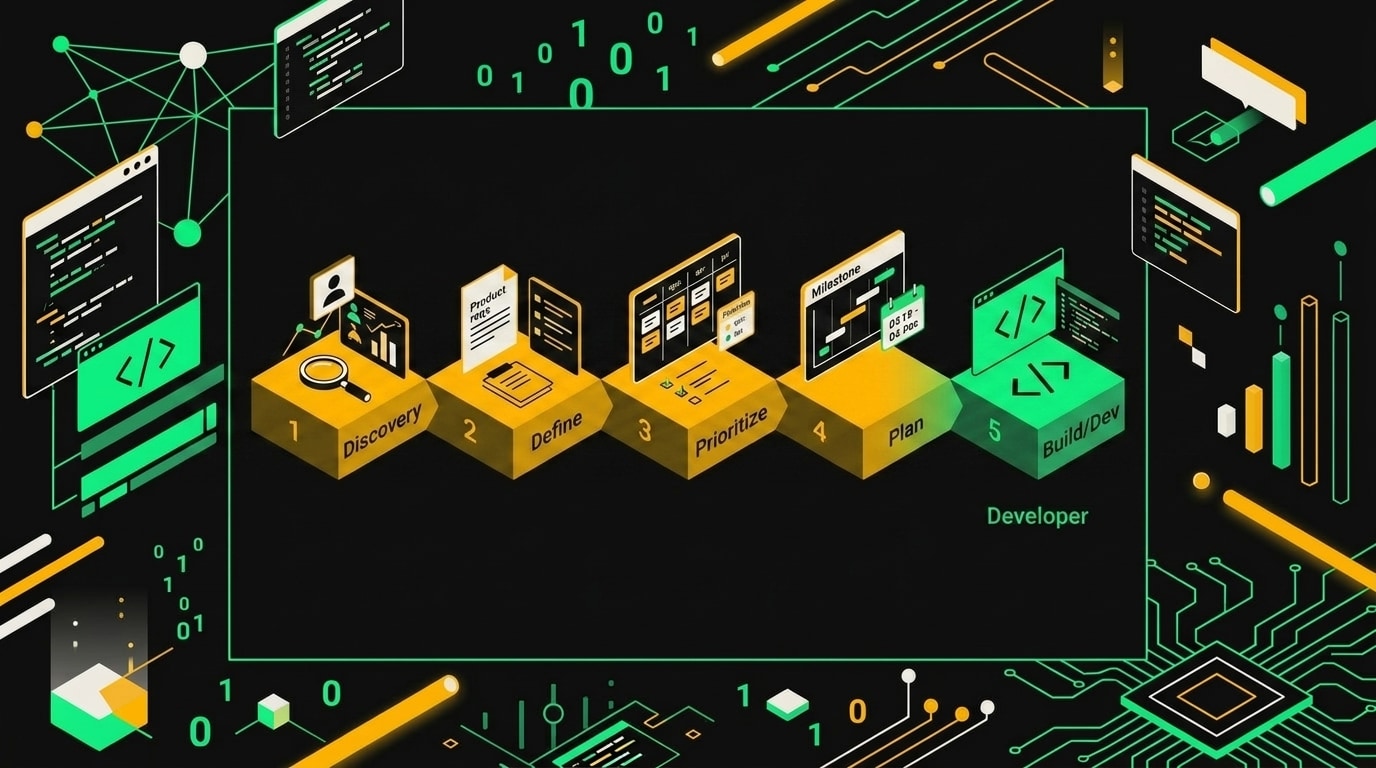
Откуда взялся миф о двух крайностях
Стандартный нарратив звучит примерно так: вайбкодинг либо для тех, кто хочет "сделать приложение за вечер" без единой строки знаний, либо для сеньора, которому надоело писать бойлерплейт. Два полюса, между ними пустота.
Откуда это взялось, понятно. Первые громкие истории были именно такими: или "я за выходные запустил SaaS без опыта программирования", или "я ускорил спринт в три раза, делегировав рутину GPT-4". Медиа закрепили шаблон, и он застрял.
Но посмотри на цифры. По данным Stack Overflow за 2025 год, 84% разработчиков уже используют AI-инструменты в работе. 84 процента. Это не два полюса, это практически вся отрасль. И когда начинаешь разбираться, где именно прирост продуктивности самый заметный, картина не совпадает с нарративом.
Джуны не выигрывают так, как ожидалось. Проблема конкретная: без понимания архитектуры человек не видит, когда модель генерирует код с гонкой состояний, неправильной обработкой ошибок или структурой, которую через месяц невозможно расширить. Код запускается. Тесты проходят. А потом приходит первый продакшн-баг, и никто не может объяснить, почему это вообще работало.
Сеньоры упираются в другой потолок. Они быстро обнаруживают, что на критических участках, там где логика сложная и цена ошибки высокая, приходится возвращаться к ручному контролю. Инструмент хорош для быстрого черновика, но доверять ему финальное решение по безопасности или производительности они не готовы.
Реальный разрыв находится в другом месте. Это аналитики, продакты, дата-сайентисты, исследователи, которые понимают предметную область и данные глубоко, но не пишут код профессионально. Им не нужен весь арсенал старшего инженера. Им нужно решить конкретную задачу достаточно хорошо, чтобы она работала в их контексте. И вот здесь прирост оказывается непропорционально большим, потому что раньше этот человек просто не мог сделать такое в принципе.
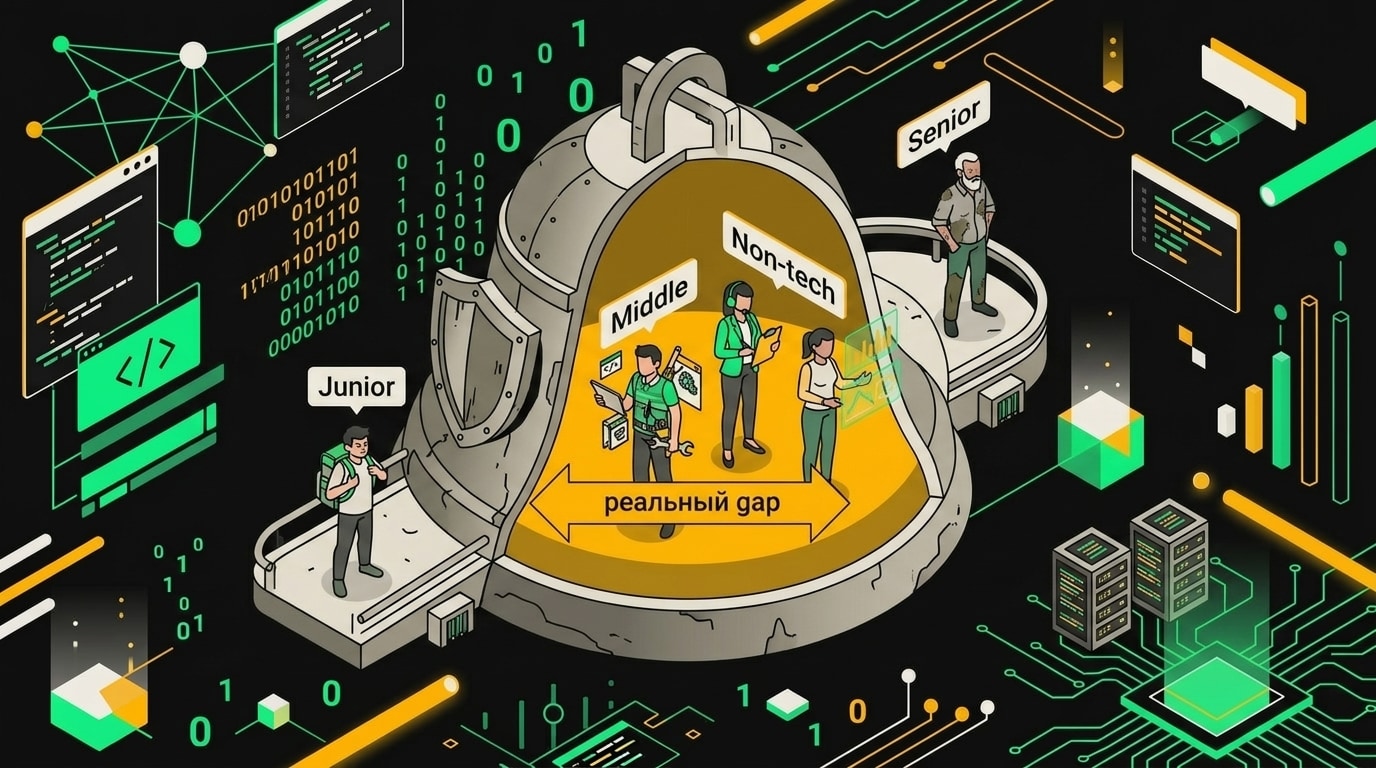
Продакты и аналитики получают непропорционально большую выгоду: им вайбкодинг закрывает пробел между идеей и прототипом, который раньше требовал привлечения инженера.
Кто такие продакты и аналитики в контексте разработки: точное определение аудитории
Речь не про новичков, которые "хотят в IT". Речь про людей, которые уже работают внутри продуктовых и технологических команд и ежедневно упираются в одну и ту же стену.
Продакт-менеджер знает, какую гипотезу нужно проверить, умеет написать PRD на пять страниц, расставить приоритеты в бэклоге и объяснить инженеру, зачем эта фича вообще нужна. Но чтобы собрать простой внутренний инструмент для команды поддержки или сделать прототип нового онбординга, он идёт в очередь к разработчикам. Очередь занята на три спринта вперёд.
Продуктовый аналитик пишет SQL-запросы сложнее, чем большинство junior-разработчиков. Он строит воронки в Amplitude, тянет данные через dbt, гоняет Python-скрипты в Jupyter. Но как только нужно превратить этот скрипт в нечто, что другой человек может открыть в браузере без инструкции на две страницы, всё останавливается. Он не знает Flask, не понимает, что такое WSGI, и не хочет разбираться в деплое на AWS ради одного дашборда.
Data analyst и бизнес-аналитик понимают, откуда берутся данные и что с ними не так, лучше, чем многие разработчики. Они знают бизнес-логику наизусть. Но TypeScript, React, Docker, это другая вселенная, и времени её осваивать нет.
Operations-менеджер или продуктовый стратег видит весь процесс целиком: где теряется время, где нужна автоматизация, где ручной Excel убивает скорость. Исторически он полностью зависел от IT-ресурсов, которые всегда в дефиците.
У всех этих людей один общий знаменатель: они точно знают, что им нужно получить на выходе. И у них нет ни времени, ни мотивации учить TypeScript, чтобы это получить. Именно для этой аудитории ИИ-инструменты разработки меняют уравнение принципиально, а не косметически.
Что вайбкодинг даёт продакту, чего не давало ничто до этого
Раньше у продакта был один инструмент проверки гипотез: написать тикет, подождать грумминга, попасть в спринт, получить результат через три недели. К тому моменту контекст уже другой, рынок чуть сдвинулся, и ты проверяешь гипотезу, которая тебе уже не так интересна.
Вайбкодинг ломает этот цикл физически.
В Lovable или Replit собирается работающий прототип за 2-3 часа. Не макет в Figma, не флоу на досках, а кликабельный продукт с реальным стейтом, который можно отдать пользователю. Разница в восприятии огромная: когда стейкхолдер кликает по кнопке и видит результат, он думает продуктом, а не картинкой. Figma-макеты люди смотрят как рекламу. Рабочий прототип они тестируют как продукт.
Второе, что раньше было практически недостижимо: A/B-тест интерфейса без UI-разработчика. Можно самостоятельно сделать вариант B, изменить расположение CTA, переписать онбординг-флоу, добавить шаг в воронку и сразу отдать на тест. Не ждать, пока освободится фронтендер. Не объяснять, что именно нужно. Просто сделать.
Отдельная история с внутренними инструментами. Дашборды статусов, формы сбора данных от саппорта, простые обёртки над таблицами с клиентами. Это задачи, которые IT-команды не приоритизируют никогда, потому что у них есть продукт, релизы и баги. Продакт с вайбкодингом закрывает их сам за один вечер. Я видел, как операционная команда три месяца жила в Google Sheets, потому что "нет ресурса", и как продакт за четыре часа собрал им нормальную форму с автоматической выгрузкой.
Среди практиков агентной разработки заметна тенденция: прототип строится сначала, решение о найме разработчика принимается после проверки гипотезы. Сначала проверяют, работает ли идея. Потом нанимают. Это переворачивает привычный порядок найма с ног на голову.
Всё это не отменяет инженера. Но даёт продакту то, чего у него раньше не было: возможность думать продуктом, а не техническим заданием.
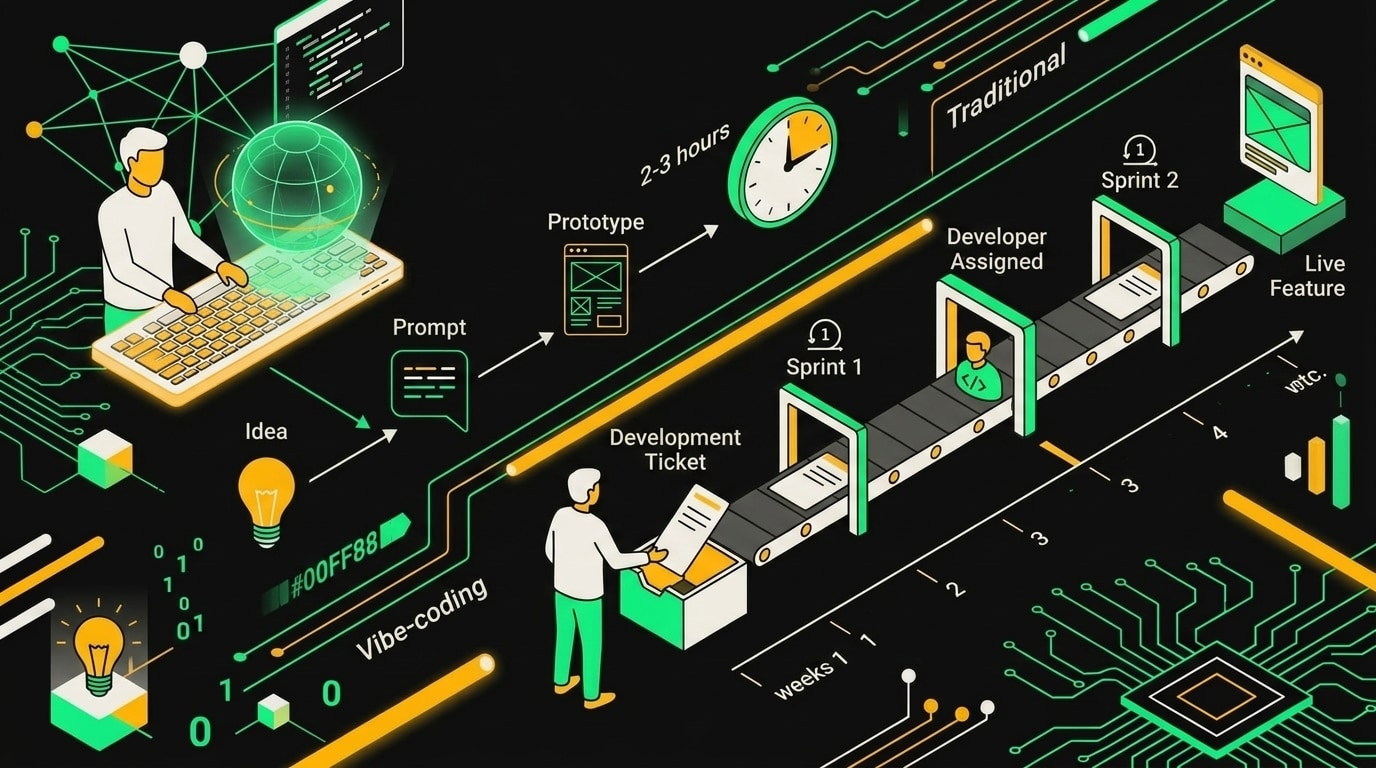
Там, где традиционный цикл съедает две-три недели на постановку задачи, спринт и ревью, вайбкодинг сжимает путь до рабочего прототипа до нескольких часов.
Инструменты, которые реально работают для non-dev специалистов в мае 2026
Главный критерий выбора инструмента, если ты не разработчик: сколько итераций дебаггинга тебе придётся сделать самому, чтобы получить рабочий результат. Потому что именно здесь большинство people-not-in-tech застревают и бросают. Не на этапе "написать промпт", а на этапе "разобраться, почему оно не работает".
Вот что в мае 2026 реально проходит этот тест.
Lovable генерирует full-stack React-приложения из описания на естественном языке. Порог входа минимальный: не нужно знать, что такое компонент или хук. Пишешь задачу, получаешь деплой. Хорошо работает для внутренних инструментов: дашборды, формы сбора данных, простые CRUD-интерфейсы. Ломается, когда задача расплывчатая.
Replit Agent решает другую боль: настройку окружения. Локальный Node, виртуальные среды Python, конфигурация портов, всё это убивает аналитика ещё до первой строки кода. В Replit Agent среда и деплой находятся в одном окне. Написал, запустил, поделился ссылкой.
Cursor с режимом Composer стоит рассматривать, если ты уже знаешь немного Python или SQL и хочешь расширить то, что умеешь. Не с нуля. Composer позволяет редактировать несколько файлов одновременно через чат, и для аналитика, который пишет скрипты обработки данных, это реально меняет скорость работы. Подробнее о том, что из такой работы в итоге выживает, а что нет, читай в разборе двух недель вайбкодинга на Cursor.
Claude Code широко используется в tech-сообществе и хорошо справляется с задачами через conversational интерфейс: можно объяснить задачу текстом, уточнить, попросить переписать логику, не зная точного синтаксиса. Хорошо работает с запросами типа "возьми этот CSV, посчитай когортное удержание, покажи результат".
Microsoft Copilot в Power Platform закрывает отдельный сегмент: корпоративные аналитики, которые работают внутри экосистемы Microsoft и не могут просто так принести внешний инструмент. Power Automate, Power BI, Dataverse. Если ты в этом мире, Copilot там уже встроен и его не нужно пробивать через IT-политику.
Теперь про то, почему большинство промптов не работают с первого раза.
Модель не читает мысли. Она буквально выполняет то, что написано. Расплывчатый промпт даёт расплывчатый результат, и ты начинаешь итерировать. Посмотри на разницу:
# Пример промпта, который даёт результат без правок
# Не так:
'Сделай приложение для отслеживания задач'
# А так:
'Создай веб-приложение на React. Одна страница.
Список задач с полями: название, статус (todo/in progress/done), дедлайн.
Фильтрация по статусу. Данные хранить в localStorage.
Стиль: минималистичный, шрифт Inter, цвета #1a1a1a и #0066ff.
Никаких внешних API, никакой авторизации.'
Второй промпт не требует технических знаний. Он требует только точности. Это навык, который тренируется быстро, и именно он отделяет аналитика, который получает рабочий прототип с первого запроса, от того, кто застревает в трёх итерациях и бросает.
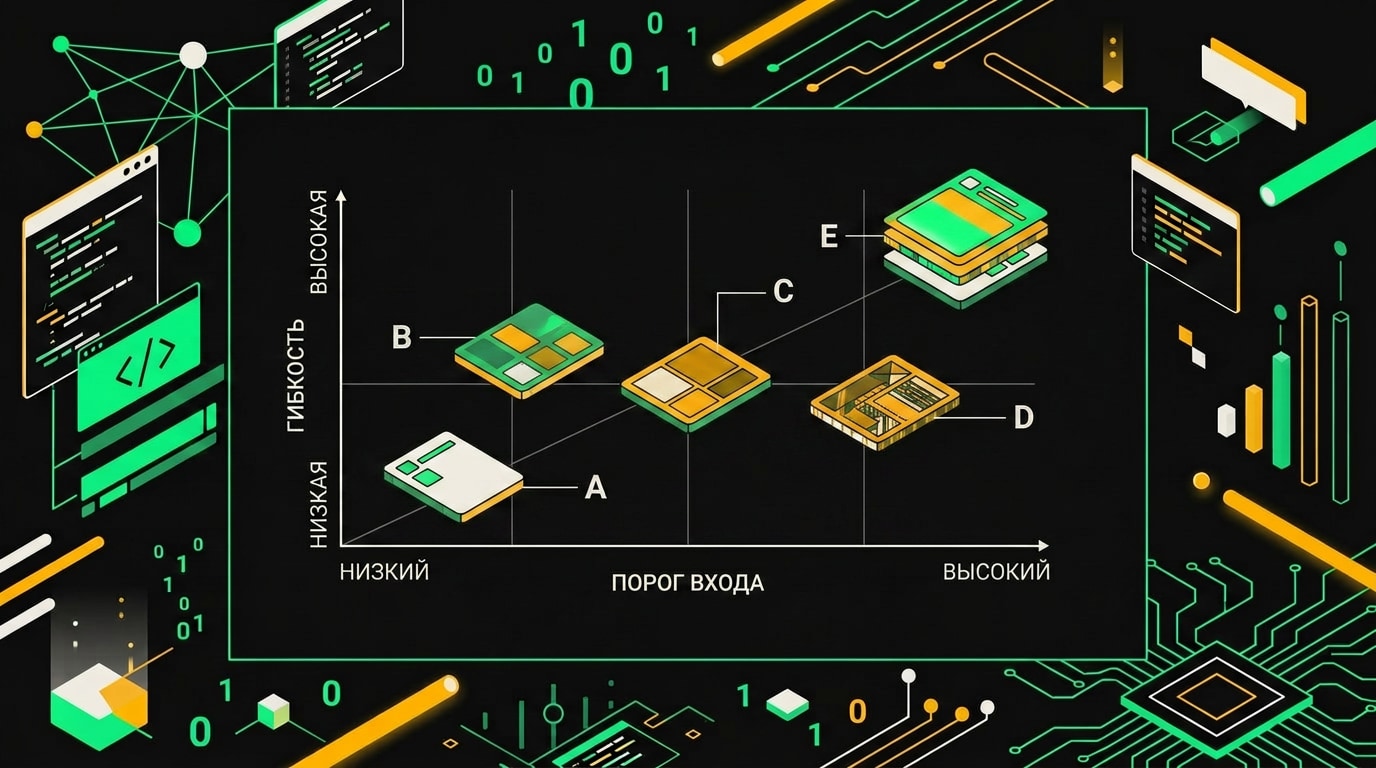
Cursor и Replit занимают правый верхний угол по гибкости, но требуют базового знакомства с кодом, тогда как Lovable и Bolt держат низкий порог входа при умеренной свободе.
Реальные ограничения: где вайбкодинг ломается для этой аудитории
Начну с конкретного случая. Продакт собирает MVP в Lovable, подключает авторизацию через Google, и инструмент генерирует код, который сохраняет access token прямо в localStorage. Никаких предупреждений. Всё "работает". Через две недели это уходит в production, потому что продакт видит функциональность, а не поверхность атаки.
Это не гипотетика. Это стандартное поведение многих LLM при генерации фронтенда: инструменты оптимизируют под "работает сейчас", а не под "безопасно через год". XSS-уязвимости, открытые API без rate limiting, захардкоженные ключи в client-side коде. Продакт без бэкграунда в безопасности физически не знает, на что смотреть.
Второе ограничение менее очевидное, но разработчики его знают хорошо. Код, собранный через вайбкодинг, часто работает как монолит из плохо склеенных кусков: переменные с именами data2, finalFinal, компоненты без чёткой ответственности, стейт, прокинутый через пять уровней вместо нормального хранилища. Когда продакт передаёт такой проект разработчику, тот нередко говорит: "проще переписать". Это не потому что разработчик ленится. Это потому что рефакторинг хаотично сгенерированного кода занимает больше времени, чем написание с нуля.
Дата-интеграция разбивает ещё больше сценариев. Подключиться к реальной корпоративной базе данных через вайбкодинг-инструмент... здесь нужны права доступа, понимание схемы, настройка окружения, часто VPN или whitelist по IP. AI-инструмент не знает топологию сети вашей компании. Он предложит строку подключения, которая сработает локально и упадёт в любой реальной инфраструктуре. Чем именно чревата передача такого кода в продакшен без ревью, хорошо видно на примере того, как Claude дописал SQL-миграцию и удалил прод-таблицу.
В феврале 2026 вышел препринт на arXiv под заголовком "Vibe Coding Kills Open Source". Авторы изучали pull requests в публичных репозиториях и высказали озабоченность качеством кода с признаками AI-генерации. Методология препринта вызвала дискуссию в сообществе, так что к конкретным числам из него стоит относиться осторожно. Но общее направление, на которое указывают и другие практики: AI-сгенерированный код требует внимательного ревью, а не беглого просмотра.
Практическое правило: вайбкодинг работает для одноразовых внутренних инструментов и прототипов, где цена ошибки низкая. Дашборд для команды из пяти человек, скрипт для парсинга данных, быстрый прототип для проверки гипотезы. Для всего, что идёт в production к реальным пользователям, сгенерированный код нужен разработчику на проверку. Не "беглый просмотр", а нормальный code review с пониманием того, что там внутри.
Как продуктовый аналитик использует вайбкодинг для работы с данными
Я не умею писать на pandas. Серьёзно. Я знаю, что такое DataFrame, понимаю, что groupby делает группировку, но если мне дать пустой редактор и сказать "напиши скрипт", я застряну на третьей строке. И при этом за последний месяц я написал (точнее, получил и запустил) больше Python-скриптов, чем за предыдущие три года.
Это и есть вайбкодинг в продуктовой аналитике.
Базовый сценарий: CSV + Colab
Типичная задача: есть выгрузка из базы, нужно понять, какие события генерируют выручку. Раньше я бы открыл Excel, помучился с pivot table, получил что-то приблизительное. Сейчас я пишу запрос в Claude или GPT-4o примерно такого вида:
# Типичный запрос аналитика к AI-инструменту
"""
У меня CSV с колонками: user_id, event_type, timestamp, revenue.
Напиши Python-скрипт:
1. Загрузи файл
2. Посчитай revenue по каждому event_type за последние 30 дней
3. Выведи топ-5 event_type по сумме
4. Сохрани результат в новый CSV с датой в названии файла
Используй pandas. Добавь обработку ошибок если файл не найден.
"""
Получаю готовый скрипт, копирую в Google Colab, загружаю файл, запускаю. Три минуты от задачи до результата. Без Stack Overflow, без документации pandas.
Ключевой момент здесь не в том, что я "научился программировать". Я делаю ровно одну вещь, которую не умеет джун без контекста бизнеса: смотрю на output и понимаю, правильный ли он. Если топ-5 событий по выручке показывает subscription_cancel на первом месте с суммой в 2 млн, я знаю, что что-то не так с логикой фильтрации или знаком у revenue. Код я не читаю построчно. Результат проверяю всегда.
Дашборды без дизайнера и фронтенда
Второй сценарий, который реально изменил мой процесс: Streamlit. Раньше любой интерактивный отчёт означал либо Tableau (лицензия, очередь к аналитику BI), либо запрос к разработчикам (спринт, приоритизация, ожидание). Сейчас я описываю AI, что хочу видеть: фильтр по дате, dropdown с продуктами, график retention по когортам, и получаю рабочее Streamlit-приложение. Деплою на Streamlit Cloud за 10 минут.
Я корректирую логику, меняю метрики, добавляю фильтры через новые запросы к AI. Цикл итерации занимает минуты, а не дни.
SQL не исчезает, он автоматизируется
SQL я знаю хорошо. Но есть класс задач, которые бесят: один и тот же запрос каждую неделю, с разными датами, с сохранением результата в разные файлы, с отправкой куда-то. Раньше это был ручной труд или просьба к Data Engineering.
Сейчас я даю AI готовый SQL-запрос и прошу обернуть его в Python-скрипт с параметрами (дата начала, дата конца), подключением к базе через psycopg2 или sqlalchemy, сохранением CSV с именем вида report_2026_05_09.csv. Скрипт кладу в cron или запускаю руками раз в неделю. Задача закрыта навсегда.
Собственные формы вместо Google Forms
Последний пример, который удивляет коллег. У нас была задача собирать структурированный фидбек от команды поддержки: категория обращения, приоритет, ссылка на тикет, свободный комментарий. Google Forms не давал нужной валидации, данные приходили грязными. Я попросил AI написать простое Gradio-приложение с нужными полями, валидацией и записью в Google Sheets через API.
Заняло два часа, включая настройку доступов. Теперь данные приходят чистыми, структура фиксированная, и я могу анализировать их напрямую.
Граница, которую я провожу для себя: вайбкодинг работает, пока я понимаю задачу лучше, чем AI понимает мой бизнес. Как только я перестаю проверять результат, это уже не аналитика.
Аналитик описывает задачу голосом или текстом, получает рабочий скрипт обработки данных и итерирует прямо в чате, минуя очередь к бэкенду.
Корпоративный контекст 2026: почему компании начали поощрять это
По данным Indeed Hiring Lab за январь 2026, вакансии с упоминанием AI-навыков продолжают расти на фоне общего спада найма. Интерпретировать это можно по-разному, но сигнал однозначный: компании хотят меньше людей, которые умеют только ставить задачи, и больше тех, кто умеет их закрывать.
Параллельно идёт другой процесс. IT-бюджеты на внутренние инструменты режут. Не катастрофично, но ощутимо. И вместо того чтобы нанимать junior-разработчиков для внутренних автоматизаций, дашбордов, скриптов парсинга, компании всё чаще смотрят на business-side команды: «разберитесь сами». Продакты, аналитики, маркетологи получают негласное задание освоить то, что раньше шло в бэклог к разработчикам.
В профессиональных обсуждениях и отраслевых медиа в 2025-2026 годах стали регулярно появляться откровенные разборы: сотрудник, который принципиально игнорирует AI-инструменты, превращается в узкое место. Не потому что он плохой специалист, а потому что его скорость не совпадает со скоростью команды, которая уже перестроилась.
Отсюда возникла новая роль, которую ещё официально нигде не закрепили, но фактически она существует: "AI-оперированный продакт". Человек, который берёт задачи, прежде требовавшие junior-разработчика, и закрывает их сам с помощью Cursor, Claude или Copilot. Написать скрипт для выгрузки данных из API. Собрать прототип формы. Автоматизировать отчёт. Это не программирование в классическом смысле, но это уже точно не "я написал ТЗ и жду".
Но здесь есть проблема, о которой говорят меньше охотно. Когда продакт генерирует код и деплоит его в продакшен или передаёт разработчику как «почти готовое», ответственность за качество размывается. Разработчик думает, что продакт проверил логику. Продакт думает, что разработчик проверит код. А баг живёт в этом зазоре. О том, где именно AI-разработка ломается в продакшене и как выстроить процессы так, чтобы этот зазор закрыть, стоит читать отдельно. Пока корпоративные процессы не адаптировались под новую реальность, этот риск остаётся структурным, а не случайным.
Как выстроить рабочий процесс: от идеи до работающего инструмента за один день
Начну с того, что убивает большинство попыток: люди садятся генерировать, не зная, что именно они хотят получить. "Нужен дашборд для продаж", это не задача. Это желание. Задача выглядит иначе: на вход приходит CSV из CRM с полями deal_id, stage, amount, owner, close_date; на выходе нужна таблица с фильтром по менеджеру и суммой по стадиям; смотрят на это два человека раз в неделю. Вот теперь можно работать.
Шаг 1: Переформулируй задачу в три вопроса. Что подаётся на вход (формат, источник, объём)? Что выходит (таблица, файл, уведомление, API-ответ)? Кто этим пользуется и как часто? Если не можешь ответить на все три, инструмент строить рано.
Шаг 2: Выбери платформу под тип задачи, а не под хайп. Веб-приложение с интерфейсом, которое увидят другие люди, делай в Lovable. Скрипт для обработки данных, трансформации таблиц или анализа, Cursor с Claude внутри. Автоматизацию, которая должна жить на сервере и запускаться по расписанию, проще всего собрать в Replit. Смешивать не надо: попытка сделать полноценный веб-сервис в Cursor выльется в три часа настройки окружения вместо работы.
Шаг 3: Первый промпт должен быть скучно конкретным. Не "сделай красивый трекер задач", а: стек React + Tailwind, данные хранятся в localStorage, три статуса (todo / in progress / done), карточка содержит поля title, owner, deadline, при переходе в done карточка уходит в архив. Чем меньше у модели пространства для интерпретации, тем меньше правок потом. Ограничения в промпте, это не скованность, а экономия времени.
Шаг 4: Проверяй логику, не код. После первой генерации открывай инструм