Что делает этот агент и зачем он нужен
Схема простая. amoCRM выгружает контакты с нужными тегами или фильтрами, n8n забирает их по очереди и для каждого запускает GPT-4o с промптом, собранным из полей карточки: имя, должность, компания, отрасль, последнее действие в CRM. GPT-4o пишет письмо. Агент отправляет его через почтовый сервис и пишет результат обратно в карточку: дату отправки, тему письма, статус доставки.
Это не mail merge.
Разница принципиальная. В классической рассылке у тебя шаблон с переменными: "Привет, {{имя}}, мы помогаем компаниям вроде {{company}} решить...". Модель здесь не участвует вообще. В агентном подходе GPT-4o получает все данные по контакту и пишет текст с нуля, под конкретного человека. Письмо директору производственного завода из Екатеринбурга и письмо Head of Growth финтех-стартапа из Москвы будут структурно разными. Не потому что разные переменные подставились, а потому что модель меняет логику аргументации, примеры, даже тональность.
Персонализированные холодные письма, как правило, показывают более высокий open rate по сравнению с шаблонными рассылками с подстановкой имени. Разрыв в цифрах сильно зависит от базы, отрасли и конкретного провайдера, поэтому ориентироваться на чужие бенчмарки не стоит: полезнее замерить свои. Логика здесь понятная: спам-фильтры и живые люди одинаково хорошо чувствуют разницу между "письмом для меня" и "письмом, где вписали моё имя".
Тот же принцип работает и в квалификации входящих лидов через AI-агента для отдела продаж: персонализация на основе CRM-данных даёт прирост там, где шаблонный подход уже не помогает.
Но есть ситуации, где агент избыточен. Если база меньше 200 контактов, проще написать письма руками: потратишь час, но будет лучше, чем любая модель. Если аудитория тёплая, то есть люди уже знают тебя или твой продукт, персонализация через GPT-4o не даёт ощутимого прироста. Там важнее скорость и личный тон, а не точность попадания в контекст незнакомца.
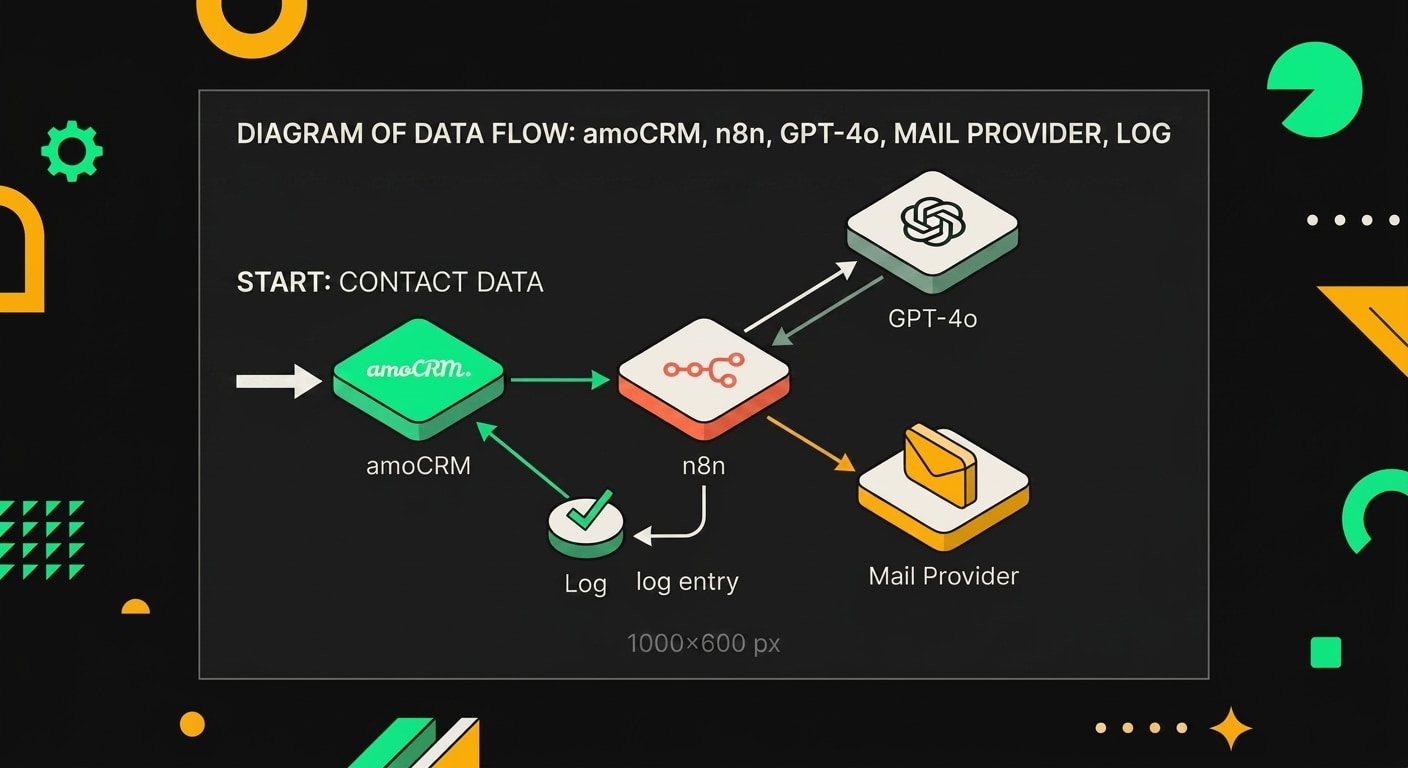
Агент состоит из четырёх слоёв: сбор данных из amoCRM, генерация текста через GPT-4o, антиспам-фильтр и отправка через SMTP с логированием обратно в CRM.
Инфраструктура: n8n self-hosted или облако
Первый вопрос, который возникает при запуске любого автоматизированного проекта: платить за облако или поднимать своё? С n8n ответ зависит от объёма выполнений, и здесь математика довольно жёсткая.
Облачный план Starter стоит $24 в месяц и даёт 2 500 выполнений. Звучит прилично, но если у вас ежедневная рассылка дайджестов хотя бы на 100 подписчиков, лимит кончается за 2-3 недели. Дальше либо доплачивать, либо ждать следующего цикла. Для продакшн-рассылки это неприемлемо.
Self-hosted Community Edition бесплатна. Актуальные системные требования смотри в официальной документации n8n: они периодически меняются с новыми релизами. Hetzner CX22 стоит около 4 EUR в месяц и с запасом перекрывает нужды небольшого workflow. Я использую именно эту конфигурацию: Docker Compose, Postgres вместо SQLite (SQLite начинает сыпаться при параллельных запросах), Nginx как реверс-прокси с SSL через Certbot.
Вот минимальный docker-compose.yml для старта:
version: '3.8'
services:
n8n:
image: n8nio/n8n:latest
restart: always
ports:
- '5678:5678'
environment:
- N8N_BASIC_AUTH_ACTIVE=true
- N8N_BASIC_AUTH_USER=admin
- N8N_BASIC_AUTH_PASSWORD=strongpassword
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=n8npassword
- WEBHOOK_URL=https://your-domain.com/
volumes:
- n8n_data:/home/node/.n8n
postgres:
image: postgres:15
environment:
- POSTGRES_DB=n8n
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=n8npassword
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
n8n_data:
postgres_data:
После docker compose up -d интерфейс поднимается на порту 5678. Nginx проксирует его на 443 с вашим доменом, Certbot выдаёт сертификат за две минуты.
Про Make и Zapier скажу коротко: self-hosted варианта у них нет в принципе, а каждый вызов к OpenAI считается отдельной операцией. На проекте с AI-суммаризацией это означает, что счётчик операций улетает в несколько раз быстрее, чем кажется на старте. Подробный разбор того, где n8n выигрывает у no-code платформ при построении AI-агентов, поможет выбрать инструмент под конкретную задачу.
Ещё один момент по версии n8n: в ветке 1.x нативный узел OpenAI поддерживает GPT-4o без каких-либо дополнительных плагинов. Указываете API-ключ, выбираете модель из дропдауна, готово. В 0.x этого не было, там приходилось использовать HTTP Request узел вручную. Если у вас старая установка, обновитесь.
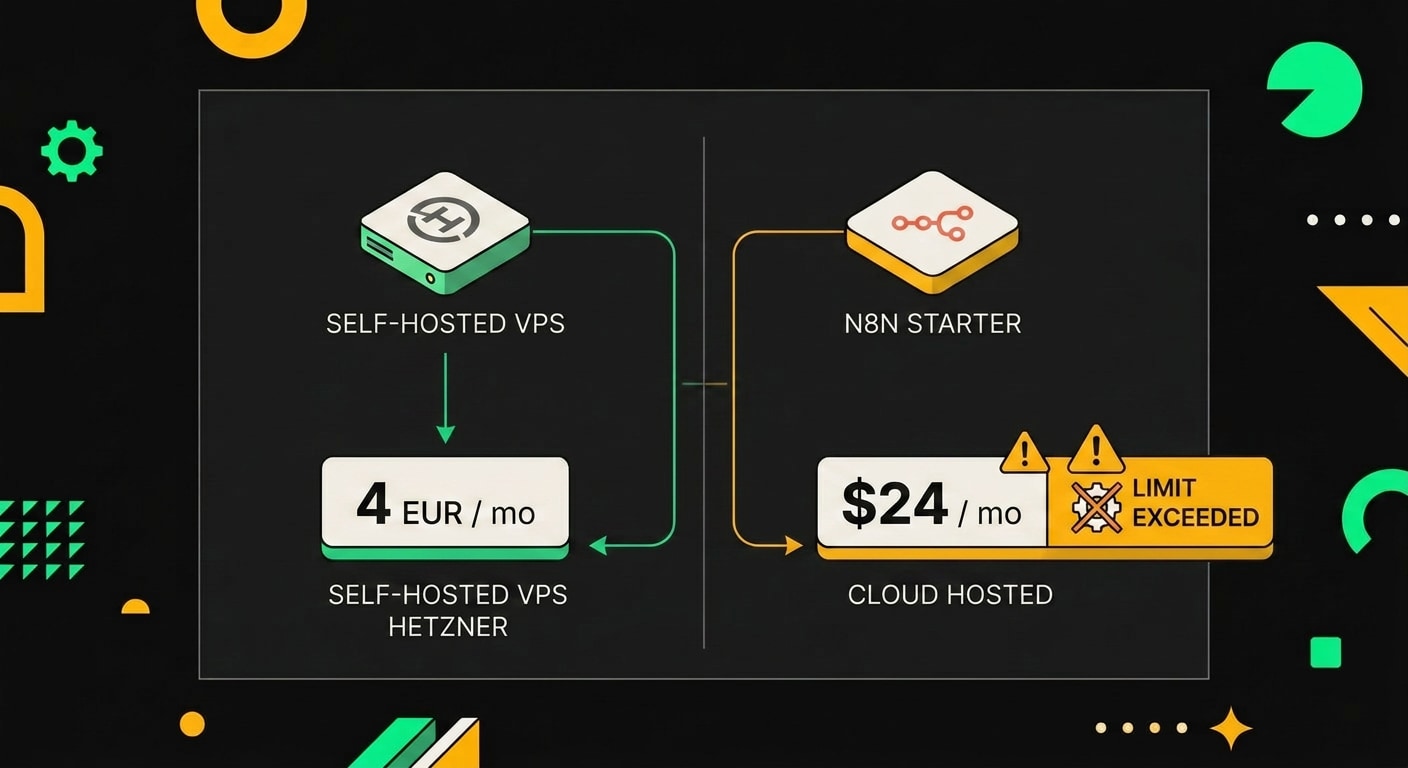
Self-hosted версия n8n не ограничивает количество выполнений и стоит 0 рублей в месяц, тогда как облачный план Starter обходится примерно в 20 долларов при лимите 2500 выполнений.
Подключение amoCRM к n8n: новый способ через OAuth2
Раньше интеграция с amoCRM через n8n строилась на узле HTTP Request с ручными заголовками. Ты хранил access_token где-то в переменных окружения или прямо в параметрах узла, а раз в 24 часа токен протухал и всё ломалось. Кто хоть раз просыпался под утро от алерта о том, что рассылка не ушла из-за 401 Unauthorized, тот понимает, о чём я.
В 2025 году n8n добавил нативный credential-тип "amoCRM OAuth2 API". Токены теперь обновляются автоматически, руками ничего не трогаешь.
Создание интеграции в amoCRM
Заходи в amoCRM: "Настройки" -> "Интеграции" -> "Создать интеграцию". Заполни название, укажи Redirect URI:
https://your-n8n-domain.com/rest/oauth2-credential/callback
Здесь your-n8n-domain.com - твой реальный домен, на котором крутится n8n. Локальный localhost не сработает: amoCRM требует публичный HTTPS-адрес.
После создания интеграции amoCRM выдаст Client ID и Client Secret. Копируй оба.
Настройка credential в n8n
В n8n открываешь "Credentials" -> "Add Credential", ищешь тип "amoCRM OAuth2 API". Вставляешь Client ID, Client Secret и указываешь поддомен своего аккаунта (например, mycompany.amocrm.ru). Жмёшь "Connect", браузер редиректит тебя на страницу авторизации amoCRM, ты подтверждаешь, и готово. Refresh-токен n8n хранит сам и обновляет по мере необходимости.
Получение контактов
Для получения списка контактов используешь HTTP Request узел с этим credential. Метод GET, URL:
https://your-subdomain.amocrm.ru/api/v4/contacts?limit=50&with=leads,tags
Параметр with=leads,tags заставляет amoCRM отдать связанные сделки и теги прямо в теле ответа, без отдельных запросов. Ответ выглядит так:
{
"_embedded": {
"contacts": [
{
"id": 12345,
"name": "Иван Петров",
"custom_fields_values": [
{
"field_code": "EMAIL",
"values": [{"value": "ivan@company.ru", "enum_code": "WORK"}]
},
{
"field_code": "POSITION",
"values": [{"value": "CTO"}]
}
],
"_embedded": {
"leads": [{"id": 67890, "name": "Сделка с Company LLC"}]
}
}
]
}
}
Обрати внимание на структуру custom_fields_values: email не лежит в отдельном поле верхнего уровня. Его нужно доставать через field_code. В n8n это делается узлом Code примерно так:
const contacts = $input.first().json._embedded.contacts;
return contacts.map(contact => {
const emailField = contact.custom_fields_values?.find(
f => f.field_code === 'EMAIL'
);
const email = emailField?.values?.[0]?.value ?? null;
const leadId = contact._embedded?.leads?.[0]?.id ?? null;
return {
json: {
id: contact.id,
name: contact.name,
email,
leadId
}
};
});
Пагинация
amoCRM отдаёт максимум 250 контактов за один запрос. Если база больше, добавляешь параметр page=2, page=3 и так далее. В n8n это удобно делать через Loop Over Items или узел Split In Batches, пока _embedded.contacts не вернёт меньше limit записей, это сигнал, что страницы кончились.
Обновление контакта после отправки письма
Когда письмо ушло, нужно зафиксировать это в CRM. Два запроса. Первый - обновляешь контакт через PATCH:
PATCH /api/v4/contacts/{id}
Второй - создаёшь примечание к сделке через POST:
POST /api/v4/leads/{lead_id}/notes
В теле примечания передаёшь note_type: "common" и текст с датой отправки. Так менеджер видит в карточке сделки полную историю касаний, не только то, что он сам вбил руками.
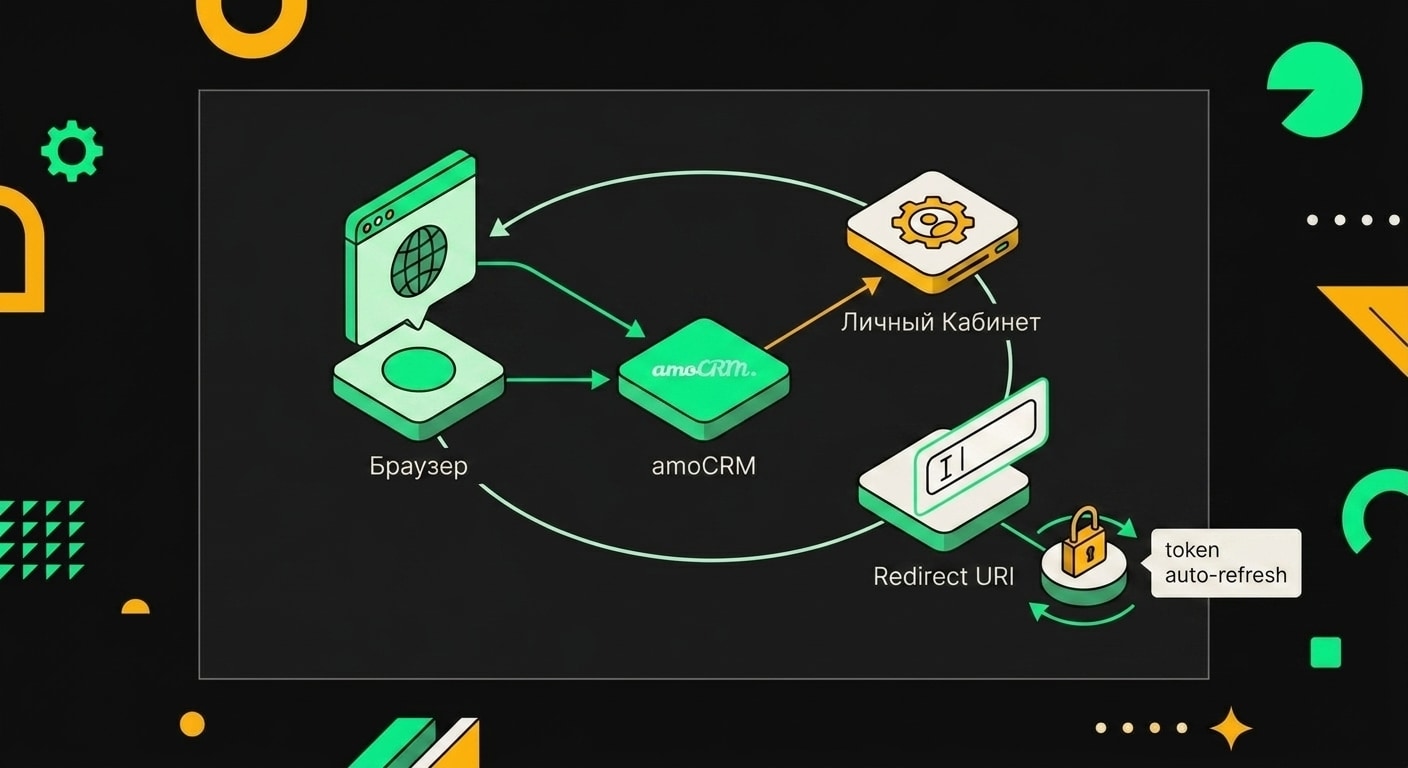
В настройках интеграции amoCRM нужно указать redirect URI вида https://your-n8n-domain/rest/oauth2-credential/callback, иначе авторизация завершится ошибкой 400.
Workflow в n8n: структура узлов
Начну с того, что весь workflow умещается в восемь узлов плюс триггер. Это не много, но и не мало. Каждый узел делает ровно одно дело, и это сознательное решение: когда что-то падает, сразу видно где.
Триггер. Используй Schedule Trigger с расписанием "каждый будний день в 09:00" по часовому поясу офиса. Параллельно повесь Webhook-триггер для ручного запуска, когда нужно прогнать тест без ожидания следующего утра. В n8n можно держать оба триггера активными и соединить их через Merge.
Узел 1: amoCRM, выборка контактов. Запрашиваем контакты с тегом cold_outreach и кастомным полем статуса не отправлено. В amoCRM фильтрация по тегам через API работает через параметр filter[tags], а кастомные поля придётся фильтровать уже в Code-узле, потому что amoCRM не даёт фильтровать по ним нативно в GET-запросе. Так что на выходе получаешь все контакты с тегом, а дальше чистишь сам.
Узел 2: SplitInBatches с размером 1. Это критичный момент. Если передать GPT сразу 50 контактов одним запросом, он начнёт смешивать детали: напишет Анне из "Сбертех" письмо с упоминанием должности Михаила из "Яндекса". Размер батча 1 означает: один контакт, один запрос к OpenAI, одно письмо. Да, медленнее. Зато правильно.
Узел 3: Code (JavaScript), парсинг полей. Custom fields в amoCRM приходят в виде массива объектов, где у каждого есть field_id и values. Никакого удобного contact.email нет. Пишем функцию:
const fields = $input.item.json.custom_fields_values || [];
const getField = (fieldId) => {
const field = fields.find(f => f.field_id === fieldId);
return field?.values?.[0]?.value ?? null;
};
return [{
json: {
email: getField(12345), // твой field_id для email
position: getField(12346), // должность
company: $input.item.json.company?.name ?? 'компания не указана',
contactName: $input.item.json.name,
contactId: $input.item.json.id
}
}];
Field ID смотришь в настройках amoCRM или через GET /api/v4/contacts/custom_fields.
Узел 4: OpenAI, GPT-4o. В системный промпт кладёшь инструкцию: тон, длина письма, запрет на стоп-слова ("синергия", "взаимовыгодное сотрудничество"). В пользовательский промпт передаёшь данные контакта через выражения n8n. Модель возвращает JSON с полями subject и body. Именно JSON, не свободный текст, иначе следующий узел не распарсит ответ надёжно. Это настраивается через параметр Response Format в узле OpenAI.
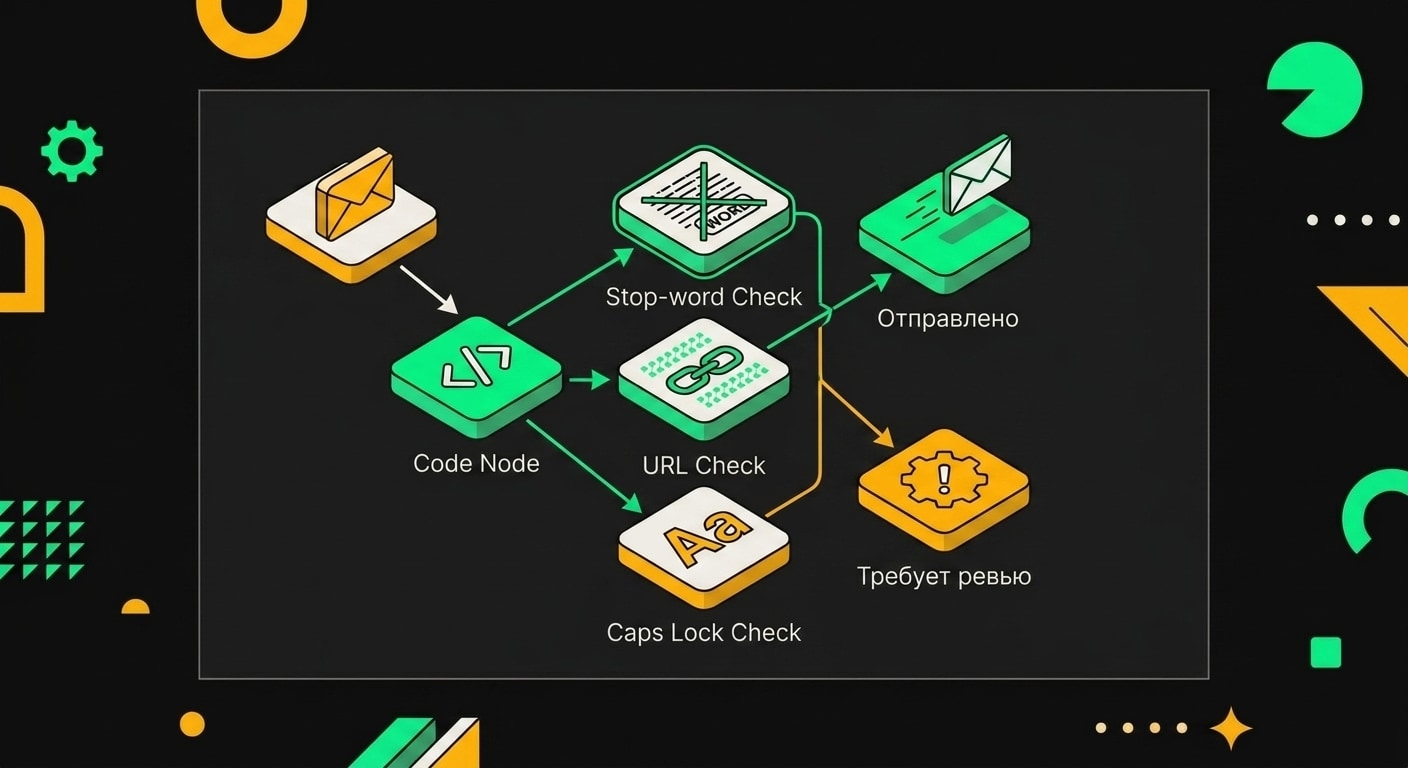
Узел 5: IF, антиспам-проверка. Перед отправкой прогоняем текст письма через простую функцию: считаем количество ссылок (больше двух, стоп), проверяем длину (меньше 80 слов или больше 400, стоп), ищем триггерные слова из заранее составленного списка. Если письмо не прошло, контакт уходит в ветку "fail" и получает тег needs_review. Потом разберёшься руками. Лучше пропустить один контакт, чем отправить спам.
Узел 6: Gmail или SMTP. Gmail удобнее для небольших объёмов, но у него лимит 500 писем в сутки на обычный аккаунт Google Workspace. Если больше, нужен SMTP через SendGrid или Postmark. В узле ставишь From Name в виде имени конкретного сотрудника, не noreply@.
Узел 7: amoCRM, обновление контакта. Три действия подряд в одном узле через несколько последовательных HTTP-запросов: добавляем тег отправлено, снимаем тег не отправлено, создаём примечание с темой и телом письма плюс timestamp. Примечание важно: через две недели ты забудешь, что именно было отправлено Ивану из "Газпромнефти".
Узел 8: Wait, случайная задержка. Ставишь Expression в поле "Wait Amount": ={{ Math.floor(Math.random() * 91) + 30 }} секунд. Это даёт диапазон от 30 до 120 секунд. Почтовые серверы обучены распознавать отправку с фиксированным интервалом как автоматическую. Случайность делает поток писем похожим на ручную работу. Дешёвый трюк, но он реально снижает вероятность попасть в спам.
После узла 8 workflow возвращается к SplitInBatches и берёт следующий контакт из очереди.
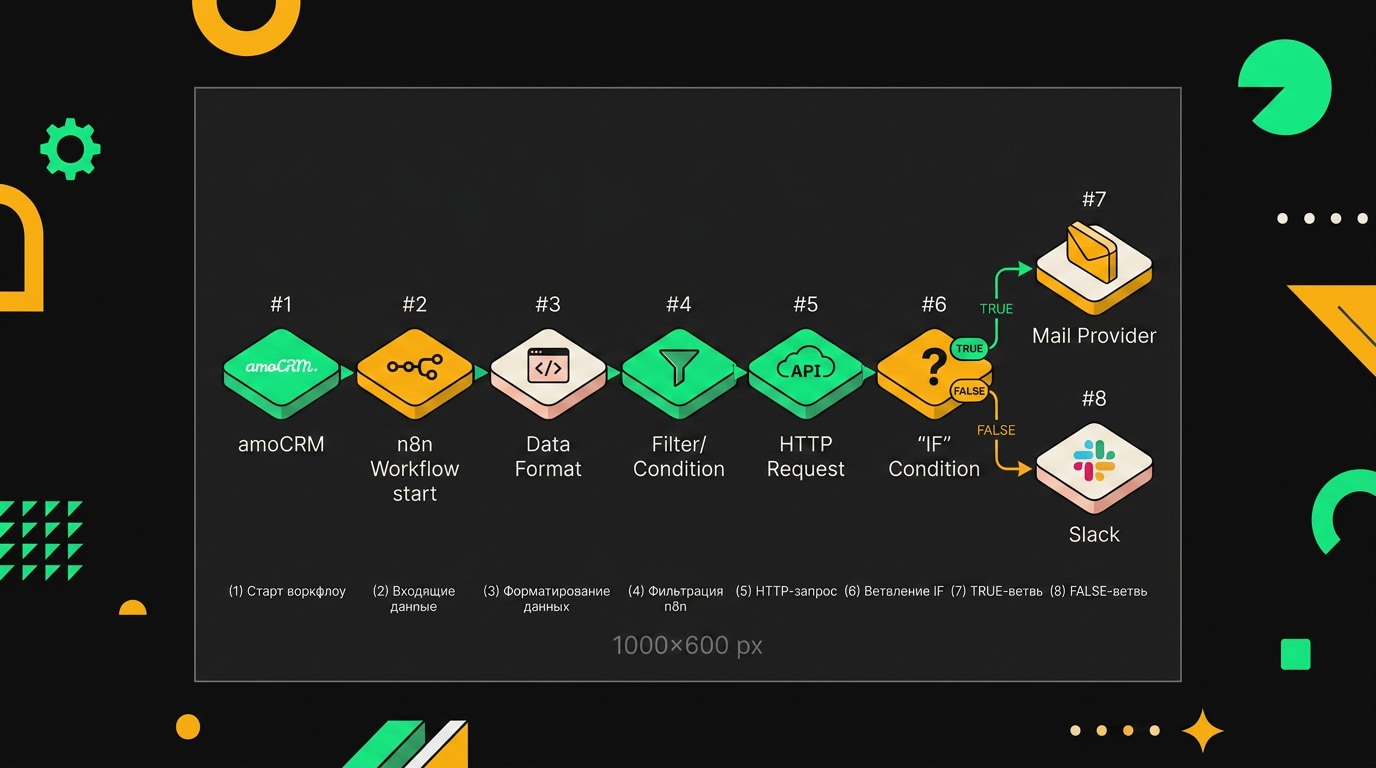
Workflow включает семь узлов: триггер по расписанию, выборка лидов из amoCRM, обогащение данных, вызов GPT-4o, проверку антиспам-фильтра, отправку письма и запись статуса в CRM.
Промпт для GPT-4o: как получить письмо, которое не похоже на спам
Весь механизм держится на двух промптах. Системный задаёт характер и ограничения, пользовательский подставляет живые данные из CRM. Если смешать их в один, GPT начинает "договариваться" сам с собой и нарушает правила через два-три запроса.
Системный промпт работает как контракт. Вы фиксируете роль, тон, структуру и список слов, которые нельзя трогать. GPT неплохо соблюдает жёсткие запреты, когда они перечислены явно, а не размыто описаны как "пиши профессионально".
Температура имеет значение. При 0.3 все письма звучат как один и тот же человек, написавший сто копий одного текста. Получатели это чувствуют. Диапазон 0.7-0.9 даёт реальную вариативность: разные первые предложения, разные формулировки CTA, разный ритм. Письма перестают выглядеть как рассылка.
Длина 100-130 слов. Холодные письма длиннее 150 слов читают хуже по всем метрикам открытий, с которыми я работал. GPT без явного ограничения пишет 200-250 слов по умолчанию.
Просить JSON в ответе, не plain text. Тогда следующий узел в n8n или Make парсит subject и body без регулярок и без боли.
// Системный промпт
Ты пишешь холодные B2B-письма на русском языке от имени компании [Название].
Правила:
- Длина тела письма: 100-130 слов
- Тон: деловой, но живой. Без канцелярита
- Первое предложение — конкретная деталь про компанию получателя, не про нас
- Никакого «Здравствуйте! Меня зовут...» в начале
- Запрещённые слова в теме: бесплатно, срочно, гарантия, выгода, акция, скидка
- Один призыв к действию в конце. Только один
- Формат ответа — JSON: {"subject": "...", "body": "..."}
// Пользовательский промпт (шаблон)
Получатель: {{name}}, {{position}} в компании {{company}}.
Контекст сделки: {{lead_name}}.
Наш продукт решает: [описание ценности].
Напиши письмо.
Первое предложение в правилах важнее остальных. GPT по умолчанию начинает с "Наша компания занимается...", что убивает письмо мгновенно. Явная инструкция про деталь получателя переворачивает логику: письмо начинается с них, а не с вас.
Пример того, что выходит на выходе при правильно настроенном промпте:
{
"subject": "Вопрос по автоматизации отдела продаж в Meridian Group",
"body": "Видел, что Meridian Group в этом году открыла направление
корпоративных поставок — обычно на этом этапе менеджеры тонут
в ручных задачах: квалификация лидов, отправка КП, напоминания.
Мы помогаем это убрать: интеграция с amoCRM, автоматические
цепочки писем, триггеры по статусам сделок. Клиенты типично
экономят 6-8 часов в неделю на одного менеджера уже в первый месяц.
Если тема актуальна, готов показать на вашем примере за 20 минут.
Когда удобно созвониться?"
}
Одна деталь про структуру: запрещённые слова из спам-листов надо добавлять именно в системный промпт, не в пользовательский. Пользовательский меняется каждый раз, системный стабилен. Полный список разберём в следующей секции.
Схожая логика разделения системного и пользовательского промптов применяется и в архитектуре агента-аналитика для финдиректора: там тоже инструкции и живые данные держат раздельно, чтобы модель не "размывала" правила под давлением входных данных.
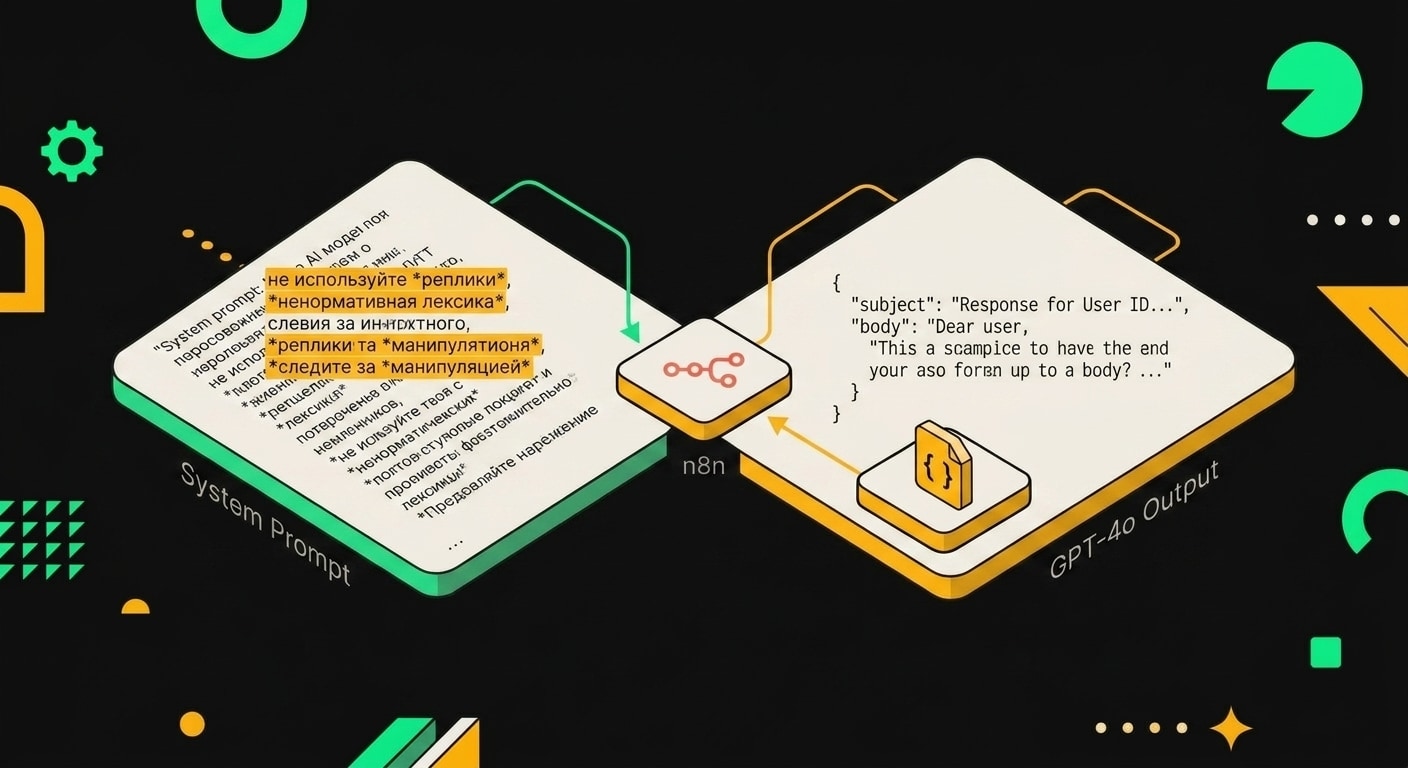
Промпт передаёт GPT-4o поля компании, должность контакта и последнее действие в CRM, а модель возвращает строго валидный JSON с полями subject, body и fallback_subject.
Антиспам-фильтр внутри workflow
Спам-фильтры в 2026 году смотрят на три вещи: репутацию отправляющего домена, корректную аутентификацию (SPF, DKIM, DMARC) и содержимое письма. Причём если с первыми двумя всё решается один раз через DNS и почтового провайдера, то содержимое меняется в каждой рассылке. Именно его нужно проверять прямо в n8n, до отправки.
Добавляю Code-узел сразу после узла формирования письма и до SMTP-шага. Вот его содержимое:
// Code-узел в n8n: антиспам-проверка
const subject = $json.subject || '';
const body = $json.body || '';
const spamWords = [
'бесплатно', 'срочно', 'не пропустите', 'гарантия',
'специальное предложение', 'кликните здесь', '100%',
'без риска', 'только сегодня', 'заработай'
];
const fullText = (subject + ' ' + body).toLowerCase();
const foundSpamWords = spamWords.filter(word => fullText.includes(word));
const capsPattern = /([А-ЯA-Z]{4,}\s){2,}/;
const hasCapsAbuse = capsPattern.test(subject);
const linkCount = (body.match(/https?:\/\//g) || []).length;
const wordCount = body.split(' ').length;
const linkRatio = linkCount / wordCount;
const passed = foundSpamWords.length === 0 && !hasCapsAbuse && linkRatio < 0.01;
return {
passed,
issues: {
spamWords: foundSpamWords,
capsAbuse: hasCapsAbuse,
linkRatio: linkRatio.toFixed(3)
},
subject,
body
};
Разберу логику. Функция берёт тему и тело письма, склеивает в одну строку и ищет стоп-слова из списка. Слова выбраны не произвольно: именно они фигурируют в правилах SpamAssassin и фильтрах Gmail как триггеры с высоким весом. "Гарантированный доход" или "кликните здесь" в теме письма прибавляют к спам-скору сразу 2-3 балла.
Проверка caps-а работает через регулярку: если в теме стоят подряд два и более слова длиной от четырёх заглавных букв, письмо блокируется. "АКЦИЯ СЕГОДНЯ" уже триггер. Одно слово заглавными допустимо (например, аббревиатура), два подряд идут в ревью.
Соотношение ссылок к тексту: если в теле 200 слов и больше двух ссылок, linkRatio превысит 0.01. Порог жёсткий, но обоснованный. Письмо с пятью ссылками и тремя абзацами текста выглядит как рекламная листовка, алгоритмы это видят.
После этого узла ставлю IF-узел: если passed === false, маршрут идёт в ветку "требует ревью". Там создаю задачу в amoCRM через соответствующий узел, передаю в поле задачи массив issues.spamWords и значение linkRatio. Менеджер видит конкретную причину, а не просто флаг "что-то не так".
Теперь про аутентификацию. Без неё Code-узел бесполезен: письмо срежут ещё до анализа содержимого. Минимальный набор такой:
- SPF: TXT-запись в DNS вида
v=spf1 include:_spf.вашпровайдер.com ~all. Указывает, с каких серверов разрешено отправлять почту от имени домена. - DKIM: настраивается через почтового провайдера (Postmark, SendGrid, Unisender Go и т.д.), они выдают публичный ключ для DNS. Подписывает каждое письмо криптографически.
- DMARC: TXT-запись `v=DMARC1