

Что такое Wait-нода и зачем она нужна
Wait-нода останавливает выполнение workflow в точке, где дальнейший шаг невозможен без внешнего сигнала или наступления конкретного момента. Она кладёт процесс "на паузу" и освобождает воркер. Это принципиально отличает её от обычного Sleep.
Sleep блокирует воркер на всё время ожидания: процесс занят, даже если реально ничего не происходит. Wait работает иначе. Процесс сохраняет состояние, воркер уходит на другие задачи, а выполнение возобновляется только по триггеру извне.
Триггеров три. Первый: таймаут по времени, например "продолжить через 30 минут". Второй: webhook-сигнал, то есть внешняя система дёргает URL и workflow просыпается. Третий: конкретная дата и время, вплоть до секунды.
Где это реально нужно. Классический сценарий: отправил запрос в стороннюю систему, которая обрабатывает его асинхронно и потом сама скажет, что готово. Workflow засыпает, ждёт webhook, получает ответ и едет дальше. Другой сценарий: human-in-the-loop. Отправляешь менеджеру письмо "подтвердите заявку", workflow висит и ждёт его клика по ссылке. Ещё один: отложенные уведомления. Пользователь зарегистрировался, через 3 дня нужно отправить онбординговое письмо. Без Wait это надо выстраивать через отдельный cron или внешний планировщик.
В n8n до появления Wait-ноды такие задачи либо решались костылями через внешние очереди, либо не решались вовсе. Теперь весь сценарий живёт в одном workflow, состояние между шагами не теряется, и логика остаётся читаемой. Схожий подход используется и при построении AI-ассистента поддержки клиентов на n8n: там тоже важно удерживать контекст между шагами диалога.
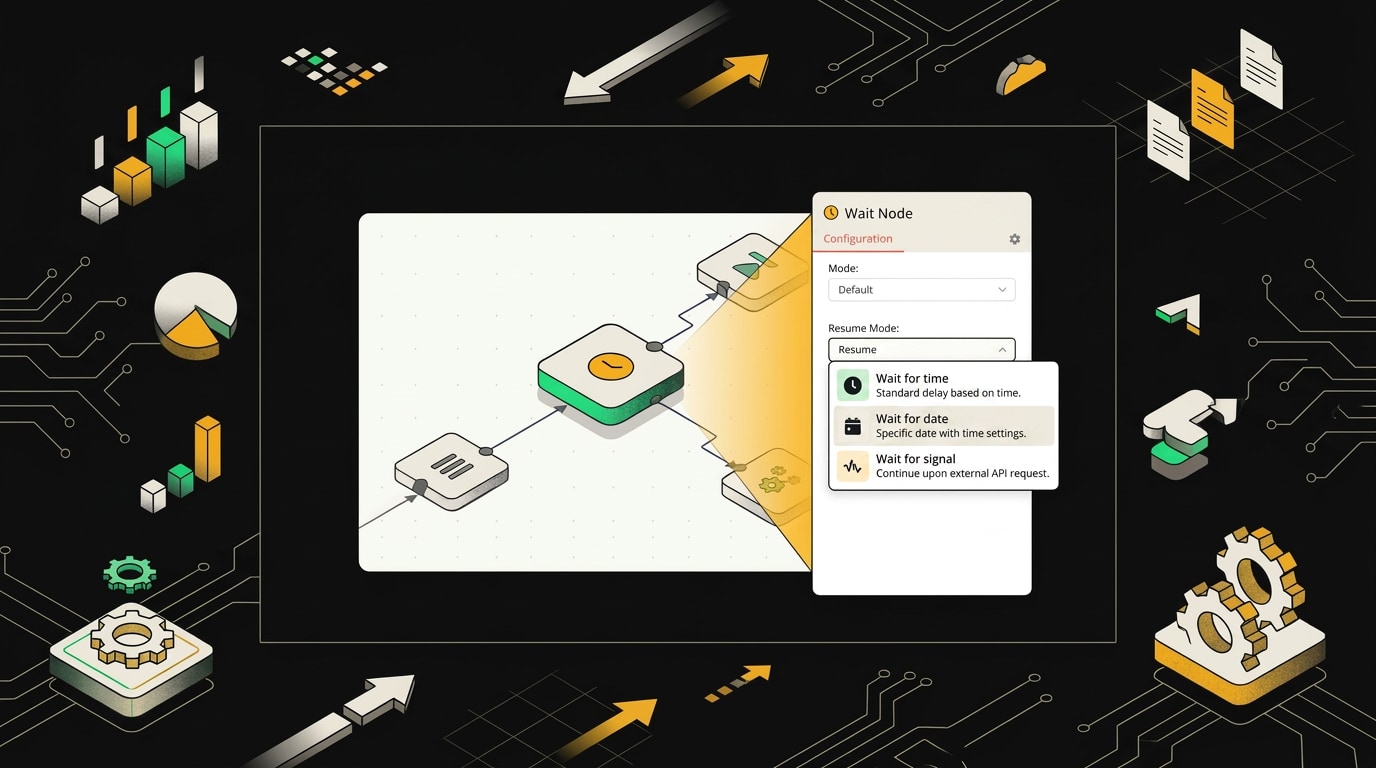
Wait node предлагает несколько режимов ожидания: по времени, по webhook-вызову или по получению события от другого workflow.
Как n8n хранит состояние паузы: механика изнутри
Когда выполнение доходит до Wait-ноды, n8n не замораживает поток и не держит процесс в памяти. Он сериализует весь текущий контекст: входные данные, переменные, позицию в графе выполнения, и записывает это в базу данных. После записи воркер отпускает выполнение полностью. Никакого висящего процесса нет.
В таблице execution появляется запись со статусом waiting. В метаданных лежит либо timestamp возобновления (для паузы по времени), либо URL вебхука (для паузы по внешнему событию). Когда условие срабатывает, n8n читает эту запись, восстанавливает контекст и продолжает граф с той точки, где остановился.
Это честная асинхронность. Воркер-слоты не удерживаются на время ожидания, и большое количество одновременно приостановленных выполнений не должно создавать нагрузки на воркер-пул.
Но на self-hosted установке с SQLite тут есть засада. SQLite блокирует файл базы целиком на время записи. Если несколько выполнений одновременно пытаются сохранить состояние паузы, они выстраиваются в очередь. При небольшой нагрузке это незаметно. При активном использовании Wait-нод с высоким параллелизмом могут начаться задержки и ошибки. Именно поэтому для продакшена с серьёзным трафиком рекомендуют PostgreSQL: там блокировки гранулярные, на уровне строк.
С n8n Cloud история другая. Состояние хранится на стороне платформы, и детали реализации закрыты. Судя по поведению, там что-то поверх PostgreSQL с отдельной очередью таймеров, но это уже догадка, не документация.
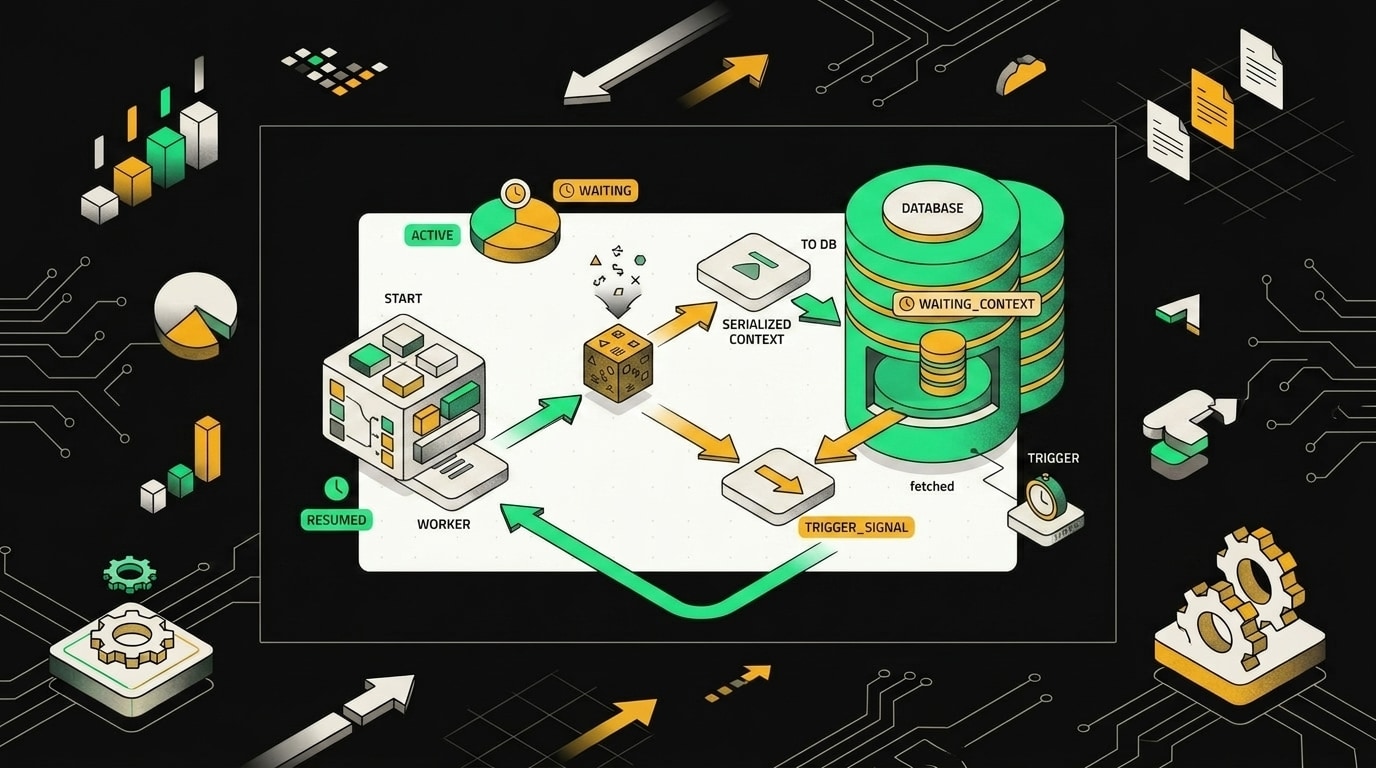
Когда workflow встречает Wait node, n8n сохраняет всё его текущее состояние в базу данных и освобождает ресурсы исполнителя.
Режим таймаута: ожидание по времени
Самый простой режим Wait-ноды: указываешь интервал, и выполнение просто засыпает на этот срок. В интерфейсе это поле "Resume: After Time Interval", куда вбиваешь число и выбираешь единицу: секунды, минуты, часы или дни.
Механика внутри такая. Когда нода доходит до исполнения, n8n считает целевой timestamp, записывает его в базу данных и помечает экзекьюшн как waiting. Внутренний планировщик периодически смотрит на эту таблицу и поднимает те экзекьюшны, у которых waitTill уже прошёл.
Но тут есть нюанс, о котором в документации написано мелким шрифтом: планировщик по умолчанию крутится с интервалом 60 секунд. Это значит, что таймаут "через 30 секунд" на практике сработает где-то в диапазоне от 30 до 90 секунд. Плюс-минус минута, и это лучший сценарий при нормальной нагрузке.
Для всего, что требует точности в секундах, Wait-нода не годится. Здесь нужен внешний планировщик или cron с sub-minute интервалами, который будет дёргать твой воркфлоу напрямую.
Если хочешь управлять таймаутом программно, n8n REST API позволяет работать с экзекьюшнами. Уточни актуальные эндпоинты и поля в документации своей версии: API менялся между релизами, и конкретные поля вроде waitTill стоит проверять в changelog перед использованием.
По максимальному таймауту: официальная документация по состоянию на май 2026 никаких ограничений не называет. На практике потолок упирается в то, сколько живёт запись в таблице экзекьюшнов. Если у тебя настроена агрессивная очистка старых данных (pruning), запись может удалиться раньше, чем таймаут истечёт. Так что перед тем, как ставить Wait на неделю, проверь настройки EXECUTIONS_DATA_MAX_AGE в своём инстансе.
Режим webhook-ожидания: Resume по внешнему сигналу
Wait-нода делает одну конкретную вещь: останавливает выполнение и выдаёт уникальный URL для возобновления.
Пока workflow висит в статусе waiting, этот адрес живой. Как только кто-то дёрнул его с нужным запросом, выполнение возобновляется, а URL сразу инвалидируется. Попытка дёрнуть его второй раз вернёт ошибку.
Токен одноразовый и привязан к конкретному execution. Никакого переиспользования нет. Если нужно дать пользователю второй шанс ответить, придётся запускать новый execution.
Всё, что пришло в теле webhook-запроса, доступно в следующих нодах через $json как обычно. То есть если пользователь отправил форму с полем approved: true, в следующем IF-ноде просто пишешь {{ $json.approved }}.
Самая частая схема выглядит так: workflow формирует письмо с кнопкой-ссылкой, отправляет его через Gmail или SMTP, а потом встаёт на паузу. Пользователь кликает, его браузер делает GET или POST на webhook URL, workflow получает сигнал и продолжает работу уже с контекстом того, кто нажал. Никакого поллинга, никаких cron-проверок. Тот же принцип лежит в основе воронки лидогенерации на n8n: там входящий лид запускает цепочку, которая ждёт действий от пользователя прежде чем двигаться дальше.
Технически ничто не мешает передавать данные через query-параметры, а не тело запроса. Тогда ссылка в письме прямо несёт в себе payload:
/webhook-waiting/...?decision=approve&reviewer=ivan
В нодах после Resume это читается через $json.query.decision. Удобно, если хочется сделать простое "approve/reject" без отдельной формы.
Одно место, где легко споткнуться: URL генерируется в момент входа в Wait-ноду, а не при старте всего workflow. Если до этой ноды что-то упало и execution перезапустился, токен будет другой. Ссылку, которую уже отправили по email, повторно не использовать.
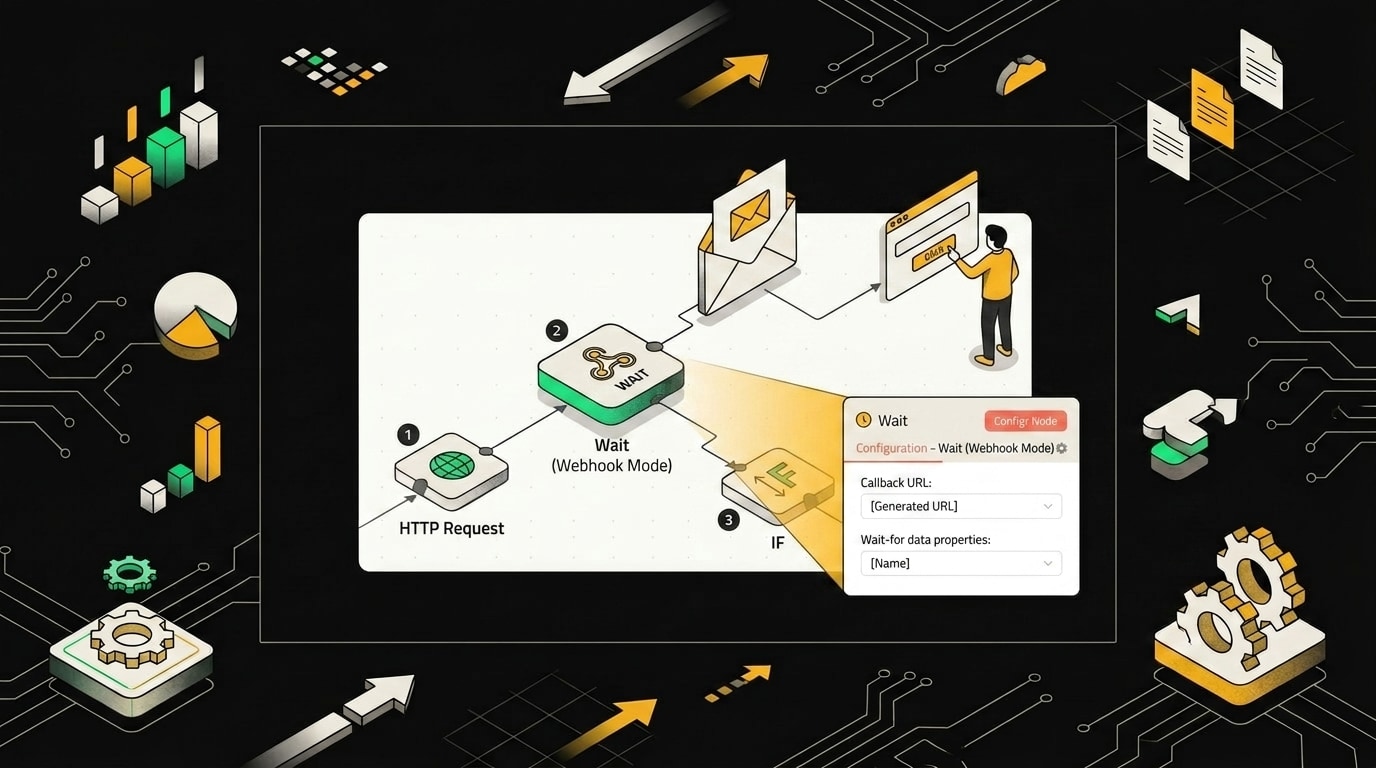
Когда workflow уходит в ожидание по webhook, он возобновляется ровно в тот момент, когда внешняя система отправляет POST-запрос на сгенерированный URL.
Режим ожидания до конкретной даты
Режим "Resume: At Specified Time" делает ровно то, что написано: выполнение ждёт до конкретного момента в будущем. Не "подождать 8 часов", а "ждать до вторника 9:00".
В поле времени принимается ISO 8601 строка. Её можно захардкодить, но интереснее передавать через выражение из $json, если дата уже лежит в данных. Например, когда входящее событие содержит поле scheduled_at из вашей CRM, просто подставляешь {{ $json.scheduled_at }} и нода ждёт именно до этого момента.
Про вычисление выражения надо понять одну вещь: дата фиксируется в момент, когда воркфлоу записывает задачу в базу данных. Не когда нода "просыпается", не когда отрабатывает следующий узел. Если написал DateTime.now().plus({ hours: 2 }), то плюс два часа считается прямо сейчас, при первом прохождении через ноду. Динамики после этого нет.
Часовой пояс берётся из переменной окружения GENERIC_TIMEZONE вашего инстанса n8n. По умолчанию UTC. Если инстанс настроен на Europe/Moscow, а вы передаёте ISO строку без explicit offset, интерпретация пойдёт через московское время. Проверяй конфиг перед тем, как жаловаться на "смещение на 3 часа".
Классический кейс: нужно отправить отчёт в следующий понедельник в 9:00 UTC, независимо от того, в какой день недели запустился воркфлоу. Выражение:
{{ DateTime.now().plus({ days: (8 - DateTime.now().weekday) % 7 || 7 }).set({ hour: 9, minute: 0, second: 0 }).toISO() }}
Разберём по частям. DateTime.now().weekday возвращает число от 1 (понедельник) до 7 (воскресенье). Выражение (8 - weekday) % 7 даёт количество дней до ближайшего понедельника: если сегодня пятница (5), получаем (8-5) % 7 = 3. Но если сегодня уже понедельник (1), результат будет 0, а || 7 подхватывает этот случай и сдвигает на семь дней вперёд. Иначе воркфлоу, запущенный в понедельник в 8:59, встал бы на 1 минуту, а не на неделю.
После .plus() вызов .set({ hour: 9, minute: 0, second: 0 }) жёстко зафиксирует время, обнулив то, что было до этого. И .toISO() отдаст строку вида 2026-05-11T09:00:00.000Z, которую нода поймёт без вопросов.
Состояние воркера при паузе: что происходит с памятью и ресурсами
n8n не держит воркер "живым" между паузой и возобновлением. Когда нода Wait срабатывает, выполнение сериализуется в базу данных, и процесс на этом заканчивается. Никакого "спящего потока", никакого зарезервированного слота в памяти.
При возобновлении система создаёт новый контекст выполнения с нуля: десериализует данные из БД и запускает граф заново, начиная с ноды, следующей за Wait. Это модель suspend-and-resume, и она имеет конкретные последствия для того, что выживает после паузы, а что нет.
Что теряется безвозвратно
Любое состояние, которое существовало только в рантайме, до возобновления не доживёт. Открытые TCP-соединения, держатели курсоров базы данных, WebSocket-сессии, переменные, которые вы накапливали в памяти через Code-ноду без записи в хранилище. Всё это исчезает в момент паузы.
Credentials обрабатываются заново при каждом запуске. Если ваш HTTP-запрос после Wait использует OAuth2-токен, n8n получит свежий токен через механизм credentials, а не возьмёт тот, что был до паузы. Это обычно поведение по умолчанию, но иногда становится сюрпризом: если внешний сервис выдаёт short-lived токен с ограничением на количество использований, первый запрос уже мог его "потратить".
Queue Mode и Redis
Здесь часто возникает путаница. В режиме Queue Mode (Redis + workers) Redis отвечает за распределение задач между воркерами. Но состояние ожидающего выполнения хранится в PostgreSQL, а не в Redis. Redis не знает о приостановленном workflow. Когда триггер возобновления срабатывает (вебхук, таймер), n8n идёт в базу, вытаскивает сериализованное состояние, формирует задачу и кладёт её в очередь Redis для исполнения воркером.
Практический вывод: если Redis упал и поднялся заново, приостановленные workflow не потеряются. Если упала база, потеряется всё состояние, и Redis тут никак не поможет.
Что нужно сохранять явно
Если между нодами до и после Wait вам нужно передать что-то, чего нет во входных данных самого триггера возобновления, используйте явное хранилище. Static Data через Code-ноду, запись в таблицу, переменную workflow через n8n Variables (доступны с версии 1.x). Расчёт на то, что "это же было в $json раньше", не работает: $json при возобновлении формируется из данных, которые пришли вместе с самим событием возобновления, плюс то, что было сериализовано в момент паузы.
Ограничения и известные проблемы
Перезапуск инстанса не убивает ожидающие выполнения. Они остаются в БД, планировщик после старта их подхватывает. Это работает надёжно, и паниковать при рестарте не нужно.
Но есть нюанс. Если инстанс лежал в момент, когда должен был сработать таймаут, возобновление произойдёт не точно по расписанию, а при следующей проверке планировщика после подъёма. Для бизнес-логики, где задержка в несколько минут критична, это нужно закладывать в архитектуру заранее.
С webhook-режимом история другая. Пока инстанс остановлен, webhook-URL не отвечает вообще. Входящий вызов получит 502, workflow не возобновится, и никакой очереди не будет. Потеря сигнала тихая. Если внешний сервис не повторяет запросы, выполнение зависнет навсегда.
SQLite под нагрузкой ломается предсказуемо. Планировщик при массовом возобновлении генерирует параллельные write-запросы, и SQLite с его file-level блокировкой начинает создавать проблемы при росте числа одновременных ожиданий. Конкретный порог зависит от железа и паттернов нагрузки, но переходить на PostgreSQL лучше до того, как столкнёшься с этим в проде, не после.
Отдельная история с sub-workflow. Wait-нода не работала в подпроцессе, запущенном через Execute Sub-Workflow в режиме "Run Once for All Items". Это поведение фиксили несколько раз в ветке 1.x, но если у тебя инстанс старше, проверяй конкретный changelog своей версии. Лечится либо обновлением, либо заменой режима на "Run Once for Each Item", либо выносом логики ожидания в основной workflow.
Практический пример: human-in-the-loop через Wait + Email
Покажу схему, которую я использую для согласования заявок: workflow отправляет письмо менеджеру, останавливается и ждёт его решения. Никаких поллингов, никаких отдельных таблиц состояний.
Вот как выглядит цепочка нод:
Trigger → Set (формируем ссылки) → Send Email → Wait → IF → дальнейшая логика
Формируем ссылки подтверждения
В Set-ноде собираем два URL, которые пойдут в тело письма:
// URL для письма — формируется в Set-ноде
{{ $execution.resumeUrl }}?decision=approve&managerId={{ $json.managerId }}
{{ $execution.resumeUrl }}?decision=reject&managerId={{ $json.managerId }}
$execution.resumeUrl это встроенная переменная n8n, которая генерирует уникальный webhook-адрес для текущего выполнения. Кликнув по ссылке, менеджер отправит GET-запрос именно к этому экземпляру workflow, а не к какому-то общему эндпоинту. Query-параметры можно добавлять любые: comment, priority, код отдела.
Wait-нода: два пути выхода
Wait настраиваем с таймаутом 48 часов. У ноды два выхода:
- Resume Webhook, срабатывает, когда менеджер кликнул ссылку
- Timeout, срабатывает через 48 часов, если ответа не было
Путь Timeout веду сразу на Set-ноду, которая выставляет decision = "auto_rejected", и дальше workflow закрывает заявку автоматически с соответствующим уведомлением заявителю.
Читаем решение менеджера
После Resume данные из query-строки доступны в $json.query:
// В IF-ноде или Expression
{{ $json.query.decision }} // "approve" или "reject"
{{ $json.query.managerId }} // идентификатор, который мы сами же туда и зашили
IF-нода проверяет $json.query.decision === "approve" и разводит дальнейший маршрут по двум веткам.
Что важно не упустить
Ссылки в письме должны быть полными, с https://. Если n8n крутится за reverse-proxy, проверь, что переменная N8N_EDITOR_BASE_URL выставлена корректно, иначе $execution.resumeUrl сгенерирует ссылку на localhost и менеджер получит нерабочий URL.
Ещё один момент: если менеджер кликнет ссылку дважды, второй запрос упадёт с ошибкой, потому что workflow уже возобновился и Wait-нода перестала слушать. Это нормальное поведение, но в письме лучше явно написать "кликните один раз". Браузерные предпросмотры ссылок (Gmail, Outlook) теоретически могут сделать этот запрос за пользователя, так что если хочешь перестраховаться, используй POST-форму вместо GET-ссылки.
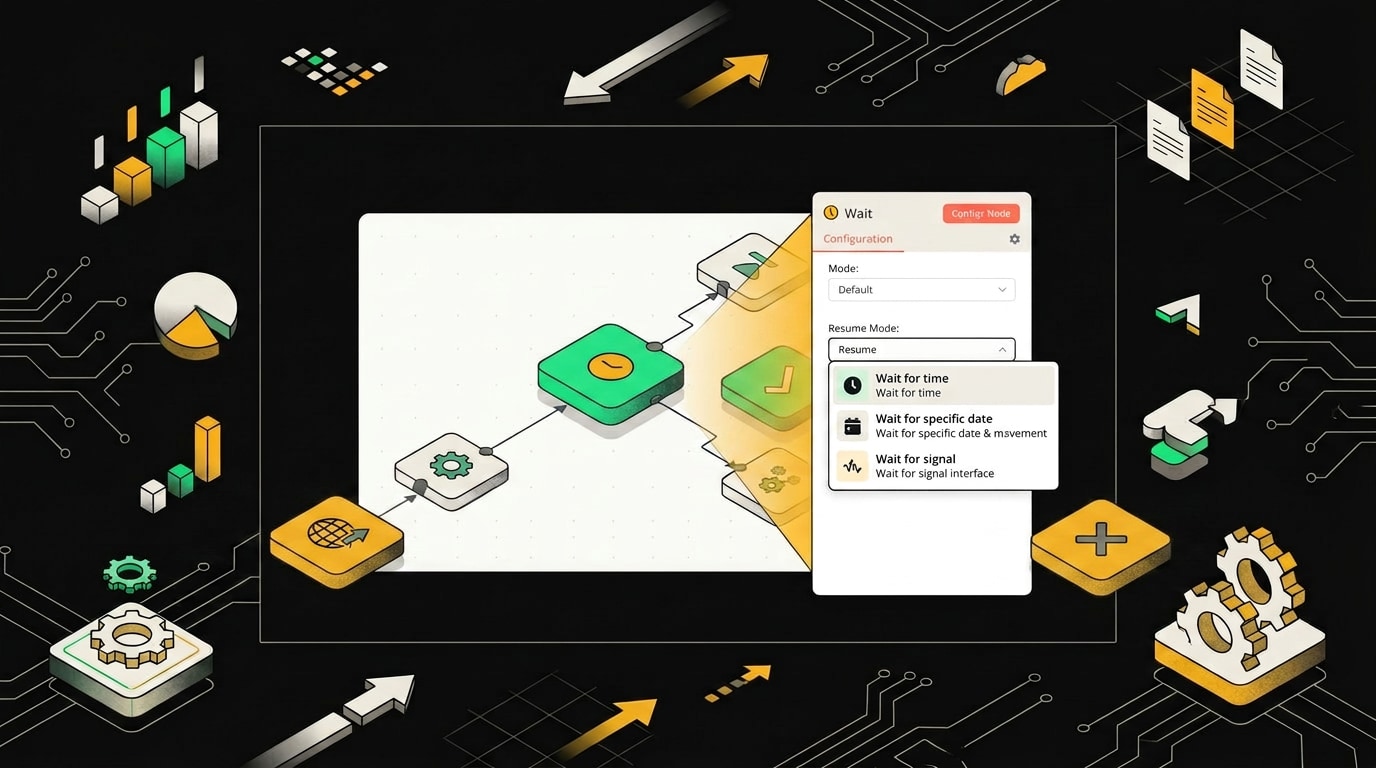
Пользователь получает письмо с двумя ссылками, и клик по любой из них отправляет webhook-запрос, который возобновляет workflow с нужным значением переменной.
Мониторинг ожидающих выполнений
Когда workflow уходит в состояние Wait, n8n не теряет его из виду. Все приостановленные процессы оседают в разделе Executions главного интерфейса. Там есть фильтр по статусу: выбираешь "Waiting" и видишь полный список с временными метками, именами workflow и execution ID. Никакой магии, просто удобный инструмент для быстрой проверки.
Но интерфейс подходит для ручного осмотра. Если нужна автоматизация, работай с REST API:
# Запрос к n8n REST API для получения всех ожидающих выполнений
curl -H "X-N8N-API-KEY: your_api_key" \
"https://your-n8n.com/api/v1/executions?status=waiting&limit=100"
Ответ содержит массив объектов с полем waitTill, это timestamp, когда выполнение должно проснуться. По нему сразу видно, кто ждёт пять минут, а кто завис ещё вчера.
Зависшие ожидания, отдельная история. Workflow уходит в Wait, внешний сервис не присылает webhook, таймаут не выставлен. Процесс висит часами. Чтобы ловить такие случаи автоматически, делаю отдельный служебный workflow на Cron: он раз в час стучится в /api/v1/executions?status=waiting, берёт все записи старше, допустим, 6 часов и отправляет алерт в Slack или создаёт задачу в трекере. Простая схема, но она реально спасает, когда production-процесс тихо зависает и никто не замечает.
Если у тебя self-hosted n8n с PostgreSQL, можно смотреть прямо в базу:
SELECT id, "waitTill", "createdAt"
FROM execution
WHERE status = 'waiting'
ORDER BY "waitTill" ASC;
Запрос отдаёт выполнения отсортированными по времени пробуждения. Удобно для дебага: сразу видно порядок, в котором процессы должны возобновиться, и можно сравнить waitTill с текущим временем, чтобы найти просроченные.
И ещё один инструмент, про который часто забывают: эндпоинт /metrics. Включается переменной окружения N8N_METRICS=true, после чего n8n начинает отдавать метрики в формате Prometheus. Среди них есть счётчики ожидающих выполнений, которые можно тянуть в Grafana и строить дашборд. Это уже уровень, когда у тебя десятки workflow и ручной мониторинг перестаёт работать.
Когда Wait-нода не нужна: альтернативы
Прежде чем тащить Wait в схему, стоит проверить, не решается ли задача проще.
Если нужна пауза меньше 30 секунд внутри одного выполнения, Code-нода справляется без лишних движений:
await new Promise(r => setTimeout(r, 5000));
Пять строк кода, никакого сохранения состояния, никаких вебхуков. Wait в таких случаях добавляет только накладные расходы.
Для регулярных задач по расписанию Schedule Trigger закрывает вопрос полностью. Workflow запустился, сделал своё дело, завершился. Никакого "висящего" выполнения, которое ждёт возобновления. Это надёжнее, потому что каждый запуск начинается чисто, без унаследованного контекста предыдущего.
Сложнее ситуация с длинными процессами, где несколько точек ожидания разбросаны по логике. Один большой workflow с цепочкой Wait-нод превращается в кашу, которую трудно отлаживать. Здесь лучше разбить процесс на отдельные workflow и связать их через HTTP Request или вызовы API. Каждый workflow отвечает за свой шаг, передаёт управление следующему и завершается. Читаемость вырастает, а упавший шаг можно перезапустить точечно, не начиная всё с начала.
Отдельный случай: ожидание завершения внешнего batch-job'а. Сюда Wait вообще не подходит, потому что время выполнения заранее неизвестно. Правильная схема: Loop, внутри которого HTTP Request проверяет статус задания, IF смотрит на результат, и если задание ещё выполняется, цикл идёт на следующую итерацию с паузой через ту же Code-ноду. Polling грязнее выглядит на схеме, но ведёт себя предсказуемо и не оставляет workflow в подвешенном состоянии на часы.
Wait нужен для конкретного сценария: выполнение должно остановиться и ждать внешнего события, которое придёт через вебхук или в заданное время. Всё остальное закрывается инструментами выше.
Если сценарий требует ожидания дольше нескольких часов, стоит рассмотреть внешние очереди или триггеры вместо встроенного Wait node.



