

Зачем автоматизировать обработку заказов в Shopify в 2026 году
Я видел одну и ту же картину в нескольких магазинах: команда справляется, пока заказов двести в день. Потом приходит промо, трафик вырастает в десять раз, и всё начинает рассыпаться — менеджеры не успевают, склад получает противоречивые данные, клиенты видят в наличии товар, которого физически нет.
Проблема не в людях. Проблема в том, что ручная обработка линейно масштабируется людьми, а нагрузка растёт экспоненциально и неравномерно.
Математика, которая меняет восприятие. Тысяча заказов в день — это в среднем 0.7 заказа в минуту. Звучит спокойно. Но во время запуска коллекции или распродажи пиковый поток может существенно превышать среднее значение. Именно в эти окна случается всё плохое: overselling, двойные резервы, потерянные вебхуки, которые Shopify отправил, но никто не обработал.
Почему n8n, а не готовые интеграции. В 2026 году на рынке достаточно SaaS-решений для автоматизации Shopify, но у них общая проблема — ты не контролируешь очередь выполнений и не видишь, что происходит под капотом во время пика. n8n в self-hosted режиме даёт несколько принципиальных вещей сразу: нативные ноды Shopify без написания обёрток, прямое подключение к Redis для управления очередями и блокировками, PostgreSQL как хранилище состояния выполнений, и HTTP Request нода для любого внешнего API без ограничений вендора. Плюс — ты держишь данные заказов у себя, что важно при работе с фискализацией и антифродом.
Что реально уходит в автоматику. Не абстрактные «бизнес-процессы», а конкретные операции: валидация адреса и состава заказа сразу после webhook orders/create, антифрод-проверка через внешний сервис до подтверждения, атомарный резерв стока с защитой от race conditions, передача данных в ОФД для фискализации, отправка задания в фулфилмент-систему, нотификации клиенту и команде на каждом переходе статуса, обработка возвратов с возвратом резерва и инициацией рефанда.
Что происходит без этого. Overselling — это не гипотетический риск, это конкретные негативные отзывы и ручная работа по отмене заказов. Race conditions при одновременных заказах на последний SKU решаются либо блокировками на уровне Redis, либо не решаются вообще. Shopify rate limits при наивной интеграции бьют именно в пиковые моменты, когда каждый запрос критичен. Потерянные вебхуки без очереди с retry-логикой означают заказы, которые просто не попали в обработку — и ты узнаёшь об этом от злого клиента, а не из дашборда.
Автоматизация здесь не про оптимизацию. Про то, чтобы система вообще работала при росте. Если вы только выбираете платформу для автоматизации, полезно сначала разобраться с базовыми принципами построения workflow-автоматизаций в n8n.

С ростом числа заказов ручная обработка становится узким местом, и автоматизация через n8n позволяет масштабироваться без линейного увеличения команды.
Архитектура решения: от вебхука Shopify до фулфилмента
Когда я впервые запустил простой вебхук Shopify → n8n на одном инстансе, первые два дня всё работало идеально. На третий день пришёл маркетинговый «прогрев» — и Shopify начал слать повторные запросы, потому что воркер завис на обращении к внешнему API и не успевал ответить за отведённое время. Дублированные заказы, злой клиент, ночная отладка. Стандартная история, которую можно было избежать с самого начала, если правильно разделить HTTP-поверхность и фактическую обработку.
Принцип первый: вебхук не должен ничего делать, кроме как принять и подтвердить. Shopify ожидает 200 OK в течение нескольких секунд — после этого считает доставку неудавшейся и начинает ретраить. В n8n для этого есть режим Respond Immediately в Webhook node: нода мгновенно возвращает ответ, а пейлоад уходит дальше по флоу асинхронно. Это не опциональная оптимизация — это обязательное условие работы на любых объёмах выше «пощупать руками».
Поток данных выглядит так:
Shopify webhook
→ n8n Webhook node (Respond Immediately → 200 OK)
→ Redis/Bull queue
→ воркеры обработки
→ исходящие интеграции
Redis с Bull (или BullMQ, если вы на Node 18+) здесь — не модный инструмент, а буфер между непредсказуемой нагрузкой снаружи и вашими воркерами внутри. Очередь принимает входящий поток, воркеры переваривают его в своём темпе.
Четыре слоя, которые нельзя смешивать:
Первый — приём: Webhook node, валидация HMAC-подписи Shopify, немедленный ответ. Второй — дедупликация: проверка по order_id в PostgreSQL перед любой бизнес-логикой. Без этого повторные доставки от Shopify и ваши ретраи создадут дубли в ERP. Третий — бизнес-логика: обогащение заказа, проверка склада, применение правил маршрутизации. Четвёртый — исходящие интеграции: запись в 1С или ERP, передача в WMS, создание отправления в СДЭК или Boxberry, обновление статуса в CRM.
Каждый слой — отдельный n8n workflow или отдельная нода в цепочке с явными точками отказа и логированием. Когда СДЭК упадёт в час ночи, вы хотите видеть в логах ровно одну строку: «интеграция СДЭК недоступна, заказ #12345 в статусе pending_shipping» — а не разбираться, на каком шаге оборвалась транзакция.
Хранилище состояний — два инструмента под разные задачи. PostgreSQL хранит финальные состояния заказов, идемпотентные ключи и полный аудит-лог: кто создал, кто изменил, какой пейлоад пришёл. Это ваша source of truth и ответ на любой вопрос саппорта. Redis — для оперативных данных с коротким TTL: токены авторизации внешних сервисов, счётчики rate-limit для API-партнёров, временные блокировки при параллельной обработке.
n8n в queue mode — не обсуждается при нагрузке. Дефолтный режим с одним процессом испытывает трудности при росте числа заказов и наличии тяжёлых интеграций. Для тысячи заказов в день с пиками мне хватало конфигурации: один main-процесс (только UI и API) плюс три-пять воркеров в отдельных контейнерах. Воркеры stateless, их можно скейлить горизонтально под конкретный пик — это главное преимущество такой схемы перед монолитным инстансом.
Ориентир для планирования мощностей: рассчитывайте количество воркеров исходя из среднего времени обработки одного заказа и целевой пропускной способности в пик, а не только от дневного объёма.
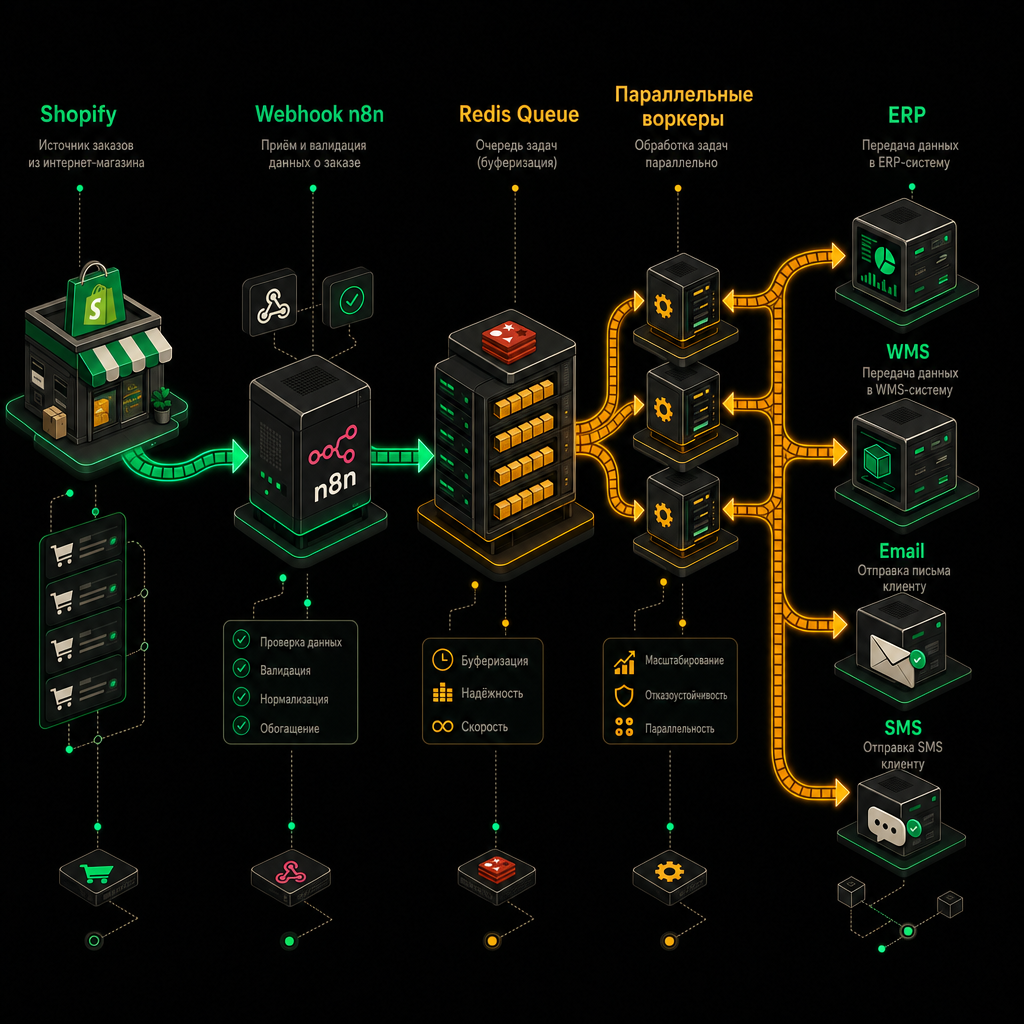
Вебхук Shopify попадает в очередь Redis Bull, откуда n8n-воркеры забирают задачи и выполняют бизнес-логику в управляемом порядке.
Подписка на вебхуки Shopify и проверка подписи HMAC
Webhooks в Shopify — это та точка, где половина интеграций ломается ещё до того, как доходит до бизнес-логики. Поэтому начну с того, какие топики я реально подписываю в проде, а не с того, что предлагает дефолтный пресет.
Минимально необходимый набор топиков:
orders/create— фиксирую заказ в своей системе сразу, не дожидаясь оплатыorders/paid— триггер для фулфилмента, бухгалтерии, начисления бонусовorders/cancelled— откат всего, что навесили наorders/createorders/fulfilled— синхронизация со складом и трекингомrefunds/create— отдельным топиком, не путать сorders/updatedinventory_levels/update— если есть мультисклад или внешний WMS
orders/updated я намеренно не беру — он шумный, прилетает на каждый чих, и без дедупликации забивает очередь.
Регистрация только через GraphQL Admin API
Через UI в админке вебхуки не создаю — там нет нормального версионирования, нет фильтров по полям, и при пересоздании приложения всё разъезжается. Использую webhookSubscriptionCreate:
mutation {
webhookSubscriptionCreate(
topic: ORDERS_PAID
webhookSubscription: {
callbackUrl: "https://n8n.example.com/webhook/shopify-orders-paid"
format: JSON
includeFields: ["id", "total_price", "customer", "line_items"]
}
) {
webhookSubscription { id }
userErrors { field message }
}
}
includeFields экономит трафик и время парсинга — если не нужен весь объект заказа, не тащите его.
Проверка HMAC — в первой же ноде
Это не опционально. Любой, кто узнал ваш URL (а он рано или поздно утечёт через логи или CDN), сможет слать вам мусор. Webhook node настраиваю так: Respond → Immediately, Raw Body → enabled. Без raw body подпись не сойдётся никогда — JSON-сериализация в n8n не побайтово совпадает с тем, что подписывал Shopify.
// Function node: HMAC verification
const crypto = require('crypto');
const secret = $env.SHOPIFY_WEBHOOK_SECRET;
const hmacHeader = $input.first().json.headers['x-shopify-hmac-sha256'];
const rawBody = $input.first().json.body; // raw string
const digest = crypto.createHmac('sha256', secret).update(rawBody, 'utf8').digest('base64');
if (digest !== hmacHeader) {
throw new Error('Invalid HMAC signature');
}
return $input.all();
Про коды ответа — критичный момент
Если подпись невалидна, нельзя возвращать 200. Видел эту ошибку в десятке проектов: люди ставят Webhook в режим Respond Immediately, и на любой запрос летит 200 OK. Shopify считает такой вебхук доставленным, ретраев не будет, а вы сидите со сломанной валидацией и не знаете об этом.
Правильно: на невалидный HMAC отдавать 401 Unauthorized. Для этого режим ответа меняю на Respond → Using 'Respond to Webhook' Node и в ветке после throw ставлю Respond to Webhook с кодом 401. Либо, если оставляю Respond Immediately ради скорости, делаю проверку HMAC прямо в Webhook node через Code-режим (в свежих версиях n8n это есть) и формирую ответ оттуда.
Архитектура: ответили — потом обработали
Shopify ожидает ответ в течение нескольких секунд. Если за это время не уложились — вебхук помечается как failed, идёт ретрай, и вы получаете дубликаты. Поэтому:
- Webhook node принимает запрос и сразу отвечает 200
- HMAC проверяется синхронно (это миллисекунды)
- Дальше —
Execute Workflowв режиме trigger без ожидания результата, и основной воркфлоу пусть себе крутится хоть минуту
В дочернем воркфлоу первым делом пишу payload в очередь (Redis, Postgres-таблица webhook_inbox, что есть под рукой) с idempotency_key = headers['x-shopify-webhook-id']. Это спасает от дублей при ретраях Shopify — он повторяет с тем же ID, и я просто игнорирую уже виденные.
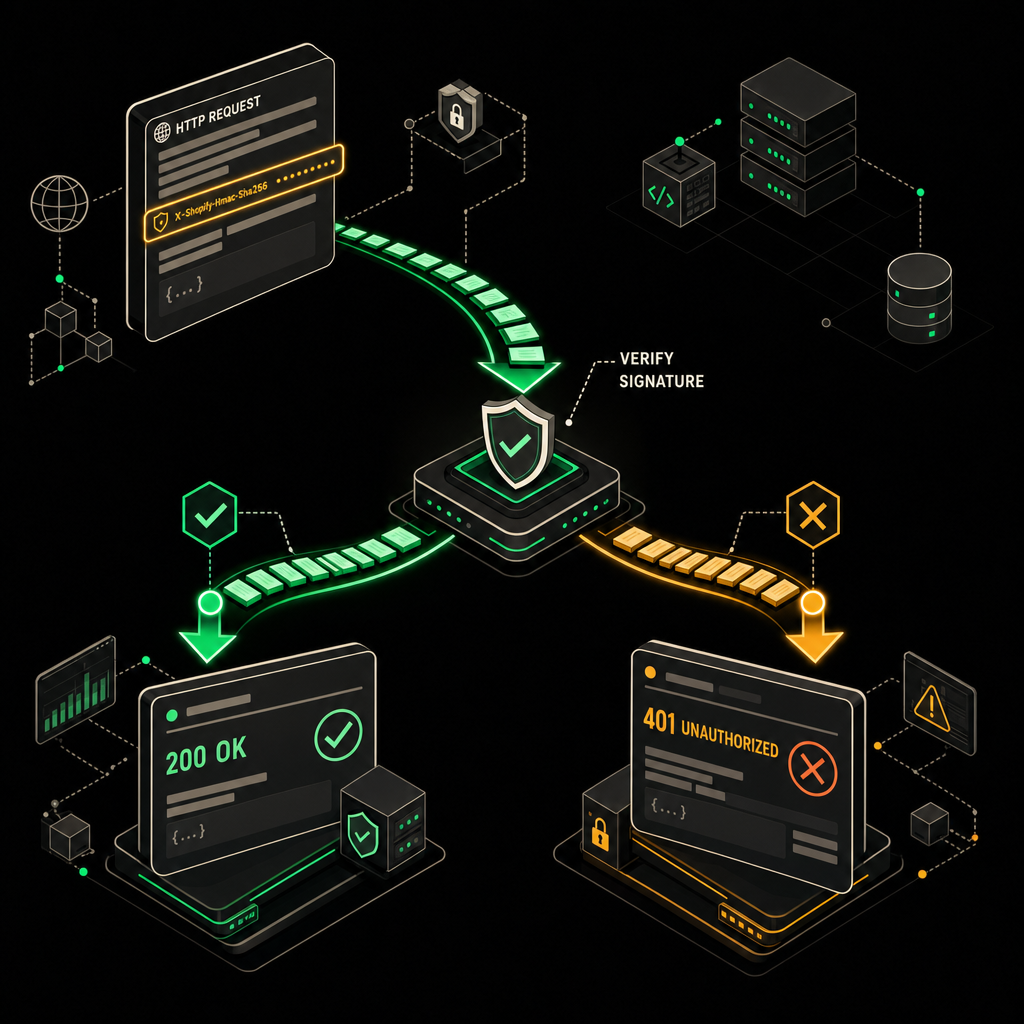
Каждый входящий вебхук должен проходить верификацию HMAC-SHA256 с использованием секрета приложения Shopify до начала любой обработки данных.
Идемпотентность: защита от дублей при at-least-once доставке
Shopify не гарантирует exactly-once. Если ваш эндпоинт ответил 5xx, таймаутнул или просто моргнул — платформа будет ретраить вебхук с экспоненциальной задержкой. На практике это значит, что один orders/paid может прилететь к вам и два, и пять раз. Без дедупликации это двойные списания со склада, дубли в Klaviyo, повторные фулфилменты и звонки от клиентов, которым «почему-то пришло два письма про один заказ».
Ключ идемпотентности я строю по двум сценариям:
- Если доверяем Shopify —
X-Shopify-Webhook-Id+topic. Заголовок уникален для каждой попытки доставки уникального события, ретраи приходят с тем же ID. - Если хотим защититься от логических дублей (например, кто-то дважды дёрнул API и Shopify сгенерировал два события на один факт) —
order.id+ тип события, напримерorder:1234567890:paid.
Для большинства интеграций я беру первый вариант — он проще и достаточен.
Хранилище: Postgres или Redis
Postgres — когда нужна аудируемость и расследование инцидентов через полгода. UNIQUE constraint делает всю работу за вас: вставка либо проходит, либо падает, гонки исключены на уровне БД.
CREATE TABLE webhook_idempotency (
webhook_id TEXT NOT NULL,
topic TEXT NOT NULL,
received_at TIMESTAMPTZ DEFAULT NOW(),
PRIMARY KEY (webhook_id, topic)
);
Redis — когда важна латентность и не жалко терять историю. SETNX с TTL закрывает окно ретраев Shopify:
SET webhook:{topic}:{webhook_id} 1 NX EX 604800
Ответ OK — обрабатываем, nil — это дубль, выходим.
Паттерн idempotency gate в n8n
Первой нодой после Webhook Trigger всегда ставлю Postgres node с INSERT ... ON CONFLICT DO NOTHING RETURNING:
INSERT INTO webhook_idempotency (webhook_id, topic)
VALUES ($1, $2)
ON CONFLICT DO NOTHING
RETURNING webhook_id;
В параметрах: $1 = {{ $json.headers["x-shopify-webhook-id"] }}, $2 = {{ $json.headers["x-shopify-topic"] }}.
Дальше — IF-нода: если массив возвращённых строк пустой, значит конфликт, и это ретрай уже обработанного события. Ранний выход через NoOp с пометкой duplicate_skipped. Если строка вернулась — мы первые, идём в основную логику.
Важный момент: гейт должен стоять до любого побочного действия. Я видел флоу, где сначала писали в CRM, а потом проверяли идемпотентность — это бессмысленно.
Логирование
К таблице webhook_idempotency я обычно добавляю отдельный append-only лог webhook_attempts со всеми попытками, включая дубли, с телом и заголовками. Когда через месяц приходит «почему у клиента три фулфилмента» — без этого лога расследование превращается в гадание. На объёмах до миллиона событий в месяц это копейки по диску, а нервов экономит много.
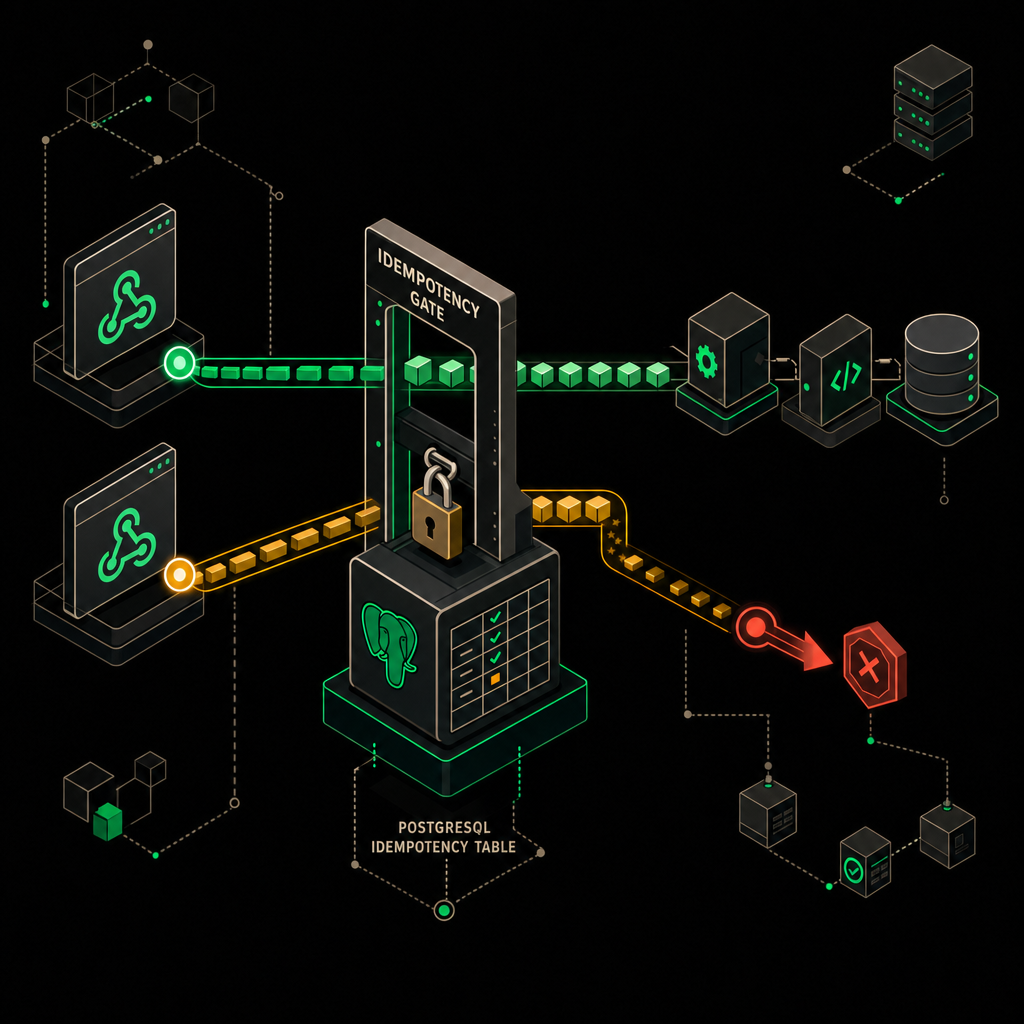
Хранение обработанных идентификаторов заказов в Redis с TTL гарантирует, что один и тот же вебхук не запустит бизнес-логику дважды.
Работа с rate limits Shopify Admin GraphQL API
Главное, что стоит зафиксировать: Shopify считает не количество запросов, а их стоимость. У каждого запроса есть cost в очках, и эти очки тратятся из bucket'а магазина, который восстанавливается с фиксированной скоростью. Актуальные лимиты зависят от вашего плана — уточняйте в официальной документации Shopify, так как они могут меняться.
Стоимость запроса также варьируется в зависимости от его сложности. Простые запросы стоят дёшево, а выборки с большим количеством объектов и вложенными полями могут стоить значительно дороже. Поэтому первое, что я делаю в любом workflow — учу его читать extensions.cost.throttleStatus из ответа. Там лежат maximumAvailable, currentlyAvailable и restoreRate — всё, что нужно для адаптивной паузы.
Стратегия 1: адаптивный throttle по ответу
Никакого фиксированного Wait 500ms между запросами — это либо медленно, либо всё равно ловит 429. Я смотрю на currentlyAvailable после каждого запроса и притормаживаю, только когда bucket реально проседает. В n8n это удобно засунуть в Code node сразу после HTTP Request:
// HTTP Request node — обработка throttle
const res = $input.first().json;
const cost = res.extensions?.cost;
if (cost) {
const available = cost.throttleStatus.currentlyAvailable;
const restore = cost.throttleStatus.restoreRate;
if (available < 200) {
const waitMs = Math.ceil((500 - available) / restore) * 1000;
await new Promise(r => setTimeout(r, waitMs));
}
}
return $input.all();
Конкретные пороговые значения подбирайте под свой план и профиль запросов. Логика простая: пока в bucket есть запас — жмём на полной, как только остаётся меньше четверти — ждём ровно столько, чтобы восстановить комфортный уровень.
Стратегия 2: bulk operations вместо цикла
Если задача — выгрузить все заказы за квартал или все продукты с метаполями, итерация через first: 250 + cursor pagination — это путь в 429. Вместо этого использую bulkOperationRunQuery: Shopify сам выполнит запрос на своей стороне, сложит результат в JSONL и отдаст ссылку. Один запуск стоит копейки в bucket, а на выходе — сотни тысяч объектов. Я опрашиваю статус раз в 10–30 секунд через currentBulkOperation, потом скачиваю файл и стримлю его в n8n через Split In Batches. Это правило по умолчанию для всего, что больше ~1000 объектов.
Стратегия 3: централизованный token bucket в Redis
Когда воркеров n8n несколько (а у меня их обычно 3–5 на тяжёлых интеграциях), локальная пауза в Code node не спасает: каждый воркер думает, что bucket полный, а Shopify видит общий поток. Решение — вынести учёт в Redis. Держу ключ shopify:bucket:{shop_domain} со значением currentlyAvailable и timestamp последнего обновления. Перед каждым запросом воркер делает Lua-скрипт: пересчитывает available с учётом restore rate за прошедшее время, проверяет, хватает ли на предполагаемую стоимость (для незнакомых запросов закладываю 50 очков), и либо резервирует, либо возвращает время ожидания. После ответа Shopify — синхронизируем реальное значение из throttleStatus. Lua-скрипт обязателен, иначе race condition между GET и SET сожрёт всю экономию.
Обработка 429 и THROTTLED
Несмотря на все стратегии, throttle всё равно случается — особенно на webhooks-всплесках. Ловлю два случая: HTTP 429 и errors[].extensions.code === "THROTTLED" в теле 200-ответа (GraphQL любит так делать). Реакция одна — exponential backoff с jitter:
const delay = Math.min(60000, 1000 * 2 ** attempt) + Math.random() * 500;
Максимум 5 ретраев, после — в Dead Letter Queue с пометкой и алертом. Без jitter несколько воркеров после общего 429 синхронно ломятся обратно и получают 429 снова — проходил это.
На практике связка «bulk для массового + адаптивный throttle для точечного + Redis bucket для координации» заметно снижает утилизацию лимита при высокой нагрузке, и THROTTLED в продакшене встречается крайне редко.
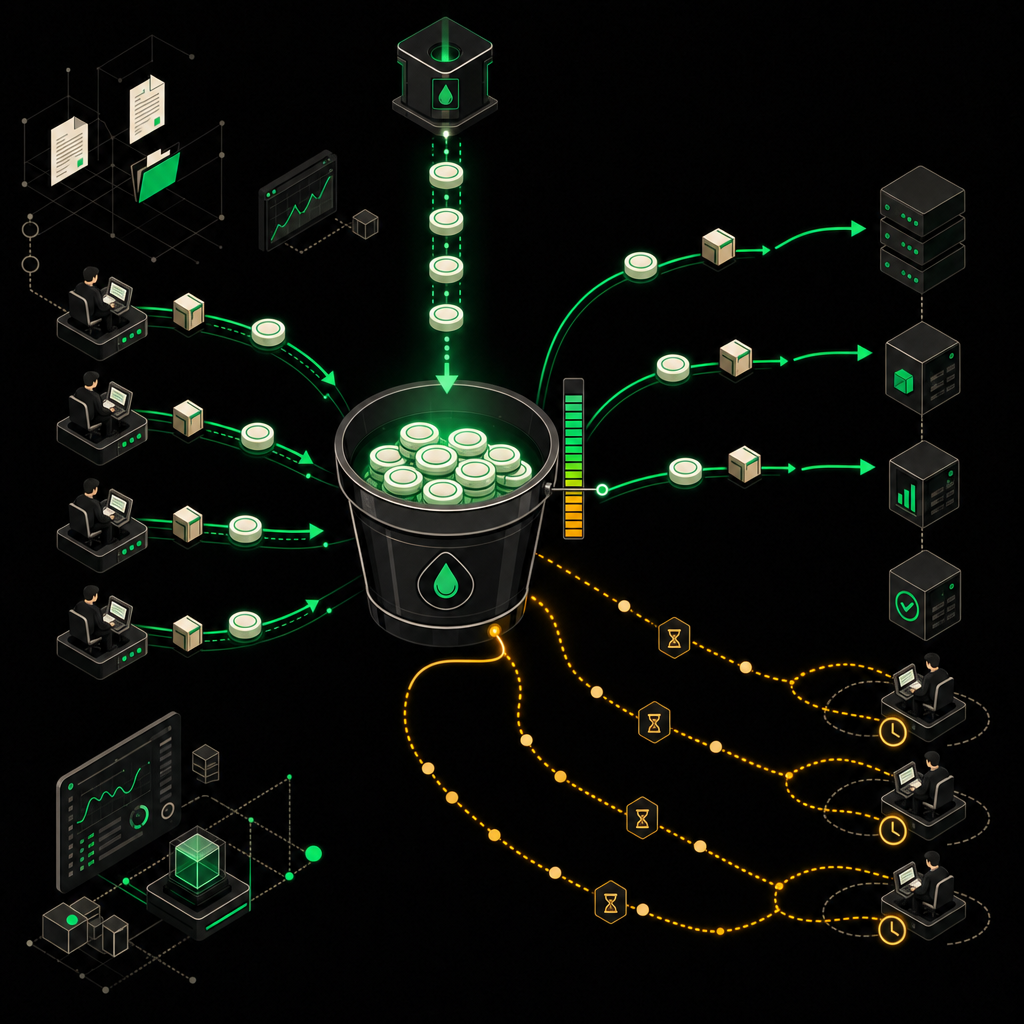
Отслеживание стоимости запросов по модели cost-based throttling Shopify позволяет равномерно расходовать квоту и избегать ошибок 429.
Предотвращение overselling: резервирование стока и блокировки
Классика жанра, на которой я обжигался не раз: на складе один последний свитер, два покупателя одновременно жмут «Оплатить», оба заказа уходят в paid, и кто-то получает email «извините, отменяем». Без явной синхронизации это не баг конкретного интегратора — это race condition в чистом виде. Между READ inventory и WRITE -1 помещается целая вечность сетевых хопов, и если у вас две параллельных транзакции, обе прочитают «1» и обе спишут до нуля. Минус один свитер из ниоткуда.
Решаю это на трёх уровнях.
Резерв на checkout, а не после оплаты. Самая частая ошибка в архитектуре — списывать сток по orders/paid. К этому моменту покупатель уже три минуты вводил CVV, а товар всё ещё «доступен» для соседней корзины. Я уменьшаю available через inventoryAdjustQuantities с reason reservation сразу при создании checkout, и возвращаю обратно по таймауту, если оплата не прошла. Да, это сложнее, чем «обновить после paid», но это единственный способ не врать витрине.
Оптимистическая блокировка на стороне Shopify. В inventoryAdjustQuantities есть compareQuantity — туда я кладу значение, которое только что прочитал. Если кто-то успел изменить сток между моим read и write, мутация падает с quantityConflict, и я ретраюсь с актуальным числом. Это бесплатный CAS, грех не пользоваться:
mutation {
inventoryAdjustQuantities(input: {
reason: "reservation",
name: "available",
changes: [{
inventoryItemId: "gid://shopify/InventoryItem/123",
locationId: "gid://shopify/Location/456",
delta: -1,
compareQuantity: 1
}]
}) { userErrors { field message code } }
}
Пессимистический лок на уровне SKU в своей БД. Перед тем как дёрнуть Shopify или подтвердить фулфилмент в WMS, я беру SELECT ... FOR UPDATE по строке SKU в собственной таблице резервов. Это сериализует конкурентные обработки одного и того же товара внутри моего сервиса, и Shopify видит уже упорядоченный поток мутаций. Лок держится миллисекунды — ровно на время записи резерва, не на время оплаты.
Синхронизация с ERP/WMS — стримом, не батчами. Видел не раз архитектуры, где WMS выгружает остатки раз в 15 минут джобом. На этом интервале при заметном трафике вы рискуете продать воздух. Сейчас я делаю либо webhook от WMS на каждое движение, либо — если WMS древний — polling с дельтой раз в 30 секунд по изменённым SKU. Источник истины — один (обычно WMS), Shopify — проекция, и эта проекция должна отставать на секунды, не на минуты.
Состояние резерва как тег заказа. Здесь я опираюсь на паттерн из Shopify Flow: вешаю на заказ теги stock-reserved, stock-validated, stock-fulfilled по мере прохождения этапов. Это даёт две полезные вещи: оператор в админке видит реальное состояние без захода в мою БД, а Flow-триггеры могут реагировать на смену тега (например, отправить алерт, если stock-reserved висит больше 20 минут — значит, оплата зависла, надо вернуть сток). Тег — это не источник истины, истина в БД, но как наблюдаемый side-channel он бесценен.
Проверка, что всё это работает: я раз в неделю прогоняю нагрузочный тест с 50 параллельными checkout'ами на товар с остатком 10. Должно пройти ровно 10 заказов, остальные 40 — получить «out of stock» на этапе checkout, а не отмену после оплаты. Если хоть один проскочил — значит, где-то в цепочке потерялся compareQuantity или лок.
Без распределённой блокировки параллельные воркеры могут одновременно подтвердить заказы на один и тот же товар, приводя к overselling.
Масштабирование n8n: queue mode и горизонтальные воркеры
Когда я переводил клиента с обработки 50 заказов в день на 1000+, regular mode у n8n начал захлёбываться на первой же распродаже. Давайте посчитаем, чтобы было понятно, откуда берётся боль: 1000 заказов × 8 шагов воркфлоу (валидация → антифрод → резерв склада → оплата → выгрузка в 1С → СДЭК → email → SMS) = 8000 executions в сутки. Среднее — около 5–6 в минуту, но пик на распродажах может быть кратно выше. Один main-процесс с этим не справляется: webhook'и начинают таймаутить, очередь в памяти растёт, OOM, рестарт, потерянные заказы.
Переезд на queue mode
В regular mode n8n исполняет воркфлоу в том же процессе, который принял webhook. В queue
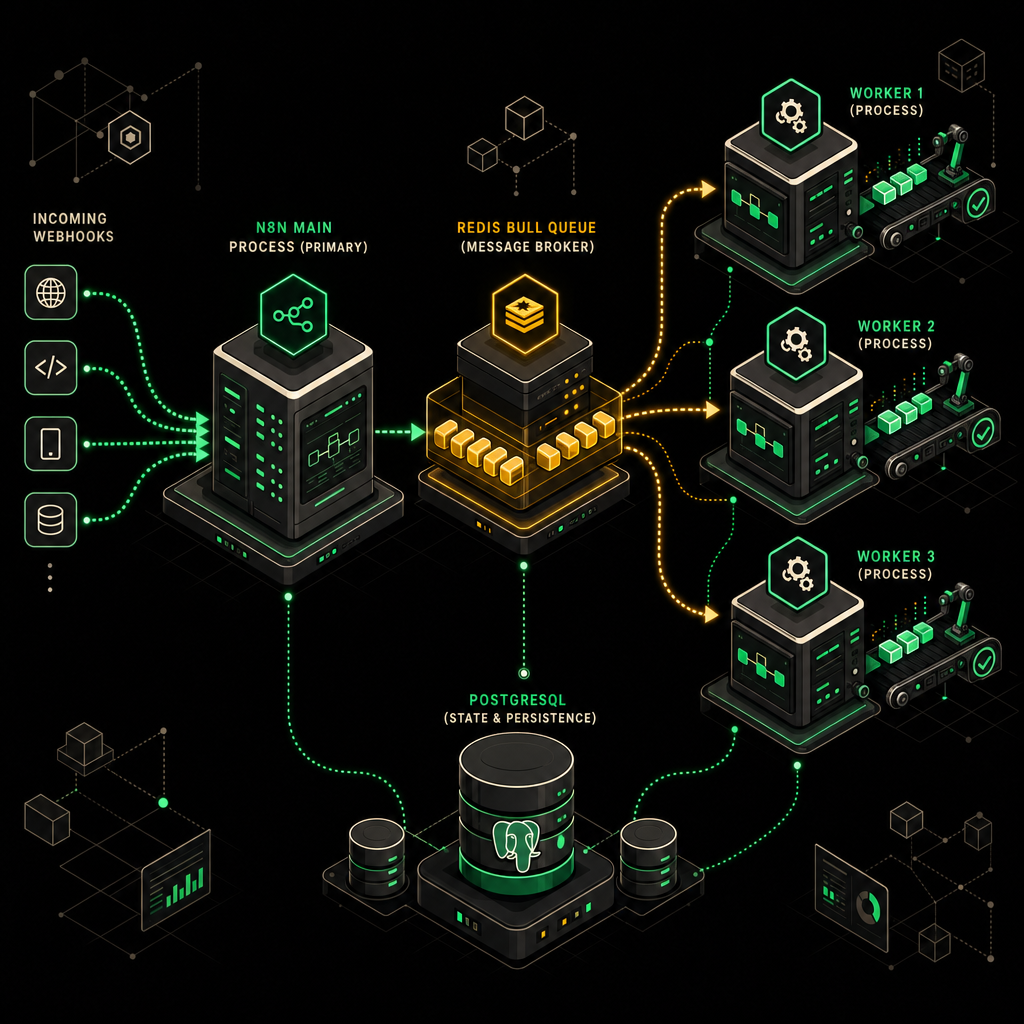
Запуск нескольких n8n-воркеров в queue mode позволяет горизонтально масштабировать обработку очереди заказов без изменения бизнес-логики.



