гадаешь, какой именно воркер завис на третьем вызове.
n8n решает конкретную боль: визуальный граф выполнения. Когда агентный цикл отрабатывает, ты видишь каждый узел, время его работы, входящие и исходящие данные. Это не про красоту интерфейса. Это про то, что отладка мультиагентного пайплайна занимает 20 минут, а не три часа.
В 2025 году вышли MCP Client и MCP Server nodes. Теперь n8n нативно говорит по протоколу Model Context Protocol без самодельных обёрток. Плюс AI Agent node с поддержкой инструментов и памяти внутри сессии. И 500+ интеграций, которые просто работают: Slack, Postgres, S3, Salesforce. Без написания коннекторов.
Но у n8n есть честные ограничения, о которых мало пишут.
Долгие выполнения (больше 5 минут на execution) создают проблемы: таймауты, зависшие воркеры, мусор в логах. При сотнях параллельных запусков очередь начинает захлёбываться. Практическое решение, которое я видел в нескольких агентствах: n8n остаётся control plane, а тяжёлые шаги выносятся в AWS Lambda или Temporal. n8n запускает задачу, получает колбэк, идёт дальше. Сам по себе не тащит тяжёлую работу.
Self-hosted режим в корпоративных проектах обязателен. Cloud-версия n8n прогоняет executions через собственную инфраструктуру компании. Если в агенте ходят внутренние документы, данные клиентов или запросы к корпоративным API, это неприемлемо. Docker-образ разворачивается за час, и дальше ты контролируешь, куда уходят данные.
Когда я выбираю LangGraph вместо n8n: сложные state machines с десятками условных переходов, которые в визуальном редакторе превращаются в спагетти. И агенты с собственной памятью между сессиями, которая живёт в Postgres и меняется по сложной логике. Там LangGraph с кастомным checkpointer-ом удобнее, потому что вся логика состояний лежит в коде, а не размазана по нодам.
n8n выигрывает там, где нужна скорость сборки и прозрачность работы. LangGraph выигрывает там, где нужна гибкость и контроль над памятью. Это не религиозный выбор.
Архитектура референсного проекта: ассистент по тендерам
Задача звучит просто: бот должен сам ходить по площадкам госзакупок (44-ФЗ, 223-ФЗ, ЕИС), отбирать лоты по нашим ОКВЭД и пороговым параметрам, собирать чек-лист участия и отдавать черновик заявки в Telegram менеджеру. На практике это четыре разных агента, каждый со своим контекстом и инструментами.
Состав ролей:
- Scout ходит по площадкам, забирает свежие извещения, нормализует поля (НМЦК, сроки, регион, заказчик). Работает по расписанию.
- Analyst оценивает соответствие лота нашему профилю: тематика, бюджет, география, опыт по похожим контрактам.
- Legal проверяет требования к участнику: лицензии, СРО, реестр МСП, отсутствие в РНП, финансовые показатели через ФНС.
- Writer собирает черновик заявки из шаблонов и данных CRM.
Сверху сидит Supervisor. Он принимает решение, какие агенты нужны на конкретном лоте, и сшивает их выводы. Паттерн классический: supervisor + fan-out. На этапе анализа Analyst и Legal работают параллельно, потому что их выводы независимы. Если хотя бы один говорит "нет" с уверенностью выше 0.8, Writer не запускается, лот уходит в архив с пометкой причины.
Про выбор паттернов для подобных задач с непредсказуемым составом подзадач подробнее написано в разборе supervisor-архитектур для автоматизации бизнес-процессов.
MCP-серверы, к которым подключены агенты:
- ФНС API (выписки ЕГРЮЛ, проверка контрагента, бухотчётность) для Legal
- внутренняя CRM с историей клиентов и наших побед/проигрышей для Analyst и Writer
- file system с шаблонами заявок, разбитыми по типам закупок, для Writer
- Postgres с историей участий: что подавали, по какой цене, чем кончилось. Этот источник дёргают все, включая Supervisor для оценки win-rate
В n8n граф выглядит так:
Webhook (новый лот от Scout)
→ Supervisor Agent (LLM, решает маршрут)
→ Switch (44-ФЗ / 223-ФЗ / коммерческая)
→ [Analyst Agent + MCP Client] ┐
→ [Legal Agent + MCP Client] ┤ параллельно
→ Merge (waitForAll)
→ Writer Agent + MCP Client
→ Telegram (с PDF-вложением)
Switch после Supervisor нужен потому, что 223-ФЗ и коммерческие закупки требуют разных промптов и разных шаблонов, а пихать всю логику в один системный промпт получается мутно и плохо отлаживается.
Что я сознательно вынес из n8n наружу:
Парсинг PDF живёт в AWS Lambda с Textract. Тендерная документация это сканы на 80-300 страниц, иногда с таблицами цен и приложениями в виде картинок. Гонять это через ноды n8n или совать целиком в контекст LLM бессмысленно по деньгам и по латентности. Lambda забирает PDF, прогоняет через Textract, складывает результат в S3 как структурированный JSON, n8n потом просто читает нужные секции.
Векторный поиск по архиву на Qdrant. У нас порядка 4000 поданных заявок за последние шесть лет, и Writer должен уметь подтянуть формулировки из похожих успешных. Embedding строится один раз при загрузке нового документа в архив, n8n обращается к Qdrant как к обычному HTTP-эндпоинту через Code node. Внутри n8n хранить эмбеддинги я пробовал в 2024, на объёме больше пары тысяч векторов это превращается в боль.
Telegram на выходе не финальная точка, а точка апрува. Менеджер получает карточку лота, оценку соответствия с обоснованием, чек-лист документов и draft заявки в виде.docx. Дальше человек правит и нажимает "подать" уже руками, потому что цена ошибки на этапе подачи слишком высокая, чтобы доверять её агенту целиком.
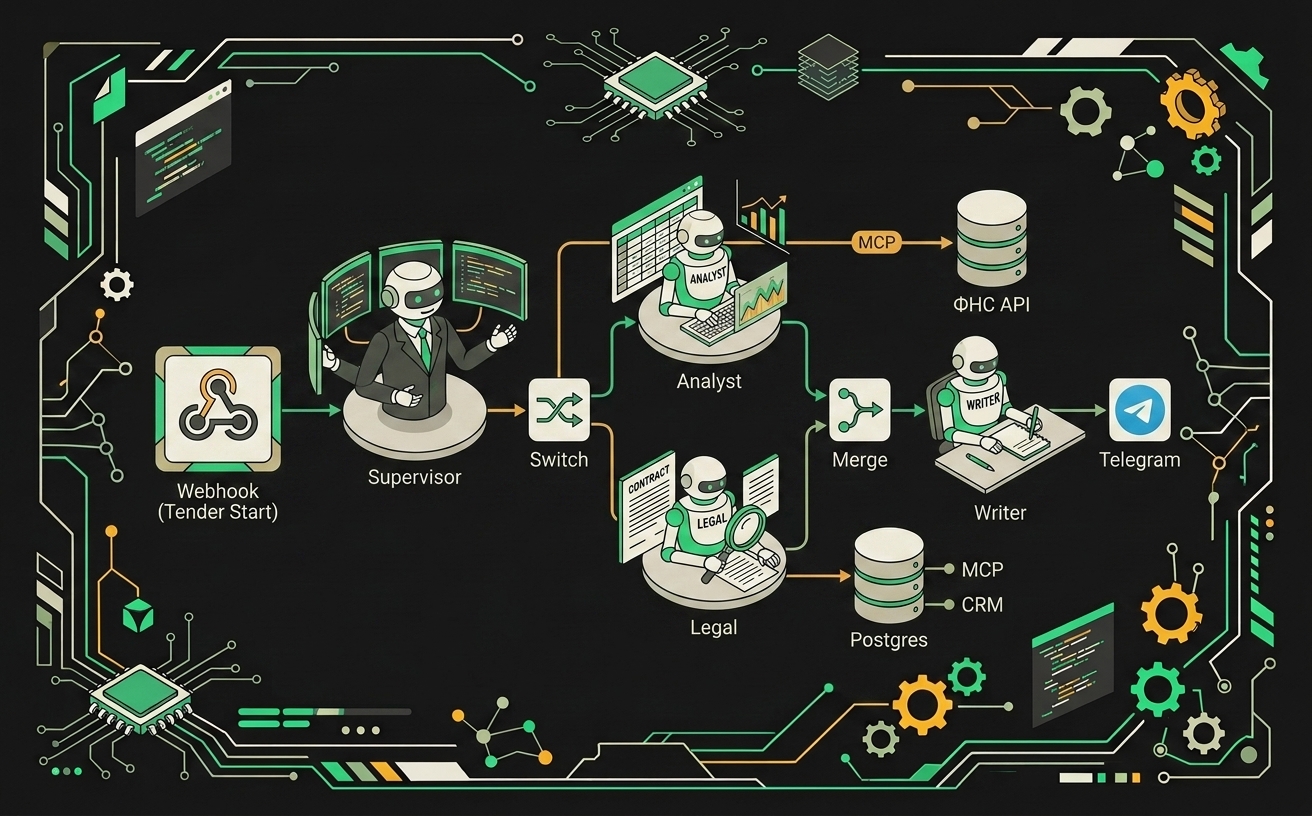
Тендерный ассистент в n8n соединяет MCP-серверы для поиска, парсинга документов и генерации ответа в единый визуальный граф без написания инфраструктурного кода вручную.
Поднимаем MCP-сервер для внутренних инструментов
Минимальный сервер, который реально пригодится в работе: два инструмента, поиск контрагента по ИНН и подтягивание истории сделок из CRM. Этого достаточно, чтобы агент в n8n начал отвечать на вопросы вроде "что у нас с ООО Ромашка за последний квартал" без ручного копания в интерфейсе.
Беру официальный TypeScript SDK. Для удалённого подключения из n8n cloud нужен Streamable HTTP transport, тот, что пришёл на смену старому HTTP+SSE в спеке марта 2025. Stdio оставляю только для локальной отладки, когда сервер запускается рядом с Claude Desktop или Inspector.
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js';
import { z } from 'zod';
const server = new Server(
{ name: 'crm-tools', version: '1.0.0' },
{ capabilities: { tools: {} } }
);
server.setRequestHandler('tools/list', async () => ({
tools: [{
name: 'find_counterparty',
description: 'Найти контрагента по ИНН в корпоративной CRM. Возвращает историю сделок и текущий статус.',
inputSchema: {
type: 'object',
properties: { inn: { type: 'string', pattern: '^\\d{10}$|^\\d{12}$' } },
required: ['inn']
}
}]
}));
server.setRequestHandler('tools/call', async (req) => {
if (req.params.name === 'find_counterparty') {
const { inn } = req.params.arguments;
const data = await crm.lookup(inn);
return { content: [{ type: 'text', text: JSON.stringify(data) }] };
}
throw new Error('Unknown tool');
});
const transport = new StreamableHTTPServerTransport({ sessionIdGenerator: () => crypto.randomUUID() });
await server.connect(transport);
Самое неочевидное в регистрации tool: модель выбирает инструмент по description, а не по name. Я первую неделю писал описания в стиле "поиск по ИНН" и удивлялся, почему агент игнорирует tool в половине случаев. Перешёл на формулировку "Найти контрагента по ИНН в корпоративной CRM. Возвращает историю сделок и текущий статус" и попадание выросло заметно. Описывайте что инструмент делает и что возвращает, как будто пишете для джуна, который выбирает между десятью похожими функциями.
inputSchema это обычный JSON Schema, и здесь имеет смысл вкладываться в валидацию. Pattern на ИНН (10 или 12 цифр) отсекает галлюцинации модели ещё до вызова CRM. Без паттерна Claude иногда подставлял ОГРН или вообще название компании строкой.
Про аутентификацию. В спеке от марта 2025 закрепили OAuth 2.1 с PKCE, и это правильное направление для публичных серверов. Но для внутреннего MCP, который живёт в корпоративной сети и обслуживает один n8n, я не вижу смысла поднимать полноценный OAuth flow. Bearer token в заголовке плюс IP allowlist на ingress закрывают 95% реальных угроз. Токен храню в секретах n8n, ротирую раз в квартал. Если сервер начнёт ходить наружу или его захотят дёргать партнёры, тогда уже OAuth.
Перед тем как втыкать сервер в агента, прогоните его через MCP Inspector. Запускается одной командой:
npx @modelcontextprotocol/inspector
Inspector показывает список tools, даёт вызвать каждый руками с произвольным входом и видеть сырой JSON-RPC. У меня раз пять было, что tool корректно регистрируется, но падает на сериализации ответа (Date в JSON, BigInt из Postgres). В Inspector это ловится за минуту, в агенте превращается в загадочные "tool returned error" без деталей.
Когда Inspector показывает зелёный список и tools отвечают как надо, можно подключать URL сервера в n8n MCP Client node и переходить к самому интересному: к тому, как агент будет эти инструменты комбинировать.
Подключаем MCP-сервер к агенту в n8n
В n8n для этого есть нода MCP Client Tool. Подключение выглядит просто: указываете endpoint своего MCP-сервера, выбираете transport (для production я везде ставлю HTTP, конкретно streamableHttp, потому что stdio годится только для локальных экспериментов), привязываете credentials. После сохранения нода сама дёргает сервер, читает манифест и подтягивает список доступных tools. Никакого ручного описания схем, как было с function calling год назад.
Дальше эту ноду подключаете к AI Agent node как ещё один tool. Для агента MCP Client неотличим от обычного HTTP Request Tool или Code Tool, он просто видит расширенный список функций с их описаниями и решает, что вызвать.
Минимальная конфигурация ноды:
{
"endpoint": "https://mcp.internal.company.ru/crm",
"transport": "streamableHttp",
"authentication": {
"type": "bearer",
"token": "={{ $credentials.mcpToken }}"
},
"toolsToInclude": ["find_counterparty", "get_deals_history"],
"timeout": 30000
}
Поле toolsToInclude тут принципиально. По умолчанию n8n тащит все tools, которые отдаёт сервер, и если на одном MCP висит 30 функций, агент начинает теряться. Лучше явно перечислять то, что нужно конкретному воркфлоу.
Пара вещей, которые мы выгребли на проде за последние месяцы.
Описания tools пишите на языке агента. Если системный промпт и пользовательские запросы на русском, а описания функций на английском (как часто бывает, когда MCP-сервер написан разработчиками "по привычке"), точность выбора tool падает. Переход описаний на русский с конкретными примерами входов заметно поднимает корректный tool selection. Эффект сильнее на более слабых моделях, на топовых выражен меньше.
Описание должно выглядеть так: не "Searches counterparty by various criteria", а "Ищет контрагента в CRM по ИНН, названию или email. Пример: ИНН='7707083893' вернёт Сбербанк с полями id, name, manager_id". Агент буквально цепляется за примеры.
Лимит tools на одного агента. На практике при большом числе функций (примерно от 15 и выше) начинается деградация: модель путает похожие tools, вызывает не то, или впадает в циклы "попробую этот, нет, попробую тот". Если функций много, делайте иерархию: один агент-роутер с несколькими крупными tools-категориями, каждая категория это вложенный sub-agent со своим набором MCP-tools. У нас так разнесено CRM (8 tools), биллинг (6), документооборот (11), и сверху роутер выбирает домен по интенту.
О том, как строить подобные иерархии роутинга для корпоративных чат-ботов в Telegram, есть отдельный разбор: маршрутизация запросов между специализированными агентами через n8n.
Логируйте каждый вызов tool в Postgres. Без этого через месяц вы не сможете ответить на вопрос "почему счёт за OpenAI вырос в три раза". Минимальный набор полей: timestamp, agent_id, tool_name, input_tokens, output_tokens, latency_ms, success (bool), error_message. Я вешаю Postgres-ноду параллельно через ветку после каждого MCP Client. На выходе получаешь таблицу, по которой за пять минут видно: какой tool жрёт токены впустую, где таймауты, какие функции агент дёргает чаще всего (и можно ли их закэшировать на стороне MCP-сервера).
Надёжность: retry, таймауты, circuit breaker
Расскажу про самые неприятные ошибки, которые я видел в продакшне. Все они связаны не с логикой агента, а с тем, как система ведёт себя при сбоях.
Начнём с retry. На MCP Client нодах я использую экспоненциальный backoff: первый повтор через 2 секунды, потом 4, 8, 16. Звучит банально, но без джиттера вы получите thundering herd. Представьте: упал MCP-сервер на 10 секунд, поднялся, а к нему одновременно прилетают 200 retry-запросов от всех аг