

Что изменилось в WB API в 2026 году и почему это важно для автоматизации
С 1 января 2026 года Wildberries ввёл Pay-as-you-go для облачных сервисов. Если ты SaaS-платформа и делаешь запросы от имени нескольких продавцов через один токен или шлюз, теперь за каждый вызов API идёт тарификация. Это сразу ударило по сервисам типа автовыгрузки остатков и массового обновления карточек: их операционные расходы выросли, и большинство уже подняли тарифы для клиентов.
Но вот что интересно. Если ты продавец и делаешь запросы напрямую от своего имени через свой токен, платной тарификации нет. Именно здесь n8n как инструмент самостоятельной автоматизации получил неожиданное конкурентное преимущество: твои воркфлоу работают под твоим же профилем, WB не классифицирует это как облачный сервис. По отзывам продавцов, это позволяет избежать дополнительных расходов по сравнению с SaaS-решениями, хотя конкретная экономия зависит от объёма операций и выбранного сервиса.
В феврале 2026 вышло девять обновлений API одним пакетом. Главное из них практически: batch-эндпоинты для карточек товаров. Раньше массовая выгрузка или обновление 500 карточек требовали 500 отдельных запросов с паузами между ними, иначе получал 429. Теперь можно передать массив в одном вызове. Для n8n-воркфлоу это меняет архитектуру: вместо петли с HTTP-нодой на каждую карточку делаешь одну ноду с телом в виде массива и обрабатываешь ответ сразу пачкой.
Март принёс другое. WB добавил валидацию метаданных на стороне API при загрузке карточек. Раньше поля с некорректными или несуществующими значениями просто игнорировались, карточка создавалась без них, и продавец мог неделями не замечать, что характеристики не сохранились. Теперь такой запрос возвращает 422 с указанием конкретного поля. Это правильно по сути, но ломает старые скрипты: все воркфлоу, которые отправляли "грязные" данные и рассчитывали на тихое прохождение, начали падать. В n8n нужно добавить шаг предварительной проверки данных перед запросом к WB.
Отдельно по токенам. Схема авторизации через Каталог готовых решений менялась на протяжении 2025-го и получила финальный вид в начале 2026-го. Токены теперь жёстко привязаны к профилю конкретного продавца и не переносятся между кабинетами. Если ты настраиваешь автоматизацию для нескольких магазинов, каждый кабинет требует отдельный токен и отдельный набор credentials в n8n. Старые интеграции, где один токен использовался для нескольких продавцов, с марта 2026 перестали работать.
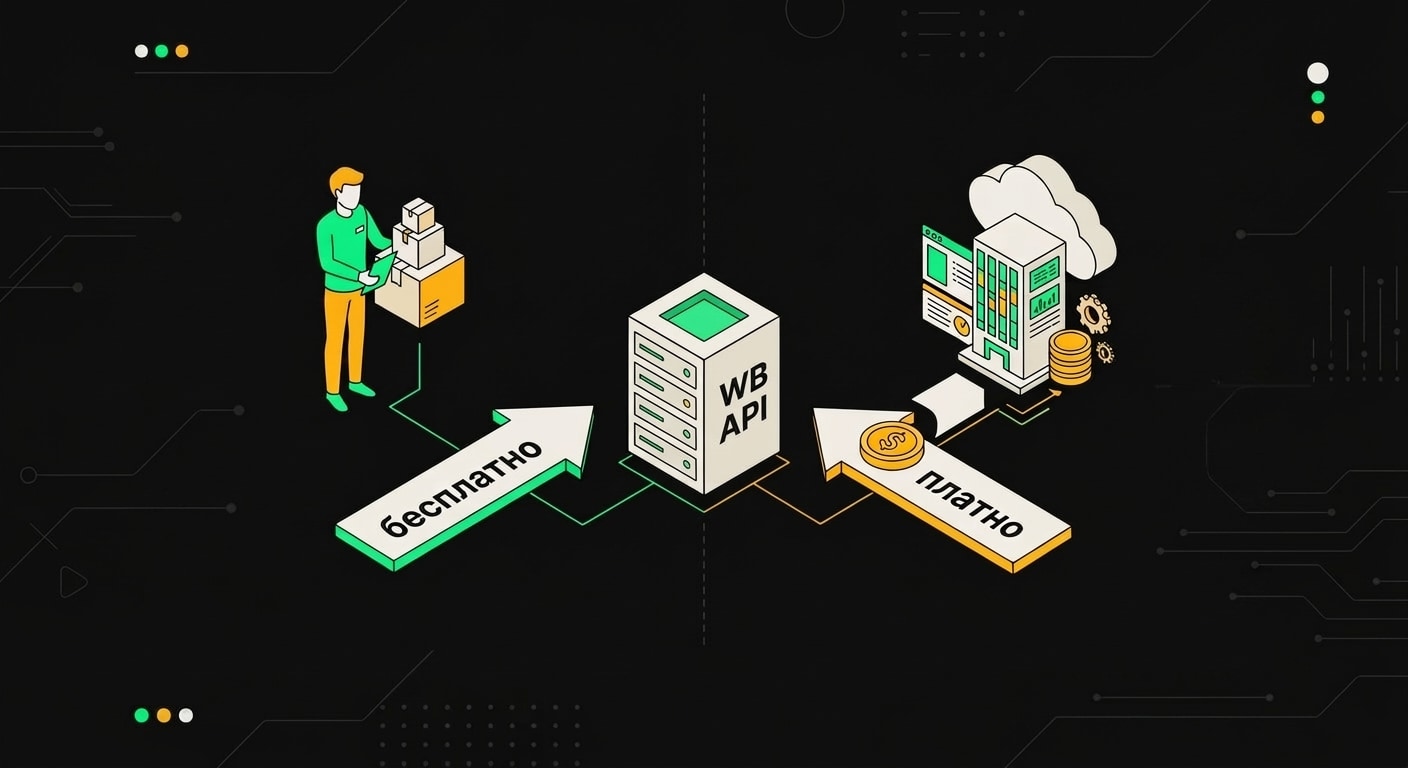
Стоимость запросов к WB API существенно различается в зависимости от типа аккаунта: продавец платит за свои товары фиксированно, а облачный сервис тарифицируется за каждый запрос к чужим карточкам.
Архитектура связки: как n8n, LLM и фотообработчик работают вместе
Вся конструкция держится на трёх независимых сервисах, которые n8n склеивает в один поток. Сам n8n не делает ничего умного: он читает данные с WB API, пихает их дальше по цепочке, собирает результаты и пишет обратно в карточку. Оркестратор без собственной логики.
Первая точка интеграции: HTTP Request node дёргает Wildberries Content API. Обычно это GET /content/v2/get/cards/list с нужными артикулами. WB отвечает довольно громоздким JSON, где вложенность доходит до 4-5 уровней. Перед тем как гнать это в LLM, структуру нужно нормализовать. Я делаю это через Code node: вытаскиваю только нужные поля (название, описание, характеристики, категорию) и собираю плоский объект. LLM не нужно знать про addin, sizes и прочий инвентарь WB.
LLM получает этот плоский объект и обогащает три поля: название, описание и SEO-теги. Для подключения в n8n есть нативные ноды: LangChain/OpenAI node если работаешь с GPT-4o или Claude 3.5, и HTTP Request если используешь локальную Mistral через Ollama. Принципиальной разницы в скорости интеграции нет, разница только в том, что LangChain node берёт на себя форматирование запроса, а с HTTP Request это делаешь руками. Я предпочитаю HTTP Request: видно ровно то, что уходит в модель.
Фотообработчик стоит отдельно. Три варианта, которые реально используются в проде:
Sharp как npm-пакет внутри Function node (n8n поддерживает кастомные пакеты), Cloudinary API через HTTP Request, или Python-сервис на Flask/FastAPI, который принимает изображение и параметры, добавляет подложку и лого, ресайзит под 900x1200 (требование WB для основного фото) и отдаёт готовый файл. Python-сервис дороже в поддержке, но если логика обработки сложная (разные шаблоны под категории, watermark с позиционированием), то это единственный адекватный вариант. Sharp хорош для простых задач: ресайз, конвертация в JPEG с нужным качеством, обрезка по центру.
Финальная нода пишет обогащённые данные обратно через POST /content/v2/cards/update. Здесь важный нюанс: WB требует передавать карточку целиком, не патч конкретного поля. То есть нормализованный объект после LLM нужно смержить обратно с оригинальным ответом API, иначе потеряешь характеристики, которые не трогал.
Весь поток выглядит так: триггер (по расписанию или webhook) -> HTTP Request к WB -> Code node нормализация -> LLM -> Code node мерж с оригиналом -> HTTP Request к фотообработчику -> HTTP Request обновление карточки. Шесть нод на базовый сценарий. Если добавить обработку ошибок и логирование, выйдет около десяти. Если тебе нужна аналогичная структура для другого маркетплейса, посмотри на автоматизацию обработки заказов в Shopify через n8n: принципы оркестрации те же.
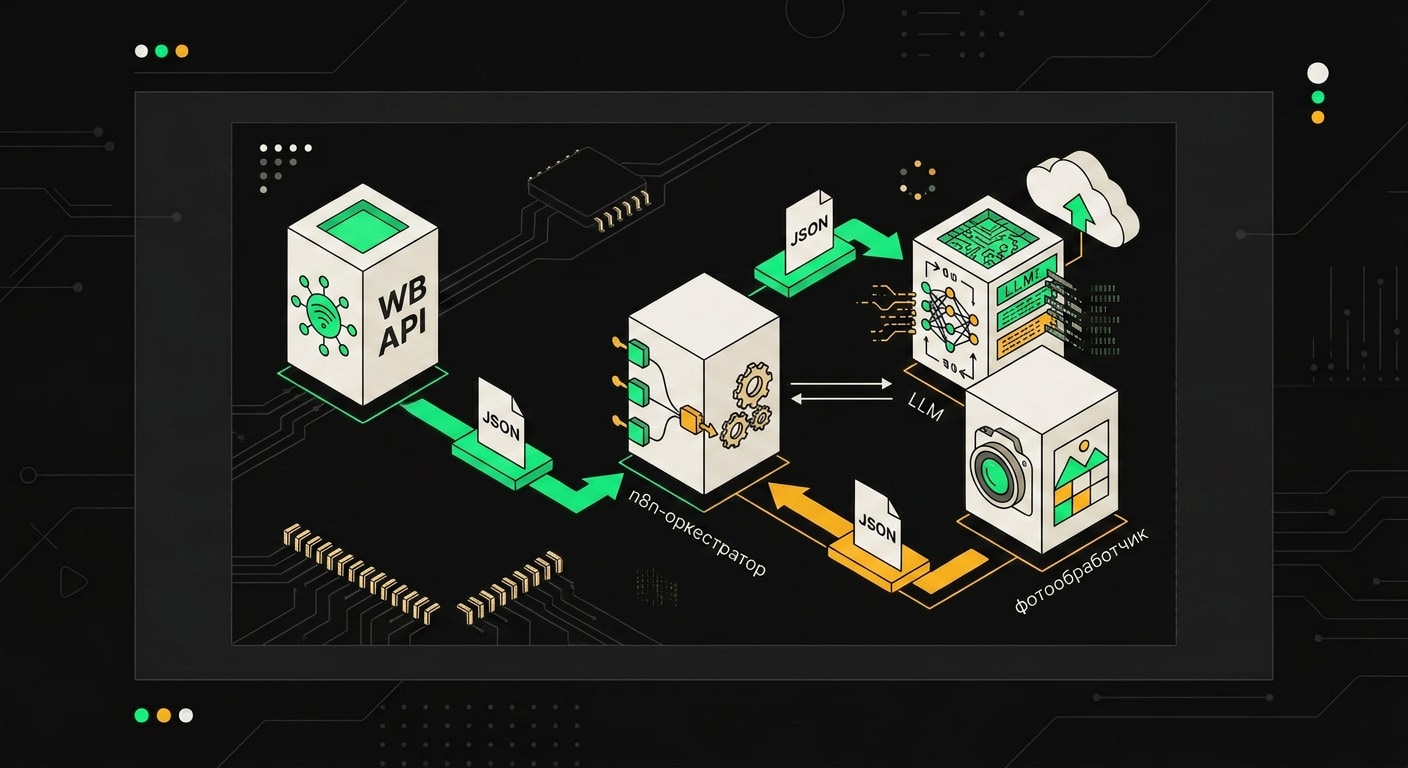
Три внешних сервиса подключаются к n8n через HTTP-узлы: WB API отдаёт данные карточки, LLM генерирует текст, а фотосервис возвращает обработанное изображение.
Парсинг карточек через WB API: выгрузка, фильтрация, нормализация
Endpoint для получения карточек один: GET /content/v2/get/cards/list. Возвращает батчи до 100 карточек за запрос, пагинация через курсор (cursor.updatedAt + cursor.nmID). Если каталог больше 500 позиций, придётся гонять несколько итераций в цикле, пока cursor.total не упадёт до нуля.
Для обогащения через LLM из ответа нужны четыре поля: title, description, characteristics и mediaFiles. С первыми двумя всё просто. А вот characteristics приходит как плоский массив объектов:
[
{ "name": "Цвет", "value": "Синий" },
{ "name": "Материал", "value": "Хлопок" }
]
В промпт такую структуру передавать неудобно: модель может перепутать порядок, добавить лишние поля или вернуть характеристики в другом виде. Гораздо надёжнее привести их к словарю заранее, прямо в n8n Code node:
// n8n Code node: нормализация характеристик
const cards = $input.all();
return cards.map(card => {
const item = card.json;
const charMap = {};
(item.characteristics || []).forEach(c => {
charMap[c.name] = c.value;
});
return { json: { ...item, charMap } };
});
После этого шага в промпт уходит уже charMap, а не сырой массив. Модели легче работать со словарём, и обратный парсинг ответа становится детерминированным.
Фильтрация перед обогащением. Гнать все карточки подряд через GPT дорого и бессмысленно. Приоритет на обработку отдаю двум категориям: карточки со статусом "Ошибки" и карточки с пустым description (пустая строка или null). В фильтре до Code node ставлю условие:
{{ $json.description === "" || $json.description === null || $json.status === "Ошибки" }}
Этот подход позволяет существенно сократить объём карточек, идущих в очередь на обогащение: в каталогах с большой долей заполненных позиций доля отсеянных может быть весьма значительной.
Про пустые строки в характеристиках. С марта 2026 WB API начал отдавать предупреждения при обратной записи (POST /content/v2/cards/update), если в characteristics есть объекты с пустым value. Раньше это просто игнорировалось. Теперь лучше чистить такие записи перед отправкой:
item.characteristics = (item.characteristics || []).filter(c => c.value !== "" && c.value != null);
Добавляю этот фильтр отдельным шагом после того, как LLM вернул обогащённые данные, но до финального HTTP Request на запись. Иначе накапливаются "тихие" предупреждения, которые потом мешают диагностике реальных ошибок схемы.
Один нюанс по mediaFiles: это массив URL, и API его не трогает при обновлении контента через /cards/update. Его можно смело тащить в контекст промпта для анализа изображений, но в payload на запись не включать.
Кстати, про форматы данных при синхронизации с несколькими маркетплейсами сразу: шпаргалка по форматам цен, остатков и SKU при синхронизации Ozon, WB и Яндекс.Маркета поможет не запутаться в различиях между площадками.
Промпты для LLM: что работает при обогащении товарных карточек
Самая частая ошибка при работе с LLM в пайплайне обогащения данных: от модели ждут магии, а дают ей мусор. Если промпт размытый, вывод будет размытым. Принцип мусор-на-входе здесь работает жёстче, чем в любом классическом ML.
Начну с базового правила. Инструкционные промпты с жёсткими ограничениями дают более стабильный результат, чем "свободные" запросы. Конкретно: "Напиши описание товара длиной 200-250 слов, используй ключевые слова из списка, не добавляй несуществующих характеристик" работает надёжнее, чем "Опиши этот товар хорошо". Модели лучше держат ограничения, когда они числовые и явные.
Второй момент: контекст надо беречь. Передавай в промпт только то, что реально нужно. Название, категория, характеристики из твоего charMap и 3-5 целевых ключевых слов. Всё. Если лить в промпт весь объект товара с 40 полями, модель начинает "галлюцинировать" связи между несвязанными атрибутами, а стоимость запроса растёт без пользы.
Для генерации SEO-тегов хорошо работает few-shot с двумя примерами. Берёшь теги из топа выдачи WB по нужной категории и вставляешь прямо в промпт как образец. Два примера достаточно: больше тяжелее контекст, меньше модель не всегда улавливает паттерн.
Отдельный момент про конкурентов. Исследование Nova Sapiens (январь 2026) показало: если в промпте упомянуть конкретный бренд конкурента, LLM переключается в режим социальной вежливости и занижает оценку характеристик. Фактически модель начинает "дипломатничать". Решение простое: передавай анонимизированные характеристики без брендов. Не "у Nike подошва 30мм", а "у конкурента А подошва 30мм" или просто числовые значения без атрибуции.
Самое важное в проде: структурируй вывод через JSON Schema. Просить LLM вернуть строгий объект { title, description, tags[] } надёжнее любого парсинга свободного текста. Вот как выглядит системный промпт, который я использую как отправную точку:
// Пример системного промпта для обогащения карточки
const systemPrompt = `Ты SEO-копирайтер для маркетплейса Wildberries.
Верни JSON строго такого формата:
{"title": string, "description": string, "tags": string[]}
Правила:
- title до 60 символов
- description 200-250 слов, без воды
- tags: 5-7 фраз, каждая 2-4 слова
- Не придумывай характеристики, которых нет в данных`;
После генерации обязательно проверяй длину title до записи. WB режет заголовки длиннее 60 символов без предупреждения, и ты об этом не узнаешь из API-ответа. Добавь простую валидацию:
if (result.title.length > 60) {
throw new Error(`Title overflow: ${result.title.length} chars`);
}
Пять минут на такую проверку экономят часы отладки, когда ты потом не можешь понять, почему карточки в каталоге выглядят обрезанными. Похожий подход к промптам и валидации LLM-вывода разобран в туториале про AI-агента для интернет-магазина БАДов на n8n и GPT-4o: там тот же принцип структурированного вывода через схему.
Автоматическая фотообработка: требования WB и инструменты
Wildberries принимает основное фото от 900x1200 пикселей, JPG или PNG, с белым или светло-серым фоном. Это жёсткое требование: если фон другой, карточка либо не пройдёт модерацию, либо выглядит хуже в выдаче. Для второго и третьего фото (инфографика) ограничений по фону нет, но разрешение то же.
Загрузка идёт через POST /content/v3/media/save. Перед этим файл должен весить меньше 2 MB и быть корректно именован. Казалось бы, мелочь, но на масштабе в несколько сотен SKU ручная обработка превращается в несколько рабочих дней.
Sharp vs Cloudinary
Для команд с DevOps ресурсом я рекомендую Sharp на Node.js. Библиотека встраивается в n8n через Code node или выносится в отдельный микросервис буквально за полчаса. Типичный пайплайн выглядит так:
- Скачать оригинальное фото (HTTP Request node).
- Ресайзить до 900x1200, Sharp по умолчанию сохраняет пропорции через
fit: 'contain'с заливкой фона. - Наложить подложку бренда через
composite(). - Сжать до нужного веса через
jpeg({ quality: 82 })или подбором качества в цикле. - Загрузить бинарник на WB.
Cloudinary удобен, если DevOps нет совсем. Transformation URL формируется динамически прямо в n8n через простой HTTP Request: w_900,h_1200,c_pad,b_white,l_logo/q_auto. Платишь за трансформации, но зато не надо держать ни одного сервиса. На объёме до 5000 трансформаций в месяц это укладывается в бесплатный план. При больших объёмах и активной загрузке стоит заранее посчитать расход кредитов: конкретные цифры зависят от применяемых трансформаций и текущих условий тарифа.
Инфографика через Puppeteer
Второе и третье фото чаще всего несут характеристики: состав, размеры, UTP. Генерировать их в PIL или Pillow медленно и неудобно, особенно когда дизайн меняется. Puppeteer решает это чище: рендеришь HTML-шаблон с переменными товара, делаешь скриншот конкретного DOM-элемента в PNG нужного разрешения.
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setViewport({ width: 900, height: 1200 });
await page.setContent(htmlTemplate(productData));
const element = await page.$('#card');
await element.screenshot({ path: 'infographic.png' });
Шаблон правит дизайнер в обычном HTML/CSS. Разработчик только пробрасывает данные. На практике это сокращает итерацию по дизайну с нескольких часов до 15 минут. Puppeteer запускается как отдельный микросервис и вызывается из n8n через HTTP Request node, так же как и Sharp.
Весь цикл от оригинала до готового файла на WB занимает 10-20 секунд на один SKU. Для батча из 200 позиций это около 30-40 минут против нескольких дней ручной работы.
Оригинальное фото проходит через четыре шага: скачивание, передачу в API фотосервиса, наложение фона и загрузку готового изображения обратно в карточку WB.
Сборка рабочего флоу в n8n: пошаговая структура
Флоу запускается двумя способами. Первый: Schedule Trigger раз в сутки в ночное окно (я ставлю 03:00, когда API Wildberries меньше нагружен). Второй: Webhook, который CRM дёргает при добавлении нового товара в каталог. В обоих случаях дальше идёт одна и та же цепочка нод.
Нода 1: получаем список карточек. HTTP Request, метод GET, endpoint /content/v2/get/cards/list. В параметрах фильтрую по updatedAt: беру только карточки, которые не обновлялись больше 30 дней. Смысл в том, чтобы не перезаписывать свежеотредактированные тексты и не тратить токены на карточки, которые кто-то уже поправил вручную.
Нода 2: нормализация charMap. Code node на JavaScript. Wildberries отдаёт характеристики в структуре charMap, где ключи могут приходить в разной кодировке и с лишними пробелами. Этот шаг описан подробнее в секции про парсинг, здесь просто запускаю ту же функцию нормализации и получаю чистый объект, готовый к вставке в промпт.
Нода 3: генерация текстов. OpenAI node. System prompt фиксирован: там инструкция по стилю, ограничения на длину title (до 60 символов) и description (до 1000 символов), требование включить ключевые характеристики из charMap. User message собирается динамически из нормализованных данных предыдущей ноды. На выходе подключаю Output Parser с JSON Schema: модель обязана вернуть объект с полями title, description и keyWords. Без схемы GPT-4o иногда добавлял в ответ пояснения свободным текстом, что ломало следующий шаг.
Нода 4: проверка перед записью. IF node с двумя условиями: длина title не больше 60 символов, и все три обязательных поля присутствуют и не пустые. Если условие не выполнено, ветка "false" ведёт сразу в Error workflow. Это спасло меня от ситуации, когда модель возвращала title в 80 символов и API принимал обновление, но Wildberries молча обрезал текст, и карточка выглядела оборванной.
Нода 5: записываем обогащённые тексты. HTTP Request, метод POST, endpoint /content/v3/cards/update. Тело запроса собирается из nmID оригинальной карточки и новых полей из ноды 3. Аутентификация через Header Auth с токеном из Credentials.
Нода 6: обновление фото. Сначала HTTP Request к внутреннему фотосервису (или S3, зависит от инфраструктуры): получаю бинарный файл изображения. Затем POST на /content/v3/media/save с multipart/form-data. Эту ноду ставлю последней, потому что фото обновляется реже, чем тексты, и при ошибке не хочу блокировать запись основного контента.
Error workflow. При статусе ответа 422 (Wildberries возвращает его на невалидные данные) основной флоу передаёт управление отдельному workflow. Тот пишет строку в Google Sheets: nmID, текст ошибки из тела ответа, timestamp. Менеджер утром открывает таблицу и видит конкретные карточки для ручной проверки. Никаких Slack-нотификаций с длинными JSON в сообщении. Таблица работает лучше: можно фильтровать, добавлять комментарии, отмечать как исправленное.
Весь флоу от триггера до записи занимает около 8-12 секунд на одну карточку. При пакете в 200 карточек с учётом rate limit Wildberries (300 запросов в минуту) это укладывается в 15-20 минут ночного окна. Готовые шаблоны флоу для e-commerce задач собраны в обзоре 12 n8n-шаблонов для e-commerce: там разобрано, что берут как основу, а что переписывают с нуля.
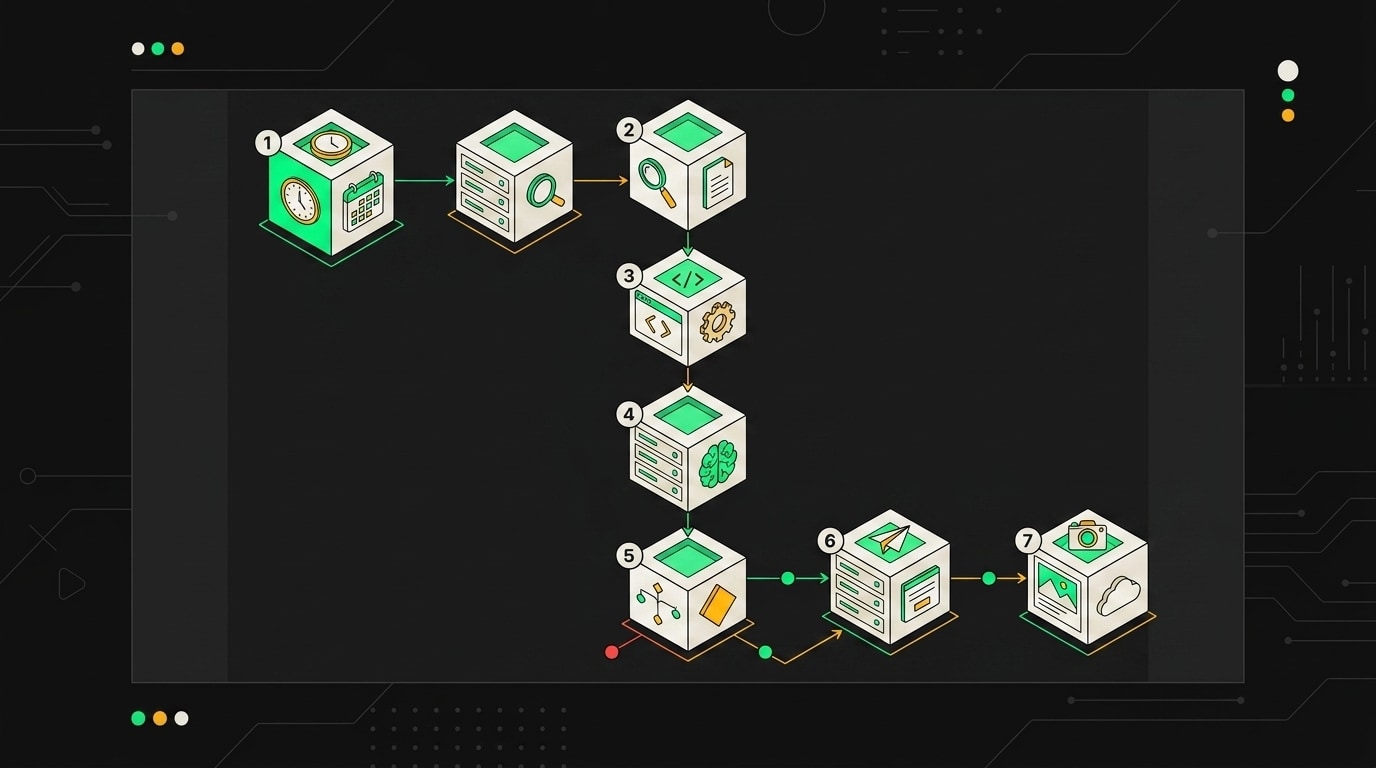
Флоу содержит 14 узлов и запускается по расписанию раз в час, последовательно обрабатывая карточки без описания из очереди в Google Sheets.
Обогащение характеристик: заполнение пустых полей через LLM и справочники WB
Самая распространённая проблема при массовой загрузке карточек: поля заполнены на 40-60%, и WB занижает карточку в поиске. В категориях с большим числом обязательных характеристик вроде "Одежды" пробелы накапливаются быстро. Вручную это часами, но автоматизировать тоже не так очевидно, как кажется.
Точка входа в справочник значений: GET /content/v2/object/characteristics/{subjectId}. Передаёшь идентификатор предметной группы, получаешь JSON с допустимыми значениями для каждой характеристики. Это именно то, что нужно перед тем, как что-то генерировать.
Ключевой приём: не спрашивай LLM "какой тип воротника у этой куртки?". Передавай в промпт готовый список допустимых значений:
Выбери подходящее значение из списка: ["Воротник-стойка", "Отложной воротник", "Капюшон", "Без воротника"].
Описание товара: {description}
Это полностью убирает галлюцинации на перечислимых полях. Модель выбирает из предложенных вариантов, а не придумывает "Шалевый воротник с подкладкой" которого нет в системе WB и который просто упадёт с ошибкой валидации.
Но вот где LLM трогать нельзя: числовые поля. Вес, габариты, размерные значения. Модели на таких полях ошибаются, причём уверенно, с единицами измерения. Числовые данные бери из ERP или 1C напрямую, через маппинг по артикулу. Если источника нет, ставь заглушку и флаг "требует ручной проверки" в своём трекере задач.
"Страна производства" отдельная история. Пытаться вывести её из описания через LLM рискованно: ошибки здесь создают юридические и логистические несоответствия. Хардкодь значение в шаблоне флоу на уровне конфигурации поставщика. Один раз настроил, забыл



