

Что отдают и принимают маркетплейсы по webhook в 2026 году
Три крупнейших российских маркетплейса реализуют event-driven интеграцию по-разному. Настолько по-разному, что код для одного не переносится на другой без переписывания логики приёма событий.
Ozon Seller API работает через два отдельных механизма. Первый: notification API, куда вы регистрируете свой URL, и Ozon шлёт POST-запросы с JSON при возникновении события. Второй: chat-bot API для работы с сообщениями покупателей. Событийная модель охватывает new_posting (создан заказ), posting_cancelled (отмена), chat_message_new (новое сообщение в чате), ticket_created (обращение в поддержку). Аутентификация: заголовки Client-Id и Api-Key, которые вы берёте в личном кабинете продавца в разделе API-ключей.
Wildberries предоставляет API через suppliers-api.wildberries.ru. Основной поток: события статусов сборочных заданий, то есть всё что связано с жизненным циклом FBS-отгрузки. Параллельно работает отдельный канал для отзывов и вопросов покупателей. Но вот в чём проблема: стабильность push-канала у WB исторически ниже, чем у Ozon, и многие команды держат параллельный polling как страховку. JWT передаётся в заголовке Authorization: Bearer <token>, токен генерируется в разделе настроек продавца.
Yandex Market Partner API комбинирует подходы. События покрывают новые заказы, смену статусов, возвраты. YM переходит к retry с экспоненциальной задержкой, если ваш сервер не ответил корректно. Плюс у YM есть режим pull для тех случаев, когда ваш сервис временно недоступен: можно запросить пропущенные события через отдельный метод. OAuth-токен приложения получают через стандартный flow Яндекс.ID.
Ключевое различие в архитектуре приёма:
- Ozon: чистый push, ваш URL должен быть публично доступен и отвечать достаточно быстро
- WB: push с обязательным резервным pull, если хотите гарантии доставки событий
- YM: push плюс встроенный механизм догонялок через pull
Это влияет на то, как вы строите обработчик. Для Ozon достаточно принять POST, бросить задачу в очередь, вернуть 200. Для WB нужен ещё шедулер, который раз в N минут забирает то, что не пришло через push. Для YM надо следить за порядковыми номерами событий, чтобы не пропустить ничего при восстановлении после сбоя.
Про токены: не храните Client-Id Ozon и JWT WB в одном месте с одинаковым TTL ротации. JWT WB протухает и требует обновления, Api-Key Ozon живёт дольше. Путаница здесь стоит дорого в три часа ночи, когда продажи встали.
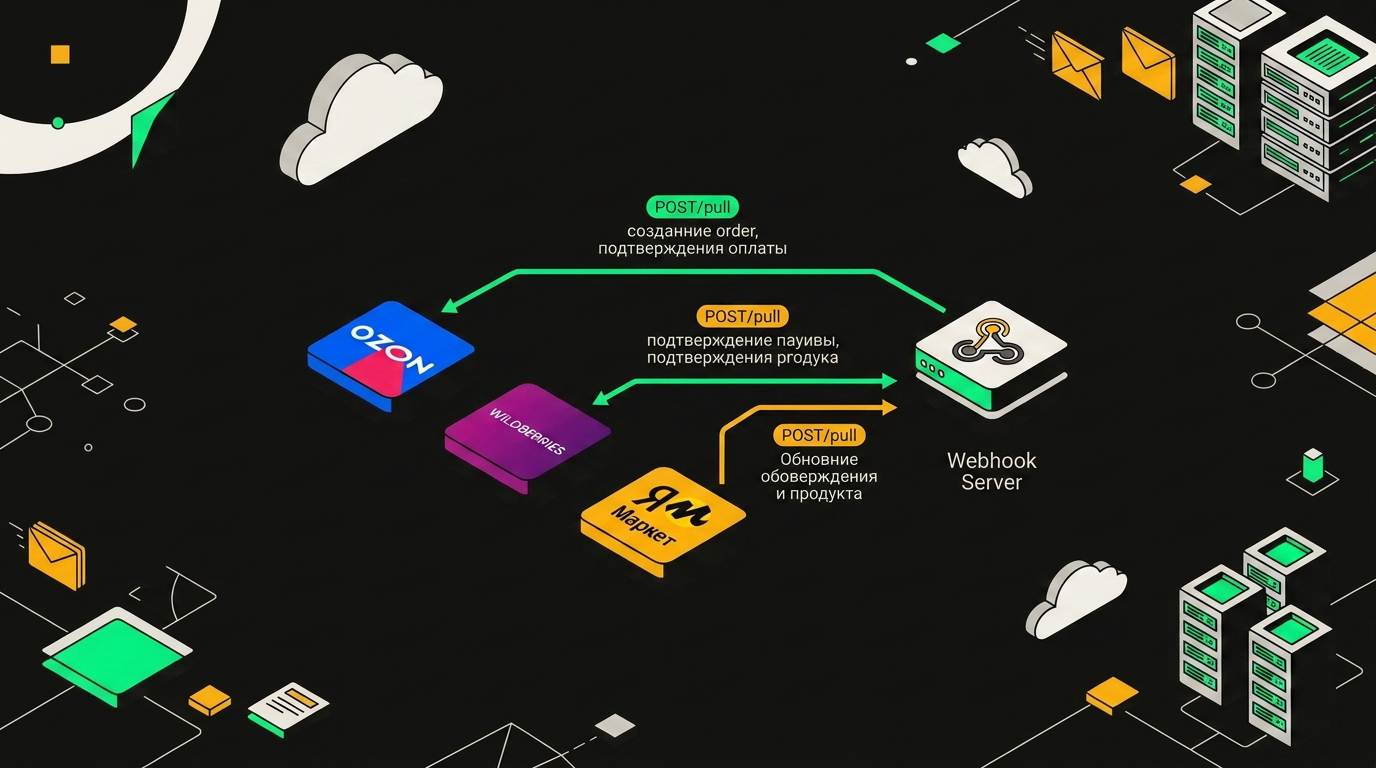
Три маркетплейса отправляют POST-запросы на разные эндпоинты одного сервера n8n, где каждый поток обрабатывается своим workflow.
Базовая схема приёма webhook в n8n
Узел Webhook кидаешь на холст, выбираешь метод POST, прописываешь путь. Для маркетплейсов я использую читаемые пути: /ozon-orders, /wb-events, /ym-notifications. Это не техническая необходимость, но когда смотришь на список вебхуков через полгода, сразу ясно что откуда.
Первое, на чём режутся почти все: в n8n есть два URL для каждого вебхука. Test URL работает только пока workflow открыт и ты жмёшь "Listen for test event". Production URL активен круглосуточно, но только если workflow активирован. Я видел кейсы, где человек настраивал интеграцию с Ozon через Test URL, всё работало, он закрывал вкладку, и заказы переставали приходить. Потом часовая отладка "почему маркетплейс не шлёт данные", хотя слать-то шлёт.
Теперь про тайминги. Wildberries и Ozon ждут 200 OK в пределах нескольких секунд. Если ответ не пришёл, они сделают повторную попытку, иногда несколько, и заказ или событие обработается дважды. Настройка "Respond When Last Node Finishes" убивает тебя здесь: если в цепочке есть запрос к внешнему API, запись в базу или хоть сколько-нибудь тяжёлая логика, лимит легко превышается.
Правильная схема: в узле Webhook выбираешь "Respond Immediately" с кодом 200, и workflow сразу подтверждает получение. Дальше вся обработка идёт асинхронно. Если на сервере включён Queue Mode (он включается через переменную окружения EXECUTIONS_MODE=queue плюс Redis), тяжёлые задачи встанут в очередь и не заблокируют приём следующего события. Без Queue Mode тяжёлую логику выношу в отдельный workflow и вызываю его через узел Execute Workflow с опцией "Run in parallel".
И последнее, что я делаю в каждой схеме приёма: сразу после Webhook, до любого парсинга, пишу сырое тело запроса в отдельную таблицу. Обычно это простой узел Postgres или Airtable с полями source, received_at, raw_body. Зачем? Парсинг может упасть, формат может поменяться (маркетплейсы любят менять схему без предупреждения), логика обработки может содержать баг. Сырые данные дают возможность перепрогнать обработку ретроспективно, не теряя ни одного события. Без этого журнала отладка инцидентов в n8n превращается в угадайку.
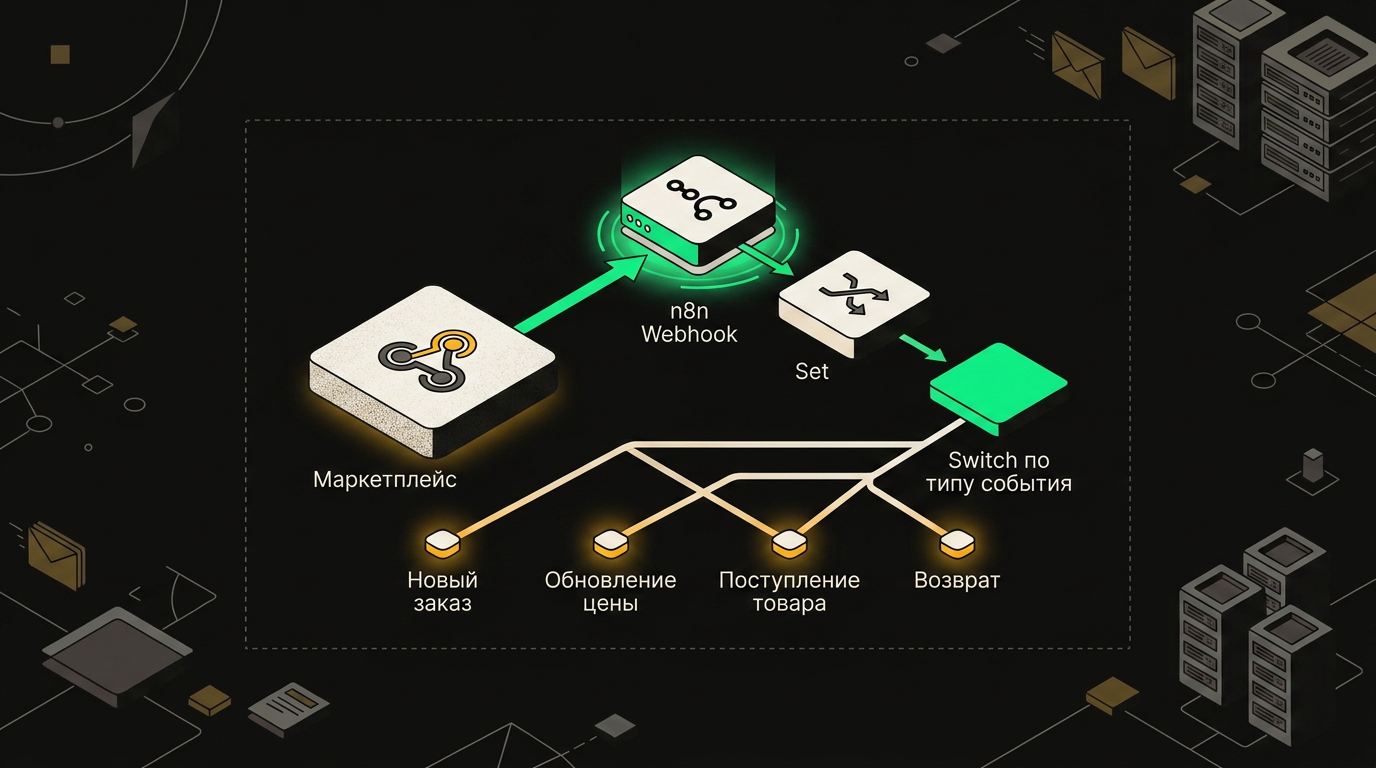
Webhook-узел принимает запрос, Switch-узел читает поле event_type и направляет данные в нужную ветку обработки.
Ozon: эндпоинты и payload
С Ozon я работаю в двух направлениях: исходящие запросы к Seller API (отправить сообщение клиенту, синхронизировать список отправлений) и входящие push-нотификации, которые сам Ozon шлёт мне на зарегистрированный URL.
Базовые эндпоинты, которыми я пользуюсь чаще всего:
POST /v1/chat/send/message, отправка сообщения покупателю в чат заказаPOST /v3/posting/fbs/list, пагинированная выборка FBS-отправлений за период, удобно для ночной сверки- Push-нотификации через Seller API push, когда нужно реагировать на событие в реальном времени, а не дёргать
/v3/posting/fbs/listкаждые 30 секунд
Чтобы Ozon начал слать пуши, URL надо зарегистрировать в личном кабинете Seller, раздел "Уведомления". Требования жёсткие: HTTPS обязателен, TLS-сертификат валидный (самоподписанные не подойдут, Let's Encrypt работает нормально), домен резолвится с публичных DNS. Если сертификат протух, нотификации просто перестают приходить, в логах личного кабинета вы увидите ошибки доставки.
Структура события у Ozon плоская и предсказуемая. Основные поля: message_type (тип события), posting_number (номер отправления, формат XXXXXXXX-XXXX-X), seller_id, warehouse_id, массив products и таймстамп. Вот как выглядит типичный payload для нового FBS-заказа:
{
"message_type": "TYPE_NEW_POSTING",
"posting_number": "24219509-0020-1",
"products": [
{"sku": 147451959, "quantity": 1, "offer_id": "A-456"}
],
"in_process_at": "2026-05-02T08:14:23Z",
"warehouse_id": 18512637000,
"seller_id": 11122
}
Подтверждение нужно вернуть быстро: HTTP 200, и Ozon считает доставку успешной. Если ответ не пришёл или код отличается от 200, Ozon ретраит. Поэтому накапливать тяжёлую логику внутри хендлера нельзя.
Практический паттерн, который я ставлю на всех интеграциях: хендлер делает ровно две вещи. Валидирует подпись и кладёт сырой payload в очередь (RabbitMQ, Redis Streams, что есть). Сразу отвечает 200. Вся бизнес-логика, обогащение данными, запись в БД, рассылка во внутренние системы происходит в воркере. Так я ни разу не упирался в таймаут, даже в пиковые дни распродаж.
Wildberries: подписки на события и опрос
С WB ситуация простая и неприятная одновременно: полноценных push-вебхуков на новые заказы FBS у них до сих пор нет. Поэтому архитектура почти всегда сводится к опросу с разумным интервалом, а вебхуки прикручиваются только там, где они реально доступны (например, отзывы).
Базовый контур такой. Все запросы идут на suppliers-api.wildberries.ru, авторизация через JWT в заголовке Authorization: Bearer <token>. Токен генерируется в личном кабинете продавца, отдельно под каждую категорию API (Маркетплейс, Контент, Статистика и т.д.). Не пытайтесь использовать один токен на всё, это путь к 401 в самый неподходящий момент.
Минимальный набор эндпоинтов для FBS-потока:
GET /api/v3/orders/new, новые сборочные задания, которые ещё не взяты в работуGET /api/v3/orders/status, текущие статусы по спискуorderIdfeedbacks-api.wildberries.ru/api/v1/feedbacks, отзывы и вопросы, тут уже можно навесить вебхук-канал на свою сторону через интеграционный слой
Для опроса в n8n я ставлю Schedule Trigger на 30–60 секунд. Меньше 30 не нужно: WB не любит частые запросы, словите 429, а реальная скорость появления заказа в выдаче всё равно не выше этого порога. Больше 60 уже бьёт по SLA сборки.
// n8n HTTP Request node для poll WB
{
"method": "GET",
"url": "https://suppliers-api.wildberries.ru/api/v3/orders/new",
"headers": {
"Authorization": "={{$credentials.wbToken}}"
},
"qs": {
"limit": 1000,
"next": "={{$json.next ?? 0}}"
}
}
Параметр next это курсор пагинации, WB возвращает его в ответе. На первой итерации передаём 0, дальше тянем из предыдущего ответа. Если заказов в очереди больше limit, без курсора вы будете молча терять часть заданий и узнаете об этом от службы поддержки WB через штраф.
Теперь про идемпотентность, на которой обжигаются почти все. WB периодически присылает одно и то же событие дважды: либо после ретрая на их стороне, либо при изменении мелких полей. Если вы на каждый ответ дёргаете создание задачи в CRM или печать этикетки, готовьтесь к дублям.
Я делаю дедуп по составному ключу orderId + lastChangeAt (для отзывов аналогично id + updatedDate). Храню в Redis с TTL или в отдельной таблице Postgres с уникальным индексом. В n8n это узел Code после HTTP Request:
const seen = await this.helpers.redis.get(`wb:order:${item.json.id}:${item.json.lastChangeAt}`);
if (seen) return null;
await this.helpers.redis.set(`wb:order:${item.json.id}:${item.json.lastChangeAt}`, '1', 'EX', 604800);
return item;
И последнее. Не смешивайте опрос новых заказов с опросом статусов в одном воркфлоу. Разделите: один поток на /orders/new каждые 30 секунд, второй на /orders/status по списку активных заказов раз в 2–5 минут. Так вы не упрётесь в общий rate limit и логи останутся читаемыми, когда что-то пойдёт не так.
Yandex Market: push-нотификации Partner API
В Маркете push-механика устроена так: ты регистрируешь свой публичный endpoint, и YM сам стучится к тебе при каждом значимом событии в магазине. Поллинг /orders раз в минуту больше не нужен, и это сильно разгружает rate limit на боевых кампаниях с тысячами заказов в день.
Подписка оформляется одним вызовом:
POST https://api.partner.market.yandex.ru/campaigns/{campaignId}/notifications/subscriptions
Authorization: Bearer <oauth-token>
Content-Type: application/json
{
"url": "https://shop.example.ru/webhooks/ym",
"events": [
"ORDER_STATUS_UPDATED",
"ORDER_CANCELLATION_REQUESTED",
"RETURN_INITIATED",
"PRICE_QUARANTINE"
]
}
Что прилетает на каждый из типов:
ORDER_STATUS_UPDATED, заказ сменил статус или подстатус (PROCESSING/STARTED, DELIVERY/SERVICE и т.п.)ORDER_CANCELLATION_REQUESTED, покупатель или Маркет запросили отмену, ответить надо в течение SLA, иначе отмена пройдёт автоматическиRETURN_INITIATED, оформлен возврат, нужно готовить приёмкуPRICE_QUARANTINE, цена ушла в карантин из-за резкого скачка, оффер скрыт с витрины до подтверждения
Тело уведомления выглядит так:
{
"orderId": 123456789,
"campaignId": 10987,
"status": "PROCESSING",
"substatus": "STARTED",
"updatedAt": "2026-05-02T11:42:08+03:00",
"eventType": "ORDER_STATUS_UPDATED"
}
Подлинность рекомендуется проверять через заголовок X-Yandex-Market-Hmac с HMAC-SHA256 от сырого тела запроса, ключ выдаётся при создании подписки. Сравнение делай constant-time, иначе теоретически утечёт через тайминг:
import hmac, hashlib
def verify(raw_body: bytes, header_sig: str, secret: str) -> bool:
calc = hmac.new(secret.encode(), raw_body, hashlib.sha256).hexdigest()
return hmac.compare_digest(calc, header_sig)
Главная засада, на которой ловятся все, кто пишет webhook первый раз: YM ждёт быстрого ответа. Если за отведённое время не получил HTTP 200, уведомление помечается недоставленным и уходит в ретрай с экспоненциальным бэкоффом. Поэтому в обработчике делай только две вещи: проверь HMAC и положи payload в очередь (Redis Streams, RabbitMQ, SQS, что есть). Вся бизнес-логика, обновление БД, синк с 1С, нотификации в Telegram оператору, всё это уже из воркера.
Типичная ошибка: разработчик пишет в обработчик await db.update_order(...) напрямую, всё работает на стенде с одним заказом в минуту. При высокой нагрузке Postgres начинает лочить строки, ответы затягиваются, YM считает уведомления потерянными и шлёт ретраи, которые добивают БД окончательно. Лечится только очередью.
Отлаживать всё это удобно на sandbox.market.yandex.ru. Там создаёшь тестовый магазин, эмулируешь заказы через UI песочницы и смотришь, как твой endpoint их переваривает. Боевые заказы трогать не нужно, и это особенно ценно, когда правишь логику отмен. Один неверно обработанный ORDER_CANCELLATION_REQUESTED на проде, и это либо отгруженный отменённый заказ, либо штраф от Маркета за просроченный SLA.
Подписки можно посмотреть и удалить через GET и DELETE на том же URL. Полезно держать в репе скрипт, который при деплое сверяет актуальный список подписок с конфигом и приводит к нужному состоянию, иначе после смены домена легко забыть старый callback и неделю ловить 502 на мёртвом endpoint.
Проверка HMAC-подписи в n8n
Ozon, Wildberries и Яндекс.Маркет для критичных вебхуков (изменение заказа, отмена, возврат, обновление цены) поддерживают валидацию заголовка с HMAC-SHA256. Если подпись не сверять, любой, кто узнает URL вашего вебхука, сможет слать поддельные события об отменах и ронять остатки.
В n8n это делается двумя путями: через Crypto-ноду или через Function. Crypto-нода удобна, когда лень писать код: ставишь Type=HMAC, Algorithm=SHA256, Secret Key из credentials, Value=сырое тело запроса, на выходе hex. Дальше IF-нода сравнивает с заголовком. Минус: сравнение через === уязвимо к timing-атакам, JS закорачивает проверку строк на первом несовпавшем байте, и атакующий по разнице времени ответа подбирает подпись побайтно. На реальном Ozon с их латентностью это малореально, но правильнее сразу делать через crypto.timingSafeEqual.
Второй момент, на котором горят чаще всего: сырое тело. Если взять $json и сделать JSON.stringify, хеш не сойдётся никогда. Маркетплейс считает подпись от байт, которые он реально отправил, с его пробелами, порядком ключей и кодировкой. В Webhook-ноде нужно включить опцию Raw Body (или Binary Data, в зависимости от версии), и читать тело из $input.first().binary.data.
Function-нода для Яндекс.Маркета:
// Function node: проверка подписи YM
const crypto = require('crypto');
const raw = $input.first().binary.data.toString('utf8');
const signature = $input.first().json.headers['x-yandex-market-hmac'];
const secret = $env.YM_WEBHOOK_SECRET;
const calc = crypto.createHmac('sha256', secret).update(raw).digest('hex');
const ok = crypto.timingSafeEqual(Buffer.from(calc), Buffer.from(signature));
if (!ok) throw new Error('Invalid HMAC');
return [{json: JSON.parse(raw)}];
Пара уточнений по коду. timingSafeEqual бросит исключение, если буферы разной длины, поэтому при подозрении на мусор в заголовке оборачивайте вызов в try/catch и считайте такое за невалидную подпись. Секрет держите в $env, не в теле workflow, иначе он улетит в экспорт JSON и в git.
При несовпадении не отвечайте 200, маркетплейс воспримет это как успешную доставку и не повторит событие. Отдавайте 401 через Respond to Webhook и пишите в лог: IP из x-forwarded-for, весь набор заголовков, первые 200 символов тела. Этого хватит, чтобы потом разобрать, что прилетело: реальная атака, протухший секрет после ротации или баг на стороне площадки.
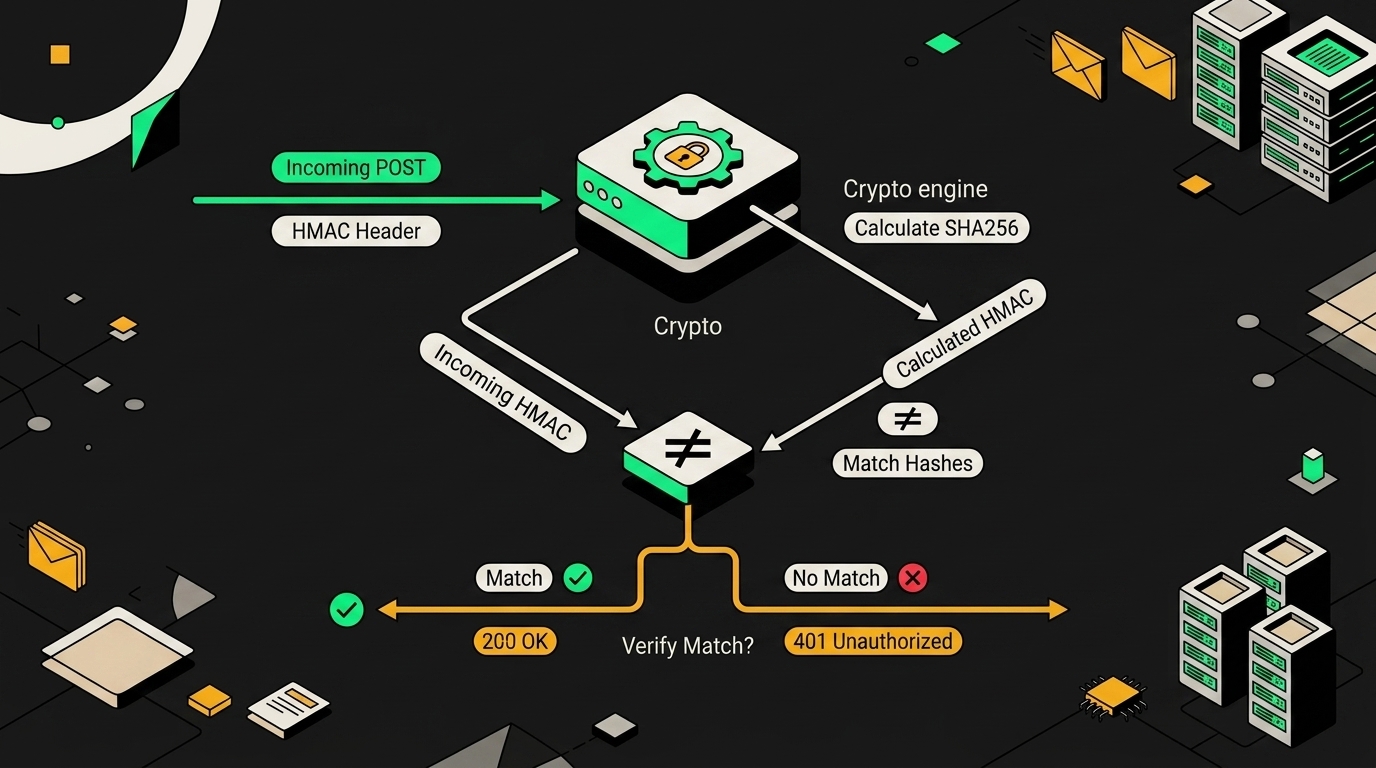
Узел Function вычисляет HMAC от тела запроса, сравнивает результат с заголовком X-Signature и блокирует поток при несовпадении.
Маршрутизация событий через Switch
Один вебхук на маркетплейс. Это принципиальный момент: не надо плодить пять эндпоинтов для разных типов событий, если можно направить всё в одну точку, а потом разобрать внутри.
Wildberries шлёт события с полем eventType, Ozon использует message_type, Яндекс.Маркет кладёт статус в status. Значит первый шаг после вебхука: нода Set, которая вытаскивает нужное поле в единое event_type, и уже с этим полем идёшь в Switch.
Switch прописываешь по четырём веткам:
new_order→ передаёшь в CRM (AmoCRM или Битрикс, зависит от проекта)cancelled→ отправляешь сигнал на склад, чтобы вернули резервreview→ уходит в OpenAI-ноду, где промпт классифицирует тональность и выделяет категорию жалобыrefund→ летит в бухгалтерию, обычно через HTTP-запрос к учётной системе или Google Sheets если бюджет невелик
Ветку "остальное" тоже пропиши явно. Default-ветка Switch без обработчика это тихая потеря данных, которую ты заметишь только когда маркетплейс добавит новый тип события и он просто исчезнет.
Отдельная история с Merge-нодой. Когда нужна агрегация событий по orderId (например, собрать полную историю заказа перед записью в базу), ставишь Merge в режиме waitForAll. Но учти: она держит поток открытым и ждёт все ветки. Если одна ветка завершилась, а другая висит из-за ретрая, Merge заблокирует запись. Я обычно добавляю таймаут на уровне HTTP-нод и явный fallback, чтобы Merge не ждала вечно.
Каждую ветку выноси в Sub-workflow. Это не ради красоты: отдельный саб тестируется изолированно, версионируется независимо, и когда Ozon изменит формат события new_order (а они изменят), ты правишь один файл, а не ищешь нужный Switch в пятисотнодовом полотне.
И последнее про источник данных. Прежде чем записывать что-либо в базу, добавляй поле source со значением ozon, wb или ym. Звучит банально, но без него уже через три месяца получишь таблицу заказов, где непонятно, какой маркетплейс что прислал. Единое хранилище работает только если данные можно фильтровать по источнику без джойнов с пятью другими таблицами.
Обработка ошибок и ретраев
Маркетплейсы любят отвечать 429, особенно если у тебя несколько воркфлоу опрашивают один и тот же эндпоинт. Игнорировать заголовок Retry-After нельзя: WB и Ozon начнут банить токен на десятки минут, если долбиться без пауз. Делаю так: после HTTP-ноды ставлю IF на код ответа, и если 429, гоню в Function для расчёта паузы, а потом в Wait с динамическим значением.
// Wait с Retry-After
const retryAfter = parseInt($input.first().json.headers['retry-after'] || '5', 10);
return [{json: {waitSeconds: Math.min(retryAfter, 300)}}];
Верхняя граница в 300 секунд тут не от хорошей жизни: иногда Retry-After приходит с неожиданно большим значением, и весь поток встаёт надолго, пока не заметишь. Лучше упереться в потолок и потом в следующей итерации опять получить 429, чем заморозить пайплайн.
С токенами история другая. JWT WB протухает, и если ловить 401 в момент работы основного воркфлоу, ты теряешь батч событий. Я держу отдельный workflow на расписании Cron: он дёргает refresh, кладёт новый токен в Credentials через n8n API и пишет timestamp в служебную таблицу. Если основной флоу всё-таки получил 401 (часовые пояса, рестарт, что угодно), он триггерит этот же refresh-воркфлоу через Execute Workflow и повторяет запрос один раз. Без рекурсии: два 401 подряд значит, что проблема не в токене, и событие уезжает в DLQ.
Сам Error Workflow подключаю в Settings каждого продакшен-флоу. Внутри минимум: Telegram-нода с упоминанием @channel, текст с {{$json.execution.url}}, именем воркфлоу и первой строкой стектрейса. Без url алерт бесполезен, ты просто знаешь что что-то упало. С url открываешь n8n и видишь конкретный execution с входными данными ноды, на которой словили исключение.
DLQ это таблица в Postgres:
CREATE TABLE dlq_events (
id BIGSERIAL PRIMARY KEY,
source TEXT NOT NULL,
event_id TEXT NOT NULL,
raw_body JSONB NOT NULL,
error TEXT,
retry_count INT DEFAULT 0,
created_at TIMESTAMPTZ DEFAULT now(),
UNIQUE (source, event_id)
);
Уникальный индекс на (source, event_id) решает сразу две задачи. Первая: идемпотентность. WB и Ozon периодически ретраят вебхуки, и без констрейнта ты получишь дубли заказов в CRM. Я ловлю 23505 (unique_violation) в ноде Postgres, маппю на ветку "уже видели" и тихо отбрасываю. Вторая: повторная обработка из DLQ не плодит дубликатов, даже если воркфлоу retry упадёт посередине и запустится заново.
Отдельный воркфлоу по расписанию вычитывает из D
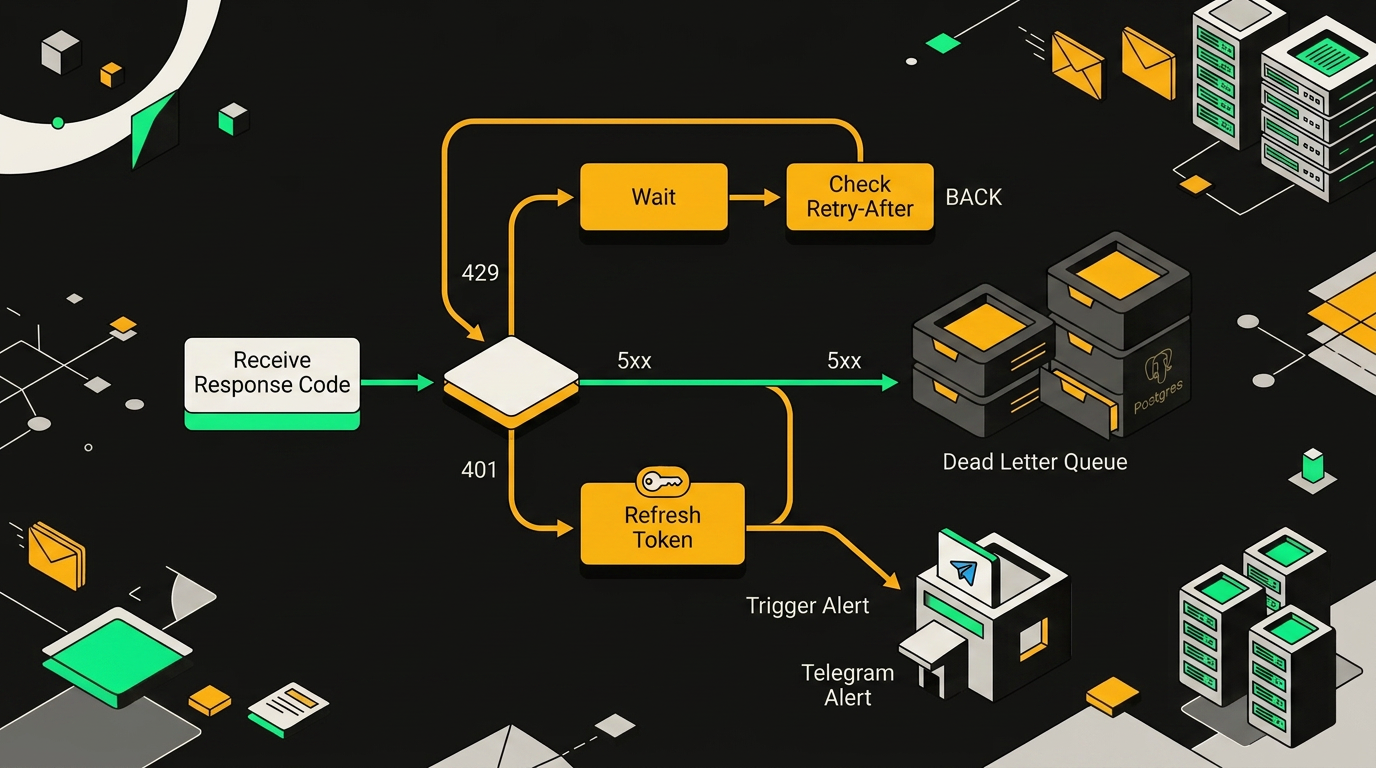
При получении кода 429 или 5xx workflow уходит в паузу с экспоненциальной задержкой и повторяет запрос до трёх раз перед записью ошибки в лог.



