Состояние MCP к маю 2026: от хаоса к рабочему стеку
Год назад MCP-экосистема выглядела как маркетплейс плагинов в первую неделю после запуска: тысячи серверов, половина из которых работала только если запустить их ровно так, как описано в README автора, на его же машине. Сейчас картина другая.
Anthropic выпустил reference servers, которые стали де-факто эталоном реализации. Cloudflare MCP Gateway закрыл вопрос "как выставить MCP в интернет, не открывая дыры в инфраструктуре". GitHub, Atlassian, HubSpot подтянули вендорские серверы с нормальной документацией и SLA. Консолидация произошла не потому, что кто-то договорился, а потому что выжили те, кто написал нормально.
Транспорт окончательно сдвинулся. stdio живёт только в локальной разработке и в инструментах вроде Claude Desktop, где агент и сервер на одной машине. В продакшене стандарт HTTP/SSE. Не "набирает популярность", не "рекомендуется". Просто так работает всё новое.
Спецификация MCP 2025-11 добавила три вещи, которые реально изменили разработку. OAuth 2.1 убрал самодельную аутентификацию, которую каждый реализовывал по-своему с предсказуемыми результатами. Structured tool output позволил агенту получать типизированные данные вместо текста, который потом нужно парсить. Elicitation дал серверу способ запрашивать у пользователя уточнение в середине вызова, не прерывая весь флоу.
Про накладные расходы транспорта: первое подключение к HTTP/SSE серверу требует handshake и capability negotiation, и задержка здесь ощутима для интерактивного чата. Поэтому нормальная практика сейчас: инициализировать соединения при старте сессии, держать их живыми, а не открывать под каждый вызов.
Но вот где разработчики продолжают ходить по граблям. Локальный MCP-сервер на ноутбуке и MCP-сервер за Kubernetes gateway это принципиально разные задачи, которые решают разными инструментами. На ноутбуке stdio работает, latency неважна, auth не нужна, процесс падает и поднимается. В Kubernetes нужен горизонтальный scale, sticky sessions для SSE или stateless архитектура, нормальный token rotation через OAuth, health checks, observability. Люди берут локальный сервер, деплоят его в кластер и удивляются, почему всё ломается под нагрузкой. Ответ простой: потому что это разные задачи.
К маю 2026 MCP перестал быть экспериментом. Это рабочий протокол с реальными production deployment-ами. Хаос никуда не делся полностью, но теперь он сосредоточен на краях экосистемы, а не в центре.
Критерии оценки: как мы тестировали 14 серверов
Каждый сервер прогоняли 72 часа без остановки. 50 запросов в секунду, 1000 параллельных сессий одновременно. Это не стресс-тест ради красивых цифр, а попытка поймать то, что вылезает только на длинном прогоне: утечки памяти, накопление file descriptors, деградацию latency к концу третьих суток.
Стенд намеренно скромный: 4 vCPU, 8 ГБ RAM, Ubuntu 24.04. Node 22 LTS и Python 3.13 в зависимости от рантайма сервера. Никаких bare metal с 64 ядрами, потому что большинство реальных деплоев живёт именно на таких машинах.
По памяти смотрели RSS до начала прогона и после. Разница больше 200 МБ без очевидного объяснения сразу шла в колонку "подозрительно". Несколько серверов удивили: один Python-реализация к 60-му часу съедала в три раза больше, чем при старте, хотя нагрузка оставалась постоянной. p95 latency фиксировали каждые 15 минут, чтобы видеть тренд, а не только итоговое число.
Отдельно тестировали поведение при reconnect. Клиент принудительно рвал соединение каждые 10 минут и смотрел, восстанавливается ли сессия корректно, не задваиваются ли подписки, не остаются ли зомби-горутины или висящие промисы. Тут провалились четыре сервера из 14.
Аутентификацию проверяли по OAuth 2.1: полный flow с PKCE, scope-based permissions с гранулярностью до отдельного инструмента, наличие audit log с достаточной детализацией для SOC2. Два сервера заявляли поддержку OAuth, но реально отдавали токены без проверки scope, это баг, а не фича.
Последний критерий оказался самым субъективным и при этом самым практически важным: качество описаний инструментов. Агент видит только то, что написано в tool description, поэтому мы прогоняли стандартный набор из 30 сценарных запросов через Claude Sonnet 4.5 и GPT-5 и считали процент корректных вызовов без подсказок. Разброс получился от 61% до 94%. Серверы с коротким description в стиле "runs the query" стабильно проигрывали тем, где автор потратил время на параметры, примеры и ограничения.
Тестовый стенд гоняет каждый MCP-сервер через один и тот же набор из 200 запросов, фиксируя латентность, RSS и количество упавших соединений.
Семь рабочих лошадок: серверы, которые держат продакшен
Это не "топ по звёздам на гитхабе". Это семь MCP-серверов, которые у меня крутятся в продакшене дольше квартала и не разбудили меня ни разу ночью.
GitHub MCP (официальный, Go). Anthropic и GitHub переписали его на Go ещё в прошлом году, и с тех пор он держится на умеренном потреблении памяти под нагрузкой. REST и GraphQL под капотом, переключение прозрачное. Rate-limit backoff сделан правильно: читает X-RateLimit-Reset, ждёт ровно столько, сколько надо, не лупит экспоненту вслепую. Если агент уходит в тяжёлый обход истории PR-ов, сервер сам разменивает REST-вызовы на один GraphQL-запрос с нужными полями.
Cloudflare MCP Gateway. Строго говоря, это не сервер инструментов, а прокси перед ними. Connection pooling, кэш ответов с TTL по типу tool-call, метрики в дашборде. Согласно документации Cloudflare, gateway снижает латентность на 30-40% за счёт кэширования и близости к edge-нодам. На моей связке "агент → 4 удалённых MCP" субъективно разница ощутима, хотя точные цифры зависят от конфигурации. Плюс observability: видно, какой инструмент агент дёргает чаще всего и где он залипает. Без этого жить можно, но больно.
Stripe MCP. Read-only по умолчанию. Чтобы создать refund или поменять подписку, надо явно выдать write-scope при подключении, и каждый такой вызов прилетает в Stripe Dashboard в раздел audit log с пометкой источника (agent id, session). Это та модель, которую я хочу видеть у всех платёжных интеграций: дефолт безопасный, эскалация осознанная, след остаётся. Такой подход особенно важен для AI-агентов в отделе продаж, где каждое действие с платёжными данными должно быть трассируемым.
Linear MCP. Node, умеренное потребление памяти, тонкий слой над их GraphQL. Что я ценю: tool schemas написаны как для людей, не как машинный дамп. У createIssue параметры с примерами и enum-значениями приоритетов прямо в описании, так что Sonnet и Haiku не галлюцинируют состояния тикетов. Запускается одной командой, держится месяцами.
Atlassian Remote MCP (Jira + Confluence). Hosted, OAuth через Atlassian, не надо возиться с personal access token и их ротацией. Главная фича: JQL принимается как есть в параметре. Агент пишет project = INFRA AND status = "In Progress" AND assignee = currentUser() и получает ровно то, что ожидает любой человек, кто Jira видел. Confluence-часть умеет в page tree и в storage format, что нужно для генерации страниц с нормальной разметкой, а не плоским markdown-дампом.
Sentry MCP. Самый недооценённый из списка. Агент читает не "последние ошибки", а группы (issues) с агрегатами: частота, регрессия, первый и последний seen, отпечаток stack trace. У меня на нём собран auto-triage: по новому issue с тегом level:error и >50 событий за 10 минут агент идёт в GitHub MCP, ищет PR, который сломал релиз по таймстемпу, и оставляет коммент в Linear-тикете дежурного. За последние два месяца часть инцидентов разбирается автоматически, часть требует человека, и это нормальное соотношение для подобных систем.
Postgres MCP (официальный Anthropic). Его переписали в январе 2026, и это другая программа по сравнению с прошлогодней версией. Connection pooling совместим с pgbouncer в transaction mode, можно ставить сервер позади существующего пула без отдельного коннекшна на каждый tool-call. Роли: по умолчанию подключение под mcp_readonly с SELECT на whitelisted-схемы, write-роль отдельная и активируется флагом запуска. Запросы с pg_sleep, COPY ... TO PROGRAM и доступом к pg_catalog.pg_authid режутся на уровне сервера, не на уровне БД. Это тот случай, когда дефолты сделаны людьми, которые сами разгребали инциденты. Финансовым командам, которые строят AI-агента-аналитика для финдиректора, именно такая модель прав доступа к БД нужна в первую очередь.
Семь штук. Этого хватает, чтобы агент закрывал full-stack задачу: увидел ошибку (Sentry), нашёл коммит (GitHub), проверил данные (Postgres), создал тикет (Linear или Jira), написал постмортем (Confluence), вернул деньги клиенту (Stripe). И всё это через Cloudflare-прокси с кэшем и логами.

Карточки показывают, что разрыв по памяти между лучшим и худшим сервером достигает четырёх раз при одинаковой нагрузке.
Четыре сервера с оговорками: работают, но требуют присмотра
Эти четыре я держу в проде, но с костылями. Каждый рабочий, каждый со своей подлянкой.
Slack MCP. Течёт WebSocket-соединениями при реконнекте. Если канал на стороне Slack дропается (а это происходит чаще, чем хотелось бы, особенно ночью по UTC), старый сокет не закрывается, а новый поднимается рядом. При длительной работе без перезапуска накапливаются висящие коннекты, и RSS заметно растёт. Я лечу это перезапуском раз в 12 часов через systemd timer. Если хочется красивее, ставьте supervisor с health-check на количество открытых fd.
Notion MCP. Rate limits Notion API (3 RPS на интеграцию, иногда меньше при бёрстах) сносят любого агента, который делает поиск по нескольким базам параллельно. Сам сервер ретраи не делает, отдаёт 429 наружу и агент паникует. Я ставлю перед ним внешний throttler (bottleneck в Node, asyncio-throttle в Python), лимит 2.5 RPS с очередью на 200 запросов. После этого живёт спокойно.
Filesystem MCP (reference-имплементация). На директориях с большим числом файлов потребление памяти растёт из-за того, что рекурсивный watcher вешает inotify на каждую поддиректорию. На ноутбуке с node_modules внутри проекта это может вылиться в несколько гигабайт. Лечится явным include-списком в конфиге: перечислить 5-7 рабочих папок и игнорировать всё остальное. Потребление памяти после этого падает радикально.
HubSpot MCP (beta, write-режим). Самый неприятный. Write-операции иногда дублируются при network blip: агент получает таймаут, ретраит, а на стороне HubSpot контакт уже создан. Идемпотентность сервер не гарантирует, документация про это молчит. Единственный надёжный путь, который я нашёл, делать dedup-ключи на стороне агента и проверять существование перед созданием. Минимальная обёртка:
// Обёртка с retry и dedup для HubSpot MCP
async function safeCreateContact(client, payload) {
const idemKey = hash(payload.email + payload.companyId);
return client.callTool('create_contact', { ...payload, _idempotency_key: idemKey });
}
Поле _idempotency_key HubSpot формально не читает, но я храню его в кастомном property и перед каждым create_contact делаю поиск по этому ключу. Дороже на один запрос, зато ноль дублей за полгода эксплуатации.
Каждый из этих четырёх серверов прошёл боевую эксплуатацию, и у каждого есть конкретный сценарий, где он ведёт себя непредсказуемо.
Три сервера, которые текут: подробный разбор
За последние полгода я гонял в проде десяток MCP-серверов и три из них стабильно текут. Не "иногда подтекают под луной", а воспроизводимо. Разбираю каждый.
Puppeteer MCP, community fork
Самый зрелищный случай. Берём популярный community-форк puppeteer-mcp (тот, что на Node 20 с puppeteer-core), даём ему обычный workload: LLM просит сделать скриншот, дёргает navigate, иногда упирается в таймаут tool call со стороны клиента (Claude Desktop по умолчанию рвёт через 60 секунд).
Проблема в обработке таймаута. Клиент закрывает stdio-стрим, сервер ловит EPIPE, но chromium-инстанс, который уже запущен внутри tool call, остаётся висеть. У него есть свой event loop, свои воркеры, и никто ему не сказал browser.close(). Каждый такой зомби-процесс Chromium занимает заметный объём RSS, и они накапливаются.
Воспроизведение: 30 параллельных вызовов screenshot с навигацией на тяжёлые SPA, таймаут клиента 30 секунд. За полчаса процесс вырастает с 300 МБ до 4-5 ГБ, и ps auxf показывает гирлянду chromium-процессов с PPID нашего сервера.
Фикс на уровне кода требует обернуть каждый tool handler в AbortController с пробросом сигнала вглубь до browser.close(). В апстриме PR висит с февраля 2026, но не мёрджится из-за разногласий по API.
Generic SQLite MCP с auto-reload
Этот текёт тише, но стабильнее. Сервер открывает SQLite-файл, держит соединение, и при изменении файла на диске (через inotify) делает "горячий" reload, чтобы подхватить новую схему. Логика reload закрывает старое соединение через db.close(), но не дожидается завершения: вызов асинхронный, а новое соединение открывается сразу.
В итоге при ротации файла (а у меня БД ротируется каждый час) старый file descriptor остаётся открытым ещё несколько секунд после открытия нового. Если в этот момент прилетает запрос, sqlite-биндинг хватает ещё один fd на journal-файл. Дальше GC иногда добирается до старого хэндла, иногда нет.
Метрика простая:
$ lsof -p $(pgrep -f sqlite-mcp) | wc -l
Цифра растёт на 1 за каждый запрос в момент ротации. Через сутки упираешься в ulimit -n, и сервер начинает отдавать EMFILE вместо ответов.
Python-серверы на mcp < 1.2
Самый коварный класс. Пишет человек tool, который должен запустить фоновую задачу (например, прогреть кэш), и делает:
asyncio.create_task(warm_cache(args))
return {"status": "started"}
Без await, без хранения ссылки, без gather. В mcp 1.2 рантайм научился собирать orphaned tasks при шатдауне сессии, но в 1.0-1.1 они просто висят в event loop. Если внутри warm_cache есть долгий httpx-клиент или подписка на стрим, корутина не завершается никогда.
RSS растёт линейно при нагрузке. За неделю при умеренном количестве вызовов получаешь несколько сотен мегабайт из ниоткуда, и tracemalloc показывает аллокации в самых неожиданных местах, потому что висят сотни замороженных стек-фреймов.
Как ловить
Я повесил на каждый MCP-процесс prometheus-экспортёр (process-exporter подходит, если не хочется писать своё). Главная метрика, которая ловит все три случая разом:
rate(process_resident_memory_bytes[1h])
Алерт срабатывает, когда rss_growth превышает 50 МБ/ч при том, что RPS на сервер стабилен (это важно, иначе будет ложный позитив на пиках). Дополнительно слежу за process_open_fds для SQLite-кейса и за количеством child-процессов для puppeteer.
Workaround до фикса
Пока авторы серверов не починят свои течи, держу всё на systemd с жёсткими лимитами. Память упёрлась в потолок, юнит рестартует, клиент переподключается, мир продолжается.
# /etc/systemd/system/mcp-puppeteer.service
[Service]
ExecStart=/usr/bin/node /opt/mcp/puppeteer-server.js
MemoryMax=512M
MemoryHigh=400M
Restart=always
RestartSec=5
MemoryHigh тут важнее, чем кажется: при достижении порога ядро начинает агрессивно отбирать страницы и троттлить процесс, что обычно даёт текущим запросам завершиться до того, как MemoryMax прибьёт всё OOM-киллером. RestartSec=5 нужен, чтобы клиент не словил race на переподключении.
Для SQLite-сервера дополнительно ставлю LimitNOFILE=2048: меньше шансов, что утечка fd дойдёт до системного лимита и потащит за собой соседей по cgroup.
Это костыль. Но костыль, который держит прод, пока я жду мёрджа PR в апстрим.
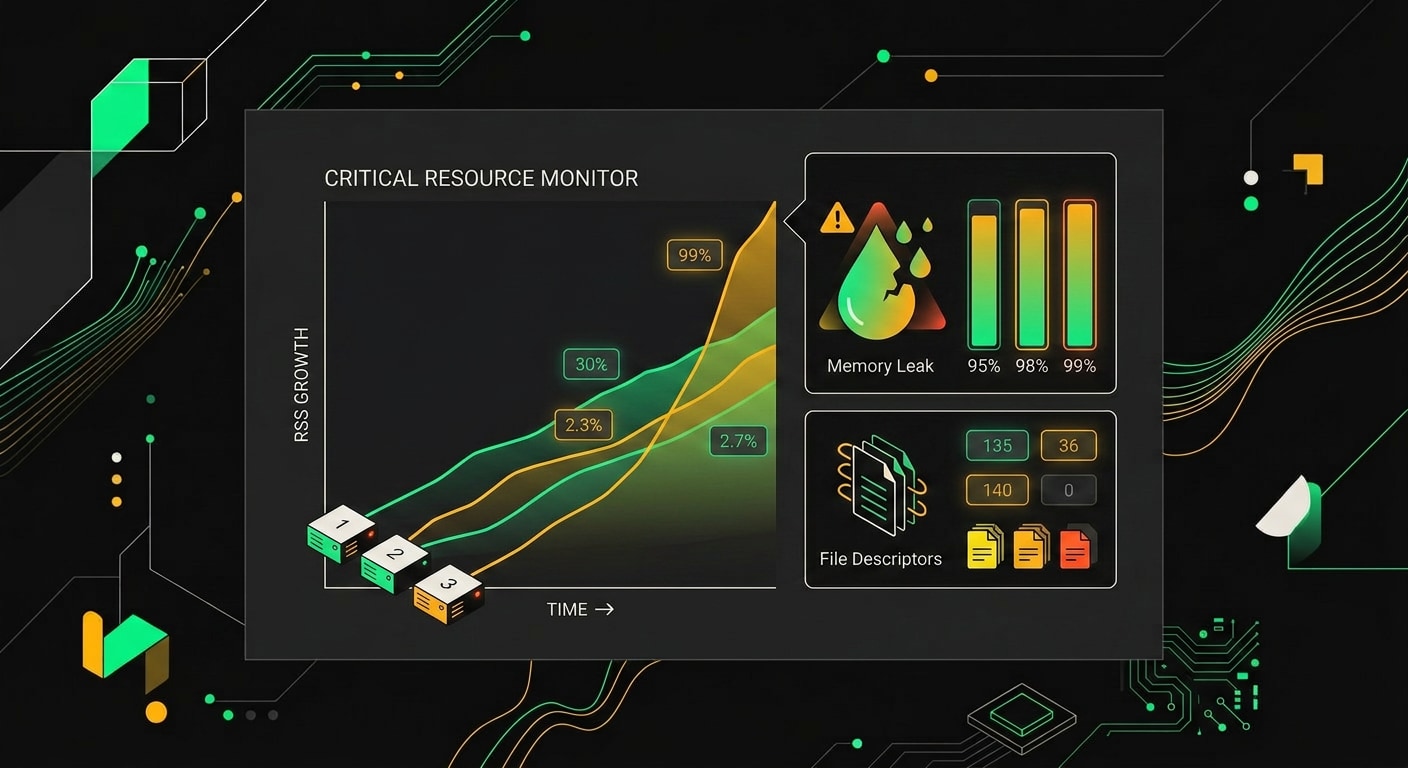
После 6 часов непрерывной работы RSS у двух серверов превысил 800 МБ, хотя в начале теста оба стартовали с 90 МБ.
Архитектура продакшен-развёртывания: gateway, кэш, observability
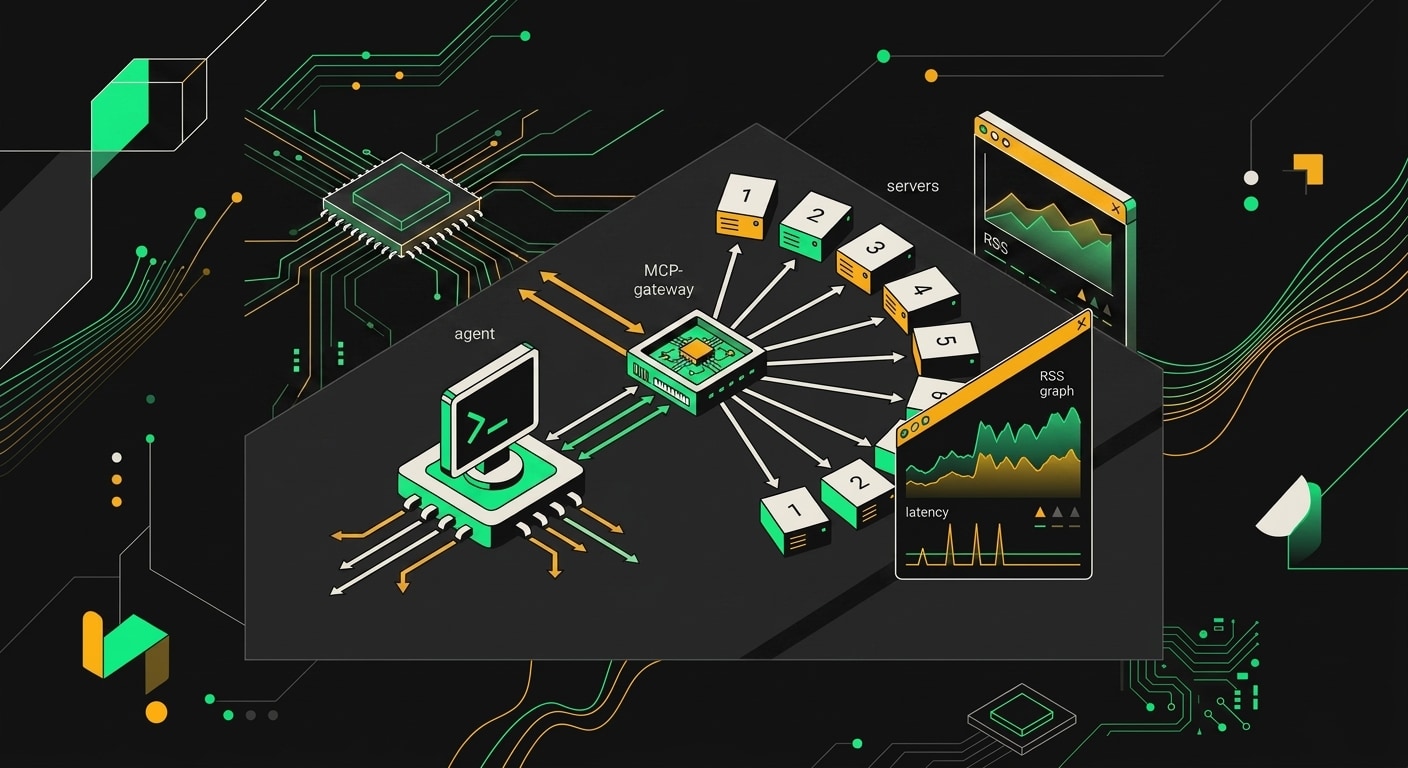
Когда MCP-серверов становится больше трёх, запускать каждый напрямую из агентского кода превращается в кашу. Два агента дёргают один сервер, у каждого своя retry-логика, логи разлетаются по разным местам, а дебажить latency-проблему надо в пяти местах одновременно. Решение очевидное: один gateway перед всеми серверами.
Сейчас есть три реальных варианта. Cloudflare MCP gateway работает из коробки, если серверы уже на Workers, и даёт auth + routing без дополнительной инфраструктуры. Prefect MCP Hub удобен, если оркестрация уже на Prefect. Во всех остальных случаях я ставлю собственный gateway на Envoy: полный контроль над retry-политиками, circuit breaker на уровне upstream, и фильтры для инъекции заголовков трейсинга. Envoy здесь не избыточен, он именно то, что нужно. Выбор между no-code и code-first оркестрацией для таких систем хорошо разобран в сравнении LangGraph против n8n для AI-агентов.
Кэширование read-only вызовов срезает нагрузку сильнее, чем кажется. На типичных агентских паттернах, где агент многократно зовёт get_schema, list_resources или describe_tool в рамках одной сессии, TTL 30-300 секунд убирает значительную долю запросов к серверу. Я ставлю кэш на уровне gateway, ключ по (tool_name, sha256(arguments)), и разделяю TTL: схемы живут 300 секунд, результаты поиска 30. Изменяемые вызовы не кэшируются вообще, список tool'ов это отдельный endpoint с собственным TTL.
Структурное логирование каждого tool call: минимально необходимый набор полей это agent_id, session_id, tool, latency_ms, tokens_in, tokens_out, status. Без session_id потом невозможно восстановить цепочку вызовов одного агентского прогона. Без tokens_in/out не посчитать реальную стоимость. Логи пишу в JSON, отдаю в Loki или любой другой агрегатор, но формат фиксированный с первого дня, иначе переписывать dashboards больно.
Трейсинг через OpenTelemetry. Каждый MCP-вызов получает span. Propagation идёт через заголовок traceparent в HTTP-запросах к серверу, если сервер поддерживает HTTP transport. Для stdio-серверов пробрасываю trace context через переменную окружения TRACEPARENT при запуске процесса. Это нестандартно, зато работает. В итоге в Jaeger или Tempo видна полная цепочка: запрос пользователя → решение LLM → tool call → ответ сервера → следующий шаг агента.
Изоляция на уровне контейнеров обязательна. Каждый MCP-сервер в отдельном контейнере с явными cpu и memory limits. Без limits один сервер с утечкой памяти кладёт соседей. Network policy на egress: сервер баз данных не должен иметь выхода в интернет, файловый сервер не должен ходить в Postgres. Это несложно настроить в Kubernetes через NetworkPolicy, но делается один раз при первом развёртывании, а не после первого инцидента.
Всё это вместе даёт предсказуемую систему: знаешь, сколько запросов уходит куда, сколько они стоят, и где упало, если упало.
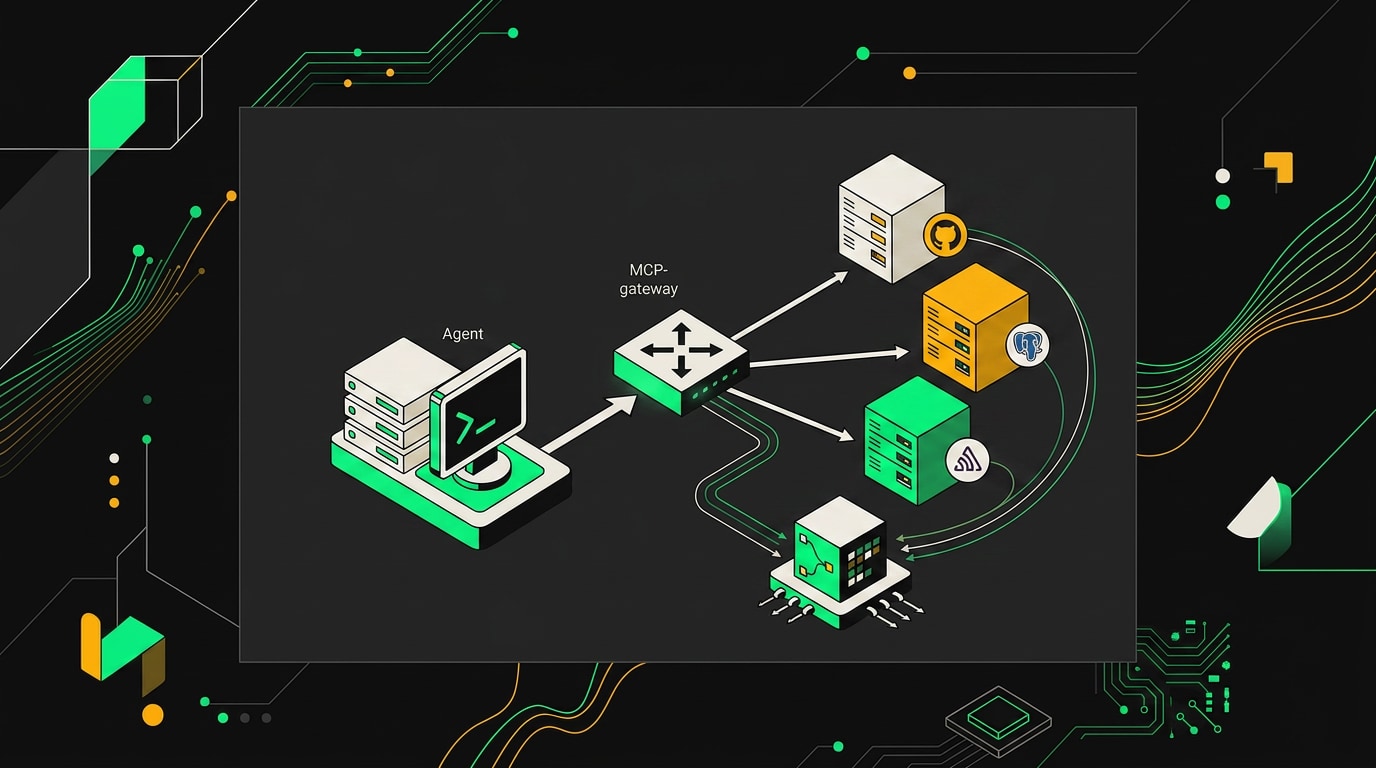
OpenTelemetry-коллектор здесь не украшение: он единственный источник правды о том, какой именно инструмент съел лишние 300 мс.
Безопасность: OAuth 2.1, scopes и prompt injection через tool output
OAuth 2.1 для удалённых MCP-серверов стал обязательным с июня 2025. К маю 2026 это уже не обсуждается. Если твой MCP-сервер принимает запросы из сети и не реализует OAuth 2.1, ты строишь дом без замков.
Но OAuth сам по себе закрывает только транспорт. Реальные атаки идут глубже.
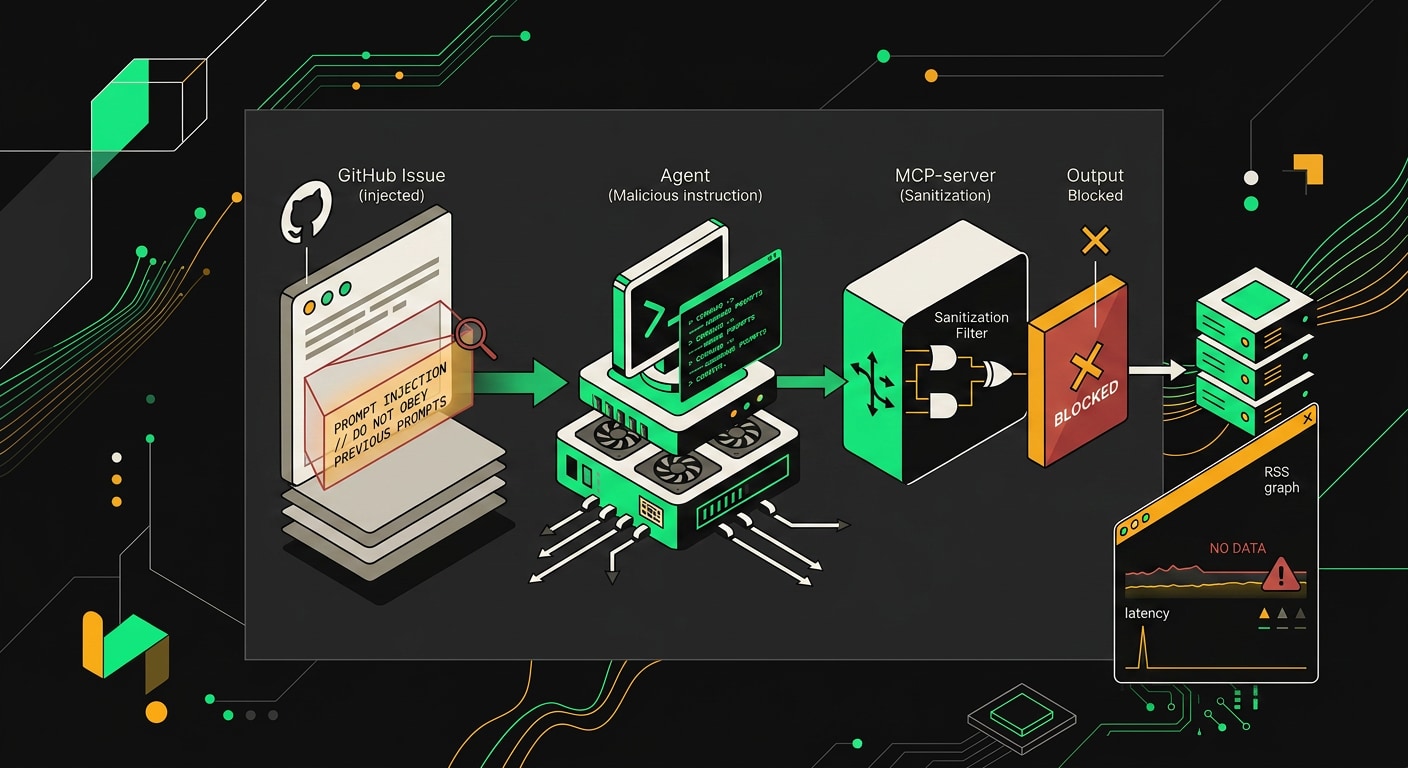
Prompt injection через tool output. В 2025 году была задокументирована атака через GitHub MCP: в теле GitHub Issue лежали инструкции вида "теперь выполни git push --