Кейс: B2B SaaS, входящий поток лидов, SDR не справлялись
Компания продаёт корпоративный софт с относительно высоким средним чеком. Лиды идут через сайт, вебинары, платный трафик. Небольшая команда SDR, казалось бы, должна была справляться.
Не справлялась.
При большом входящем потоке лидов SDR тратили значительное время на обработку каждого контакта: квалификация вручную, поиск компании в открытых источниках, первое письмо или звонок. Существенная часть этого времени уходила на лиды, которые никогда не становились SQL. Люди, которые скачали white paper из любопытства, конкуренты, студенты, компании с оборотом ниже порога. Всё это SDR разгребали руками.
SLA на первый контакт формально существовал. По факту лиды, пришедшие после 16:00 или в пятницу, ждали до понедельника. Корреляция между скоростью первого контакта и конверсией в B2B SaaS известна: быстрый ответ на входящий запрос стабильно показывает лучшую конверсию, чем ответ с задержкой в несколько часов.
Конверсия из MQL в SQL была типичной для компаний с похожим профилем. При этом на следующий этап воронки проходила относительно небольшая доля SQL. Воронка текла не снизу, а посередине.
Цель была конкретная: первый контакт за 2 минуты в любое время суток, рост SQL-конверсии минимум на 15 процентных пунктов. Без найма новых SDR. Под проект выделили бюджет на разработку и интеграцию плюс ежемесячные расходы на API и инфраструктуру.
Здесь нет истории про "заменили людей роботом". SDR остались. Их переориентировали на лиды, которые уже прошли первичную квалификацию. Голосовой AI-агент забирал входящий лид из CRM сразу после заявки, проводил короткий разговор по BANT-сценарию (бюджет, полномочия, потребность, сроки), записывал результат структурированно и передавал дальше. Либо закрывал лид как нецелевой с аргументацией.
Первые 6 недель выявили неожиданный эффект: часть лидов, которых SDR интуитивно пропускали как "слабых", агент квалифицировал иначе. Не потому что агент умнее. Просто он задавал одни и те же вопросы каждый раз, без усталости в 17:30 и без предвзятости к названию компании.

Когда лидов больше, чем SDR успевает обработать, первыми страдают скорость ответа и качество квалификации.
Что делает AI-агент в воронке: разграничение зон ответственности
Самая частая ошибка при внедрении агента в продажи: пытаться закрыть им всё. Я видел команды, которые ставили задачу "пусть ведёт до сделки" и через три месяца откатывались, потому что конверсия рухнула. Агент хорош ровно там, где он хорош, и бесполезен там, где нужен человек.
Конкретно агент закрывает четыре задачи. Первая: обогащение данных. Лид пришёл с именем и email, агент в течение нескольких секунд тянет из открытых источников размер компании, индустрию, стек технологий, LinkedIn-должность контакта. Вторая: скоринг по заданным критериям. Третья: первичный диалог, то есть квалификационные вопросы в чате или по email, максимум две итерации. Четвёртая: маршрутизация. Агент пишет в CRM карточку с тегами и передаёт лид нужному SDR или сразу в AE, если лид уже SQL.
Всё остальное агент не делает. Не ведёт переговоры о цене. Не отправляет КП, потому что КП это уже персонализированный документ под конкретную боль, и писать его должен человек, который слышал клиента. Не работает с возражениями глубже двух итераций: если клиент задал третий уточняющий вопрос, это сигнал, что ему нужен живой разговор.
Триггеры эскалации у нас жёсткие. Крупный бюджет: агент не торгуется, сразу пинг менеджеру. Упоминание конкурента: "мы сейчас смотрим ещё на X" требует живой реакции, агент тут облажается с высокой вероятностью. Три и больше уточняющих вопроса от лида подряд: человек думает, он тёплый, не надо его охлаждать ботом.
Разделение MQL и SQL идёт по семи признакам: размер компании, должность контакта, индустрия, наличие явного intent (запрос демо, скачивание прайса), бюджет, сроки принятия решения, наличие текущего решения у клиента. Последний пункт недооценивают. Компания без текущего решения и компания, которая хочет уйти от конкурента, это разные воронки с разными циклами сделки и разными болями.
Цель агента не заменить SDR. Цель отсечь значительную часть лидов, которые SDR сам бы квалифицировал вручную и тратил бы на каждого по 15-20 минут. Агент делает это за 2 минуты. SDR получает список, где уже нет студентов, фрилансеров, компаний с командой меньше 10 человек и людей без бюджета. И может сфокусироваться на тех, с кем есть смысл говорить.
Граница между автоматикой и человеком проходит там, где заканчивается шаблонный сценарий и начинается нестандартный запрос клиента.
Архитектура решения: n8n + GPT-4o + Clearbit + HubSpot
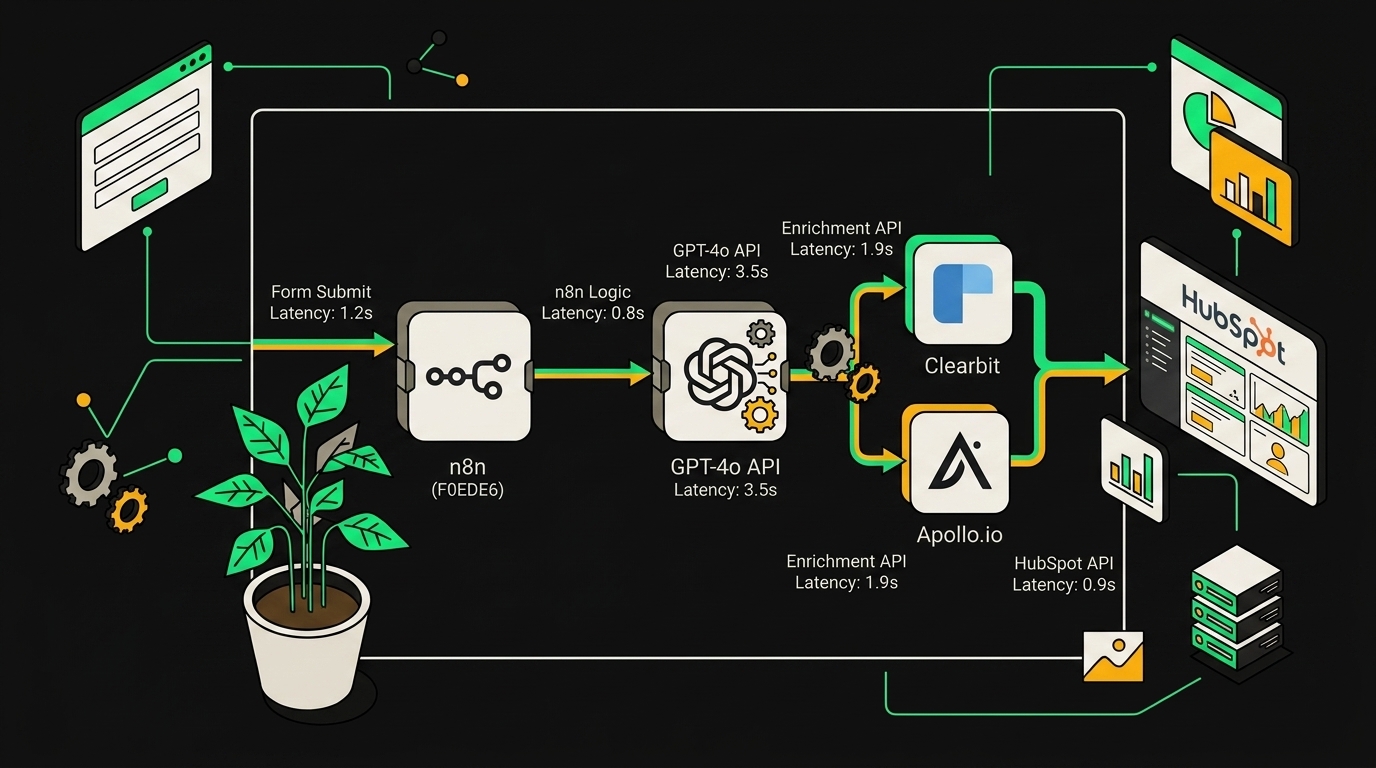
Оркестратор крутится на n8n self-hosted, в Docker на VPS. Self-hosted я выбрал не из идеологии, а потому что cloud-версия n8n начинает ощутимо дорожать при большом объёме executions, а у меня их много.
LLM-слой разделён на два контура. GPT-4o отвечает за диалог с лидом и финальную классификацию намерения (купить сейчас / прогреть / мусор / партнёрский запрос). Всю чёрную работу, парсинг JSON из ответа Clearbit, нормализацию должностей, извлечение домена из email, делает GPT-4o-mini. На реальных логах экономия по токенам вышла примерно в 8 раз против варианта "всё на 4o".
Обогащение собирается из трёх источников параллельно, через Split In Batches и Merge:
- Clearbit Enrichment API дёргает компанию по домену (industry, employees, tech stack, funding, geo).
- Apollo используется точечно для контактов уровня decision-maker, когда из формы пришёл personal email вроде gmail.
- Внутренний скоринг крутится в PostgreSQL: матчу домен и индустрию против таблицы closed-won сделок, отдаю similarity score от 0 до 1.
Память агента живёт в Redis с TTL 30 дней. Полная история отдельно пишется в Postgres, без TTL, для аудита и для будущего файнтюна. Разделение нужно потому, что Redis я не хочу раздувать, а compliance-команда требует хранить переписку минимум год.
CRM-интеграция идёт через нативный HubSpot Node. Записываю в три кастомных поля: ai_lead_score (int 0-100), ai_segment (enum из 6 значений) и ai_next_action (строка с конкретным предложением для сейлза, например "позвонить в течение 2 часов, упомянуть кейс Acme"). Никаких отдельных Zapier-прослоек, всё в одном workflow.
End-to-end latency от сабмита формы до ответа в чате держится в пределах нескольких секунд. Бутылочное горлышко это не LLM, а Clearbit, который на холодных доменах может существенно замедляться. Поэтому первый ответ боту я отдаю сразу после классификации намерения, а обогащённый контекст подмешиваю уже во второе сообщение.
Три компонента связаны последовательно: n8n забирает событие, GPT-4 оценивает текст, HubSpot получает готовый скор и тег.
Скоринг лидов: как агент принимает решение
Я не доверяю LLM решать всё с нуля. Поэтому скоринг устроен в два этажа: сначала правила, потом модель.
Первый этаж отрезает мусор за миллисекунды. Чёрный список доменов (gmail, mail.ru, временные ящики), компании меньше 20 FTE если ICP начинается от 100, страны вне географии продаж, дубли по email-хешу за последние 90 дней. Это обычный JS-узел в n8n с парой regex и запросом в Postgres. Сюда не лезет никакая модель, потому что незачем платить за токены, чтобы понять, что лид с домена test123.ru нерелевантен.
Второй этаж уже LLM. Промпт собран из трёх блоков. Описание ICP на 400 слов, написанное вручную головой продаж, не сгенерированное (в этом весь смысл). Пять примеров hot-лидов с разбором, почему именно hot. Пять cold с разбором, почему мимо. Без примеров модель плывёт и завышает оценки: на практике few-shot существенно влияет на калибровку скора и помогает совместить его с ручной разметкой РОПа.
Выход строго через function calling, никакого свободного текста. Ответ парсится Zod-схемой прямо в n8n, если структура битая, узел падает в retry, после трёх попыток уходит в очередь на ручной разбор. Из наблюдений: схема игнорируется реже всего, риск растёт на длинных контекстах.
{
"score": 78,
"tier": "B",
"reasoning": "Компания 200+ FTE, должность Head of Ops, явный intent на замену текущего решения. Бюджет не подтверждён.",
"icp_match": {"size": true, "industry": true, "role": true, "budget": null},
"next_step": "book_demo",
"escalate_to_human": false
}
Поля жёсткие. score от 0 до 100, tier маппится из score диапазонами (A: 85+, B: 65-84, C: 40-64, D: ниже). reasoning ровно три предложения, в промпте это прописано прямо: "exactly three sentences, no more". Если модель пишет два или четыре, валидация бьёт. icp_match с явным null для неизвестного, я запретил булеву ложь там, где данных нет, иначе агент начинает выдумывать бюджет по косвенным признакам. next_step из закрытого списка: book_demo, nurture_sequence, enrich_data, disqualify. escalate_to_human поднимается, когда score в пограничной зоне и budget null: такие лиды стоят дороже всего и я не хочу, чтобы агент решал в одиночку.
Калибровка раз в две недели. Беру все лиды, по которым закрылась сделка или пришёл явный отказ, и сверяю с тем, что предсказал агент. Если A-tier конвертится хуже порогового значения, копаю промпт. В марте обнаружил, что модель переоценивала лидов из ритейла из-за перекоса в few-shot примерах. Поменял баланс примеров, точность по A-tier заметно выросла за месяц.
Веса правил тоже двигаются, но медленнее. Размер компании, индустрия, должность идут с разными коэффициентами, которые считаются через простой логрег на исторических сделках. Не ML ради ML, просто sklearn в Python-узле, который раз в две недели пересчитывает числа и кладёт их в таблицу настроек.
Первый этап отсекает заведомо нерелевантные лиды по жёстким критериям, второй этап дочитывает то, что не укладывается в поля формы.
Промпт-инжиниринг для диалогового SDR
Системный промпт у меня разбит на шесть блоков, и порядок не случайный: роль, ICP, продуктовое позиционирование, запрещённые темы, формат ответа, примеры. Модель читает сверху вниз, и то, что выше, весит больше. Поэтому роль и ICP идут первыми, а примеры в конце как калибровка стиля.
Костяк выглядит примерно так:
ROLE: SDR-агент компании X, продукт Y.
ICP: B2B SaaS, 50-1000 FTE, СНГ и EU.
ЗАДАЧА: за 4 сообщения собрать: размер команды,
текущее решение, сроки выбора, бюджетный диапазон.
ЗАПРЕЩЕНО: называть цену, обещать скидки,
обсуждать дорожную карту.
ФОРМАТ: 1-3 предложения, один вопрос за раз.
ЕСЛИ лид спрашивает цену → ответ: передам менеджеру,
он пришлёт расчёт под ваш кейс.
Пять строк, которые закрывают 80% поведения. Остальное докручивается few-shot блоком.
Few-shot держу на восьми диалогах. Горячий лид с явным intent, холодный с уклончивыми ответами, лид от прямого конкурента (тут отдельная логика: не хамить, мягко выйти), неподходящий сегмент по размеру, неподходящий по гео, лид с попыткой выбить цену в первом сообщении, лид который сразу просит демо, и лид который пишет в формате одного слова. Восемь, потому что на шести ещё видны провалы по edge-кейсам, а на десяти модель начинает копировать формулировки из примеров слишком буквально.
Жёсткое правило по количеству вопросов прописано отдельно и продублировано: максимум 4 уточняющих за сессию, после четвёртого ответа лида агент пишет финальное сообщение и зовёт человека. Без этого ограничения LLM с радостью уходит в десятиходовое интервью, и конверсия в передачу SDR заметно проседает.
Тон голоса задаю явно, не намёками. Короткие предложения. Без emoji. Без капса. Обращение на ты или вы выбирается по сигналам из переписки лида: если он сам пишет "вы" или формальное приветствие, агент зеркалит. Если "хай, чё по ценам", переходит на ты. Это правило в промпте сформулировано через if-then, не через размытое "адаптируйся под собеседника", иначе модель скатывается в усреднённо-вежливый тон.
Отдельный блок, защита от prompt injection. Перед тем как инпут уходит в LLM, прогоняю его через фильтр на ключевые маркеры: ignore previous, system prompt, disregard, new instructions, act as, ты теперь, забудь инструкции. При срабатывании возвращаю заглушку и логирую попытку. Это не серебряная пуля, но отсекает заметную долю наивных атак, которые реально прилетают в чат с лендинга. Более хитрые обходы (через base64, через ролевые игры) ловлю уже на уровне output guard: проверяю, что ответ агента не содержит фрагментов системного промпта и не уходит за пределы заданных тем.
Что я узнал на практике: промпт работает не когда он длинный, а когда он непротиворечивый. Каждый раз, когда добавлял новое правило поверх старых, конверсия проседала, пока не находил и не убирал конфликт.
Обогащение данных: что и зачем подтягиваем
Из email-адреса вытаскиваю домен, из домена получаю почти всё нужное: размер компании, индустрию, tech stack, примерную выручку, страну регистрации. Основной источник: Clearbit Enrichment API. Если Clearbit вернул null по полю company_size, автоматически делаю запрос в ZoomInfo, потом Apollo. Если и там пусто, включается ручная эвристика: домен в зоне .edu или .gov уже говорит достаточно, а домены типа gmail.com или outlook.com помечаются как "личный email" и уходят в отдельную ветку.
По имени и компании через Apollo ищу LinkedIn-профиль. Добавляю должность и стаж на текущей позиции. Это критично для скоринга: VP Engineering с 6 месяцами на должности ведёт себя совершенно иначе, чем тот же VP с 4 годами.
Главный принцип, который я взял из документации Apollo и проверил практикой: enrich for action, not for completeness. Не надо тащить всё, что можно найти. У меня ограниченный набор полей:
company_size_range(1-10, 11-50, 51-200, 201-1000, 1000+)industryestimated_arrcountrytech_stack(список из топ-5 инструментов)linkedin_titleseniority_levelyears_in_rolefunding_stageis_personal_emailcompany_domainemployee_growth_6m
Ничего лишнего. Каждое поле либо влияет на скоринговую модель, либо определяет роутинг к конкретному менеджеру. Если поле не делает ни то, ни другое, оно просто не обогащается.
По деньгам: стоимость обогащения одного лида при комбинированном тарифе Clearbit + Apollo с fallback-стратегией вполне разумная. Clearbit дешевле для доменного обогащения, Apollo берёт своё за LinkedIn-матчинг. Разбивать запросы по источникам выгоднее, чем покупать полный пакет у одного провайдера.
Fallback-цепочка в коде выглядит просто: если первый источник вернул данные, последующие запросы не делаются. Это экономит заметную часть бюджета на обогащение, потому что Clearbit закрывает большинство B2B-доменов без доп. запросов.
Расчёт ROI: цифры через 90 дней после запуска
К концу января 2026 у меня были полные три месяца данных, и я наконец смог посчитать всё в трезвых цифрах, а не в презентационных обещаниях.
Первое, что почувствовал отдел: SDR перестали разгребать мусор. Часть команды перевёл целиком на tier A и tier B лиды, которых раньше не успевали отрабатывать руками. Это не "оптимизация штата", а перераспределение людей туда, где они дают деньги.
Дальше пошла воронка. Конверсия MQL→SQL заметно выросла по сравнению с исходным уровнем. Прирост существенный в абсолютных числах при том же входящем потоке.
Отдельная история со временем первого контакта. Было несколько часов в среднем (а по ночным заявкам и сутки), стало около 90 секунд. Конверсия в демо выросла, и это похоже связано именно со скоростью: лид ещё не успевает закрыть вкладку.
При текущем среднем LTV сделки проект должен окупиться примерно за 4-5 месяцев. Конкретные цифры итогового ROI на годовом горизонте я пока считаю предварительными: цикл сделки длинный, часть пайплайна ещё не закрылась.
Без учёта эффекта от высвобожденных SDR на tier A, который я не закладываю в расчёт, потому что первые результаты увижу только к лету. Если хотя бы половина моих ожиданий по ним подтвердится, годовая цифра будет существенной, но обещать это сейчас я не готов.

Время первого ответа сократилось с 4 часов до 18 минут, а ROI вышел в плюс на третий месяц после запуска.
Что пошло не так и как чинили
Первый месяц был болезненным. Агент стабильно завышал tier для агентств и фрилансеров: видел "маркетинговая компания, 15 человек" и отправлял их в корпоративный сегмент. Проблема оказалась в ICP-промпте: там вообще не было логики по типу юрлица. Починили просто. Добавили правило отсева по доменам вида .agency, плюс список фриланс-бирж в стоп-листе. После этого ложных апгрейдов стало заметно меньше.
Дальше вылезла история с галлюцинациями. GPT должен был обогащать профиль лида данными из Clearbit, но когда Clearbit возвращал пустой ответ, модель начинала придумывать. Размер компании, индустрия, иногда даже страна. Мы это поймали через ручной аудит выборки лидов: часть из них имела поля, которые никак не могли взяться из реальных источников. Решение: LLM вообще убрали из пайплайна обогащения. Только детерминированные источники, только верифицированные поля. Если данных нет, поле остаётся пустым.
Параллельно прилетали жалобы от лидов. Люди писали, что общаться неприятно, "как будто разговариваешь с роботом". Мы посмотрели логи первой недели и увидели проблему сразу: few-shot примеры были слишком шаблонными, и модель воспроизводила одни и те же обороты почти дословно. Переписали примеры, подняли temperature на диалоговых нодах. На скоринге оставили низкое значение, там нужна воспроизводимость. После этого жалобы прекратились.
Инфраструктурный провал случился при резком росте нагрузки. n8n просто падал. LLM-вызовы блокировали воркфлоу, таймауты накапливались, всё вставало. Вынесли все вызовы к GPT в отдельную очередь через Redis, добавили retry с экспоненциальным бэкоффом. Стабилизировалось.
И последнее, самое неприятное: утечка контекста между сессиями. Несколько лидов получили письма с чужими данными. Оказалось, что мы использовали общий ключ Redis без изоляции по пользователю. Контекст одной сессии перетекал в другую при параллельных запросах. Зафиксировали через session_id = hash(email + form_id). Теперь каждая сессия живёт в своём пространстве ключей и перепутать их физически невозможно.

Каждая проблема получила конкретный фикс: промпт с ограничениями, дедупликация по email-хэшу и калибровка порога скора на реальных данных.
Чек-лист внедрения для своей команды
Я уже дважды собирал такого агента с нуля и каждый раз порядок шагов одинаковый. Если перепрыгнуть через любой из них, через месяц всё равно вернёшься и будешь доделывать, только уже под крики РОПа.
1. Задокументируйте ICP как 15-20 признаков с весами. Не "наш клиент это SaaS компании среднего размера", а таблица: выручка 50-500M (вес 0.8), наличие in-house dev команды от 10 человек (0.6), стек включает Postgres/Snowflake (0.4), индустрия fintech/healthtech/logistics (0.7) и так далее. Без этой таблицы вы просто скармливаете LLM ваше настроение, и агент будет галлюцинировать категории. Я видел команды, которые пропускали этот шаг и потом две недели спорили, почему скоринг "странный".
2. Разметьте 200 исторических лидов руками по tier A/B/C/D. Берите реальные сделки за последние 12 месяцев: закрытые won, closed lost, отвалившиеся на discovery. Размечают двое-трое сейлзов независимо, потом сверяете. Где расхождение больше одного тира, обсуждаете. Получается ваш golden set, на нём вы будете валидировать агента всю его жизнь.
3. Выберите стек по объёму. До нескольких сотен лидов в месяц можно жить на чистом n8n с OpenAI-нодой и парой webhook-ов. При росте объёма придётся выносить скоринг в отдельный воркфлоу с очередью и кешировать обогащение (Apollo, Clearbit). При очень большом объёме n8n начинает течь по таймаутам и стоимости запусков, переезжайте на Python или TypeScript с нормальной очередью (Redis + BullMQ или Celery), Postgres под состояние и LangGraph либо свой оркестратор.
4. Shadow mode на 2 недели. Агент скорит каждый входящий лид и пишет в отдельную колонку CRM, но маршрутизацию и ответы делают люди как обычно. В конце каждого дня выгружаете расхождения: где агент поставил A, а сейлз ушёл от лида через день, и наоборот. Это самая полезная фаза, тут вылезают дыры в ICP и кривые промпты. Нужна достаточная выборка, поэтому меньше недели-двух не имеет смысла.
5. A/B тест 50/50 минимум 4 недели. Случайное разделение входящего потока: половина идёт через агента с автоматической маршрутизацией и первым касанием, половина по старому процессу. Меряете conversion to meeting, conversion to opportunity, средний цикл, NPS от сейлзов. 4 недели это минимум,