Зачем строить RAG-агента поверх корпоративной базы знаний
Расскажу честно, откуда растёт задача. В корпоративной среде знания нередко живут в нескольких местах одновременно: регламент в Confluence, актуальная версия того же регламента — в Google Drive, обсуждение исключений из него — в тикетах Jira, а настоящая «живая» версия — в голове Андрея, который ведёт этот процесс уже три года. Поиск по ключевым словам здесь не спасает. Он находит документ 2021 года с нужным заголовком, но не говорит, что в марте 2025-го его переписали и теперь действует другой порядок.
Именно здесь RAG решает конкретную инженерную проблему, а не абстрактную «работу с данными». Retrieval-Augmented Generation — это когда LLM отвечает не из своих весов, обученных на данных прошлого, а из фрагментов документов, которые ты сам контролируешь. Ответ приходит со ссылкой на источник: конкретный заголовок, раздел, дата обновления. Галлюцинации не исчезают полностью, но они становятся проверяемыми — модель либо опирается на чанк из базы, либо честно говорит, что не нашла. И главное: когда документ обновляется, ты переиндексируешь его в векторное хранилище — и агент уже знает новую версию. Дообучать LLM не нужно.
Почему в 2026 году связка n8n + Qdrant выглядит разумным выбором именно для корпоративного контура? Во-первых, оба инструмента разворачиваются self-hosted — данные не покидают периметр, что критично для чувствительных внутренних документов. Во-вторых, n8n сейчас имеет нативные ноды и для Qdrant, и для AI Agent — это означает, что пайплайн «получить документ → нарезать → эмбеддить → положить в Qdrant» и пайплайн «принять вопрос → найти релевантные чанки → сформировать ответ» строятся визуально, без написания инфраструктурного кода с нуля. Low-code здесь не про упрощение — это про скорость итерации: поменял промпт, поменял стратегию разбивки на чанки, переподключил источник.
Сценарии, где это работает в первую очередь:
Саппорт. Агент ищет ответ по базе прецедентов и регламентов, даёт оператору готовый черновик с источником. Время на обработку тикета падает, качество ответов выравнивается.
Внутренние регламенты и политики. HR или юрист перестаёт отвечать на вопрос «а как у нас устроен отпуск по уходу» двадцать раз в месяц. Агент автоматизации HR-процессов отвечает сам, со ссылкой на актуальный документ.
Онбординг. Новый сотрудник получает ответы на стандартные вопросы в первые две недели без необходимости дёргать коллег. База знаний при этом накапливает реальные вопросы онбординга — и со временем становится точнее.
Q&A по продуктовой документации. Команда разработки или продаж спрашивает про поведение конкретной фичи — агент поднимает нужный раздел из спецификации или changelog.
Общая логика одна: там, где человек тратит время на поиск информации, которая уже где-то существует, RAG-агент это время возвращает.

До внедрения RAG корпоративные знания разбросаны по десяткам изолированных систем, что делает их недоступными для автоматического поиска.
Архитектура решения: компоненты и потоки данных
Система строится вокруг двух независимых пайплайнов, которые намеренно не знают друг о друге. Первый — ingestion — отвечает за то, чтобы знания попали в индекс. Второй — retrieval — отвечает за то, чтобы агент нашёл нужное в момент вопроса. Разделение принципиальное: сбой индексации не роняет чат, а деградация ретривала не блокирует загрузку новых документов.
Ingestion pipeline. Источники — Confluence, Notion, Google Drive, корпоративные S3-бакеты — триггерят n8n workflow через вебхуки или по расписанию. Workflow чистит текст, режет на чанки, вызывает embeddings API (в нашем случае text-embedding-3-large), и складывает векторы в Qdrant. Исходник при этом уходит в S3-совместимое хранилище, метаданные чанка — в Postgres: source URL, timestamp, version hash, tenant ID. Redis кэширует эмбеддинги для документов, которые не изменились — при реиндексации большого корпуса это экономит несколько сотен долларов в месяц на API-колах.
Retrieval pipeline. Пользователь пишет в Slack или Teams → сообщение попадает в n8n AI Agent workflow → агент формирует запрос к Qdrant retriever → получает топ-K релевантных чанков → передаёт контекст в LLM вместе с системным промптом → возвращает ответ в чат-канал. Между Qdrant и LLM стоит простой reranker — без него precision на длинных корпусах заметно падает.
Мультитенантность без боли. Распространённая ошибка — создавать отдельную коллекцию Qdrant на каждый отдел. При двадцати департаментах это двадцать коллекций, двадцать наборов индексных параметров, двадцать точек мониторинга. Вместо этого я использую payload-партиционирование в одной коллекции: каждый вектор несёт поле tenant_id, фильтр по нему добавляется к каждому поиску автоматически на уровне retriever-ноды в n8n. Qdrant поддерживает эффективную работу с такими фильтрами через payload индексы — при правильной настройке latency практически не растёт.
Observability. Без трейсинга RAG-система — чёрный ящик: непонятно, почему агент дал плохой ответ — плохой ретривал или плохая генерация. Каждый запрос получает trace_id, который прокидывается через весь путь: от n8n workflow через Qdrant-запрос до LLM-колла. Langfuse собирает эти трейсы и показывает метрики качества ретривала — mean reciprocal rank, доля ответов с пустым контекстом, latency по перцентилям. OpenTelemetry экспортирует инфраструктурные метрики в Grafana. В апреле 2026-го это уже не опциональная надстройка — без observability невозможно объяснить бизнесу, почему система иногда галлюцинирует, и тем более невозможно это починить.
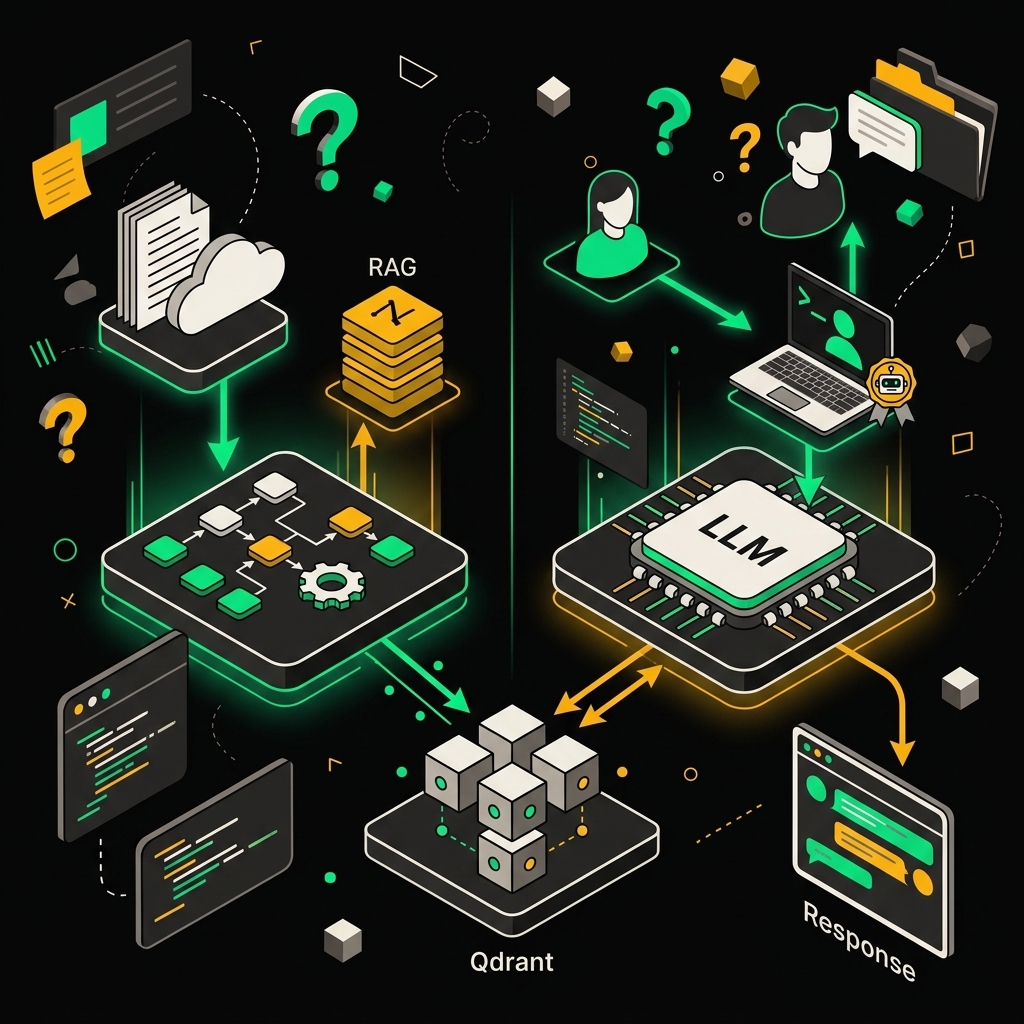
Классическая RAG-архитектура разделяет процесс на два независимых пайплайна — загрузку и индексацию данных и их последующий поиск по запросу.
Подготовка данных: чанкинг, overlap и контекстуализация
Перед тем как что-то отправлять в векторное хранилище, я обычно трачу больше времени на нарезку и обогащение, чем на сам пайплайн ретривала. Качество чанков определяет потолок качества всей системы — никакой ре-ранкер не вытащит ответ из бессмысленно порезанного абзаца.
Базовый чанкинг
Дефолт, с которого начинаю почти всегда — RecursiveCharacterTextSplitter. Он режет по иерархии разделителей (параграфы → предложения → пробелы), что для большинства документов даёт читаемые куски без обрыва на середине мысли. Параметры, которые работают в большинстве кейсов:
- размер чанка 500–1000 токенов (не символов — считайте именно токенайзером той модели эмбеддингов, которую будете использовать),
- overlap 10–20% — этого достаточно, чтобы не терять фразы на границе, и при этом не раздувать индекс вдвое.
Меньше 500 — теряется контекст, ретривал начинает возвращать обрывки. Больше 1000 — эмбеддинг «размазывается», точность семантического поиска падает, плюс упирается в лимиты cross-encoder ре-ранкеров.
Когда дефолта мало
Для длинных регламентов, договоров и любых документов с жёсткой логической структурой я переключаюсь на семантический чанкинг — режу по смысловым границам (через эмбеддинг-метрику между соседними предложениями или по структуре заголовков). Это дороже на этапе индексации, но в проде на регламентах с десятками разделов выигрыш ощутимый.
Таблицы — отдельная боль. Их нельзя резать построчно вместе с окружающим текстом: теряются заголовки колонок. Я храню таблицу как один чанк (если влезает) или сериализую построчно с обязательным дублированием шапки в каждой строке. Для широких таблиц — markdown или JSON, эмбеддингам это нормально заходит.
Код требует своей стратегии: бить по AST (функциям, классам), а не по символам. Иначе получите половину функции в одном чанке и её сигнатуру в другом — с точки зрения поиска это мусор.
Contextual Retrieval
Самое сильное улучшение, которое я внедрял за последний год — подход Anthropic с контекстуализацией чанков. Идея простая: перед эмбеддингом прогоняешь каждый чанк через дешёвую LLM с промптом «опиши в одном-двух предложениях, о чём этот фрагмент в контексте всего документа». Это короткое описание дописываешь в начало чанка — и уже эту склейку эмбеддишь и индексируешь.
На практике прирост точности ретривала заметен на документах с HR-тематикой и техдоках. Стоимость индексации растёт, но с prompt caching это копейки: документ грузится в кэш один раз, а контекст для каждого чанка генерируется почти бесплатно.
// Пример чанка с контекстом перед embedding
{
"text": "[Контекст: документ о политике отпусков, раздел 'Перенос дней'] Сотрудник может перенести до 7 дней на следующий год при согласовании с руководителем...",
"metadata": {
"doc_id": "hr-policy-2026",
"section": "vacation-transfer",
"updated_at": "2026-03-15",
"acl": ["all-employees"]
}
}
Обратите внимание: контекст идёт в поле text (то, что эмбеддится), а не в метаданные. Это принципиально — мы хотим, чтобы вектор «знал», к какому документу и разделу относится фрагмент.
Метаданные и фильтрация
Метаданные — это то, что превращает векторный поиск из «угадайки по смыслу» в управляемую систему. Минимальный набор, который я всегда тащу:
doc_id,section— для трассировки и дедупа,updated_at— для буста свежих документов и фильтрации устаревших,author,department,doc_type— для фасетной фильтрации,acl— список ролей или групп, имеющих доступ. Без этого поля в корпоративном RAG жить нельзя: иначе бухгалтерия найдёт черновики совета директоров.
Фильтрация по метаданным делается до векторного поиска (pre-filter) — это и быстрее, и безопаснее, чем фильтровать топ-K постфактум.
Гигиена данных
Перед индексацией прогоняю всё через два обязательных шага:
- Дедупликация по хэшу содержимого (sha256 от нормализованного текста). В корпоративных хранилищах один и тот же регламент часто лежит в трёх местах в разных версиях — без дедупа ретривал будет возвращать один и тот же ответ трижды и забивать контекстное окно.
- Нормализация: даты к ISO 8601, телефоны к E.164, нижний регистр для ключей метаданных, прибивание невидимых символов (NBSP, zero-width). На эмбеддингах это влияет слабо, но критично для гибридного поиска с BM25 и для точных фильтров.
Один раз потратив день на нормализатор, экономишь недели на разборках «почему поиск не находит документ, который точно есть».

Правильный чанкинг с перекрытием фрагментов и контекстуализацией каждого чанка критически влияет на точность последующего семантического поиска.
Настройка коллекции Qdrant: vectors, payload и индексы
Перед тем как лить данные, я всегда фиксирую три вещи: размерность, метрику и стратегию multitenancy. Менять их потом — значит пересоздавать коллекцию.
Размерность под модель эмбеддингов. Тут жёсткая привязка: 1536 для text-embedding-3-small, 1024 для bge-m3, 3072 для text-embedding-3-large. Если планируете Matryoshka-усечение у OpenAI — заранее решите, на какой размерности будете жить, и пишите её в size. Метрика для текста — почти всегда Cosine; Dot имеет смысл, только если вы сами гарантируете нормализацию.
HNSW и multitenancy. Дефолтные m=16, ef_construct=128 — рабочий компромисс по скорости индексации и recall. Но если в одной коллекции живут десятки/сотни тенантов (group_id, workspace_id и т.п.), глобальный HNSW-граф вреден: запросы одного тенанта тащат за собой связи через всю коллекцию. Решение — отключить глобальный граф (m=0) и строить HNSW локально внутри payload-партиции через payload_m. На запросе достаточно фильтра по group_id, и Qdrant пойдёт по локальному подграфу.
Payload-индексы. Без них фильтры превращаются в полный скан. Минимальный набор для базы знаний:
group_id—keyword, обязательно сis_tenant: trueпри multitenancy;updated_at—datetime, для инкрементальных пересборок и временных срезов;acl—keyword(массив ролей/юзеров), для пост-фильтрации доступа;doc_type—keyword, чтобы можно было ограничивать поиск по типу источника.
Гибридный поиск. Один dense-вектор на топиках с редкой терминологией (артикулы, коды ошибок, юридические формулировки) проигрывает. Я держу named vectors: dense для семантики и sparse_vectors.bm25 для лексики, а на стороне приложения склеиваю через RRF или Reciprocal Fusion из встроенного query_points с prefetch.
Квантизация. До ~1М векторов можно жить без неё. Дальше включаю scalar int8 с always_ram: true — это сжатие в 4 раза при минимальной потере recall и оригиналы остаются на диске для re-scoring. Для 10М+ и жёстких бюджетов по RAM — binary (32×), но только если эмбеддинги к этому пригодны (OpenAI и Cohere — да, мелкие open-source модели часто проседают, проверяйте на своём eval-сете).
PUT /collections/kb_main
{
"vectors": {
"dense": { "size": 1024, "distance": "Cosine" }
},
"sparse_vectors": { "bm25": {} },
"hnsw_config": { "m": 0, "payload_m": 16 },
"quantization_config": {
"scalar": { "type": "int8", "always_ram": true }
}
}
После создания коллекции отдельными запросами накатываю payload-индексы:
PUT /collections/kb_main/index
{ "field_name": "group_id", "field_schema": { "type": "keyword", "is_tenant": true } }
PUT /collections/kb_main/index
{ "field_name": "updated_at", "field_schema": "datetime" }
PUT /collections/kb_main/index
{ "field_name": "acl", "field_schema": "keyword" }
PUT /collections/kb_main/index
{ "field_name": "doc_type", "field_schema": "keyword" }
Что я проверяю сразу после: /collections/kb_main показывает payload_schema со всеми четырьмя полями, config.hnsw_config.m = 0, и при первом query_points с фильтром по group_id латентность не растёт линейно от общего объёма коллекции. Если растёт — значит is_tenant не подхватился, и надо пересоздавать индекс по полю.
Ingestion-воркфлоу в n8n: от источника до векторов
Я строю ingestion как несколько мелких воркфлоу вместо одного монстра. Так проще дебажить, и Error Trigger ловит сбои гранулярно.
Триггеры
Три точки входа на каждый источник:
- Schedule — раз в час по Confluence и Notion. Этого хватает: документация редко обновляется чаще, а API-лимиты у Notion жёсткие, особенно после изменений политики этой весной.
- Webhook — для событий
page.updatedиpage.deleted. Confluence шлёт через автоматизации, Notion через сторонний релей (нативных вебхуков по-прежнему нет). Это даёт near-real-time на критичных пространствах. - Manual — кнопка для бэкфилла и переиндексации после смены модели эмбеддингов. Принимает параметры
space_id,since,force_recompute.
Основная цепочка нод
Source Connector → Cleaner → Splitter → Contextualizer → Embeddings → Qdrant Upsert
- Source Connector. HTTP Request с пагинацией через
Loop Over Items. Тяну только то, у чегоupdated_at > last_run_at(хранится в Postgres-таблицеingestion_state). - HTML/Markdown Cleaner. Code-нода: вырезаю навигацию, футеры Confluence, разворачиваю таблицы в Markdown, нормализую заголовки. Сохраняю исходный URL и breadcrumbs в метаданных.
- Text Splitter. Recursive по структуре заголовков, окно 800 токенов, overlap 120. Split по смысловым границам, а не по символам — экономит контекст на этапе ретривала.
- Contextualizer. LLM-нода генерирует короткий контекст-хедер для каждого чанка: «о чём документ, где этот фрагмент находится». Приклеиваю к чанку перед эмбеддингом — техника contextual retrieval, заметно улучшает recall на практике.
- Embeddings. Батч по 96 чанков за вызов.
- Qdrant Upsert. См. ниже.
Идемпотентность
point_id = sha1(doc_id + ":" + chunk_index) — детерминированный, влезает в формат UUID после преобразования. Всегда upsert, никогда insert. Это значит, что повторный прогон того же документа не плодит дубликатов и не требует предварительной очистки.
Инкрементальное обновление
Логика на каждый документ:
- Считаю новые чанки и их
point_id. - Делаю
scrollпо Qdrant с фильтромdoc_id == X, собираю существующиеpoint_id. - Upsert нового набора.
- Удаляю разницу:
deleteпо фильтруdoc_id == X AND point_id NOT IN (новый_набор).
Если updated_at не изменился относительно ingestion_state — пропускаю документ целиком, даже не дёргая эмбеддинги. На прогоне в 40k страниц это срезает время с часов до минут.
Обработка ошибок
Отдельный воркфлоу с Error Trigger, привязанный ко всем ingestion-флоу. Внутри:
- Классификатор ошибки:
rate_limit,auth,parse,embedding_api,qdrant. - Ретраи с экспоненциальной задержкой. После нескольких попыток — dead-letter.
- Dead-letter в Postgres: таблица
ingestion_dlqс payload, ошибкой, traceback иretry_after. Отдельный Schedule-воркфлоу раз в шесть часов перепрогоняет записи, у которыхretry_after < now(). - Алёрт в Slack при росте DLQ сверх настроенного порога — иначе шум.
Батчинг
Qdrant upsert принимает 64–256 точек за раз. Меньше — упирается в RTT, больше — растёт p99 на стороне Qdrant и риск таймаута gRPC. Я держу 128 как дефолт, для крупных бэкфиллов поднимаю до 256 и переключаюсь на gRPC вместо HTTP — на миллионе точек разница ощутимая, часы против десятков минут.
Один нюанс n8n: Split In Batches по умолчанию держит весь массив в памяти. На больших источниках разбиваю на под-воркфлоу через Execute Workflow с передачей курсора — иначе воркер ловит OOM где-то на 200k items.
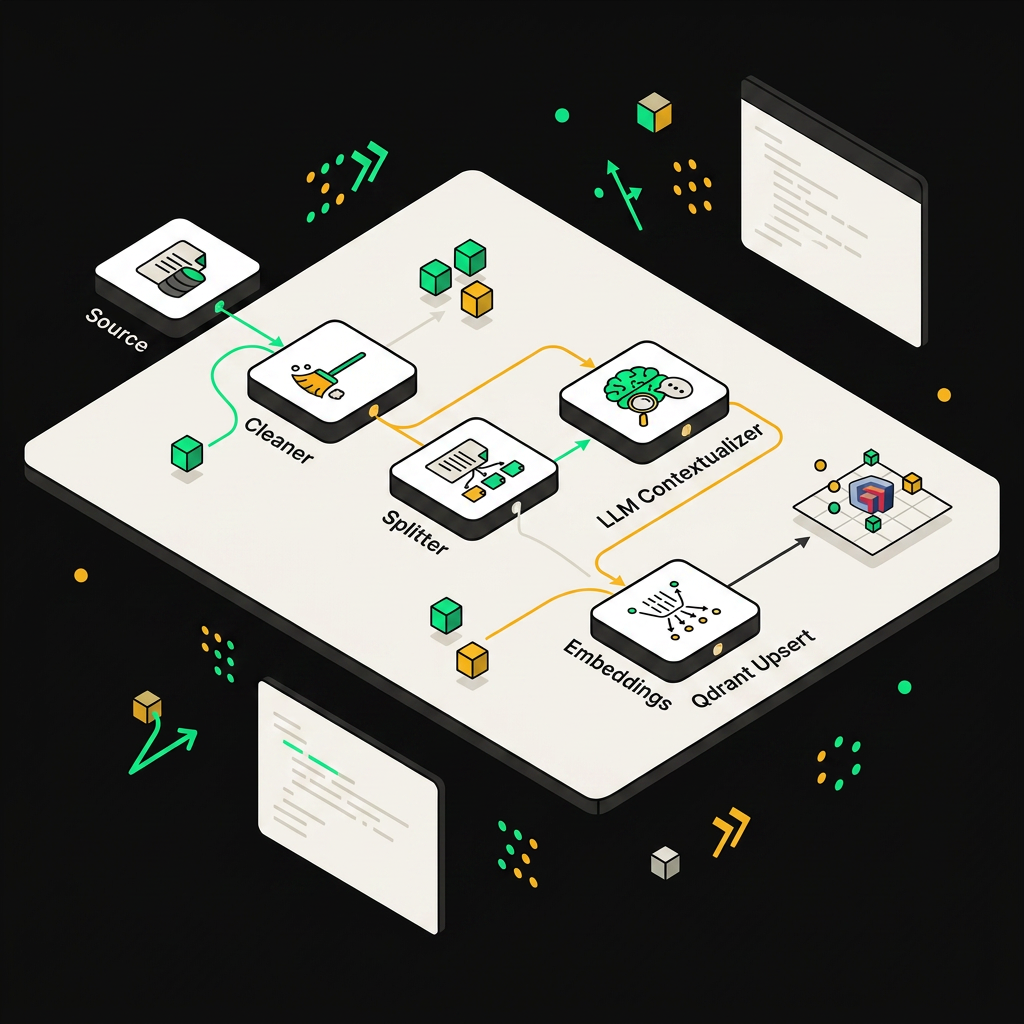
Автоматизированный ingestion-пайплайн в n8n обрабатывает документ за несколько узлов — от загрузки и чанкинга до эмбеддинга и записи в Qdrant.
AI Agent в n8n: tools, retriever и промпт
Ядром всей оркестрации у меня выступает нода AI Agent в режиме Tools Agent — она единственная держит цикл «think → call tool → observe» и решает, лезть ли в базу знаний или сразу отвечать. К ней я подключаю четыре инструмента, и каждый делает ровно одно:
kb_search— Qdrant Vector Store как retriever tool. Сюда уходят все фактологические вопросы о продукте, документации, регламентах.ticket_lookup— HTTP Request Tool в нашу тикет-систему поcustomer_idи статусу. Полезно, когда пользователь спрашивает «а что с моим обращением».calendar_lookup— Google Calendar tool, читает свободные слоты CSM. Используется только если агент уже идентифицировал намерение записаться.escalate_to_human— Slack-нода, постит в канал поддержки тред с историей диалога и причиной эскалации. Это терминальный tool: после его вызова агент завершает ответ фразой ожидания.
Архитектура инструментов n8n-агента с маршрутизацией между tools — отдельная тема, но здесь важно: каждый tool изолирован, и агент сам решает, какой из них вызвать на основе системного промпта и контекста диалога.
Memory — Postgres Chat Memory с настраиваемым окном истории. Postgres, а не Redis, потому что мне нужна история на разборы инцидентов и для дообучения промптов — TTL выставляю на стороне БД.
Системный промпт
Промпт держу коротким и жёстким, без ролевых игр:
Ты — ассистент поддержки Acme. Отвечай только на основе результатов tool `kb_search`
или данных из других tools. Если уверенность низкая или источников нет — честно
скажи «не знаю» и предложи `escalate_to_human`.
Формат ответа:
1. Краткий ответ (2–4 предложения).
2. Блок «Источники:» — список ссылок из metadata.url найденных чанков.
Запрещено: выдумывать номера тикетов, цены, SLA, даты релизов.
При вопросах вне scope (юридические, медицинские, конкуренты) — отказ.
Ключевое — пункт про источники. Без него модель регулярно «забывает» приклеить ссылки, даже если retriever их вернул в payload.
Гибридный поиск и реранкинг
Чистый dense у меня давал плохие результаты на запросах с кодами ошибок и артикулами — там, где важен точный токен. Поэтому retriever ходит в Qdrant Query API с гибридом: dense + sparse (BM25), фьюжн через RRF, top_k=20, потом реранкер срезает до 5. Я остановился на bge-reranker-v2-m3 на собственном GPU; Cohere Rerank 3.5 даёт чуть лучшее качество на русском, но платный трафик растёт быстрее, чем мне хочется.
ACL — на этапе запроса, через payload filter. Никаких пост-фильтраций после ретрива: иначе top_k плывёт и реранкер получает мусор.
// Qdrant query с фильтром доступа и гибридом
{
"prefetch": [
{ "query": [...], "using": "dense", "limit": 20 },
{ "query": {...}, "using": "bm25", "limit": 20 }
],
"query": { "fusion": "rrf" },
"filter": {
"must": [
{ "key": "acl", "match": { "any": ["user-123", "team-sales"] } },
{ "key": "group_id", "match": { "value": "acme-corp" } }
]
},
"limit": 5
}
acl я пишу в payload при индексации как массив идентификаторов, у которых есть

AI Agent orchestrates несколько инструментов одновременно, динамически выбирая между векторным поиском и другими tools в зависимости от запроса.