

Что в n8n называют мультиагентной системой и где проходит граница
Если открыть r/n8n и поискать "multi-agent", найдёшь десятки скриншотов: цепочка из трёх-четырёх AI Agent нод, стрелки между ними, гордая подпись "my multi-agent system". Проблема в том, что большинство из них не агентные системы. Это пайплайны с красивым названием.
Разница принципиальная. Линейный AI-пайплайн берёт входные данные, прогоняет через узлы по порядку и отдаёт результат. Каждый узел не знает, что делают остальные, не может передать задачу обратно или в сторону, не хранит контекст между вызовами. Это автоматизация с языковой моделью внутри. Полезная, но не агентная.
Настоящая мультиагентная система держится на четырёх вещах.
Первая: общая память или общий контекст. Агенты должны видеть, что уже сделали другие. Без shared memory каждый агент работает вслепую, и вся "агентность" разваливается на изолированные вызовы LLM.
Вторая: динамический роутинг. Оркестратор не знает заранее, кому передать задачу. Он принимает решение в рантайме на основе результата предыдущего шага. Если у тебя Switch-нода с захардкоженными условиями, это не роутинг, это if/else.
Третья: делегирование и рефлексия. Worker-агент выполнил задачу, вернул результат, critic-агент оценил его и отправил обратно на доработку. Или оркестратор переформулировал задачу, потому что первый ответ не подошёл. Петля обратной связи обязательна.
Четвёртая: автономные решения о следующем шаге. Агент сам выбирает инструмент или субагента, не по заранее прописанной логике.
В n8n на практике всё это реализуется через комбинацию: AI Agent нода с инструментами, где часть инструментов сама является вызовом другого агента (tool-agent pattern), плюс хранилище состояния через memory-ноды или внешний стор. Без memory-ноды между агентами получаешь именно то, о чём пишут на r/n8n: "я подключил пять агентов, но они не понимают друг друга".
Терминология в 2026 году уже устоялась. Orchestrator принимает задачу верхнего уровня и решает, кому её отдать. Worker выполняет конкретную, ограниченную задачу: парсит данные, пишет код, ищет по базе знаний. Router анализирует результат и выбирает следующий шаг, часто это отдельный промпт без тяжёлого контекста. Critic валидирует выход worker-а по заданным критериям и возвращает feedback. Tool-agent это агент, который оркестратор вызывает как инструмент через функциональный вызов.
Когда один AI Agent с несколькими инструментами полностью закрывает задачу? Когда задача однородная: суммаризация документа, ответ на вопрос по базе знаний, генерация текста по шаблону. Один агент с RAG-инструментом и парой API-вызовов справляется лучше, чем переусложнённая оркестрация. Я видел системы, где три агента делали то, что один делал чище и дешевле, просто потому что автор хотел "мультиагентность".
Оркестрация нескольких агентов нужна, когда задачи требуют разных компетенций и эти компетенции конфликтуют в одном промпте, когда задача слишком длинная для одного контекстного окна и её нужно декомпозировать с промежуточной валидацией, или когда часть шагов идёт параллельно и их результаты нужно синтезировать. Три сценария, не больше. Всё остальное, скорее всего, можно решить одним агентом с хорошими инструментами.
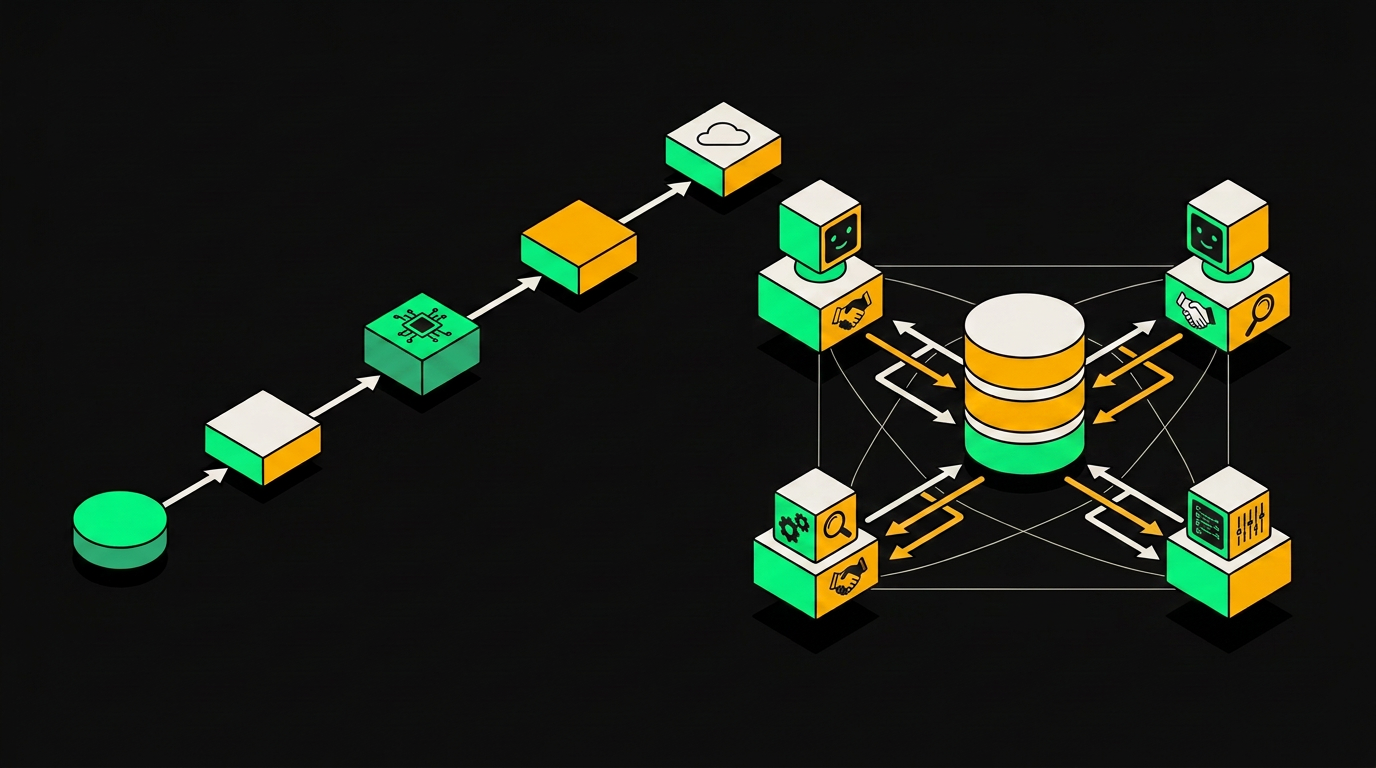
Pipeline гонит данные последовательно через каждый узел, а multi-agent позволяет агентам обращаться к общей памяти в любом порядке.
Архитектурные паттерны: orchestrator-workers, router, reflexion
Прежде чем тащить в n8n очередной узел, полезно понять, какую форму вообще принимает многоагентная система. Паттернов немного, но перепутать их дорого: неправильный выбор означает либо избыточную сложность, либо потолок качества, о который ты упрёшься через неделю после запуска.
Orchestrator-workers. Один агент-оркестратор получает задачу целиком, декомпозирует её на подзадачи и раздаёт воркерам. Воркеры специализированы: один умеет работать с базой, другой пишет код, третий читает PDF. Оркестратор не знает деталей реализации каждого; он знает только, кому что отдать и как собрать результаты обратно. В n8n это выглядит как главный AI Agent, который через Sub-workflow ноду вызывает дочерние workflow. Каждый воркер живёт в своём workflow и получает на вход только то, что ему нужно.
Этот паттерн хорошо работает, когда задача разбивается на параллельные куски без жёсткой зависимости. Например: сбор данных из пяти источников, нормализация, запись в базу. Оркестратор запускает пять воркеров одновременно и ждёт агрегации.
Router. Классификатор смотрит на входящий запрос и решает, кому его передать. Классификатор дешёвый: быстрые малые модели справляются с роутингом за доли секунды и стоят на порядок дешевле вызова GPT-4o. Дальше запрос уходит профильному агенту: вопрос по документации, вопрос по биллингу, вопрос по техподдержке. Каждый агент заточен под свою область, поэтому качество выше, чем у одного агента-универсала.
Роутер уместен, когда у тебя есть несколько чётко разграниченных доменов с разными промптами, разными инструментами, а то и разными моделями. Один большой агент, который "умеет всё", обычно делает всё посредственно.
Reflexion и self-healing. Исполнитель генерирует ответ. Критик проверяет его по заранее заданным критериям: корректность, полнота, соответствие формату. Если критик недоволен, он возвращает ревью исполнителю с конкретными замечаниями, и цикл повторяется. В n8n это петля: AI Agent (исполнитель) → AI Agent (критик) → условный узел → обратно к исполнителю или выход.
Число итераций ограничивают явно. Разумный потолок подбирается под конкретную задачу, но без ограничения вообще получишь бесконечный цикл при особо упрямой паре агентов.
Self-healing немного другое. Там агент сам ловит ошибку выполнения инструмента (HTTP 500, невалидный JSON, отказ API) и переформулирует запрос к инструменту. Это не рефлексия над качеством, это устойчивость к сбоям. В n8n реализуется через Error Trigger или retry-логику внутри Custom Code ноды.
Hierarchical agents. Это обобщение orchestrator-workers на несколько уровней. Агент верхнего уровня вызывает агентов второго уровня, те вызывают агентов третьего. Sub-workflow нода в n8n делает это нативно: вызов дочернего workflow выглядит с точки зрения родителя как обычный инструмент. Иерархия нужна, когда задача слишком большая, чтобы её декомпозировал один оркестратор, или когда домены пересекаются и нужна промежуточная координация.
Держи в голове: каждый уровень добавляет задержку и токены на координацию. Три уровня иерархии вместо двух часто удваивают стоимость запроса.
Какой паттерн брать:
| Задача | Паттерн |
|---|---|
| Параллельная обработка независимых кусков | Orchestrator-workers |
| Несколько доменов, разные промпты/модели | Router |
| Высокие требования к качеству вывода | Reflexion |
| Глубокая декомпозиция сложных задач | Hierarchical agents |
| Устойчивость к сбоям инструментов | Self-healing (retry loop) |
На практике паттерны комбинируются. Роутер направляет запрос к оркестратору, оркестратор раздаёт задачи воркерам, каждый воркер прогоняет вывод через критика. Это нормально. Главное: каждый слой должен иметь понятную ответственность, иначе дебажить это будет больно.
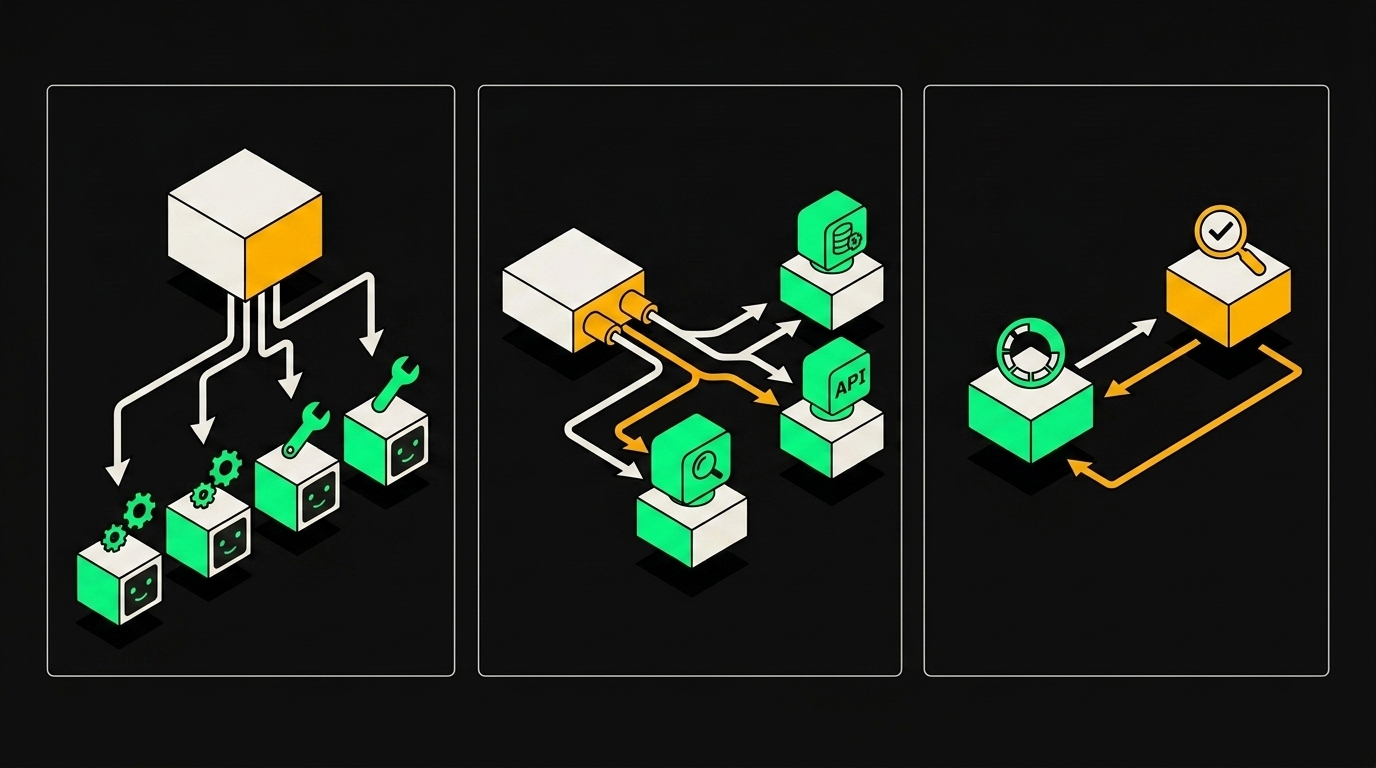
Три базовых паттерна мульти-агентных систем: оркестратор раздаёт задачи воркерам, роутер выбирает нужного агента, рефлексия запускает самопроверку результата.
Сборка orchestrator-workers воркфлоу в n8n: пошагово
Начинаю с точки входа. Chat Trigger ловит сообщение пользователя и пробрасывает его в AI Agent, который у меня выполняет роль диспетчера. В системном промпте оркестратора я прямо описываю доступных воркеров и условия их вызова. Не "ты умный помощник", а конкретика: какие задачи бывают, какие инструменты есть, в каком формате звать.
Кусок промпта оркестратора, который реально работает у меня в проде:
Ты диспетчер. Доступные воркеры:
- invoice_extractor: извлечение данных из счетов (PDF, JPG)
- contract_classifier: классификация типа договора
- entity_resolver: матчинг контрагентов с базой
Для каждой подзадачи вызови соответствующий tool с JSON по схеме task_envelope.
Если задач несколько, вызывай параллельно.
Никогда не придумывай данные сами, только через воркеры.
Воркеры. Каждый сидит в отдельном workflow со своим триггером Execute Workflow Trigger. Подключаю их к оркестратору через ноду Call n8n Workflow Tool: один tool = один воркер. Это даёт мне три вещи. Версионирование по отдельности, изолированный лог выполнения и возможность гонять воркер руками без оркестратора.
Контракт между оркестратором и воркером строгий, JSON конверт:
{
"task": "extract_invoice_data",
"context": {
"file_id": "{{$json.file_id}}",
"language": "ru"
},
"expected_output": {
"schema": "invoice_v2",
"required": ["number", "date", "total", "vat"]
},
"timeout_ms": 45000
}
Поле task использую внутри воркера для роутинга, если воркер обслуживает несколько связанных операций. expected_output.schema подставляю в системный промпт LLM-ноды воркера через выражение, чтобы агент знал, какие поля он обязан вернуть. timeout_ms читаю в первой ноде воркера и прокидываю в HTTP Request и в Wait, чтобы оркестратор не висел вечно.
Сбор результатов. Если воркеры вызывались параллельно через несколько tool calls подряд, AI Agent сам соберёт ответы в финальное сообщение, тут ничего делать не надо. Но когда мне нужен детерминированный merge (например, склеить инвойс с резолвом контрагента в одну запись), я вешаю после оркестратора ноду Merge в режиме Combine by Position или Combine by Matching Fields по file_id. Для семантической агрегации, где надо взвесить противоречивые ответы воркеров, ставлю второго агента с reduce-промптом:
На вход придут N результатов от воркеров в массиве items.
Сверь поля. При расхождении выбери значение с большим confidence.
Верни единый JSON по схеме invoice_v2.
Если данные несовместимы, верни {"error": "conflict", "fields": [...]}.
Сбои. Воркер падает редко, но больно: либо LLM провайдер вернул 429, либо PDF-парсер подавился сканом. В каждом воркере держу Error Trigger в отдельном workflow, который пишет инцидент в таблицу и шлёт алерт. А retry делаю на уровне ноды: в настройках Call n8n Workflow Tool включаю Retry On Fail, ставлю 4 попытки с Wait Between Tries и формулой экспоненты {{ 1000 * Math.pow(2, $runIndex) }} мс. Получается 1с, 2с, 4с, 8с. Для 429 от OpenAI этого хватает почти всегда.
Один нюанс, на котором я сжёг пару вечеров. Если воркер вернул ошибку, но оркестратор-агент должен это пережить и продолжить с остальными задачами, в Call n8n Workflow Tool обязательно включи "Continue On Fail" и в выходе оборачивай результат в {"status": "error", "reason": ...}. Иначе агент получит исключение, потеряет контекст параллельных вызовов и начнёт галлюцинировать ответ за упавшего воркера. Проверено.
Общая память агентов: Postgres Memory, Redis и векторные хранилища
Когда я первый раз собрал мультиагентную схему в n8n (Supervisor + три воркера: billing, shipping, support), я наступил на классические грабли. У каждого AI Agent нода своя Window Buffer Memory. Это значит, что billing-агент не знает, что support-агент уже спросил у клиента номер заказа. Клиент пишет "ну я же только что сказал", а система переспрашивает. Изоляция памяти ломает иллюзию единого ассистента быстрее, чем кривой prompt.
Минимально рабочее решение, с которого я советую начинать: Postgres Chat Memory нода с одним общим session_id на всех агентов в воркфлоу. Не на агента, а на разговор. В n8n это делается тривиально, надо подставить в поле Session ID одно и то же выражение, например ={{ $json.chatId }} во всех Memory нодах. Все агенты пишут и читают из одной таблицы n8n_chat_histories, и Supervisor видит реплики воркеров как часть истории. Этого хватает примерно для 80% сценариев поддержки, где диалог короткий и линейный.
Проблемы начинаются на длинных диалогах и при необходимости вспомнить факт из разговора недельной давности. Postgres-история растёт, в контекст её всю не запихнёшь, а LIMIT по последним N сообщениям отрезает как раз то, что нужно. Здесь подключается второй слой.
Я делаю двухуровневую схему:
Short-term, Redis. Хеш с оперативным состоянием сессии: какой агент сейчас активен, какой intent распознан последним, ID клиента, флаги. Это не история сообщений, это рабочая память маршрутизатора. Читается за доли миллисекунды, переживает рестарт n8n, легко чистится по TTL.
// Структура записи в Redis для shared memory
HSET agent:session:{sessionId}
last_intent "refund_request"
active_agent "billing_worker"
customer_id "c_8821"
updated_at "2026-05-01T10:22:14Z"
EXPIRE agent:session:{sessionId} 3600
TTL в час я ставлю по умолчанию, для саппорта норм. Для B2B-сценариев с длинными кейсами поднимаю до суток и обновляю expiry при каждом сообщении (EXPIRE после HSET). В n8n это нода Redis с операциями Hash Set и Expire, либо одна Execute Command нода с pipeline.
Long-term, векторка. Сюда уходит всё, что должно искаться семантически: фрагменты диалогов, извлечённые факты о клиенте, решения по тикетам. Я гоняю и Qdrant, и pgvector, выбор по инфре. Если Postgres уже стоит для n8n, проще не плодить сервисы и взять pgvector. Если нагрузка серьёзная и нужны фильтры по метаданным с приличной скоростью, Qdrant выигрывает.
Поверх векторки вешается Vector Store Question Answer Tool, и каждый агент получает его в tools. Агент сам решает, нужно ли лезть в долговременную память. Это и есть RAG поверх собственной истории диалога. Порог косинусной близости и число возвращаемых фрагментов подбираются под конкретный корпус: слишком низкий порог даёт шум, слишком высокий режет релевантные куски.
Стратегия вытеснения и сжатия. Без неё векторка за месяц превращается в свалку. Я делаю отдельный summarization-воркфлоу, который запускается каждые N сообщений или по крону раз в сутки. Он берёт сырые сообщения из Postgres, прогоняет через дешёвую модель (gpt-4o-mini или Llama 3.3 локально) с промптом "выдели факты о клиенте, решения и нерешённые вопросы", складывает результат в векторку с метаданными type=summary, а сырой кусок помечает как обработанный. Так в long-term живут только сжатые знания, а не транскрипт.
Один нюанс, на котором я сжёг пару дней. Если агентов несколько и они пишут в одну Postgres Memory параллельно (например, Supervisor вызывает billing и shipping одновременно через Parallel ноду), порядок сообщений в истории может нарушаться. Решение: либо последовательный вызов через Supervisor, либо писать в Redis Stream с временными метками и периодически сливать в Postgres отсортированно. Я остановился на последовательном, параллелизм в диалогах редко даёт выигрыш, который окупает геморрой с консистентностью.
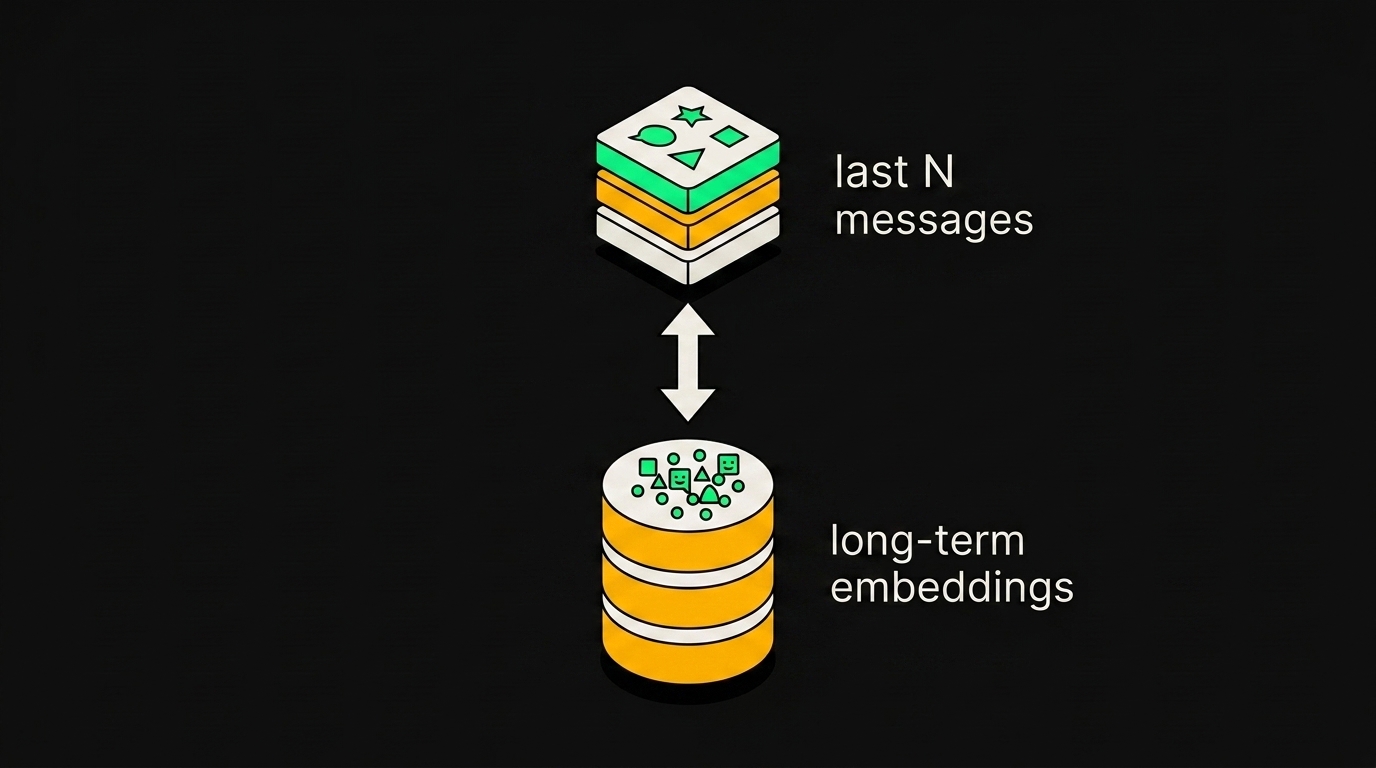
Redis хранит текущий диалог и горячие переменные, Qdrant берёт на себя долгосрочную семантическую память с поиском по близости.
Выбор моделей под роли: GPT-5.2, Claude 4, Gemini Flash, локальные через Ollama
Если сваливать все задачи на одну модель, получишь либо дорого, либо тупо, либо медленно. У меня в продакшене на пять ролей приходится четыре разные модели плюс одна локальная. Расскажу, кто за что отвечает и почему.
Orchestrator: GPT-5.2 или Claude 4 Opus. Это мозг, который читает запрос пользователя, разбирает его на подзадачи и решает, кому что отдать. Здесь нельзя экономить. Мне нужен длинный контекст (минимум 200k токенов, потому что в оркестратор летит вся история диалога плюс описания инструментов), точная декомпозиция и стабильное следование схеме JSON для плана. GPT-5.2 у меня выигрывает на сложных мультишаговых планах с ветвлениями, Claude 4 Opus лучше держит длинные технические ТЗ без галлюцинаций промежуточных шагов. Я обычно ставлю Opus, если в проекте много кода и документации, и GPT-5.2, если задачи разнородные.
Router/классификатор: Gemini 2.5 Flash или GPT-5 mini. Это быстрая модель на входе, которая решает "это вопрос про биллинг, юридический, технический или smalltalk". Один промпт, один JSON на выходе, латентность критична. На нагрузке от 50k запросов в день экономия по сравнению с использованием большой модели колоссальная. Что быстрее и точнее на пограничных случаях именно для вашей задачи, стоит замерить самостоятельно.
Воркеры по доменам. Тут уже без универсалов:
- Текст, копирайт, длинные ответы клиенту, ревью кода: Claude 4 Sonnet. Тон живее, меньше воды, лучше работает с инструкциями стиля.
- Логика, расчёты, цепочки tool calling с 5+ инструментами подряд: GPT-5 (не mini). Function calling у OpenAI всё ещё надёжнее, особенно когда нужно дёргать API в строгом порядке с обработкой ошибок.
- PII-чувствительные данные (медкарты, паспорта, внутренние HR-документы): Llama 3.3 70B локально через Ollama на своём железе. Никакие персональные данные не уходят к провайдерам. Качество ниже, чем у Sonnet, но для извлечения сущностей и суммаризации хватает с запасом. Держу на двух A100, кванты Q5_K_M, throughput около 35 токенов/сек на одного клиента.
Critic-агент: всегда другая модель, не та, что исполняла. Это правило, которое я выстрадал. Модель, склонная к определённым ошибкам, при самопроверке подтверждает их значительно чаще, чем ловит. Ставлю Claude 4 Sonnet критиком к GPT-исполнителю и наоборот. На сложных проверках (фактологическая верификация, поиск противоречий в плане) критиком идёт Opus, даже если воркер был дешёвой моделью.
Цены и расчёт
Актуальные тарифы на модели меняются, поэтому сверяйтесь напрямую с pricing-страницами OpenAI, Anthropic и Google. Ценообразование часто обновляется, и любые конкретные цифры в тексте устаревают быстрее, чем статья доходит до читателя.
Общий принцип: смешанная стратегия (дешёвая модель на роутинге, средняя на воркерах, дорогая на оркестраторе) в несколько раз дешевле, чем ставить одну топовую модель на все роли. Конкретный коэффициент зависит от вашего распределения нагрузки по ролям и актуальных цен.
Fallback-цепочка
Провайдеры падают. OpenAI, Anthropic, Google периодически сталкиваются с инцидентами и деградацией. Без резерва агент молчит, клиенты пишут злые сообщения.
В n8n я делаю это через Switch ноду после AI Agent: проверяется код ошибки и доступность. Цепочка для оркестратора: GPT-5.2 → Claude 4 Opus → GPT-5 (деградация по качеству, но работает). Для воркера-текстовика: Sonnet → GPT-5 → Llama 3.3 локально. Для роутера: Gemini Flash → GPT-5 mini.
Переключение делаю не по длинному таймауту, а по нескольким подряд 5xx или быстрому таймауту. Состояние "провайдер деградирует" держу в Redis с TTL, чтобы не долбиться в мёртвый эндпоинт каждым новым запросом. После TTL пробую снова. Простая схема, но именно она стабилизирует SLA при инцидентах у провайдеров.
Tool calling и интеграция с внешними системами
Агент без инструментов это просто чат-бот с лишним промптом. Реальная работа начинается там, где LLM получает доступ к API, базам и внутренним сервисам. В n8n у меня обычно три слоя инструментов, и я держу их отдельно по уровню доверия.
HTTP Request Tool это универсальный мост ко всему, что говорит по REST. Описание инструмента (поле description) LLM читает как часть промпта, поэтому я пишу его жёстко: какой эндпоинт, какие параметры обязательны, что вернётся, и главное чего делать НЕ надо. Например, для CRM прописываю "только чтение карточек по customer_id, никаких mutations". Это не защита, это подсказка модели. Реальная защита ниже.
Code Tool на JavaScript беру там, где LLM нельзя доверять арифметику, форматирование сумм, проверку лимитов, работу с деньгами. Модель отлично роняет копейку в дробях и охотно округляет 49999 до 50000 если её попросить "проверь лимит". Поэтому любая операция с финансовыми последствиями идёт через детерминированный код, а LLM только собирает аргументы.
// Code Tool: безопасная обёртка над платёжным API
const { amount, currency, customer_id, idempotency_key } = $input.item.json;
if (amount > 50000) {
return { error: 'amount_exceeds_agent_limit', requires_human: true };
}
const res = await this.helpers.httpRequest({
method: 'POST',
url: 'https://api.billing.internal/refunds',
headers: { 'Idempotency-Key': idempotency_key },
body: { amount, currency, customer_id },
json: true
});
return { status: res.status, refund_id: res.id };
Здесь есть три вещи, на которые я обращаю внимание у себя в команде. Первое: лимит 50000 живёт в коде, а не в промпте. Если завтра LLM решит "ну тут особый случай, можно и больше", она упрётся в return с requires_human. Второе: Idempotency-Key прокидывается в headers и генерируется выше по графу (обычно как hash от ticket_id + action_type). Если агент дёрнул refund, упал на таймауте и ретраит, биллинг вернёт тот же refund_id, а



