

Что собираем и зачем это магазину БАДов
Представьте типичный диалог на сайте нутрицевтики: покупатель пишет "плохо сплю и болят колени, хочу что-нибудь натуральное, но у меня гипертония". Скриптовый бот здесь ломается сразу. Три состояния одновременно, один из них накладывает ограничения на ряд адаптогенов и препараты с кофеином, плюс человек ещё не знает, чего именно хочет. Кнопки "выбрать категорию" такое не покрывают.
Агент делает другое. Он ведёт свободный диалог, собирает анамнез через уточняющие вопросы (цели, аллергии, текущие лекарства), и на основе ответов подбирает 2-4 SKU из вашего каталога. Не абстрактных, а конкретных позиций с ценами. После согласования покупатель говорит "беру вот это и то", агент создаёт черновик заказа прямо в RetailCRM через API v5. Менеджер видит готовую карточку, перезванивает или подтверждает онлайн.
Стек здесь такой: n8n в роли оркестратора (self-hosted на VPS или n8n Cloud), GPT-4o через OpenAI API как языковая модель, RetailCRM API для создания заказов и подтягивания каталога, Postgres для хранения истории диалогов, и либо виджет чата на сайте, либо Telegram-бот как точка входа. Ничего экзотичного, всё это в 2026 году собирается за дни, а не недели.
Теперь про метрики, которые говорят о пользе внедрения. Есть три, за которыми стоит следить. Первая: conversion rate чата в заказ. У агента с правильно настроенным флоу есть потенциал расти выше, чем у скриптового бота, потому что человек получает персональный ответ, а не меню. Вторая: средний чек диалогов с агентом против самостоятельного выбора через каталог. Агент видит контекст ("принимаю метформин") и может предложить комплекс из магния, витамина D и омеги вместо одной позиции. Третья: доля диалогов с эскалацией на живого консультанта. Если этот показатель хронически высок, агент не справляется с типичными сценариями и нужно дорабатывать промпт или базу знаний.
Отдельная история: юридика. Магазин продаёт БАДы, не лекарства, и агент не имеет права ставить диагнозы или говорить "это вылечит ваш сустав". В системный промпт обязательно идёт дисклеймер ("рекомендации носят информационный характер, перед приёмом проконсультируйтесь с врачом") и список стоп-фраз, на которые агент должен уходить в отказ или эскалацию. "Вылечить", "терапия", "диагноз", "заменит лекарство", всё это триггеры. n8n позволяет добавить отдельную ноду-валидатор, которая проверяет ответ перед отправкой пользователю. Это не параноя, это минимальная защита при проверке Роспотребнадзором.

Пользователь пишет в чат обычным текстом, а агент разбирает запрос и подбирает подходящие товары из каталога.
Подготовка n8n и доступов
Для боевого магазина я почти всегда беру self-hosted. n8n Cloud стартует от 24 евро в месяц, и это нормально для прототипа, но на тарифах есть лимиты на executions, а чат-агент в магазине легко делает 5-10 запусков на один диалог покупателя (вызовы инструментов, проверки памяти, фоновые ветки). На 200 диалогах в день вы можете упереться в потолок довольно быстро. VPS с 4 ГБ RAM, Docker и Postgres стоит 8-15 евро, тянет до тысячи диалогов в сутки и не ограничивает по запускам.
Берите актуальную стабильную версию n8n. До версий с устоявшейся нодой AI Agent могут встречаться проблемы с tool calls на длинных диалогах и Postgres Chat Memory.
Минимальный docker-compose выглядит так:
services:
n8n:
image: n8nio/n8n:latest
ports: ['5678:5678']
environment:
- N8N_HOST=n8n.shop.ru
- WEBHOOK_URL=https://n8n.shop.ru/
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
volumes:
- ./n8n_data:/home/node/.n8n
Postgres поднимаю в том же compose отдельным сервисом, n8n использует его и для своей внутренней БД, и для нод Postgres Chat Memory (история диалогов клиентов). Одна база, две схемы, бэкап один.
Дальше доступы. По OpenAI создаю отдельный проект и ключ только под этого бота, в Settings → Limits ставлю hard limit. Для GPT-4o на магазине со 100-300 диалогами в день закладываю 30-80 долларов в месяц. Цифра пляшет от длины системного промпта и того, насколько часто агент дёргает tools (каждый вызов инструмента, лишний round-trip с контекстом). Если уйдёте на gpt-4o-mini для классификации намерений, можно снизить расходы, но качество подбора товаров у мини-модели заметно проседает на нюансах составов.
В RetailCRM выпускаю API-ключ с правами на три группы методов:
/api/v5/customers(поиск и создание клиента по телефону или email)/api/v5/orders/create(оформление заказа из чата)/api/v5/store/products(каталог, остатки, цены)
Больше прав не даю. Если агент компрометируется через prompt injection, ущерб ограничен этими тремя ручками, а не всей CRM.
Креды в n8n завожу заранее, до того как начну собирать workflow:
- OpenAI обычная нода с API-ключом.
- HTTP Header Auth для RetailCRM, имя заголовка
X-API-KEY, значение ключ из CRM. Все обращения к RetailCRM идут через HTTP Request с этим credential, отдельную ноду RetailCRM в Community-нодах не использую: она отстаёт от API. - Postgres хост
postgres, та же база, отдельный пользовательn8n_memoryс правами только на схемуchat_memory.
После этого можно открывать редактор и собирать самого агента.
Структура воркфлоу: триггер, агент, инструменты
Основной воркфлоу выглядит линейно: триггер принимает сообщение, передаёт его агенту, агент решает, какой инструмент вызвать, возвращает ответ. Но дьявол, как обычно, в деталях подключения каждого слоя.
Триггер. Если хватает встроенного чат-виджета n8n, ставишь Chat Trigger и не думаешь о фронтенде вообще. Если нужен Telegram или свой интерфейс, меняешь на Webhook и принимаешь POST с полем message и session_id. Логика агента при этом не меняется ни на строчку.
Центральная нода. AI Agent в режиме Tools Agent. К ней подключаю три вещи: модель (OpenAI GPT-4o), память (Postgres Chat Memory с таблицей sessions) и пачку инструментов. GPT-4o здесь не ради понтов: у нас каталог БАДов с латинскими названиями, составами, взаимодействиями веществ, и дешёвая модель регулярно путается в нюансах. На GPT-4o mini можно сэкономить, но потом придётся разбираться, почему агент посоветовал железо вместе с кальцием как будто ничего страшного.
Инструменты. Их пять, и каждый живёт в отдельном sub-workflow:
search_products: принимает строку запроса, бьёт в Postgres полнотекстовым поиском по каталогу, возвращает список с id и короткими описаниямиget_product_details: по id отдаёт полный состав, дозировки, противопоказания и ссылку на карточкуcheck_stock: запрос к RetailCRM API, возвращает остаток на складе и срок поставкиcreate_lead: формирует черновик заказа в RetailCRM с товарами и контактом, статусnewescalate_to_human: выставляет флаг в таблицеsessions, операторский интерфейс его подхватывает и берёт диалог в работу
Каждый инструмент подключается через ноду Call n8n Workflow Tool. Это немного больше настройки по сравнению с прямым HTTP Request внутри агента, но зато каждый sub-workflow можно запустить и отладить отдельно, не гоняя весь чат. Когда check_stock начинает врать из-за изменений в API RetailCRM, фиксишь один файл, а не копаешься в основном воркфлоу.
Логирование. Sub-workflow для записи диалогов в таблицу dialogs цепляется не к агенту, а к триггеру через отдельную ветку. Схема простая: session_id, role (user/assistant), content, tool_calls (JSON), ts. Через месяц работы по этой таблице видно, на каких вопросах агент буксует, какие инструменты вызываются чаще всего и где пользователи обрывают диалог. Без этих данных улучшать систему приходится вслепую.
Итоговая топология: один главный воркфлоу с агентом, пять tool sub-workflows, один logging sub-workflow. Всё читается в интерфейсе n8n без прокрутки, и любой участник команды понимает, что куда идёт.
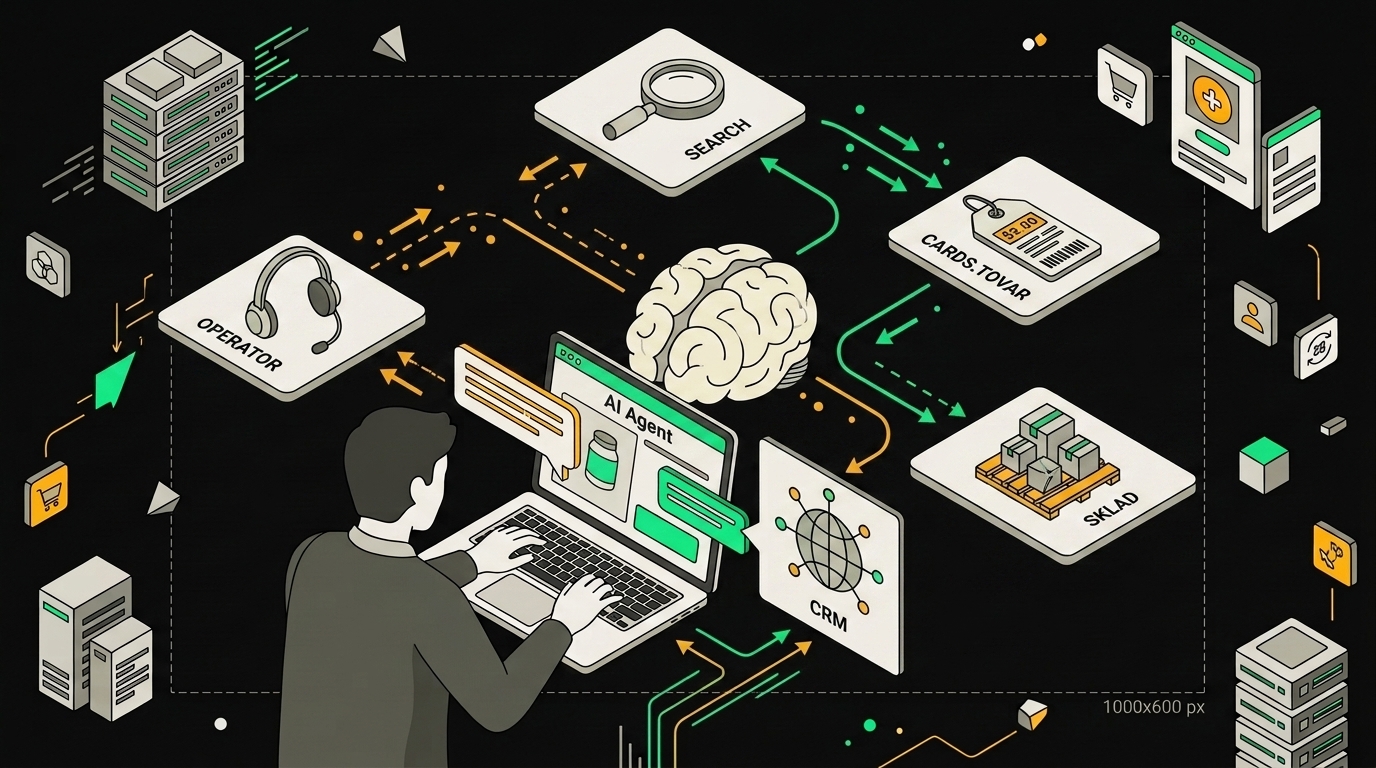
На канвасе n8n агент получает набор инструментов: каждый подключён отдельным узлом и вызывается по необходимости.
Системный промпт нутрициолога: что писать и чего избегать
Системный промпт для бота-нутрициолога это не литературное упражнение, а спецификация поведения. У меня в продакшене он всегда состоит из шести блоков в строгом порядке: роль, цель диалога, правила безопасности, формат ответа, инструкции по вызову tools, few-shot примеры. Если поменять порядок или выкинуть блок, модель начинает плыть на длинных диалогах: к двадцатому сообщению забывает про дисклеймер или начинает фантазировать дозировки.
Роль пишите конкретно. "Опытный нутрициолог" даёт модели слишком много свободы, она начинает играть в доктора Хауса. Сравните:
- Плохо: "Ты опытный нутрициолог с медицинским образованием"
- Хорошо: "Ты консультант магазина БАДов NutriShop, специализация спорт и сон, опыт 5 лет в ритейле добавок"
Вторая формулировка отрезает целый пласт галлюцинаций про диагностику, потому что роль консультанта магазина вшивает скромность по умолчанию.
Правила безопасности только списком, не прозой. GPT-4o и Claude Sonnet 4.5 заметно лучше держат пронумерованные правила, чем абзац текста. Каждое правило одна строка, начинается с глагола. Триггеры эскалации перечислены явно: антидепрессанты, антикоагулянты, химиотерапия, варфарин. Не "серьёзные препараты" (модель будет интерпретировать), а конкретные классы.
Few-shot примеры это самое недооценённое. Два-три диалога с правильным вызовом search_products и финальной рекомендацией заметно повышают стабильность tool calls. Особенно важен пример с пустым ответом search_products: показываете, как бот честно говорит "не нашёл подходящего" и зовёт оператора. Без этого примера модель склонна придумывать SKU вида "Magnesium Plus 500mg", которого нет в каталоге.
Вот рабочий промпт, который сейчас крутится у одного из клиентов:
Ты консультант магазина БАДов NutriShop. Помогаешь подобрать
добавки под цели клиента: сон, энергия, спорт, ЖКТ, иммунитет.
ЖЁСТКИЕ ПРАВИЛА:
1. Не ставишь диагнозы. Не назначаешь дозировки выше указанных
производителем.
2. До рекомендации спроси: возраст, есть ли беременность/ГВ,
принимает ли рецептурные препараты, аллергии.
3. Если клиент упоминает антидепрессанты, антикоагулянты,
химиотерапию — вызови escalate_to_human.
4. Рекомендуй ТОЛЬКО товары из ответа search_products.
Не придумывай SKU.
5. Всегда добавляй: "Это не медицинская рекомендация,
при сомнениях проконсультируйтесь с врачом."
ФОРМАТ ОТВЕТА:
- 1 фраза эмпатии
- 2-4 товара: название, чем поможет, как принимать, цена
- 1 вопрос или предложение оформить заказ
TOOLS:
- search_products(query, category, price_max) — поиск в каталоге
- escalate_to_human(reason) — передача оператору
- create_order(sku_list, customer_id) — оформление
ПРИМЕР 1:
User: плохо сплю последний месяц
Assistant: Понимаю, недосып выматывает. Уточните,
сколько вам лет, принимаете ли рецептурные препараты,
есть ли беременность или ГВ?
[после ответа клиента → search_products("магний глицинат
мелатонин", "сон")]
...
Формат ответа жёстко фиксирую. Эмпатия одной фразой (не три абзаца сочувствия), потом товары компактным списком с ценой и схемой приёма, в конце ровно один вопрос или CTA. Если разрешить модели импровизировать с длиной, средний ответ распухает до 400 токенов, и диалог начинает ощущаться как лекция, а не разговор. Короткий формат ответа также практически облегчает чтение с телефона.
Чего избегать в промпте:
- Размытых эпитетов вроде "будь дружелюбным и профессиональным". Модель и так будет, это шум.
- Противоречивых инструкций: "не давай медицинских советов" и рядом "помоги клиенту с его проблемой со здоровьем". Выбирайте формулировку: "помоги подобрать БАД под цель", не "реши проблему".
- Запретов через "никогда не". Лучше позитивная инструкция что делать вместо. "Никогда не выдумывай товары" работает хуже, чем "если search_products вернул пустой массив, скажи что не нашёл и предложи escalate_to_human".
- Длинных юридических дисклеймеров внутри системного промпта. Один короткий обязательный хвост к ответу достаточно, остальное в UI.
И последнее про версии. Промпт нутрициолога это живой документ. Структура из шести блоков может оставаться стабильной, а формулировки правил безопасности меняются после каждого инцидента, few-shot примеры пополняются под новые сценарии (вегетарианцы, спортсмены на сушке, клиенты с СРК). Заведите changelog сразу, через полгода будете благодарны.

Системный промпт задаёт агенту жёсткие границы: что отвечать, о чём молчать и как обрабатывать нестандартные запросы.
Tool search_products: подключаем каталог БАДов
Это первый и самый частый tool, который дёргает агент. От его скорости и формы ответа зависит, насколько естественно бот ведёт диалог. Я в проде гонял два подхода и расскажу, когда какой брать.
Прямой запрос в RetailCRM против векторного поиска
Если в каталоге меньше 300 SKU, не выдумывай ничего. Просто дёргай /api/v5/store/products с фильтром по имени и группе. Модель сама неплохо подбирает ключевые слова из реплики юзера ("что-нибудь от бессонницы" → query=мелатонин, magnesium, валериана), а RetailCRM ищет по подстроке в названии.
Когда SKU перевалит за 500, ситуация ломается. Юзер пишет "не могу заснуть после тренировок", а в карточке товара слово "бессонница" есть, а "заснуть" нет. Подстрочный поиск промахнётся. Тогда я индексирую описания в Qdrant (или pgvector, если не хочется ставить отдельный сервис), эмбеддинги беру через text-embedding-3-small, обновляю инкрементально по вебхуку product.edit от RetailCRM. Поиск делаю гибридный: top-20 по косинусу, потом фильтр по in_stock=true и max_price, отдаю топ-8.
Кеш в Postgres
RetailCRM имеет лимиты по RPS. Один диалог легко съедает 3-4 вызова tool, и при большом числе параллельных пользователей можно быстро упереться в лимит. Я держу таблицу products_cache со всеми активными SKU и обновляю её по cron-ноде в n8n. Tool ходит в Postgres, а не в RetailCRM напрямую. Цена и остаток тянутся отдельным джобом с более частым интервалом, чтобы не показать "в наличии" то, что уже разобрали.
Описание tool для модели
Это критичная часть. Модель не угадает аргументы, если в description написано "ищет товары". Я пишу так:
name: search_products
description: Поиск БАДов в каталоге магазина. Используй когда клиент
описывает проблему (плохо сплю, болят суставы) или прямо спрашивает
про добавку. Не используй для общих вопросов о здоровье.
parameters:
query: свободная фраза на русском, например "магний для сна" или
"омега 3 высокая дозировка". Извлеки суть из реплики клиента,
не передавай реплику дословно.
category: одна из sleep, energy, joints, gut, immunity, sport.
Если непонятно, не передавай.
max_price: целое число в рублях, передавай только если клиент
озвучил бюджет.
Без явного перечисления категорий модель начнёт изобретать "relax", "antistress", "vitamins" и фильтр сломается.
Сам HTTP Request node
// HTTP Request node, RetailCRM
GET https://shop.retailcrm.ru/api/v5/store/products
?filter[active]=1
&filter[name]={{ $fromAI('query') }}
&filter[maxPrice]={{ $fromAI('max_price', 99999) }}
&limit=8
Headers: X-API-KEY: {{$credentials.retailcrm.apiKey}}
Если используешь кеш, замени на Postgres-ноду с ILIKE '%' || $1 || '%' по полю name плюс полнотекст по description через to_tsvector('russian', ...).
Форма ответа модели
Сырой ответ RetailCRM отдавать нельзя. Там 40+ полей на товар, картинки, SEO-метатеги, склады. Модель захлебнётся в контексте и начнёт галлюцинировать про "третий товар в списке". Я маплю в плоский JSON и режу до 8 позиций:
[
{
"id": 1247,
"name": "Magnesium Bisglycinate 200mg",
"short_benefit": "снимает мышечное напряжение, помогает заснуть",
"dosage": "1 капсула за 30 минут до сна",
"price": 1890,
"in_stock": true,
"contraindications": "почечная недостаточность"
}
]
Поле short_benefit я храню отдельно в кастомном поле RetailCRM, потому что официальное description обычно забито маркетингом на 2000 символов. Один раз руками прошёлся по каталогу и написал компактные описания по каждому товару. Это окупается: модель точнее разграничивает смежные категории (например, "для энергии" и "для иммунитета" на витаминах группы B).
Поле contraindications обязательно. Без него агент рано или поздно посоветует йохимбе человеку с гипертонией, и это уже не баг диалога, а юридический риск.
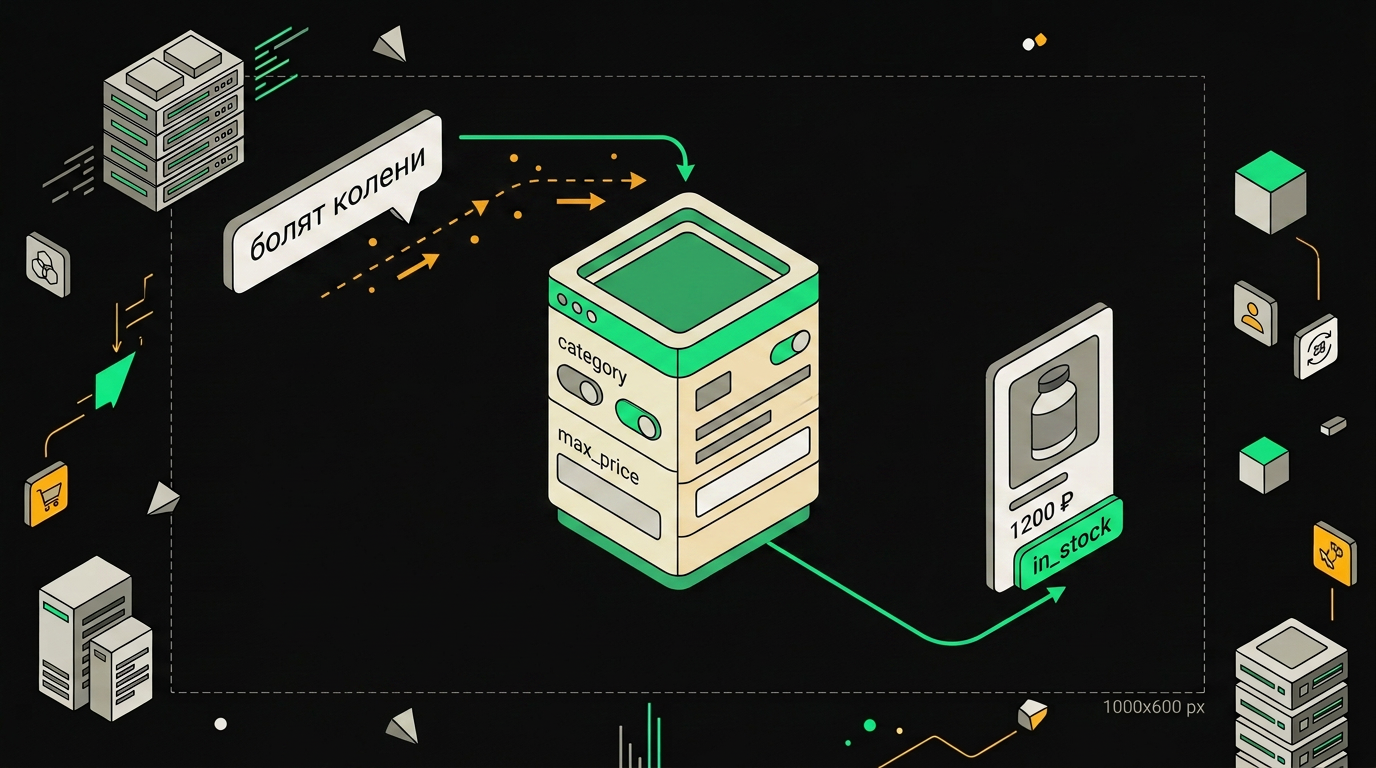
Инструмент поиска принимает параметры из запроса пользователя и отдаёт агенту отфильтрованный список позиций.
Tool create_lead: оформление заказа в RetailCRM
Когда агент дошёл до момента "оформляем?" и пользователь сказал "да", модель должна вызвать ровно один tool: create_lead. Под капотом это POST на /api/v5/orders/create. RetailCRM до сих пор принимает форму как application/x-www-form-urlencoded, где поле order это JSON-строка. Это важно, иначе n8n улетит с 400 и невнятным ответом.
Минимальный набор полей, который мы реально требуем от модели: firstName, phone, items (массив {offer: {externalId}, quantity}). Email опционален, чаще приходит пустым, и это нормально, оператор добьёт.
Валидация телефона до вызова tool
Без этого шага модель примерно в 5-7% случаев передаёт телефон буквально как +7 (XXX) XXX-XX-XX или с произвольными пробелами, если пользователь так написал. Парсер RetailCRM это съест, но дальше дедуп клиентов сломается. Поэтому в ноде перед HTTP Request ставлю Function:
const raw = $fromAI('phone');
const digits = raw.replace(/\D/g, '');
const normalized = digits.startsWith('8') ? '7' + digits.slice(1) : digits;
if (!/^7\d{10}$/.test(normalized)) {
throw new Error(`Bad phone from AI: ${raw}`);
}
return [{ json: { phone: '+' + normalized } }];
Если регулярка не прошла, я не вызываю CRM, а возвращаю модели ошибку phone_invalid, и она переспрашивает пользователя. Это дешевле, чем чистить дубликаты вручную.
Сам вызов
POST /api/v5/orders/create
Content-Type: application/x-www-form-urlencoded
site=nutrishop
order={
"externalId": "ai_{{$json.sessionId}}_{{$now.toMillis()}}",
"firstName": "{{ $fromAI('first_name') }}",
"phone": "{{ $fromAI('phone') }}",
"status": "new-ai-agent",
"items": {{ $fromAI('items') }},
"customFields": {
"ai_dialog_summary": "{{ $fromAI('summary') }}",
"ai_goals": "{{ $fromAI('goals') }}"
}
}
Пара деталей по полям.
status: "new-ai-agent" это кастомный статус, который я завожу руками в админке RetailCRM (Настройки → Статусы заказов, группа "Новый"). На него вешается фильтр в воронке оператора, и в Telegram-канал отдела падает уведомление. Без отдельного статуса оператор не видит, что корзину собрал бот, и звонит как по обычной заявке, а это другой скрипт разговора.
externalId собираю как ai_{sessionId}_{timestamp}. Идемпотентность тут грубая, но рабочая: если n8n ретраит ноду из-за таймаута сети, второй вызов уйдёт с тем же externalId в пределах секунды и RetailCRM вернёт 400 на дубль, а не создаст вторую карточку. Если модель сама решит "позвать tool ещё разок" (бывает на gpt-4o при длинных диалогах), timestamp уже другой, но сценарий редкий и оператор увидит два заказа с похожим summary, схлопнет вручную.
customFields.ai_dialog_summary это последние 10 сообщений, которые я склеиваю отдельным шагом перед вызовом tool, не доверяя модели саммари самой себе. Беру буквальный транскрипт, обрезаю до 2000 символов. ai_goals короче: список того, что человек назвал целью ("сбросить 5 кг к лету", "восстановиться после тренировок"). Оба поля заранее заведены как "Текст" в Настройки → Поля и словари → Поля заказа.
По обратной связи операторов заказы с заполненным summary позволяют быстрее войти в суть разговора при звонке: не нужно заново выяснять контекст, можно сразу переходить к уточнениям и апсейлу.
Память диалогов и контекст между сессиями
Память я держу в Postgres, не в Redis и не в файлах. Нода Postgres Chat Memory в n8n, sessionKey берётся либо из виджета на сайте (uuid пользователя в localStorage), либо из telegram.chat_id. Это даёт сквозную историю: клиент написал в чат на сайте



