Два способа слушать amoCRM: как они устроены
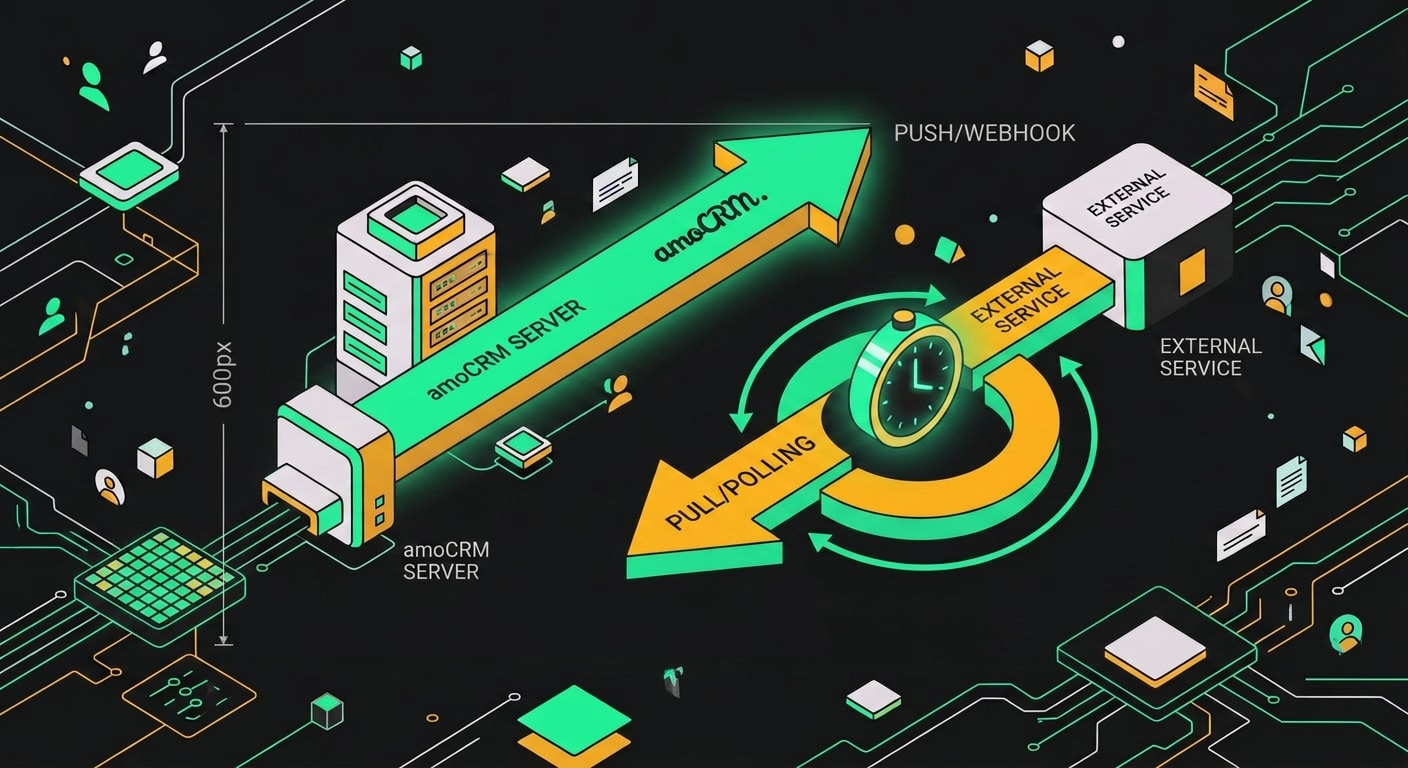
Принципиально разных способа отслеживать изменения в amoCRM два. Webhook и polling. Они решают одну задачу, но устроены противоположно.
Webhook работает по модели push. Вы регистрируете в настройках amoCRM URL своего сервера, и дальше amoCRM сам стучится к вам: при смене статуса сделки, создании контакта, изменении любого поля. Он отправляет POST-запрос на ваш endpoint с данными о событии. Вы ничего не опрашиваете и не ждёте. Событие случилось, запрос прилетел, вы его обработали.
Polling устроен наоборот: pull. Ваш сервис (или нода в n8n) по таймеру дёргает REST API amoCRM, забирает список сделок или контактов, сравнивает с тем, что было при прошлом запросе, и ищет расхождения. Ничего не изменилось, интервал прошёл, запрос ушёл снова. И так по кругу.
Грубая схема: webhook это "amoCRM звонит вам", polling это "вы звоните amoCRM каждые N секунд и спрашиваете, не случилось ли чего".
Разница в нагрузке и в задержке. Webhook реагирует мгновенно и не генерирует лишних запросов. Polling всегда немного опаздывает (на длину интервала) и тратит API-лимиты вхолостую, даже если ничего не менялось. Но webhook требует публичный endpoint с валидным HTTPS, а polling поднимается хоть на локальной машине за NAT.
Webhook сам присылает событие, polling каждый раз спрашивает сервер, вот и вся разница в подходах.
Лимиты API amoCRM в 2026 году: цифры, которые определяют выбор
По информации на момент написания, amoCRM устанавливает лимиты на уровне отдельной интеграции и всего аккаунта. Именно от этих ограничений зависит, будет ли ваша интеграция работать нормально или начнёт периодически падать с 429.
Проблема polling в том, что он тратит квоту независимо от результата. Вы делаете GET /api/v4/leads?updated_at=... каждые 10 секунд. Если за это время ни одна сделка не изменилась, запрос всё равно уходит, ответ приходит пустой, квота списана. При интервале 10 секунд это 6 запросов в минуту, 360 в час. Звучит терпимо, пока у вас одна интеграция и тихий аккаунт.
Теперь добавь реальную нагрузку. 100 сделок в час создаётся или обновляется в CRM, менеджеры параллельно работают через браузер, ещё одна интеграция тянет контакты. Polling с интервалом 10 секунд для двух сущностей (сделки + контакты) уже даёт 12 запросов в минуту только на прослушивание. Плюс запросы на обновление данных после того, как изменение обнаружено. Плюс фоновые запросы других интеграций. Аккаунтовый лимит суммирует всё, что летит с этого аккаунта, и при нескольких интеграциях его бывает проще исчерпать, чем кажется.
Webhook устроен иначе. Вы регистрируете endpoint, amoCRM отправляет POST только тогда, когда произошло событие. Никаких пустых запросов, никакого фонового расхода квоты. Сотня сделок в час превращается в сотню входящих POST на вашу сторону, и ни одного лишнего запроса к API в счёт лимита.
Если лимитов всё-таки не хватает, в разделе "Счёт и оплата" amoCRM продаётся отдельный пакет "Лимиты на API". Его можно докупить без продления основной подписки: это не апгрейд тарифа, а отдельная позиция. Но я бы смотрел на это как на последний аргумент, а не первый шаг. Потому что если вы упираетесь в лимит при polling, проблема чаще всего архитектурная, а не в том, что лимит слишком мал.

При частоте опроса раз в минуту polling съедает 1440 запросов в сутки даже при нулевой активности в CRM.
Webhook в amoCRM: как подключить и что реально приходит в payload
Подключение живёт в двух местах. Первое: «Настройки» > «Интеграции» > вкладка «Webhook». Там можно указать URL и выбрать события глобально для всего аккаунта. Второе место: Digital-воронка, триггер «Отправить webhook». Это точечно: событие срабатывает только когда сделка попадает в конкретный этап.
Для большинства задач автоматизации Digital-воронка удобнее, потому что вы контролируете, при каком переходе отправляется запрос. Глобальные вебхуки из раздела интеграций плюют событиями на каждый чих: изменили имя контакта, сменили ответственного, поменяли любое поле. Если endpoint не готов к такому потоку, очередь быстро превращается в мусор.
Поддерживаемые события: добавление и изменение сделки, контакта, компании; смена ответственного; изменение статуса (то есть переход между этапами воронки). Событие удаления тоже есть, но на практике оно срабатывает непредсказуемо.
Что реально прилетает
Вот здесь начинается боль для всех, кто привык к нормальным REST API. amoCRM отправляет payload в формате application/x-www-form-urlencoded. Не JSON. Это ломает дефолтные настройки n8n, Zapier-подобных инструментов и любых серверов, которые ждут Content-Type: application/json.
Структура после decode выглядит так:
// Пример структуры входящего webhook от amoCRM (decoded form-data)
{
"leads[status][0][id]": "12345",
"leads[status][0][status_id]": "67",
"leads[status][0][pipeline_id]": "100",
"leads[status][0][old_status_id]": "66",
"leads[status][0][responsible_user_id]": "777",
"account[id]": "99999",
"account[subdomain]": "mycompany"
}
Ключи содержат вложенность в виде строк с квадратными скобками. В PHP parse_str() это разберёт в нормальный ассоциативный массив автоматически. В Python придётся парсить вручную или использовать urllib.parse.parse_qs. В n8n нужно явно указать «Form-Urlencoded» в настройках Webhook-ноды, иначе тело запроса придёт как пустой объект.
Тип события кодируется в самом ключе: leads[add], leads[update], leads[status], contacts[add] и так далее. Индекс [0] означает, что в одном запросе теоретически могут прийти несколько объектов, но на практике amoCRM почти всегда шлёт по одному.
Таймауты и надёжность
Два момента, которые обходятся дорого если их не знать заранее.
Первый: ответить HTTP 200 нужно за 3 секунды. Если endpoint молчит дольше, amoCRM считает доставку неудачной. Это значит, никакой тяжёлой логики прямо в обработчике. Принял запрос, сохранил в очередь, ответил 200, потом обработал асинхронно.
Второй: повторных попыток нет. amoCRM не ретраит. Если endpoint был недоступен в момент события, данные потеряны навсегда. Это не гипотетический сценарий. Деплой, перезагрузка сервера, случайный таймаут у хостера, и вы пропустили десяток сделок без каких-либо логов на стороне amoCRM.
Обход стандартный: ставите перед основным обработчиком лёгкий прокси (например, отдельная serverless-функция или простой Express-сервер), который только принимает и сохраняет в базу или брокер сообщений. Основная логика читает оттуда.
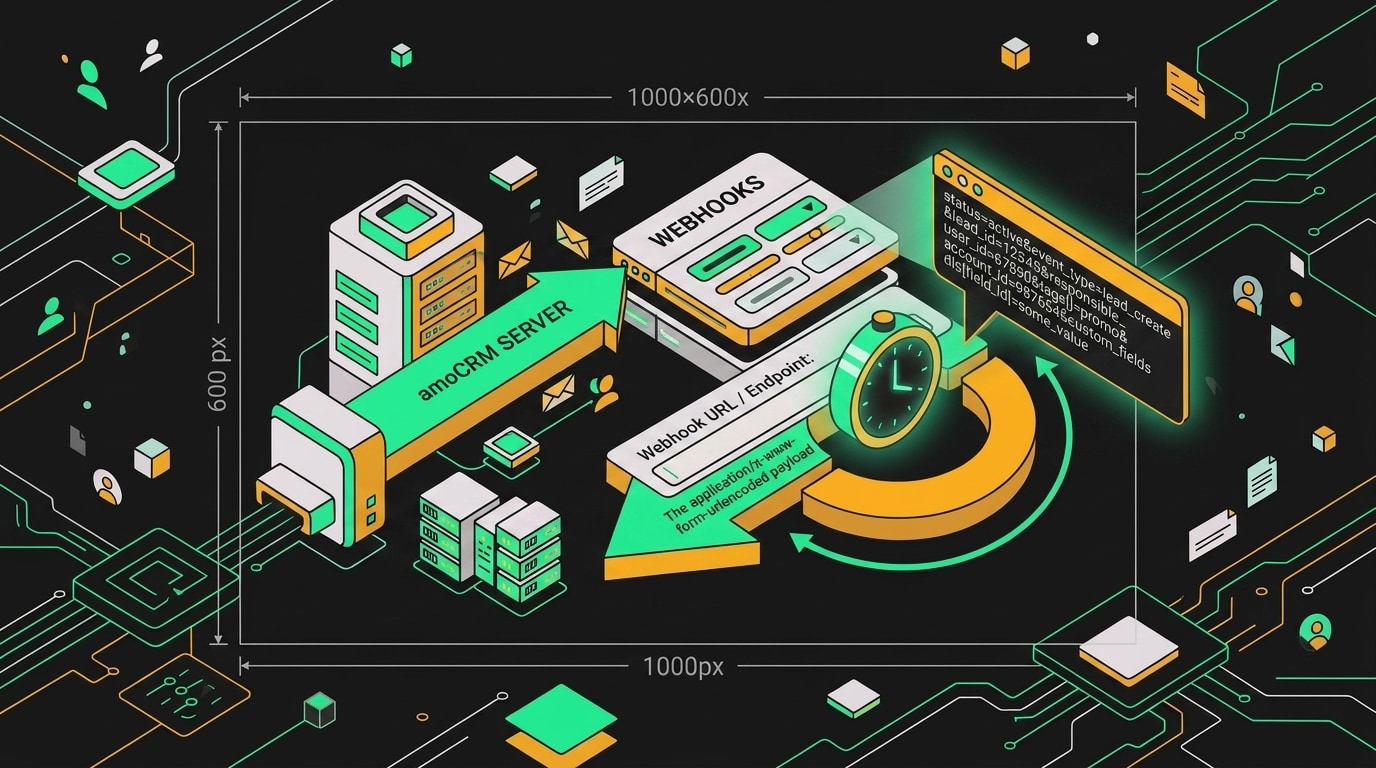
В разделе «Интеграции» amoCRM принимает URL endpoint и список событий, на которые нужно подписаться.
Polling через REST API amoCRM: когда и как делать правильно
Webhook удобен, но не всегда доступен. Если интеграция работает внутри корпоративной сети без внешнего IP, или нужна история изменений за конкретный период, polling через REST оказывается единственным рабочим вариантом. Аналогичная задача часто возникает при двусторонней синхронизации данных между CRM и внешними сервисами, где polling помогает поддерживать актуальность записей без внешнего endpoint.
Базовый запрос выглядит так:
GET /api/v4/leads?filter[updated_at][from]={timestamp}
Параметр filter[updated_at][from] принимает Unix-timestamp. API вернёт все сделки, у которых поле updated_at больше или равно этому значению. Простая идея, но есть несколько мест, где легко сломаться.
Где хранить last_checked_at. Нельзя держать метку времени только в памяти процесса. При перезапуске сервиса потеряете окно и либо пропустите изменения, либо обработаете их повторно. Минимальный вариант: записывать timestamp в Redis сразу после успешного прохода. Если Redis нет, подойдёт отдельная таблица в PostgreSQL с единственной строкой. Главное: обновлять метку только после того, как события реально обработаны, а не в начале итерации.
Интервал запросов. Ориентируйтесь на актуальные лимиты из документации amoCRM. Если интеграция одна, 30 секунд между итерациями дают вполне комфортный запас. При 15 секундах тоже нормально, но если у вас несколько интеграций на одном аккаунте (например, ещё и синхронизация контактов), они суммируются и легко упираются в лимит. Тогда получите 429, и цикл начнёт пропускать итерации.
Минимальный polling-цикл на Node.js:
const axios = require('axios');
async function pollAmoCRM(lastChecked) {
const response = await axios.get(
'https://mycompany.amocrm.ru/api/v4/leads',
{
params: { 'filter[updated_at][from]': lastChecked },
headers: { Authorization: `Bearer ${process.env.AMO_TOKEN}` }
}
);
return response.data._embedded?.leads ?? [];
}
// Вызов каждые 30 секунд
setInterval(async () => {
const leads = await pollAmoCRM(Math.floor(Date.now() / 1000) - 30);
leads.forEach(lead => processLead(lead));
}, 30000);
Несколько замечаний по этому коду. setInterval здесь работает как простой таймер, он не ждёт завершения предыдущей итерации. Если pollAmoCRM выполняется дольше 30 секунд (например, при медленной сети или тяжёлом processLead), вызовы начнут накапливаться. Для продакшна лучше использовать рекурсивный setTimeout или явную блокировку через флаг.
Второй момент: Math.floor(Date.now() / 1000) - 30 вычисляет метку каждый раз заново, а не берёт сохранённое значение. Это работает только если сервис не падал. В реальной интеграции нужно читать last_checked_at из Redis перед каждым вызовом и писать туда новое значение после обработки.
Про токены. process.env.AMO_TOKEN это правильный подход: токен не попадает в код и не уходит в репозиторий. Но переменных окружения недостаточно, если сервер скомпрометирован. Access Token у amoCRM живёт 24 часа, Refresh Token: 3 месяца. При утечке оба нужно немедленно инвалидировать через интерфейс интегратора и перевыпустить. Для команд, которые параноидально относятся к секретам (и правильно делают), имеет смысл держать токены в HashiCorp Vault с динамическим чтением при каждом запуске.
Polling проигрывает webhook по задержке реакции, но выигрывает по предсказуемости. Вы точно знаете, что запрос ушёл, получили ответ, обработали. Никаких проблем с недоступностью принимающего endpoint, никаких потерь при временном падении вашего сервиса.
n8n + amoCRM: webhook-нода против polling Schedule Trigger
Встроенный amoCRM-нод в n8n при активации workflow сам регистрирует webhook-endpoint в CRM. Это удобно: не нужно лезть в настройки amoCRM, создавать хуки вручную через API или копировать URL. Активировал workflow, нода отправила POST на api/v4/webhooks, получила подтверждение, и с этого момента события летят напрямую.
Но работает это только если у вашего n8n-инстанса есть публичный URL с валидным SSL. На self-hosted без reverse proxy (nginx, Caddy, Traefik) webhook просто не зарегистрируется, потому что amoCRM при создании хука сразу делает тестовый запрос и проверяет ответ 200. Нет SSL, нет доступного хоста, нет хука. Тут нужен либо Caddy с автоматическим Let's Encrypt, либо туннель типа ngrok на время разработки.
На n8n Cloud с этим проще. Публичный URL есть из коробки, SSL есть, так что webhook-триггер поднимается без танцев.
Альтернатива: Schedule Trigger плюс HTTP Request нода. Раз в минуту или раз в пять минут делаешь GET-запрос на api/v4/leads?filter[updated_at][from]=..., сравниваешь с временем прошлого запуска и вытаскиваешь только свежие записи. Работает везде, не требует публичного URL. Но у этого подхода есть конкретная цена: каждое срабатывание Schedule Trigger тратит execution-кредиты на n8n Cloud, даже если в amoCRM за эти пять минут ничего не изменилось. Workflow запустился, HTTP Request вернул пустой массив, кредиты списаны. При polling раз в минуту это 1440 executions в сутки только на один workflow с нулевой полезной нагрузкой в спокойный период.
Webhook-триггер делает один execution ровно тогда, когда событие произошло. Пришёл новый лид, сработал триггер, execution потрачен. Нет лидов, нет executions. Если у вас несколько workflows на amoCRM-события, разница в счёте становится заметной уже в конце первого месяца. Схожая экономия кредитов достигается и в других CRM-связках: например, при автоматизации заказов через RetailCRM и n8n webhook-триггеры позволяют обрабатывать только реальные события без холостых запусков.
Отдельный момент по payload. amoCRM отправляет данные в формате application/x-www-form-urlencoded, не JSON. В n8n это значит, что тело запроса приходит как строка, и стандартное обращение {{ $json.body.leads.add[0].id }} не сработает напрямую. Нужна промежуточная нода: либо Code (раньше называлась Function), либо Set с выражением. Вот базовый пример для Code-ноды:
const body = $input.first().json.body;
const leads = body['leads[add][0][id]']
? Object.entries(body)
.filter(([k]) => k.startsWith('leads[add]'))
: [];
return [{ json: { raw: body } }];
Формат ключей у amoCRM после URL-decode выглядит как leads[add][0][id], leads[add][0][name] и так далее. Удобнее всего сразу парсить это в нормальный объект через простую рекурсивную функцию или библиотеку qs, если вы на self-hosted и можете поставить npm-пакеты в n8n.
На практике для n8n Cloud я выбираю webhook-нод без вариантов. Для локальной разработки или корпоративного self-hosted за внутренним файрволом без публичного выхода, polling через Schedule + HTTP Request иногда единственный реалистичный вариант. Просто нужно понимать, что платишь за него кредитами вхолостую.
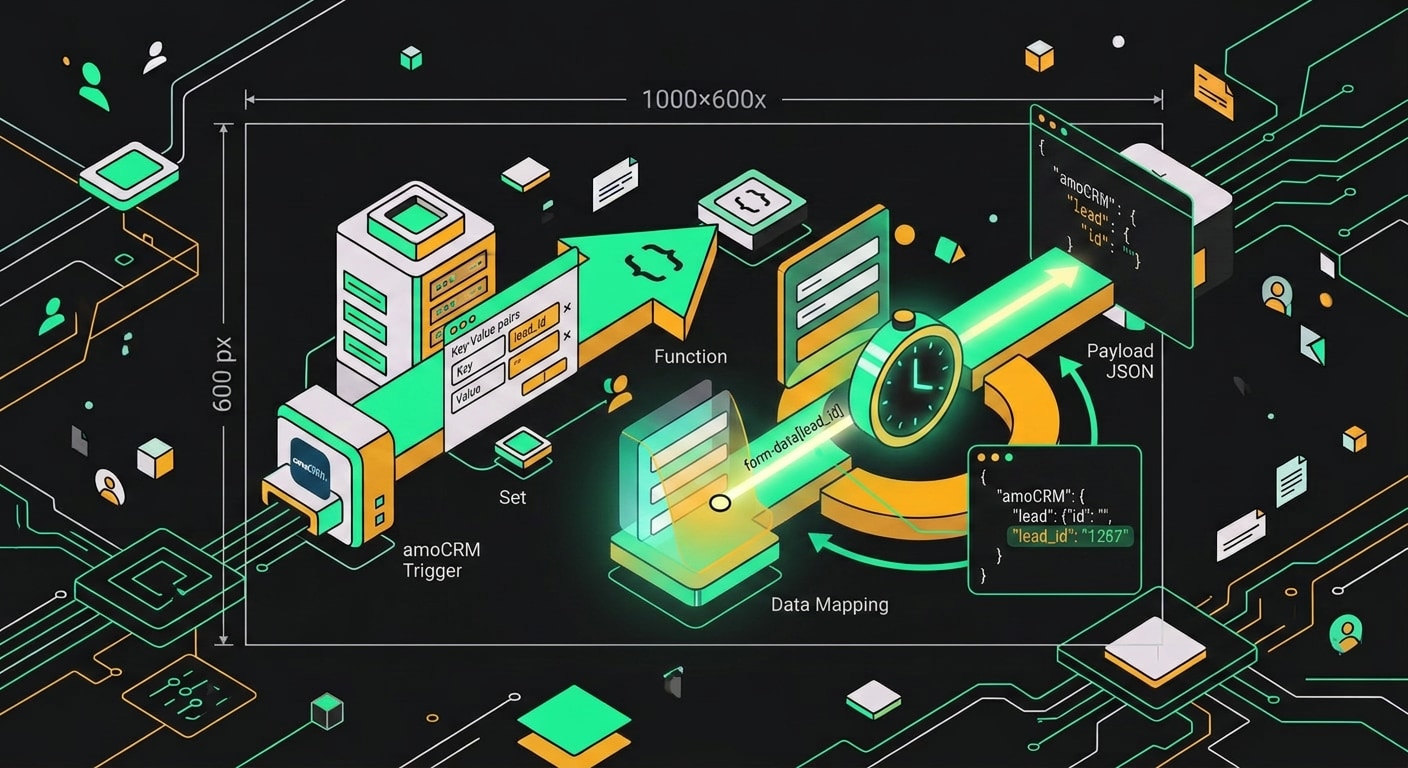
Нод Webhook в n8n получает payload от amoCRM и сразу передаёт данные в следующий шаг без лишнего кода.
Надёжность доставки: что теряется при webhook и как это компенсировать
amoCRM не хранит очередь неотправленных событий и не делает retry. Упал ваш сервер на 3 минуты, пока деплоили фикс, или истёк таймаут SSL, который вы забыли обновить: webhook ушёл в никуда и не вернётся. amoCRM просто получила 5xx или таймаут и двинулась дальше. Никакого dead letter queue, никакого повторного запроса через минуту.
Это значит, что строить критичную бизнес-логику только на webhook, это строить её на канале без гарантий доставки.
Рабочая схема выглядит так: webhook обрабатывает события в реальном времени, а polling с интервалом 5-10 минут работает как страховочная сетка. Каждые N минут запрашиваете /api/v4/leads с фильтром filter[updated_at][from]=<timestamp последнего успешного прогона> и сверяете результат с тем, что уже есть в вашей БД. Лиды, которые изменились, но не прошли через webhook, всплывут здесь.
Для сценариев вроде "смена статуса запускает выставление счёта" я бы перевернул приоритет: polling с интервалом 1-2 минуты как основной канал, webhook как ускоритель. Да, это чуть дороже по запросам к API, зато вы знаете, что каждое изменение статуса будет обработано максимум через 2 минуты, независимо от состояния вашего endpoint.
Теперь про идемпотентность. Первое, что делает обработчик webhook при получении события, до любой бизнес-логики, до отправки письма и до записи в CRM: сохраняет сырой payload в лог-таблицу. Структура минимальная:
CREATE TABLE webhook_log (
id SERIAL PRIMARY KEY,
dedup_key VARCHAR(64) UNIQUE,
payload JSONB,
received_at TIMESTAMPTZ DEFAULT now(),
processed BOOLEAN DEFAULT false
);
Поле dedup_key строится как lead_id + '_' + updated_at. Если webhook и polling одновременно принесут одно и то же событие (что при гибридной схеме неизбежно), INSERT с ON CONFLICT DO NOTHING просто проигнорирует дубль. Бизнес-логика запускается только при успешной записи.
Это решает две проблемы сразу. Первая: вы не обрабатываете одно событие дважды при параллельных сигналах. Вторая: при рестарте воркера или сбое в середине обработки вы можете переиграть все события с processed = false, не боясь задвоения.
Один нюанс с полем updated_at в amoCRM: оно обновляется с точностью до секунды. Если два изменения одного лида произошли в одну секунду, у них будет одинаковый dedup_key. На практике такое случается редко, но если хотите перестраховаться, добавляйте в ключ хэш от самого payload или используйте комбинацию lead_id + updated_at + pipeline_status_id.
Очередь между webhook и обработчиком сглаживает пики нагрузки и страхует от потери событий при временном сбое.
Производительность под нагрузкой: цифры из практики
Возьму конкретный сценарий: 500 обновлений сделок в час. При webhook-подходе это 500 входящих POST-запросов к вашему серверу. При polling с интервалом 30 секунд это 120 запросов к API amoCRM, каждый из которых возвращает батч изменений. На первый взгляд polling выглядит экономнее по нагрузке на вашу инфраструктуру. Но это не совсем честное сравнение: 120 запросов к внешнему API с авторизацией и парсингом ответа стоят дороже, чем 500 лёгких POST, которые вы просто кладёте в очередь.
Теперь поднимаем нагрузку до 5000 обновлений в час. Polling с интервалом 10 секунд даёт 360 API-запросов в час. При соответствии лимитам аккаунта это укладывается, и каждый запрос тянет батч изменений. Звучит разумно. Но webhook при той же нагрузке генерирует 5000 входящих запросов в час, то есть примерно 1,4 запроса в секунду. Без очереди (Redis, RabbitMQ) вы начнёте терять события на пиках: ваш обработчик не успеет ответить 200 OK за отведённое amoCRM время, и платформа засчитает доставку как неудачную.
Я видел кейсы, где разработчики писали синхронный webhook-обработчик: принял запрос, обновил базу, ответил. При спокойном трафике работает. При пике в 50 событий за 5 секунд начинаются таймауты. Очередь решает это за счёт простого паттерна: принял POST, положил payload в очередь, ответил 200 за 10 миллисекунд. Дальше воркеры разгребают в своём темпе.
По латентности разница принципиальная. Webhook реагирует на события быстро, с небольшой задержкой на стороне amoCRM. Polling добавляет задержку, равную интервалу опроса: поставили 30 секунд, значит реакция от 0 до 30 секунд, медиана около 15. Если у вас SLA с требованием "среагировать за 5 секунд", polling с интервалом 30 секунд физически не выполнит это требование. Половина событий будет обрабатываться позже дедлайна. Тут не нужно считать процентили, всё очевидно из геометрии задачи.
Polling с коротким интервалом (скажем, 5 секунд) технически даст latency, сравнимую с webhook, но сожжёт API-квоту: 720 запросов в час только на один поллер. При нескольких интеграциях одновременно это становится проблемой быстро. Чтобы оценить, сколько таких интеграций реально нужно отделу продаж, полезно посмотреть на типовой набор внешних сервисов для Bitrix24: там хорошо видно, как быстро накапливаются параллельные источники запросов.
При 500 событиях в час polling генерирует тысячи холостых запросов, тогда как webhook делает ровно 500 вызовов.
Безопасность: защита webhook endpoint и хранение токенов
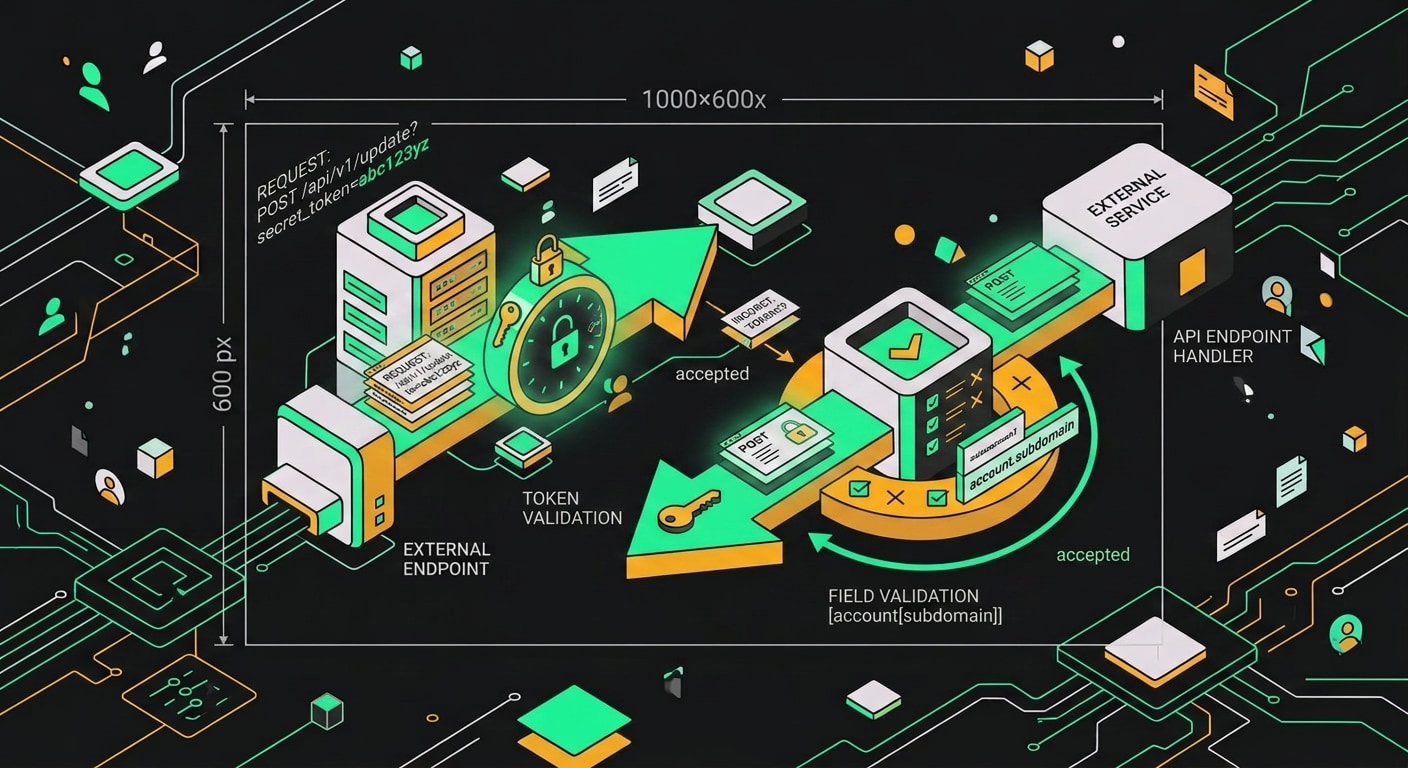
amoCRM не подписывает webhook-запросы через HMAC. Это значит, что проверить отправителя стандартным криптографическим способом не получится. Любой, кто знает адрес вашего endpoint, может слать туда POST-запросы, и вы не отличите их от настоящих.
Минимальная защита, секретный токен в URL. Регистрируете webhook с адресом вроде https://your-app.com/webhooks/amocrm?token=s3cr3t_r4ndom_string, и на сервере первым делом сверяете этот параметр. Если нет или не совпадает, возвращаете 401 и дальше не читаете payload. Другой вариант: базовая HTTP-аутентификация, если ваш фреймворк её удобно прикручивает. Оба подхода слабее HMAC, но это лучше открытого endpoint.
Второй рубеж: проверка поля account[subdomain] в теле запроса. Если ваша интеграция обслуживает один аккаунт mycompany, а в payload пришёл subdomain=someoneelse, запрос надо отклонить немедленно. Это ловит случай, когда кто-то настроил чужой webhook на ваш URL (случайно или намеренно).
Теперь про хранение токенов. Access Token, Refresh Token и `