

Почему ручная обработка возвратов больше не работает
С 1 февраля 2026 года п. 4 ст. 24 ЗоЗПП обязал ритейлеров компенсировать разницу в цене на технически сложные товары при возврате. Это не просто новая строчка в законе. Это дополнительный расчёт к каждому кейсу: нужно сверить цену покупки с текущей ценой, зафиксировать разницу, провести выплату. Вручную, при потоке в несколько сотен заявок в месяц, это начинает ломать операционку.
Посмотрим на проблему шире. Ручная обработка возврата требует времени оператора на классификацию, проверку, ответ покупателю и маршрутизацию внутри компании. В fashion доля возвратов достигает 30-40% от заказов. В электронике меньше, 8-12%, но там как раз живёт злополучный п. 4 ст. 24 с ценовой компенсацией. На большом потоке это превращается в серьёзную операционную нагрузку.
Но стоимость обработки это ещё не главная проблема. Главная: поток заявок размазан по десяти каналам одновременно. Wildberries API кидает статусы возвратов в одно место. Ozon пишет в другое. Email со сканом чека приходит на третий ящик. Покупатель параллельно пишет в Telegram-бот магазина. Иногда одна и та же проблема прилетает из трёх источников сразу, и оператор тратит 20 минут, чтобы понять: это три разных человека или один настойчивый?
Отзывы и заявки на возврат при этом мешаются в одном потоке. "Товар пришёл сломанный, верните деньги" выглядит как отзыв, но это заявка с юридическими последствиями. "Оформляю возврат" без деталей не скажет оператору ничего, пока тот не откроет историю заказов в трёх разных системах.
Значительная часть обращений относится к шаблонным сценариям с известными ответами: "Как оформить возврат?", "Когда придут деньги?", "Что делать, если товар пришёл без коробки?" Но они падают вперемешку со сложными кейсами, и оператор разбирает всё подряд, по очереди.
Ручной подход работал, когда возвратов было мало и все они приходили через одну форму. Сейчас это не тот масштаб и не та структура данных.

Когда один оператор одновременно закрывает чат, звонок и почту, качество каждого канала падает быстрее, чем растёт нагрузка.
Что именно автоматизируем: карта процесса
Прежде чем писать код или выбирать инструменты, я всегда рисую карту процесса буквально на бумаге. Иначе автоматизируешь хаос и получаешь автоматизированный хаос.
Вот как выглядит полный цикл обработки возвратов в типичном интернет-магазине, который торгует на нескольких площадках одновременно.
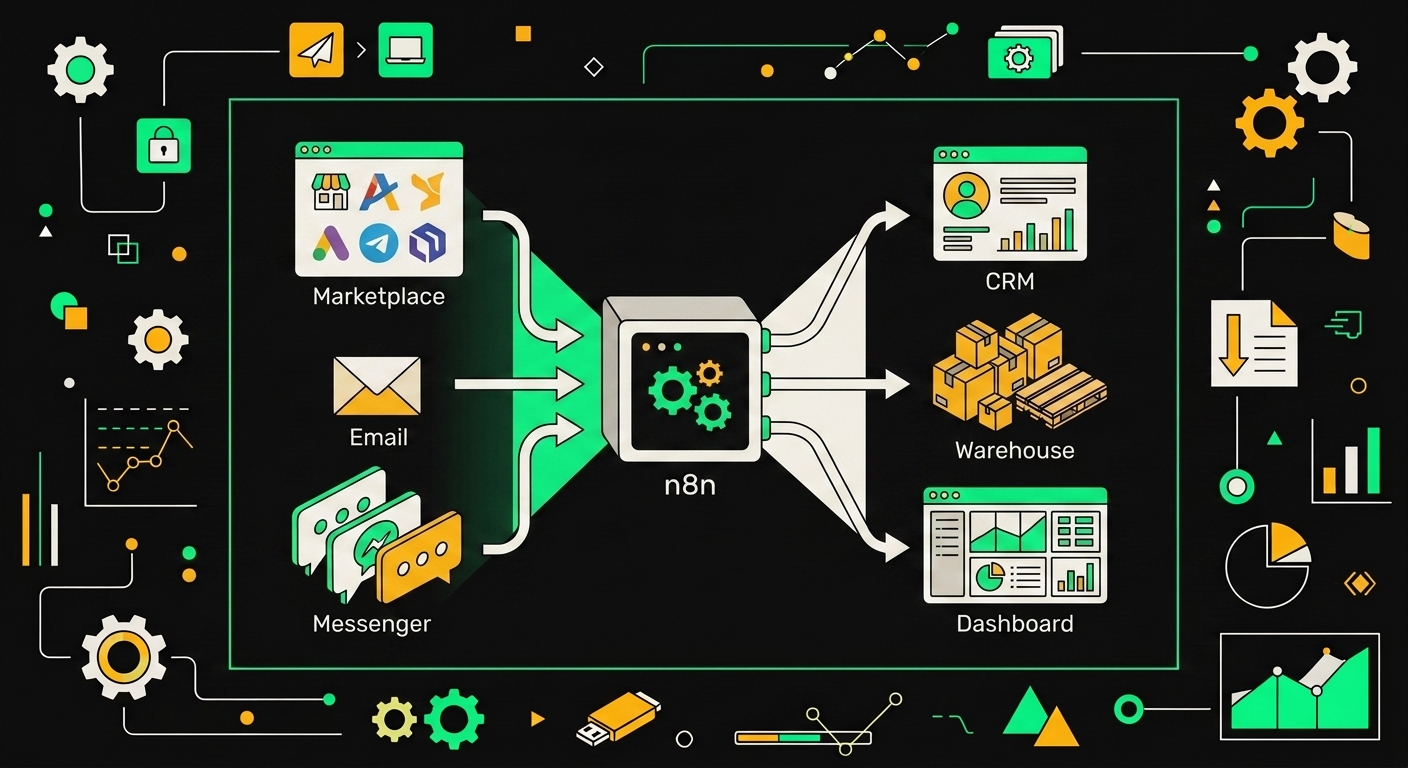
Слой 1. Сбор обращений
Обращения прилетают отовсюду, и это главная боль. Ozon Seller API отдаёт заявки на возврат через соответствующие эндпоинты FBS, WB работает через свой Marketplace API с похожей структурой, но другими статусами и другой логикой дедлайнов. Почта на IMAP-сервере собирает письма от клиентов, которые пишут напрямую. Веб-форма на сайте генерирует POST-запросы в очередь. Telegram-бот и WhatsApp через Business API добавляют ещё два потока.
Задача первого слоя: притащить всё это в единую очередь с единой схемой данных. Я обычно использую Redis Streams или RabbitMQ как шину. Каждое обращение нормализуется в один формат: источник, ID клиента, ID заказа, текст, вложения, timestamp.
Слой 2. AI-классификация
Вот где начинается интересное. Нормализованное обращение уходит в классификатор, который одновременно определяет несколько независимых атрибутов.
Тип: возврат, обмен, жалоба без возврата, нейтральный отзыв. Причина: брак производителя, брак при доставке, не подошёл размер, товар не соответствует описанию, просто передумал. Тональность: спокойная, раздражённая, агрессивная. Срочность: есть дедлайн по правилам площадки, клиент угрожает жалобой в Роспотребнадзор, стандартный кейс.
Для этого я делаю один вызов к LLM с JSON-схемой на выходе. GPT-4o и Claude 3.5 Sonnet оба справляются хорошо. Пограничные случаи, где модель не уверена (низкий confidence score), сразу идут на ручную разметку.
Слой 3. Маршрутизация
По результатам классификации срабатывает дерево решений. Простые кейсы автоодобряются без участия человека: клиент возвращает товар небольшой стоимости, причина "не подошёл размер", тональность спокойная, первый возврат за 90 дней. Доля таких кейсов зависит от специфики конкретного магазина.
Сложные кейсы эскалируются. Юрист получает задачу, если сумма выше установленного порога или клиент упоминает судебное разбирательство. Старший менеджер подключается при агрессивной тональности или повторном обращении по одному заказу. Пороги в деньгах надо калибровать под каждый бизнес отдельно.
Слой 4. Исполнение
Одобренный кейс запускает цепочку действий параллельно. Генерируется и отправляется ответ клиенту, текст которого подбирается под тональность: сухой и чёткий для спокойных, более тёплый для раздражённых. Через API площадки инициируется возврат средств. CRM обновляется с новым статусом и причиной. Складская система получает сигнал о предстоящей приёмке товара обратно.
Слой 5. Аналитика
Каждый обработанный кейс пишет запись в аналитическую базу. Дашборд показывает динамику по причинам возвратов в разрезе категорий товаров, поставщиков, площадок. Именно отсюда вылезают неочевидные вещи: например, что конкретный поставщик даёт непропорционально высокий процент брака по сравнению со средним по категории.
Это уже не про автоматизацию поддержки. Это про управление качеством ассортимента, которое бизнес получает как побочный продукт.
Воронка показывает, на каком шаге теряется больше всего заявок и где автоматизация даёт максимальный прирост скорости.
Архитектура связки n8n + LLM: конкретные узлы
Скелет workflow я собираю из четырёх слоёв: вход, нормализация, LLM-классификация, маршрутизация и запись. Каждый слой решает одну задачу, и это критично, потому что иначе при отладке вы будете лазить по портянке из 40 узлов и искать, где LLM получил кривой JSON.
Триггеры. Под Ozon и Wildberries вешаю Webhook-узлы на callback'и о возвратах и претензиях. Почта идёт через IMAP Trigger, чат поддержки через Telegram Trigger, плюс Schedule раз в 15 минут добивает то, что прилетело без вебхуков (например, новые тикеты в личном кабинете маркетплейса, где пуша нет вообще).
Нормализация. Тут узел Code на JS, и он спасает всё остальное. Задача простая: на выходе должен быть единый объект, на который можно натравить LLM-промпт без условий "если это ozon, то посмотри сюда, а если почта, то туда". Если вы строите n8n-воркфлоу для работы с маркетплейсами, эта схема нормализации переиспользуется практически без изменений.
// Узел Code в n8n: нормализация входящего обращения
const raw = $input.item.json;
const source = $input.item.json.source;
let normalized = {
external_id: null,
order_id: null,
customer: { id: null, name: null, email: null },
text: '',
attachments: [],
channel: source,
received_at: new Date().toISOString()
};
if (source === 'ozon') {
normalized.external_id = raw.posting_number;
normalized.order_id = raw.posting_number;
normalized.text = raw.return_reason + '. ' + (raw.comment || '');
normalized.customer.id = raw.customer_id;
} else if (source === 'email') {
normalized.external_id = raw.messageId;
normalized.text = raw.text;
normalized.customer.email = raw.from;
normalized.attachments = raw.attachments || [];
}
return { json: normalized };
В реальном проекте сюда же добавляю ветку для WB (raw.srid как external_id), Telegram (raw.message.from.id) и фолбэк, который просто складывает всё сырьё в text и помечает channel: 'unknown'. Ничего не должно теряться, даже если интеграция отвалилась.
AI-узел. Использую либо нативную ноду OpenAI/Anthropic, либо HTTP Request, если нужно дёргать YandexGPT или GigaChat (нативных нод под них на май 2026 в community-наборе всё ещё нет в стабильном виде). Принципиальный момент: structured output. Промпт требует от модели вернуть строго JSON вида {category, confidence, legal_flag, suggested_action, reasoning}. У OpenAI это response_format: json_schema, у Anthropic я просто валидирую через Ajv в следующем Code-узле и при ошибке отправляю на повтор с температурой 0.
Категории, которые я выделяю под маркетплейсы: auto_return (брак очевиден, товар вернули в товарном виде в 14 дней), manual_review (спорный износ, фото нечёткое, претензия по комплектации), legal_case (технически сложный товар, истёк период простого возврата по статье 25, требуется проверка по статье 18, или клиент ссылается на статью 24 о замене на аналогичный). Для последней категории confidence у LLM почти всегда занижен, и это ОК, дальше всё равно человек.
Switch и ветки. Switch-узел смотрит на category и confidence. Порог я держу на 0.85: ниже него любой кейс уезжает в manual_review, даже если модель уверенно классифицировала как автовозврат. Дешевле перепроверить руками, чем оформить возврат на 40 тысяч рублей по галлюцинации.
- Ветка
auto_return: HTTP-запрос к API маркетплейса на подтверждение возврата, шаблонный ответ клиенту через тот же канал, запись в Bitrix24 со статусом "закрыто автоматически". - Ветка
manual_review: создание сделки в AmoCRM с тегом и саммари от LLM в комментарии, уведомление оператору в Telegram. - Ветка
legal_case: то же, что manual_review, плюс копия юристу и блокировка любых автоматических ответов клиенту до ручного апрува.
Аудит. Каждый прогон я пишу в PostgreSQL: исходный JSON, нормализованный JSON, ответ LLM, выбранная ветка, итоговое действие. Это нужно для двух вещей. Первая, разбор инцидентов когда клиент пишет "почему мне отказали". Вторая, датасет для дообучения промпта или замены модели. На накопленной выборке можно честно сравнить, например, GPT-4.1 mini против Claude Haiku 4 по точности классификации legal_case, а не гадать по двум примерам.
Google Sheets как хранилище аудита тоже работает, но после 50 тысяч строк начинает тормозить и API упирается в квоту. Если объёмы выше 200 обращений в день, сразу Postgres.
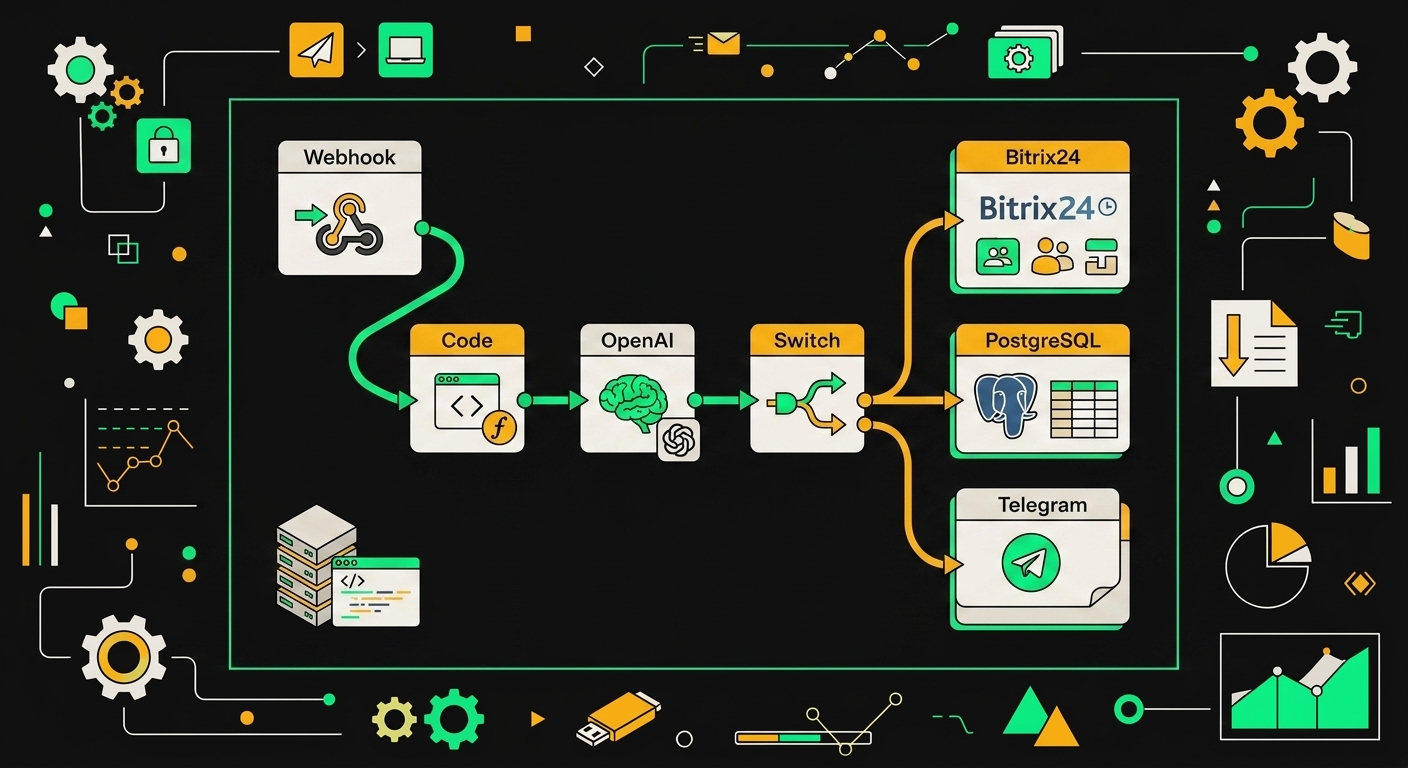
Каждый узел n8n отвечает за одну операцию: так сценарий остаётся читаемым и легко меняется без переписывания всего потока.
AI-классификатор: промпт, который реально работает
Первое, что я выкинул из старой версии, это парсинг свободного текста регулярками. На 1000 обращений в день получалось около 150 поломок: модель то добавит лишний абзац вежливости, то переименует поле, то вернёт массив вместо объекта. Переход на structured output через response_format: json_schema резко поднял стабильность. Оставшиеся сбои это таймауты и переполнение контекста, не формат.
Схему я делаю максимально жёсткой. Никаких "string" с описанием в духе "категория обращения", только enum. Шесть полей, ничего лишнего:
type: return, exchange, complaint, review, questionreason_code: defect, size, description_mismatch, changed_mind, delivery_damage, othersentiment: число от -1 до 1urgency: low, medium, highis_technically_complex: booleansummary: одна строка, до 200 символов
Поле is_technically_complex это отдельная история. Если оно true, обращение уходит в ветку, где промпт уже знает про статьи 18 и 24 ЗоЗПП в редакции 2026 года (последние правки про сроки проверки качества и про дистанционную продажу технически сложных товаров). Холодильник со сколом на дверце и ноутбук с битым пикселем юридически разные ситуации, и ответ менеджера должен это учитывать. Без флага модель регулярно путала 14 дней с 15 днями и ссылалась на устаревшую редакцию.
Few-shot примеры. Это та часть, на которой большинство экономит и зря. Я взял 6 реальных обращений из бэклога: возврат с дефектом, обмен по размеру, жалоба на курьера, нейтральный отзыв, вопрос про совместимость, отказ от заказа в пути. Реальные тексты с реальной орфографией работают заметно лучше синтетических примеров. Это закономерно: модель видит живой язык покупателей, а не причёсанные шаблоны.
Температура 0.1, иногда 0.2 если хочется чуть более терпимого парсинга кривой грамматики. Выше не ставлю никогда. Креативность здесь враг, классификатор должен быть скучным.
Сам HTTP-запрос в n8n выглядит так:
{
"model": "gpt-4o-mini",
"temperature": 0.1,
"messages": [
{"role": "system", "content": "Ты классификатор обращений интернет-магазина электроники. Отвечай только JSON по схеме."},
{"role": "user", "content": "{{ $json.text }}"}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "ticket_classification",
"strict": true,
"schema": {
"type": "object",
"properties": {
"type": {"enum": ["return","exchange","complaint","review","question"]},
"reason_code": {"enum": ["defect","size","description_mismatch","changed_mind","delivery_damage","other"]},
"sentiment": {"type": "number"},
"urgency": {"enum": ["low","medium","high"]},
"is_technically_complex": {"type": "boolean"},
"summary": {"type": "string"}
},
"required": ["type","reason_code","sentiment","urgency","is_technically_complex","summary"],
"additionalProperties": false
}
}
}
}
Обратите внимание на "strict": true. Без него OpenAI иногда позволяет себе вольности в редких случаях, с ним валидация на их стороне отрубает невалидный JSON ещё до того, как он попадёт ко мне. На gpt-4o-mini один такой запрос обходится в районе $0.0002, то есть 1000 обращений это 20 центов. Дешевле, чем кофе оператору, который раньше руками раскидывал тикеты по очередям.
Логика автоодобрения и эскалации
Каждый входящий возврат проходит через цепочку условий, прежде чем попасть к оператору или уйти в автоответ. Цепочка линейная, без ветвлений назад.
Автоодобрение срабатывает, если одновременно выполняются четыре условия: type=return, reason_code в списке [size, changed_mind], сумма заказа ниже порогового значения (пример порога: 15 000 руб., но под каждый бизнес нужно считать отдельно), флаг is_technically_complex=false и с момента покупки прошло меньше 14 дней. Все четыре, не три. Если хоть одно не выполнено, заявка идёт дальше по дереву.
Конкретная доля автоодобряемых заявок зависит от ассортимента и площадок. В сегментах с высокой долей одежды и аксессуаров она будет выше, в электронике ниже. AI просто генерирует письмо клиенту с инструкцией по возврату и закрывает тикет.
Полуавтомат подключается, когда условия автоодобрения не выполнены, но и флагов обязательной эскалации тоже нет. AI готовит черновик: предлагаемое решение, текст ответа клиенту, ссылку на статью закона если нужно. Оператор видит это в Telegram-боте или внутреннем дашборде и жмёт "Подтвердить" или правит текст вручную. Это быстрее, чем ручная обработка с нуля.
Обязательная передача юристу происходит в трёх случаях. Первый: is_technically_complex=true плюс reason_code=defect. Это бытовая техника, смартфоны, всё что требует экспертизы по качеству. Второй: повторный возврат того же SKU от того же клиента, даже если товар простой. Третий: в тексте заявки система нашла упоминание Роспотребнадзора, суда, "права потребителя" в контексте угрозы. Классификатор на этом обучен отдельно, потому что формулировки бывают косвенными: "обращусь куда следует", "знаю свои права" и подобное.
По срокам: после поправок в законодательство о защите прав потребителей, вступивших в силу в 2025 году, окно ответа на письменную претензию стало жёстче в части фиксации даты получения. Система ставит автонапоминание оператору и юристу за 2 дня до дедлайна. Не уведомление на почту, а пуш в Telegram с кнопкой "Взял в работу". Если никто не нажал в течение 4 часов, напоминание уходит руководителю.
Каждое решение логируется в двух полях: ai_decision и human_final_decision. Это нужно для двух вещей. Аудит по запросу юриста или регулятора: видно, кто и когда принял решение, автомат или человек. И дообучение модели: расхождение между ai_decision и human_final_decision копится в отдельный датасет, который раз в квартал идёт на файнтюнинг. Без этого логирования система через полгода деградирует, потому что теряет обратную связь о своих ошибках.
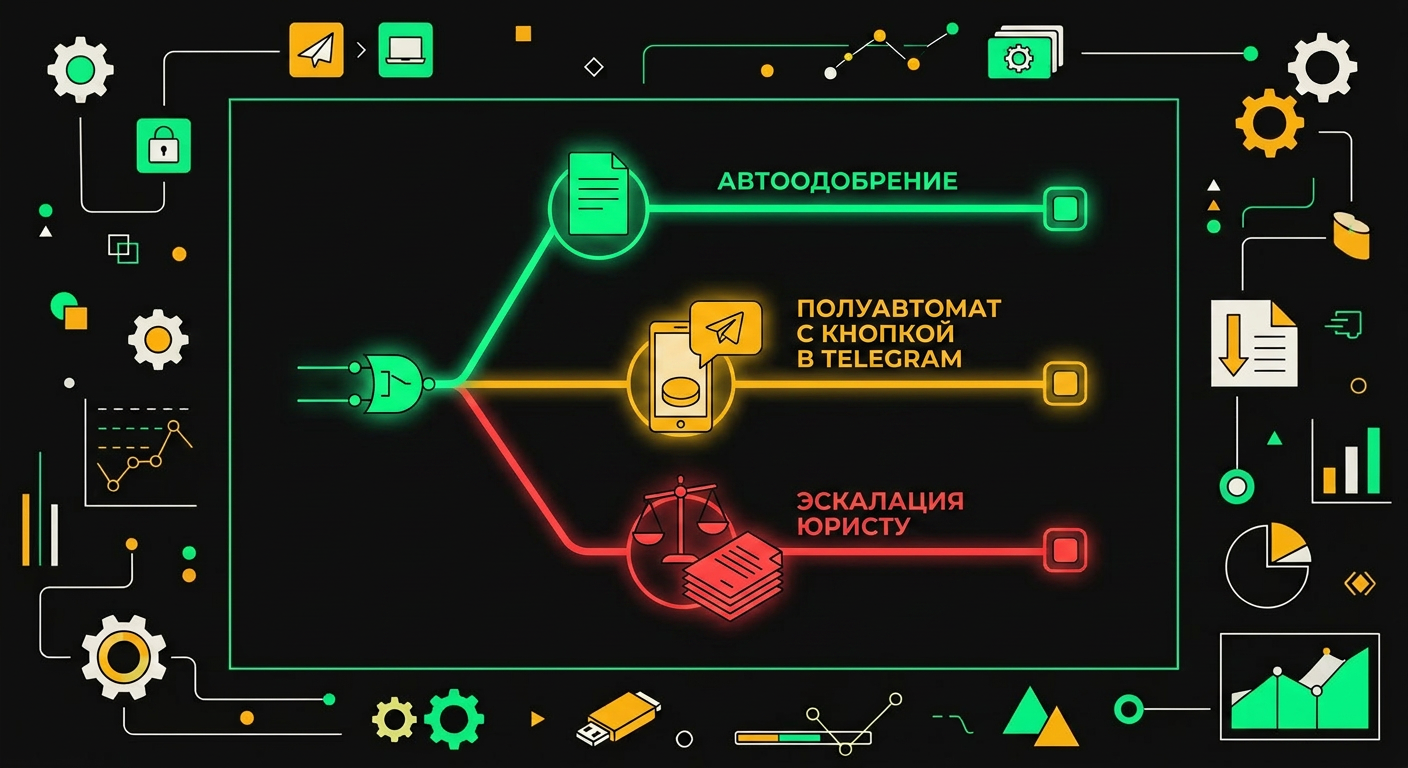
Дерево разбирает обращение по четырём критериям и направляет его к нужному специалисту ещё до того, как оператор открыл тикет.
Учёт изменений ЗоЗПП от февраля 2026
В феврале 2026 года вступили в силу поправки, которые заметно осложнили жизнь тем, кто обрабатывает претензии по технически сложным товарам. Главное изменение: п. 4 ст. 24 теперь прямо закрепляет право потребителя требовать разницы между ценой покупки и текущей рыночной ценой аналога. Раньше этот момент был предметом споров, теперь он закреплён в законе, и воркфлоу обязан уметь это считать.
Первое, что нужно сделать: подтягивать актуальную цену из каталога в момент обработки обращения. Я делаю это через HTTP-запрос к внутреннему API каталога прямо в n8n, до того как запрос уходит в языковую модель. Модель получает уже готовые цифры: цена покупки из заказа, текущая цена из каталога, разница. Дальше AI только вставляет их в расчёт. Логика разницы цен не должна жить внутри промпта.
С неустойкой отдельная история. Поправки ввели ограничение максимального размера, и тут AI-узел должен знать этот потолок и проверять рассчитанную сумму перед включением в черновик ответа. Я храню предельное значение как переменную окружения в n8n, обновляю вручную при изменениях. Можно вынести в таблицу конфигурации, но для одного параметра это избыточно.
Справочник технически сложных товаров храню отдельно: таблица в PostgreSQL, список SKU и категорий, которые под него подпадают. Перед тем как передать обращение в AI-узел, n8n делает lookup по артикулу из заказа и добавляет в контекст флаг is_technically_complex: true/false. Это надёжнее, чем просить модель самостоятельно определять, сложный товар или нет: категории размытые, и галлюцинации здесь стоят дорого.
Срок предъявления требования о разнице цен и пакет документов отличаются от обычного возврата. Поэтому у меня два отдельных шаблона: один для стандартного возврата, второй для случаев с разницей цен. Шаблон подбирается на основе того же флага и даты обращения: n8n проверяет, укладывается ли потребитель в срок, и выбирает нужную ветку. AI получает уже конкретный шаблон и заполняет его данными, а не генерирует ответ с нуля.
И последнее, без чего всё это теряет смысл: каждое решение по возврату технически сложного товара фиксируется в БД с явной ссылкой на норму закона. Поле legal_basis содержит строку вида "п. 4 ст. 24 ЗоЗПП (ред. 02.2026)". Когда через полгода придёт жалоба в Роспотребнадзор или начнётся судебный спор, вы поднимете запись и увидите, на каком основании и с какими ценами было принято решение. Без этого поля история обращений превращается в кучу текста, из которой ничего не восстановить.
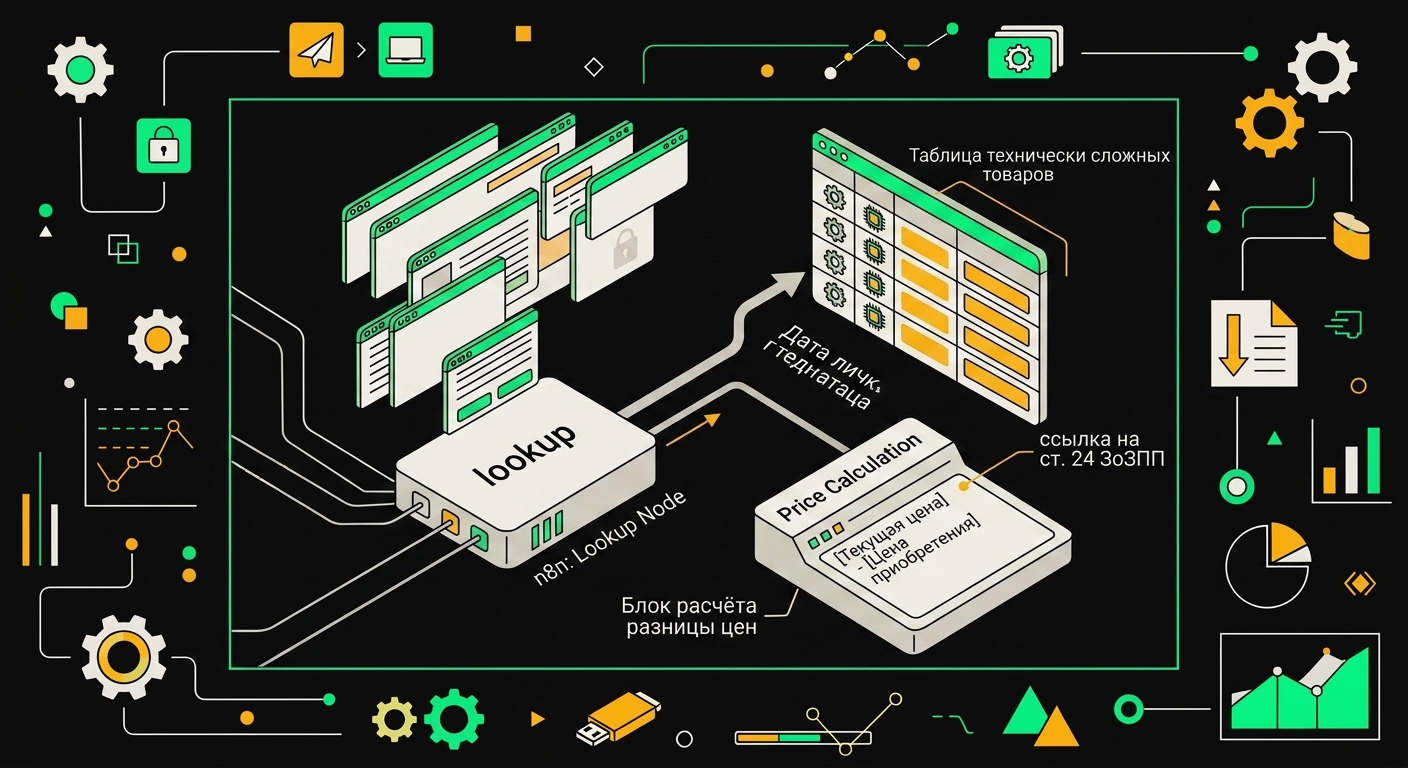
Узел вычисляет дельту между ценой на момент покупки и ценой на дату возврата и подставляет сумму прямо в шаблон ответа.
Работа с отзывами: отдельная ветка пайплайна
Отзывы в нашем пайплайне живут отдельно от основного потока заказов. Это принципиально: у них другой ритм поступления, другая структура данных и другая цепочка реакций.
Источников четыре: Ozon, Wildberries, Яндекс.Маркет и Яндекс.Карты. Ozon и WB отдают отзывы через официальные API продавца, там всё предсказуемо. Маркет тоже покрыт официально. А вот Карты периодически скрейпятся через Bright Data, потому что там API для бизнеса капризное и закрыто для большинства аккаунтов. Apify использую как резервный вариант, когда надо быстро поднять сбор по новой гео-точке без долгого согласования.
После сбора каждый отзыв прогоняется через aspect-based sentiment analysis. Не просто "позитивный/негативный" на весь текст, а покомпонентно: доставка, качество, упаковка, соответствие описанию. Один отзыв вполне может давать +0.8 по качеству и -0.7 по упаковке одновременно. Агрегировать это в одно число значит потерять самое интересное. Параллельно модель вытаскивает упомянутые SKU (покупатели часто пишут артикулы или названия цветовых вариантов) и конкретные дефекты в свободной форме.
Дальше срабатывает первый автотриггер. Если sentiment по отзыву ниже -0.5 и модель зафиксировала упоминание конкретного дефекта (не "не понравилось", а "трещина на корпусе", "не работает кнопка", "пришло не то"), пайплайн автоматически создаёт тикет в системе качества. Без участия человека. Тикет уже содержит: текст отзыва, SKU, извлечённый дефект, ссылку на заказ если связка нашлась.
Связка "отзыв - заказ - возврат" выстраивается по нескольким ключам: номер заказа из текста, имя покупателя плюс дата, иногда просто по SKU и временному окну. Получается не всегда, процент совпадений зависит от того, насколько полно покупатель указывает детали заказа в тексте отзыва. И вот тут начинается самое полезное: если за одну неделю по одному SKU накапливается пять и больше негативных отзывов с reason=defect, категорийный менеджер получает оповещение через автоматизированный мониторинг репутации. Не в конце квартала, не при плановом аудите, а пока товар ещё активно продаётся и можно что-то сделать.
Ответы продав

Аспектный анализ позволяет видеть не общую оценку, а конкретно что именно не понравилось: упаковка, срок, качество или сервис.



