

Зачем вообще двусторонняя синхронизация, а не выгрузка в одну сторону
Классический сценарий: отдел продаж живёт в amoCRM, менеджеры там ставят теги, двигают сделки по воронке, пишут примечания. А финансовый директор и руководитель работают в Google Sheets, потому что привыкли, потому что там удобнее считать, потому что "так всегда было". И в какой-то момент кто-то говорит: сделайте так, чтобы и там было, и там.
Вопрос, который при этом почти никогда не задают: а зачем именно двусторонняя?
Односторонняя выгрузка закрывает большинство реальных кейсов. Если Sheets нужен для дашборда, для сводок за неделю, для того чтобы руководитель смотрел воронку, не заходя в CRM, то хватит скрипта на Apps Script или Zapier, который раз в час тянет данные в сторону таблицы. Никакой обратной записи. Looker Studio поверх того же API amoCRM закроет это ещё чище, без промежуточного хранилища. Metabase с прямым коннектором к базе тоже вариант, если данные уже где-то лежат структурированно.
Но заказчики часто превращают одностороннюю схему в двустороннюю не потому что это технически нужно, а потому что удобно редактировать прямо в таблице. "Ну и пусть эти правки улетают обратно в CRM." Вот здесь начинаются проблемы.
При двусторонней синхронизации баг не ломает одну систему. Он одновременно множит мусор в обеих. Я видел кейс, где из-за кривого маппинга поля "дата следующего контакта" скрипт за несколько часов перезаписал её у сотен сделок. В CRM всё уехало. Но и в Sheets осталась та же каша, потому что следующий цикл синхронизации затянул обратно то, что только что записал. Откат занял два дня.
Двусторонняя схема оправдана в конкретных условиях. Во-первых, правки в Sheets происходят часто, условно больше 5-10 раз в день, и каждая из них должна реально менять запись в CRM. Во-вторых, в таблице нет полей, которые конфликтуют с тем, что параллельно меняет менеджер в CRM. Если менеджер в 10:15 обновил статус сделки в amoCRM, а финансист в 10:17 сохранил строку в Sheets с тем же полем, у вас нет однозначного ответа, какая версия правильная. Нужен либо last-write-wins с явным логированием, либо раздельные поля для разных ролей.
Перед стартом я бы обсудил с заказчиком три вопроса. Какие поля реально редактируются в Sheets, а какие только читаются? Есть ли бюджет на нормальный конфликт-резолвинг или хотя бы на алерт при коллизии? И не проще ли сделать отдельную лёгкую автоматизацию через n8n, которая пишет напрямую в CRM через API, без Sheets как посредника? Это звучит как "больше работы", но на практике такая схема надёжнее и проще в поддержке, чем таблица с триггерами и скриптами, которые никто не понимает через полгода.
Двусторонняя синхронизация выглядит простой на схеме, но на практике порождает конфликты, которые сложно отловить без явной логики разрешения.
Архитектура на n8n: webhooks, polling и гибрид
Начну с того, что чистый polling в этой связке я отбросил почти сразу. Google Sheets API даёт 300 read requests per minute на проект, и если опрашивать таблицу раз в минуту по нескольким воркфлоу (сделки, контакты, задачи) с прогрузкой диапазонов через values.batchGet, лимит съедается за пару недель работы. А когда у клиента параллельно крутятся ещё отчёты на Looker Studio через тот же сервис-аккаунт, вы ловите 429 в самый неподходящий момент.
Поэтому базовая схема у меня двунаправленная и почти полностью событийная.
amoCRM → Sheets. В amoCRM настраиваются вебхуки на конкретные события: смена статуса сделки, создание лида, изменение кастомного поля (например, "Сумма к доплате" или "Дата отгрузки"). Каждый хук бьёт в свой Webhook node на n8n. Дальше идёт Function node, где я нормализую payload: amoCRM присылает данные в форме leads[status][0][...], это надо разворачивать в плоский объект, плюс приводить timestamp из unix к ISO, плюс резолвить ID пользователей и pipeline в человекочитаемые имена через кэш в Redis или в статичной мапе внутри workflow. После нормализации Google Sheets node делает appendOrUpdate по ключу lead_id.
Sheets → amoCRM. Тут вебхуков на стороне Google нет, но есть onEdit триггер в Apps Script. Скрипт висит на таблице, ловит правку конкретного диапазона (обычно колонки статуса и комментариев менеджера), собирает diff и отправляет POST на Webhook node n8n с заголовком авторизации. На стороне n8n дальше та же логика: нормализация, потом amoCRM node с методом update lead. Важный момент: в Apps Script надо ставить debounce секунд на 5, иначе при массовой правке через копи-паст вы получаете десятки одновременных POST и упираетесь в rate limit amoCRM (7 запросов в секунду на аккаунт).
[amoCRM webhook] ──┐
├──> Function (normalize) ──> Switch (event type) ──┬──> Google Sheets (upsert)
[Apps Script POST]─┘ └──> amoCRM (update)
│
[Error Trigger] <───────┘
Merge node нужен там, где одно событие порождает запись и в лист "Сделки", и в лист "История", собираю результаты обоих Sheets-нод и в Error Trigger кидаю объединённый контекст, чтобы при падении видеть сразу обе ветки.
Reconciliation. Вебхуки иногда теряются. У amoCRM бывают задержки доставки при пиковой нагрузке, и я не уверен, что поведение здесь полностью предсказуемо. Поэтому в районе 03:40 по МСК запускается ночной workflow: тянет из amoCRM все сделки, изменённые за последние 24 часа (filter[updated_at][from]), сравнивает с состоянием в Sheets через хеш ключевых полей и доливает расхождения. Квоту не трогает, расхождения ловит.
Где хостить n8n. Я гонял оба варианта. n8n Cloud удобен тем, что не надо думать про обновления и SSL, но latency вебхуков от amoCRM до европейских регионов Cloud может быть заметнее, чем при self-hosted. Для синхронизации это обычно терпимо, для сценариев, где менеджер ждёт ответа в интерфейсе, уже заметно. Self-hosted на VPS в Москве или Амстердаме (DigitalOcean, Selectel, Hetzner) даёт меньшую latency и никакого холодного старта, но вы платите вниманием: бэкапы Postgres, ротация логов, мониторинг очереди в режиме queue mode если воркфлоу больше сотни. Мой текущий дефолт, self-hosted на VPS с Postgres и Redis в docker-compose; n8n Cloud беру только если у клиента нет devops и бюджет на сопровождение нулевой.
В n8n данные могут поступать двумя путями одновременно: через вебхук amoCRM и через polling Sheets, что требует единой точки слияния.
Подводный камень №1: дубликаты при одновременном создании записи
Классическая ситуация. Менеджер заводит сделку в amoCRM в 14:32:05, аналитик в те же полминуты дописывает строку в Google Sheets по тому же клиенту. Синк отрабатывает в обе стороны, и через минуту у вас две сделки в amoCRM и две строки в Sheets. К концу недели таких пар накапливается тридцать, отдел продаж тратит час на ручное склеивание.
Корень проблемы простой: системы сравнивают записи по тому, что у них есть. Имя клиента, телефон, сумма. Любой из этих признаков может разойтись на пробел или регистр, и матчинг провалится. А значит обе стороны видят "новую" запись и честно её создают.
Лечится одним приёмом: единый внешний идентификатор, который генерится в момент создания записи и потом живёт с ней до конца. Я делаю так:
- В amoCRM добавляю кастомное поле
external_id(тип text, видимое только админам). - В Sheets первая колонка называется
row_uid, защищена от редактирования. - UID генерится на стороне источника. В Sheets через Apps Script на
onEdit, в amoCRM через виджет или webhook на событиеadd. - Перед каждым insert синк делает lookup по
external_id. Нашли совпадение, идём в update. Не нашли, тогда create.
Вот триггер для Sheets, который я ставлю первым делом на любой новой таблице:
// Apps Script: генерим row_uid при добавлении строки
function onEdit(e) {
const sheet = e.range.getSheet();
if (sheet.getName() !== 'Leads') return;
const row = e.range.getRow();
if (row === 1) return;
const uidCell = sheet.getRange(row, 1);
if (!uidCell.getValue()) {
uidCell.setValue(Utilities.getUuid());
}
}
UUIDv4 даёт коллизию на масштабах, которых у вас не будет никогда, так что про уникальность можно не думать. Важнее другое: UID должен проставляться до того, как строка попадёт в очередь на синк. Если ваш интегратор читает таблицу по расписанию раз в 5 минут, а триггер onEdit отрабатывает за миллисекунды, всё ок. Если же синк слушает изменения через push (например, через Sheets API watch), убедитесь что push-событие летит после записи UID, а не одновременно с добавлением строки.
И ещё момент про amoCRM. Хук на add приходит уже после создания сделки, то есть в окне между созданием и записью UID есть несколько сотен миллисекунд, когда сделка существует без идентификатора. Если у вас параллельно крутится синкер из Sheets, он может успеть втянуть эту сделку как новую. Я страхую это так: синкер игнорирует записи с пустым external_id и created_at моложе нескольких десятков секунд. Дёшево и закрывает гонку.
Если оба источника создают запись почти одновременно, без проверки на дубли вы получите две сделки вместо одной.
Подводный камень №2: эхо-циклы и бесконечные обновления
Сценарий, который я ловил уже трижды у разных клиентов, выглядит так. n8n обновляет ячейку в Google Sheets, на листе висит триггер onEdit, он отправляет вебхук обратно в amoCRM, amoCRM фиксирует изменение поля и шлёт update-событие в n8n. Круг замкнулся. Дальше система живёт собственной жизнью.
Симптоматика узнаваемая. Счётчик выполнений в n8n растёт ровной линией, без пиков и провалов, как будто кто-то открыл кран. Квота Sheets API (300 запросов в минуту на проект по умолчанию) выгорает часа за два, и ты получаешь 429 на ровном месте. Если посмотреть в логи amoCRM, видно, что одна и та же сделка апдейтится по 40 раз в минуту с идентичным телом.
Лечится это двумя способами, и я обычно ставлю оба сразу.
Source-флаг. В каждую запись, которую делает интеграция, дописываю служебное поле last_modified_by = "sync_bot". На входе в воркфлоу первым шагом проверяю это поле и, если оно sync_bot, выхожу. Дёшево, прозрачно, отлаживается за минуту. Минус: нужно поле, и amoCRM с Sheets должны его прокидывать без потерь (в Sheets я держу его в скрытой колонке справа).
Дедупликация по хешу полезной нагрузки. Беру значимые поля, считаю SHA-256, сравниваю с предыдущим хешем для этого lead_id. Если совпало, событие эхо, дропаю. Хранить хеш можно в Redis с TTL 60 секунд (правильнее на проде) или прямо в Static Data самого воркфлоу для быстрых прототипов и небольших объёмов.
Вот рабочий код для ноды Function в n8n, версия со встроенным Static Data:
// n8n Function node: отсев эха по хешу
const crypto = require('crypto');
const payload = JSON.stringify($json.fields);
const hash = crypto.createHash('sha256').update(payload).digest('hex');
const staticData = $getWorkflowStaticData('global');
staticData.hashes = staticData.hashes || {};
const key = $json.lead_id;
if (staticData.hashes[key] === hash) {
return [];
}
staticData.hashes[key] = hash;
return [{ json: $json }];
Пара заметок по этому коду. Static Data персистится между запусками, но живёт в БД n8n и не чистится сам, так что для тысяч лидов лучше Redis с честным TTL. И ещё: JSON.stringify не гарантирует стабильный порядок ключей при разных источниках, поэтому если amoCRM и Sheets отдают одни и те же данные в разном порядке, хеши не совпадут и эхо проскочит. Я перед хешированием прогоняю объект через сортировку ключей либо беру только белый список полей.
Если совсем коротко: source-флаг закрывает большинство случаев эхо-циклов, хеш добивает остаток, где флаг по какой-то причине не дошёл.
Эхо-цикл возникает, когда обновление в одной системе вызывает вебхук, который снова пишет в первую систему, и так по кругу.
Подводный камень №3: гонки и конфликт правок одной записи
Классический сценарий, на котором я обжёгся уже трижды. Менеджер в amoCRM открывает сделку и переключает статус на "Оплачено". В ту же секунду (буквально в ту же, разница 200 мс) аналитик в Google Sheets правит сумму, потому что нашёл опечатку в счёте. Что произойдёт без защиты? Зависит от того, чей вебхук долетит до синхронизатора последним.
Если последним прилетит апдейт из amoCRM, он принесёт с собой старую сумму (ту, что была до правки аналитика) и новый статус. Скрипт перезапишет всю строку, и исправление аналитика испарится. Если последним долетит триггер из Sheets, пропадёт статус "Оплачено". Тихо, без ошибок в логах. Через неделю кто-то заметит расхождение и начнёт винить интеграцию.
Корень проблемы в том, что мы синхронизируем объект целиком, а правки идут на уровне полей. Дальше есть три рабочих стратегии, по возрастанию сложности.
Last-write-wins по updated_at. Самое примитивное. У записи есть один таймстамп последнего изменения, побеждает тот, у кого он свежее. Дёшево, но именно эта схема и теряет данные в примере выше: статус и сумма меняются почти одновременно, а перезаписывается всё.
Lock на запись. Перед апдейтом ставим флаг "редактируется", блокируем встречные изменения, снимаем флаг после коммита. Работает, но в системе с двумя UI (amoCRM и Sheets) lock неудобный: пользователь Sheets не видит, что сделку прямо сейчас трогает менеджер, и его правка просто отвалится с ошибкой. Раздражает.
Field-level merge. То, к чему я в итоге пришёл на большинстве проектов. Синхронизируем не объект, а diff: какие поля реально поменялись и когда. Если из amoCRM пришло изменение поля status, мы трогаем в Sheets только колонку статуса, не перетирая amount. Сумму редактирует аналитик, статус приезжает из CRM, конфликта физически нет, потому что поля разные.
Тонкость в том, как считать diff. Идеально хранить updated_at на каждое поле, а не на запись. Я делал это через скрытый лист meta в той же таблице: для каждой строки данных есть зеркальная строка с таймстампами по колонкам. Переусложнение? Да. На проекте с двумя менеджерами и одной аналитичкой можно жить без этого. На проекте, где 15 человек одновременно правят сделки и параллельно идёт автоматическая выгрузка из 1С, без поколоночных таймстампов начинается ад.
Практический минимум, который покрывает большинство случаев и не требует meta-листа: вебхук amoCRM приходит с modified_user_id и updated_at. Перед записью в Sheets сравниваем updated_at из вебхука с last_sync_ts, который мы сохранили для строки в прошлый раз. Если в Sheets строка трогалась после last_sync_ts (это видно по встроенному ревизионному API Google), значит, был параллельный апдейт. Тогда не пишем целиком объект, а накатываем только те поля, которые реально изменились в amoCRM (сравниваем с локальным кэшем предыдущего состояния сделки).
Звучит душно, но реализуется это сотней строк на Apps Script плюс кэш в одном служебном листе. Зато ты перестаёшь объяснять менеджеру, почему его "Оплачено" опять слетело.
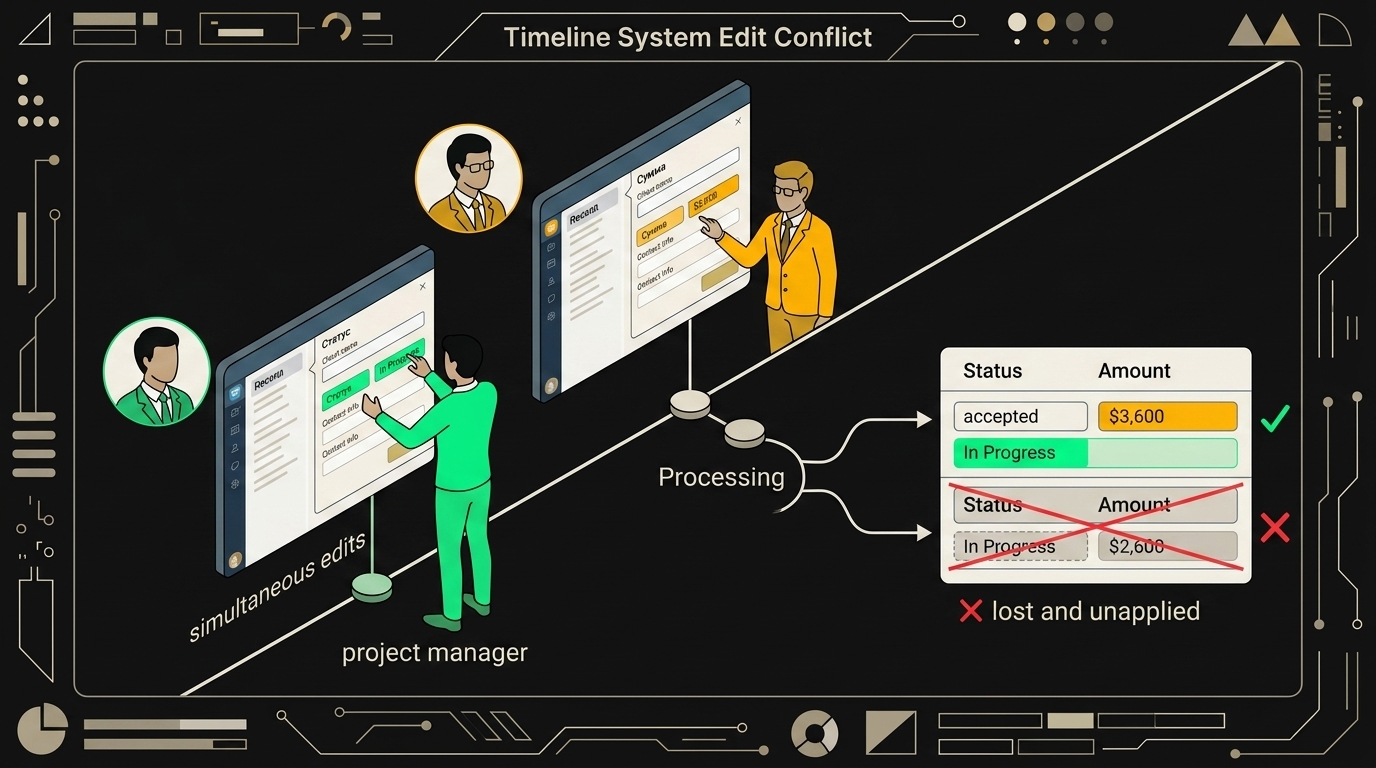
Стратегия last-write-wins проста в реализации, но молча затирает чужие правки, если два человека редактируют запись с разницей в несколько секунд.
Подводный камень №4: вебхуки amoCRM теряются и приходят пачками
amoCRM не гарантирует доставку вебхука. Если ваш endpoint вернул 500 (или просто отвалился по таймауту), повторной попытки не будет. Событие потеряно навсегда. Я ловил это на проде дважды: сначала когда n8n упал на 40 секунд во время деплоя, потом когда Sheets API отдал 503 и вся цепочка свалилась с ошибкой. В обоих случаях сделки в amoCRM обновились, а в нашей витрине нет. Расхождение нашли только через неделю, когда менеджер спросил "а где сделка Иванова за прошлый вторник".
Вторая беда противоположная по природе. Клиент решает мигрировать данные и через API за минуту обновляет 2000 сделок. amoCRM честно шлёт 2000 вебхуков пачкой. n8n в стандартном режиме обрабатывает их последовательно, очередь Webhook node забивается, начинаются таймауты, часть запросов отваливается с теми самыми 5xx. Смотри пункт первый.
Решение строится из четырёх слоёв.
Идемпотентность на входе. Webhook node делает одно: парсит payload, кладёт в очередь, отвечает 200. Никакой бизнес-логики. Дальше обработчик берёт сообщение и проверяет пару lead_id + updated_at против локального стейта (Redis, отдельная таблица, что угодно). Если такая пара уже обработана, пропускаем. Это спасает и от дублей amoCRM (а они бывают), и от повторов из очереди при сбоях.
Очередь между приёмом и обработкой. Минимум, что я рекомендую, это n8n в queue mode с Redis под капотом. Лучше RabbitMQ или Redis Streams снаружи n8n, тогда вы контролируете backpressure руками: 2000 событий встанут в очередь и спокойно прожуются за разумное время, а не убьют инстанс. DLQ для сообщений, упавших несколько раз подряд, лучше читать регулярно глазами.
Сырой лог всего входящего. Отдельный поток без всякой обработки пишет каждый вебхук в S3 (или в отдельный лист Sheets, если объёмы небольшие, до 10к в день). Поля: timestamp, headers, body, request_id. Когда через месяц приходит вопрос "почему сделка X не доехала", вы за минуту находите, был ли вообще вебхук, и если был, что в нём лежало. Без этого лога вы будете гадать.
Ночной reconciliation. Cron дёргает GET /api/v4/leads?filter[updated_at][from]={вчера} с пагинацией, проходит по всем изменённым сделкам и сверяет с тем, что лежит в Sheets. Расхождения дописывает или подсвечивает в отдельной вкладке _recon_diff. Без этого слоя тихие пропуски вебхуков всплывают только тогда, когда менеджер вручную замечает несовпадение.
Все четыре слоя работают вместе. Уберёте любой, рано или поздно поймаете тихое расхождение, которое всплывёт в самый неподходящий момент.

При массовом импорте в amoCRM система может отправить сотни вебхуков за минуту, и без очереди обработки часть событий просто теряется.
Подводный камень №5: лимиты Google Sheets и amoCRM API
Самое больное место в связках Sheets+amoCRM это даже не маппинг полей, а лимиты. Их легко не заметить на тестах с 50 строками и словить продакшн-факап на 5000.
Что у нас по цифрам. Google Sheets API: 300 read и 300 write запросов в минуту на проект, плюс 60 на пользователя. amoCRM строже: 7 запросов в секунду на аккаунт, и при превышении прилетает 429. Один криво написанный воркфлоу в n8n может положить интеграцию для всего отдела продаж.
Главная ошибка, которую вижу в чужих сценариях: Loop Over Items по 2000 строкам с нодой Google Sheets внутри, которая делает update на каждой итерации. Это 2000 запросов подряд, лимит вылетает быстро. Решение простое: spreadsheets.values.batchUpdate с массивом диапазонов в одном запросе. Расход режется в десятки раз, число запросов к Sheets на тот же объём данных падает кратно.
В amoCRM аналогично. Эндпоинт /api/v4/leads принимает массив до 250 объектов за один POST или PATCH. Если вы создаёте сделки по одной, вы просто жжёте лимит впустую. Собирайте пачку в Code-ноде, отправляйте одним запросом, парсите ответ обратно в items.
Если очень нужно бить по одному (например, у каждой сделки свои кастомные поля и батч становится монстром), ставьте Wait node между итерациями, выдерживая темп с запасом до лимита amoCRM.
Отдельно про мониторинг 429. Я всегда подключаю Error Trigger workflow для оповещений в Telegram, который ловит ошибки от основного сценария и пинает в Telegram с ID воркфлоу, эндпоинтом и телом ответа. Это спасает от ситуации "интеграция молча сломалась в пятницу вечером". Внутри ретрая делаем экспоненциальный бэкофф, вот рабочий кусок для Function-ноды:
// n8n Function: экспоненциальный бэкофф при 429
let attempt = $json.attempt || 0;
if ($json.statusCode === 429 && attempt < 5) {
const delay = Math.pow(2, attempt) * 1000;
await new Promise(r => setTimeout(r, delay));
return [{ json: { ...$json, attempt: attempt + 1, retry: true } }];
}
return [{ json: $json }];
Логика: первая повторная попытка через 1 секунду, потом 2, 4, 8, 16. После пяти неудач отдаём наверх и пусть Error Trigger разбирается.
И последнее. Если у вас несколько воркфлоу долбят один и тот же amoCRM-аккаунт, лимит общий. Я в таких случаях выношу все обращения к amoCRM в один отдельный sub-workflow с внутренней очередью через Redis или хотя бы через Wait+Static Data. Иначе два независимых сценария честно соблюдают по 4 запроса в секунду каждый, в сумме дают 8, и аккаунт уезжает в 429.

API amoCRM ограничивает количество запросов, и при синхронизации большого объёма данных без троттлинга вы быстро получите 429 и остановку потока.
Подводный камень №6: маппинг полей и типов
Самое коварное место всей интеграции. Здесь ломается больше отчётов, чем во всех остальных пунктах вместе взятых, и ломается тихо: цифры в дашборде есть, выглядят правдоподобно, а на самом деле туда уехала чушь.
Начнём с кастомных полей. В amoCRM у поля есть field_id, например 547821,
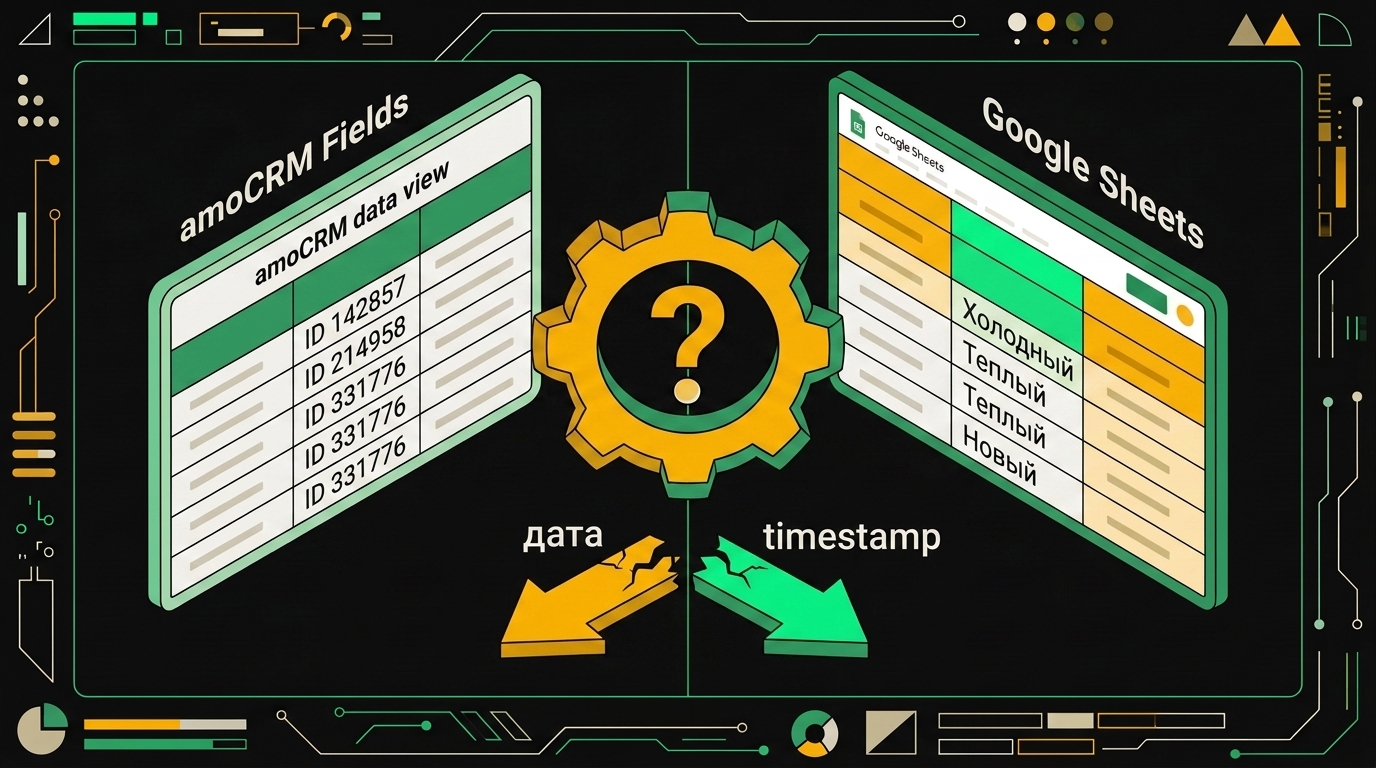
Несоответствие кастомных полей amoCRM и столбцов Sheets чаще всего обнаруживается не сразу, а когда данные уже несколько часов пишутся не туда.



