

Что такое вайбкодинг и почему он добрался до продакшена
Термин придумал Андрей Карпаты в феврале 2025-го, и поначалу это читалось как шутка про ленивых разработчиков: "скажи модели что хочешь, прими всё что она предложит, не разбирайся в деталях". За год с небольшим это превратилось в реальный рабочий процесс в командах, которые раньше вайбкодинг не воспринимали всерьёз.
К 2026 году три инструмента захватили большую часть рынка. Cursor ($20/мес) заточен под работу в IDE: ты остаёшься в редакторе, принимаешь или отклоняешь диффы, видишь контекст. Claude Code ($20/мес) работает иначе: терминал, агентский режим, минимум GUI. Он сам читает файлы, запускает тесты, двигается по кодовой базе без твоей навигации. GitHub Copilot прижился там, где нет выбора инструментов: корпоративные команды на enterprise-тарифах, где безопасность и SSO важнее UX.
Парадигмы у Cursor и Claude Code разные, и это не косметика. Cursor провоцирует на частые мелкие правки: предлагает, ты кликаешь "accept", идёшь дальше. Риск в том, что ты принимаешь код не думая, потому что интерфейс слишком удобен для этого. Claude Code требует нормального промпта и заставляет проверять результат уже после: агент сделал что-то, ты смотришь что именно. Другая дисциплина.
Скорость первых итераций реально выросла. Команды, которые публично делились опытом в конце 2025-го, отмечали заметное ускорение на прототипах и новых фичах с нуля. Когда неделя работы превращается в два дня, команды это замечают в спринтах.
Но здесь ровно та ловушка, в которую падают быстро. Скорость прототипа и надёжность продакшн-кода решают разные задачи. Прототип должен работать сейчас, на твоей машине, с твоими данными. Продакшн-код должен работать через полгода, после рефакторинга соседнего модуля, под нагрузкой, без тебя рядом. Вайбкодинг ускоряет первое. Со вторым история сложнее.
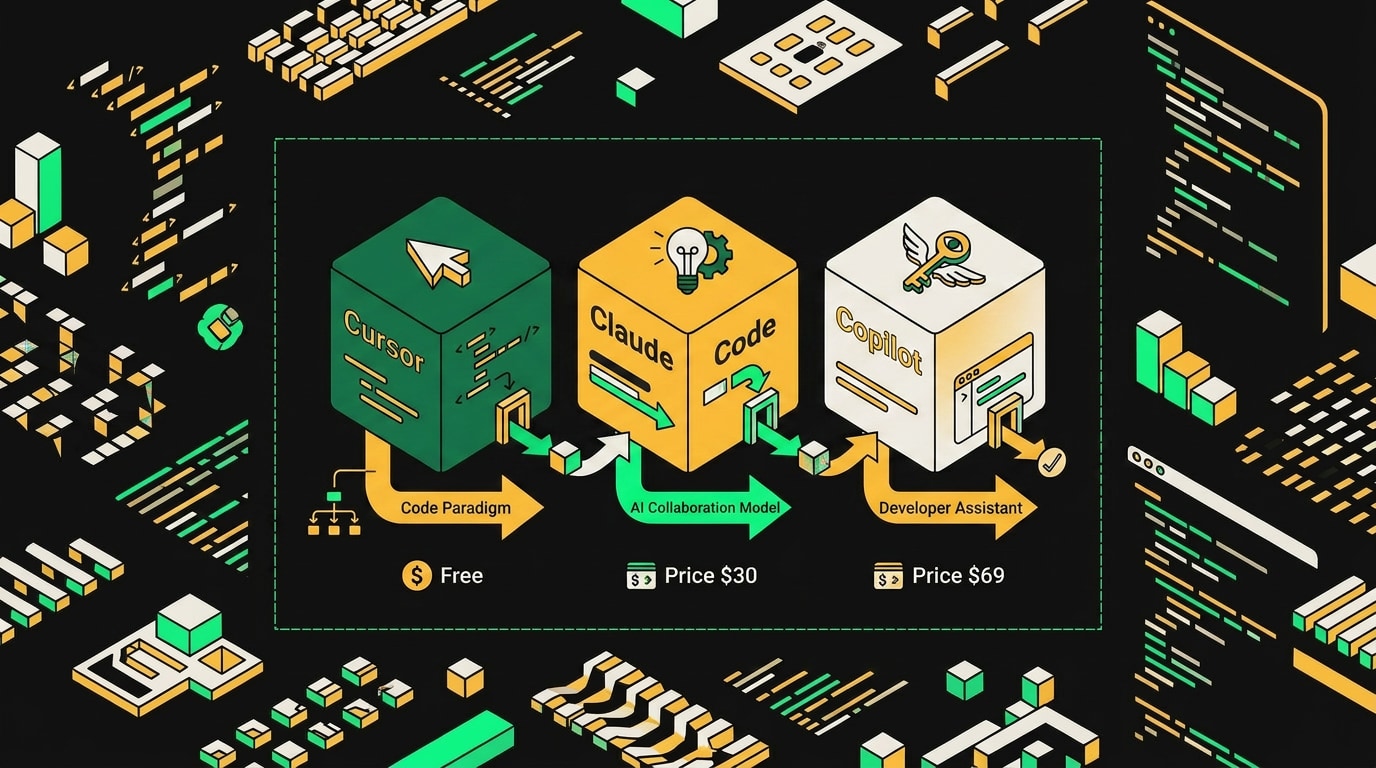
GitHub Copilot, Cursor и Claude закрывают разные сценарии работы, и выбор между ними зависит от того, где именно вы теряете больше времени.
Главная проблема: технический долг растёт быстрее, чем его замечают
LLM решает задачу из промпта. Ровно её и только её. Никакого контекста о том, что в соседнем модуле уже есть UserValidator, что соглашение по именованию сервисов поменялось три спринта назад, или что эту логику пагинации писали пять раз в разных вариациях и шестой раз не нужен.
Каждый сгенерированный файл чистый синтаксически. Линтер молчит. Тесты зелёные. Code review проходит, потому что ревьюер смотрит на структуру кода, а не на то, что parseUserInput() в auth/utils.ts делает примерно то же самое, что sanitizeInput() в shared/helpers.ts, написанный три недели назад другим промптом.
Именно здесь и зарыта проблема. Синтаксически чистый код скрывает архитектурный мусор лучше, чем любой другой.
Типичная картина после нескольких недель активного вайбкодинга: проект перевалил за 50 файлов, а в кодовой базе уже живут несколько разных абстракций для работы с API-ответами, несколько систем обработки ошибок с несовместимыми интерфейсами, и именование компонентов разъехалось. Каждый файл написан корректно. Вместе они превращают онбординг нового разработчика в детективную историю.
Технический долг от AI-генерации накапливается не линейно. Первые две недели всё идёт гладко. Потом скорость разработки начинает падать, и команда не сразу понимает почему, потому что визуально код выглядит нормально.
Есть три метрики, которые стоит начать мониторить с первого дня работы с AI-генерацией. Cyclomatic complexity: если функции, которые LLM пишет "с нуля", регулярно уходят за 10, промпты, скорее всего, слишком открытые и модель заполняет неопределённость ветвлениями. Дублирование кода: при активной AI-генерации оно растёт быстро, и чем раньше это отловить, тем дешевле рефакторинг. Количество файлов без тестов: AI-код часто идёт без тестов, если их явно не попросить, и эта категория файлов первой накапливает скрытые зависимости.
Проверять эти метрики раз в спринт недостаточно. При активном вайбкодинге проверка нужна каждые два-три дня. Иначе к моменту, когда цифры станут тревожными, переписывать придётся уже не модуль, а половину архитектуры.

Видимая часть айсберга, код, который запустился с первого раза; скрытая, отсутствие тестов, хрупкие зависимости и логика, которую через месяц никто не поймёт.
Проблема контекста: почему AI "забывает" архитектуру
Возьмём реальный сценарий. У вас монорепозиторий: 150 файлов, три сервиса, общая папка shared/utils, кастомные классы ошибок, слоистая архитектура. Вы просите Claude Code добавить новый эндпоинт. Он пишет код, всё выглядит разумно. Потом открываете PR и находите parseDate() второй раз, теперь в api/helpers.ts, хотя она уже живёт в shared/utils/date.ts с прошлого квартала.
Это не баг модели. Это физика контекстного окна.
Даже у Claude Opus 4.5 с его ~200k токенов проект на 150+ файлов не влезает целиком, если считать честно: исходники, тесты, конфиги, lock-файлы. Cursor решает это через embeddings и @codebase, то есть семантический поиск по репозиторию перед каждым запросом. Claude Code идёт другим путём: агентные вызовы к файловой системе, ls, grep, read_file по цепочке. Оба подхода работают, но оба зависят от того, насколько точно инструмент угадал, что именно нужно загрузить в контекст прямо сейчас.
Когда угадывает неточно, модель не говорит "я не знаю". Она достраивает. Изобретает интерфейс, который, по её мнению, должен существовать в проекте с такой структурой. Иногда угадывает правильно. Иногда пишет третью реализацию formatCurrency().
Практический признак того, что контекст обрезан: в одном PR появляются две разные реализации одной утилиты. Или AI импортирует из пути, которого нет. Или создаёт новый кастомный класс ошибки рядом с тем, что вы уже написали два месяца назад.
Обход простой, но требует дисциплины. Явные архитектурные документы в корне репозитория: .cursorrules для Cursor, CLAUDE.md для Claude Code, architecture.md для обоих. Эти файлы маленькие, они всегда влезают в контекст, и модель читает их приоритетно. По сути вы вручную кладёте в контекст то, что инструмент мог не найти сам.
Вот минимальный CLAUDE.md, который реально работает:
# CLAUDE.md

*Когда репозиторий растёт, модель видит только фрагмент кодовой базы, и её советы начинают расходиться с реальной архитектурой проекта.*
## Архитектура
- Слои: api/ → services/ → repositories/ → db/
- Ошибки: всегда через кастомные классы в src/errors/
- Нельзя: прямые SQL-запросы из api/
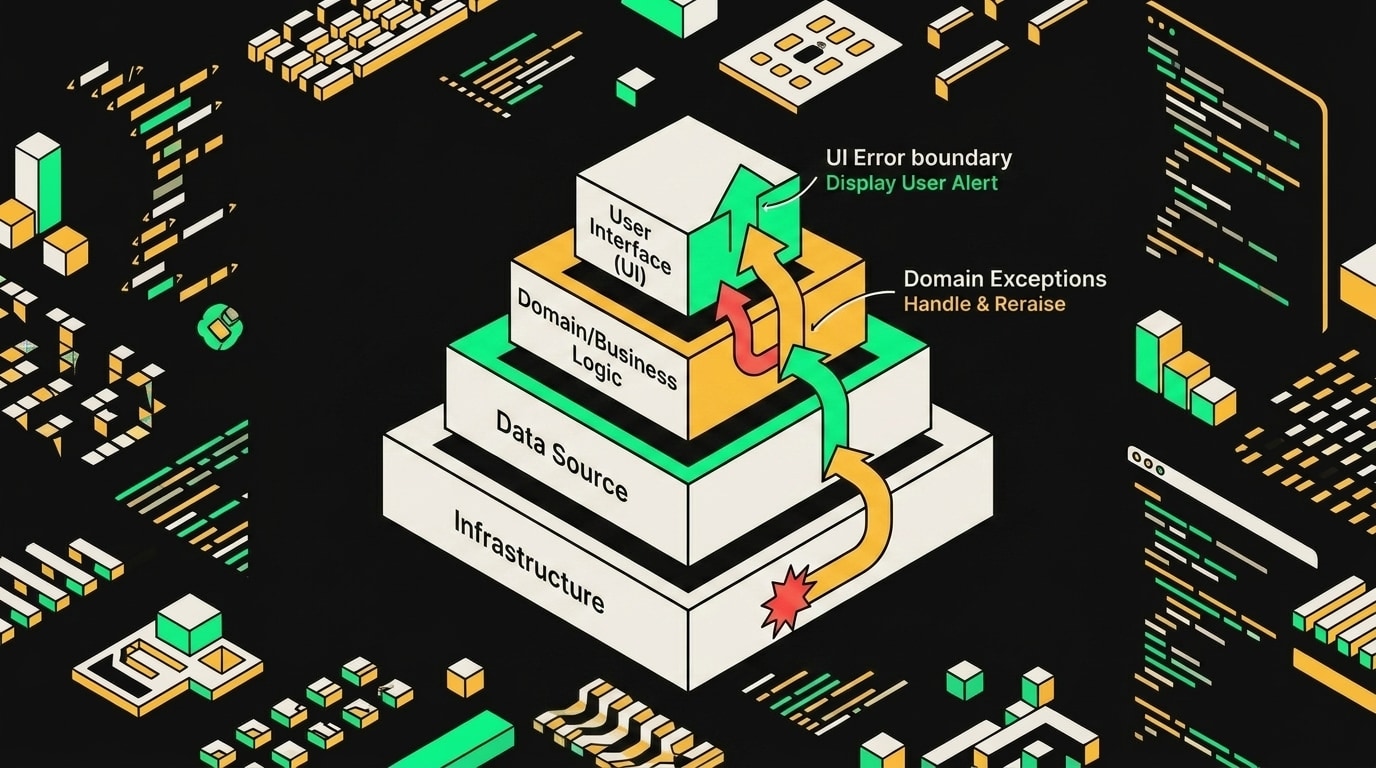
*Продакшен-код обрабатывает ошибки на каждом слое по-своему, а не сваливает всё в один общий catch.*
## Соглашения
- Функции: camelCase, классы: PascalCase
- Тесты: рядом с файлом, суффикс .test.ts
Восемь строк. Но теперь модель знает, что parseDate() искать в shared/utils/, что ошибки не создаются на месте, и что из контроллера нельзя лезть напрямую в базу. Это не серебряная пуля: если в src/errors/ лежит 40 классов, модель всё равно не увидит их все без явного запроса. Но хотя бы знает, куда смотреть.
Файл надо держать живым. Если архитектура меняется, обновляете CLAUDE.md в том же PR. Иначе через месяц документ описывает проект, которого уже нет, и становится хуже, чем его отсутствие.
Обработка ошибок в AI-сгенерированном коде: типичные паттерны провала
LLM оптимистична по природе. Когда я прошу ChatGPT или Claude написать функцию fetchUser, модель по умолчанию рисует happy path: данные пришли, вернули объект, все счастливы. Обработка ошибок появляется в ответе только если явно написать в промпте "добавь полную обработку ошибок с retry и таймаутами". Без этого уточнения получаешь примерно вот это:
// Что генерирует AI по умолчанию
async function fetchUser(id: string) {
try {
return await db.users.findOne(id);
} catch (e) {
console.log(e);
return null; // потеря контекста ошибки
}
}
Это не просто "неполный код". Это активно опасный код. Вызывающий код получает null, не зная почему. База недоступна? Запись не найдена? Таймаут? Всё превращается в одинаковый null, а реальная ошибка тихо умирает в консоли где-то в логах.
Я называю это паттерном "проглоченного исключения". По моим наблюдениям на code review, он встречается в AI-сгенерированном коде заметно чаще, чем в написанном вручную. И линтер его не поймает без специальных правил.
Что делать с этим на уровне архитектуры. У меня работает стратегия слоёв: Infrastructure Layer перехватывает низкоуровневые технические ошибки и выбрасывает доменные исключения. Не сырой DatabaseError из ORM наружу, а StorageUnavailableError с контекстом. Бизнес-логика не должна знать, что под капотом Postgres упал или соединение прервалось. Вот рабочий вариант:
// Что нужно в продакшне
async function fetchUser(id: string): Promise<User> {
try {
return await db.users.findOne(id);
} catch (e) {
if (e instanceof DatabaseConnectionError) {
throw new StorageUnavailableError('users', { cause: e });
}
throw new UnexpectedStorageError({ cause: e });
}
}
Здесь два принципиальных отличия. Первое: ошибка не проглатывается, она пробрасывается наверх с сохранением цепочки через cause. Второе: тип исключения несёт смысл. StorageUnavailableError говорит вызывающему коду: "сервис хранилища недоступен, реши, что делать". UnexpectedStorageError говорит: "что-то непредвиденное, лог и алерт".
Второй антипаттерн, который AI игнорирует почти всегда: таймауты и retry. Сетевой вызов без таймаута в 2026 году это не упущение, это баг по умолчанию. AI генерирует await fetch(url) или await db.users.findOne(id) без AbortController, без timeout-обёртки, без экспоненциального backoff при 503. Я добавил в наш шаблон промпта обязательный раздел error scenarios:
error scenarios:
- network timeout after 3s: throw TimeoutError
- 503/429 response: retry with exponential backoff, max 3 attempts
- 4xx client error: throw immediately, no retry
После добавления этого раздела качество сгенерированного кода по части устойчивости выросло заметно. Модели понимают задачу.
Как ловить проглоченные исключения автоматически. Линтер-правило require-explicit-error-handling в ESLint настроен на запрет catch-блоков, которые не делают throw и не вызывают зарегистрированный error-handler. Пустой catch или catch с только console.log не проходит CI. Это закрывает большую часть случаев, которые AI генерирует по умолчанию.
Главный вывод простой: AI не думает о том, что пойдёт не так. Это не баг модели, это особенность задачи. Модель оптимизирует под "выполни задачу", а не под "выдержи продакшн-нагрузку с сетевыми сбоями". Проверять нужно системно, через промпт-шаблоны и линтер, а не надеяться на ревью глазами. Именно такие тихие баги в обработке ошибок порой приводят к инцидентам с необратимыми последствиями в продакшене.
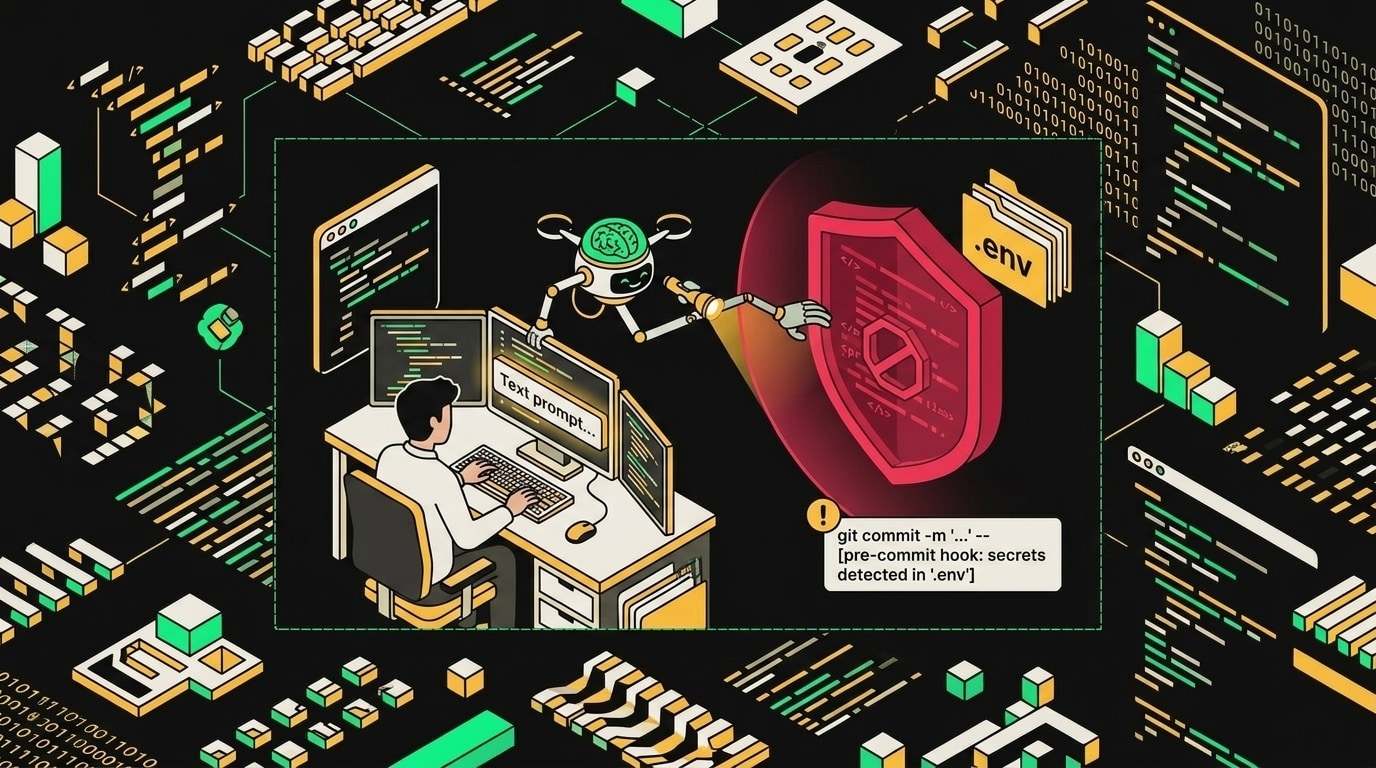
Pre-commit хук на основе detect-secrets останавливает коммит до того, как токен окажется в истории Git.
Code review AI-кода: что пропускают стандартные процессы
Классический ревью заточен под человека. Ревьюер смотрит на логику, ловит опечатки в условиях, проверяет edge cases, которые автор мог не учесть в три часа дня после пятого совещания. AI-код проходит через эти фильтры почти без трений. Он синтаксически корректен, логически связен, и именно это создаёт ложное ощущение безопасности.
Проблемы прячутся в другом месте.
Первое: скрытые зависимости. Copilot или ChatGPT генерируют код, который тащит паттерны из обучающих данных двух-трёхлетней давности. Для Python-проекта это может означать использование asyncio.get_event_loop() вместо asyncio.run(), или pkg_resources вместо importlib.metadata. Код работает, тесты зеленые, а через полгода вы разбираетесь с deprecation warning'ами в продакшне.
Второе: избыточные абстракции. Модели любят "красивые" решения. Там, где нужна функция из 12 строк, AI выстраивает три класса с фабриками, потому что именно так выглядело большинство примеров в обучающем корпусе. Ревьюер-человек часто это пропускает: код выглядит "профессионально".
Третье: дублирование с существующими модулями. Если в проекте уже есть utils/date_helpers.py, AI об этом не знает. Он напишет новую функцию форматирования дат прямо в том файле, где его попросили. Через год в кодовой базе три реализации одного и того же.
Поэтому для AI-кода нужен отдельный чеклист, и он выглядит конкретно так:
- Дублирование с существующими модулями. Grep по кодовой базе на ключевые функции перед мержем.
- Именование. AI часто использует generic-названия:
process_data,handle_request,do_thing. Если в проекте принятоprocess_user_payment_request, чинить надо до мержа, не потом. - Ветки ошибок. Особенно в I/O-коде. AI генерирует
try/except Exception: passчаще, чем хотелось бы. Каждый блок обработки исключений требует явного взгляда. - Захардкоженные значения. Таймауты, лимиты, URL'ы, магические числа. Модели вставляют их без предупреждения.
Из инструментов: SonarQube даёт технический долг в числах, что удобно для аргументов на ретро. Semgrep позволяет написать кастомные правила под конкретный проект, например, запрет на get_event_loop() или обязательный формат логирования. Покрытие тестами >70% как gate в CI, не рекомендация, а hard requirement. AI-код без этого порога пропускать не стоит.
GitHub Copilot сейчас доминирует в корпоративных pipeline именно по одной причине: он не требует смены IDE или реструктуризации CI/CD. Copilot Business подключается к существующему GitHub Actions за пару часов. Конкурентам с более сложной интеграцией это сложно перебить, даже если качество генерации у них выше на бенчмарках.
Ревью AI-кода не сложнее обычного. Оно просто другое. Смещение акцента с "нет ли тут бага" на "нет ли тут лишнего" меняет то, на что смотришь в первую очередь.

Разработчики, которые делегируют отладку AI больше шести месяцев подряд, хуже справляются с диагностикой незнакомых ошибок без подсказок.
Безопасность: что AI-агенты делают с секретами и правами доступа
Claude Code работает прямо в терминале и по умолчанию видит всё, что видит ваш shell. Включая .env. Включая ~/.aws/credentials, если вы не позаботились об ограничениях заранее.
Это не гипотетическая угроза. Типичный сценарий выглядит так: просишь агента написать интеграцию с каким-нибудь сервисом, он генерирует рабочий код, а в конце добавляет что-то вроде:
# Для тестирования можно захардкодить прямо здесь:
API_KEY = "sk-proj-xxxxxxxxxxxxxxxx"
Комментарий "для тестирования" звучит безобидно. Но если у вас нет pre-commit хука, этот ключ спокойно уедет в репозиторий. Откатывать такое из git-истории неприятно, а если репо публичное, то ключ уже скомпрометирован в момент пуша.
Первая линия защиты: detect-secrets в pre-commit.
# .pre-commit-config.yaml
repos:
- repo: https://github.com/Yelp/detect-secrets
rev: v1.4.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
Хук сканирует diff перед коммитом и блокирует его, если находит что-то похожее на секрет: API-ключи, токены, строки подключения к БД. Baseline-файл фиксирует уже известные "ложные срабатывания", чтобы он не орал на тестовые заглушки вроде EXAMPLE_KEY.
Второй риск менее очевидный. AI генерирует SQL без параметризации, когда промпт нечёткий. Напишешь "сделай запрос, который ищет пользователя по имени", и есть шанс получить:
query = f"SELECT * FROM users WHERE name = '{username}'"
Рабочий код. Уязвимый к SQL-инъекции. Claude в 2026-м справляется с этим заметно лучше, чем год назад, но всё равно не всегда. Особенно если контекст большой и задача сформулирована небрежно.
Минимальный набор защит, который должен быть в каждом проекте с AI-агентом в разработке:
.envв.gitignore(звучит очевидно, но я видел репозитории без этого)- pre-commit с
detect-secretsили GitGuardian - SAST в CI: Semgrep или Bandit для Python, например, ловят жёстко закодированные секреты и небезопасные паттерны при каждом PR
- Ротация секретов через vault (HashiCorp Vault или AWS Secrets Manager), а не через переменные окружения напрямую
Ротация особенно важна именно потому, что агент имеет доступ к файловой системе. Если ключ утёк, но срок его жизни 24 часа, ущерб ограничен. Долгоживущий ключ, который утёк незаметно три недели назад, это другой разговор.
Права доступа для самого агента тоже нужно ограничивать явно. Claude Code поддерживает --allowedTools и директиву permissions в CLAUDE.md. Если агент занимается только фронтендом, ему незачем читать директорию с конфигами инфраструктуры. Принцип минимальных привилегий работает одинаково для людей и для AI-процессов.
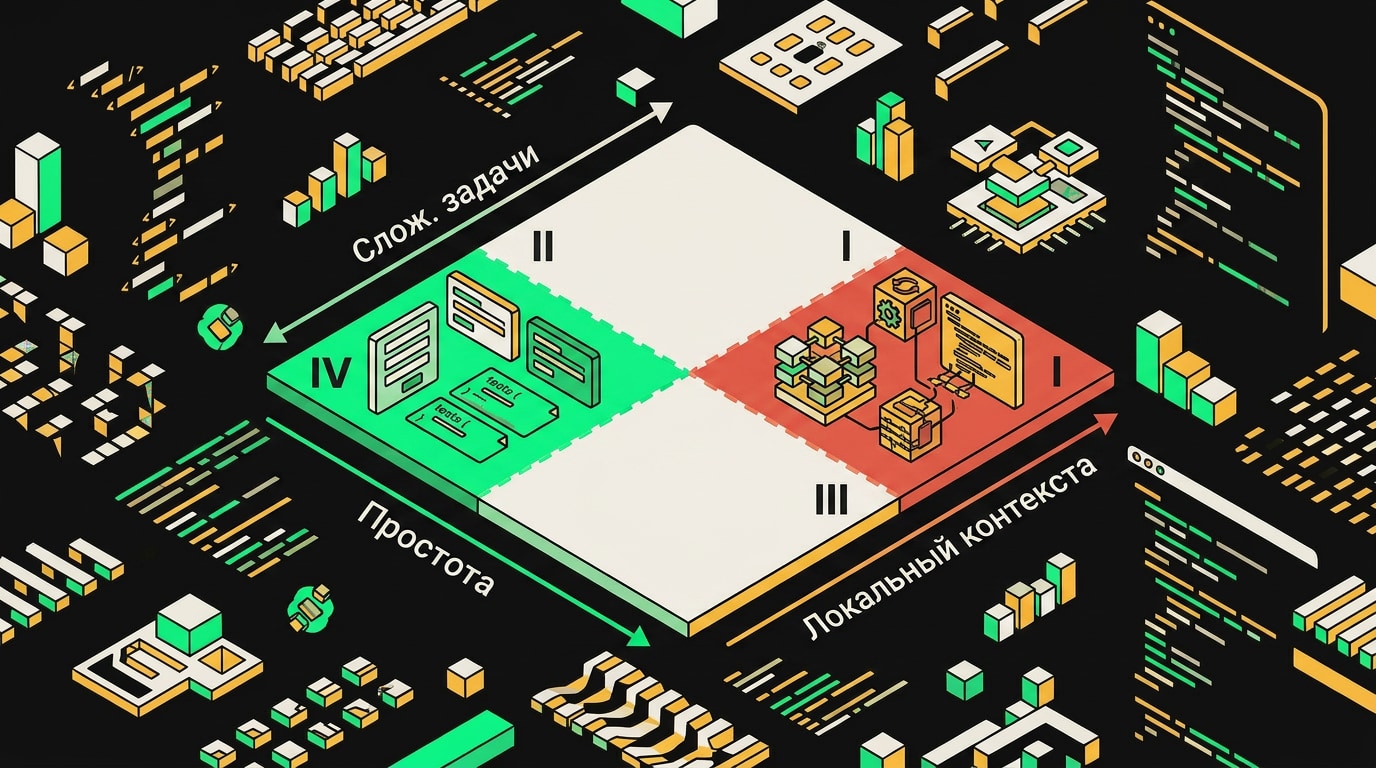
Вайбкодинг оправдан в левом нижнем квадранте матрицы: прототипы и утилиты с низкой сложностью и невысокой ценой ошибки.
Деградация навыков команды: реальная цена скорости
Часть исследователей и команд, опубликовавших наблюдения в 2025 году, фиксировали одну закономерность: разработчики, которые длительное время работают преимущественно через AI-ассистентов, могут показывать снижение навыков отладки. Не катастрофическое, но заметное на практике. Время на диагностику незнакомой ошибки растёт. Способность читать стектрейс и строить гипотезу "в голове" ухудшается.
Это не страшилка про "AI отберёт мозг". Механизм проще и скучнее: навык деградирует без практики. Мышца атрофируется.
Проблема не в том, что Copilot или Claude пишут код. Проблема в том, что разработчик перестаёт объяснять себе, почему код работает именно так. Он получает результат, тесты зелёные, PR открыт. Понимания нет, но и боли нет. Пока нет.
Симптом, который я вижу на code review чаще всего: разработчик не может ответить на вопрос "зачем вот эта строка?". Не "откуда она" (понятно, откуда), а именно "зачем". Молчание. Или: "ну, AI так сгенерировал, наверное для безопасности". Это момент, когда скорость уже стоила дороже, чем казалось.
У нас в команде работает одно правило, которое мы называем "понять перед мержем". Звучит банально, но на практике это конкретное требование: автор PR обязан объяснить логику каждого нетривиального блока, независимо от того, кто его написал, человек или AI. Не пересказать, что делает код, а объяснить решение. Почему именно такая структура, почему здесь итерация, а не рекурсия, почему этот edge case обработан именно так. Если объяснения нет, PR не мержится. Точка.
Второй инструмент грубее, но работает: ротация задач без AI. Мы намеренно выделяем категорию задач, где ассистент запрещён. Алгоритмические разборы, архитектурные решения на новых компонентах, разбор production-инцидентов. Именно там, где думать больнее всего, AI не участвует. Это не наказание. Это тренировка.
Скорость доставки фич за последний год выросла у большинства команд, которые внедрили AI в процесс. Но если не следить за тем, что происходит с людьми внутри этого процесса, через два года получишь команду, которая быстро генерирует код и медленно с ним разбирается. Это плохой обмен.
Когда вайбкодинг работает хорошо: правильный контекст применения
Я потратил несколько месяцев на то, чтобы понять, где AI-ассистенты реально экономят время, а где создают иллюзию скорости. Вывод оказался простым, но не очевидным сразу.
CRUD-эндпоин



