Что тормозит тендерный отдел без автоматизации
Представьте двух-трёх специалистов, которые каждое утро открывают zakupki.gov.ru и начинают листать. Потом агрегаторы. Потом снова ЕИС, потому что с утра появились новые позиции. На ЕИС ежедневно публикуются тысячи закупок по 44-ФЗ и 223-ФЗ, и физически отсмотреть их без потерь невозможно. Что-то пропустят. Всегда.
Пропущенный тендер - это не просто строчка в отчёте. Это конкретная выручка, которой не будет. А тендер, замеченный за три дня до дедлайна, ещё хуже: заявку сделают, но плохую. Нормальная заявка требует существенного времени в зависимости от сложности лота. Нужно собрать документы, заполнить формы под конкретную площадку, проверить требования к участнику, свериться с реестром недобросовестных поставщиков. Если время есть - делаешь это внимательно. Если нет - делаешь кое-как.
Но главная проблема даже не в пропущенных тендерах.
Специалист тендерного отдела тратит значительную часть своего времени на поиск и первичный отбор. На то, чтобы просто найти подходящие закупки в потоке нерелевантного шума. На анализ конкурентов, на стратегию ценового предложения, на работу с заказчиком - времени почти не остаётся. Человек с квалификацией аналитика работает как парсер.
Это не проблема конкретного сотрудника или отдела. Это структурный дефект: процесс выстроен так, что самая дорогая часть работы (думать) вытесняется самой дешёвой (смотреть и копировать).

По оценкам практиков, до 60% рабочего времени тендерного специалиста уходит на поиск и первичный отбор закупок, а не на подготовку заявок.
Архитектура AI-агента: из чего он состоит
Агент для мониторинга тендеров устроен в три слоя, и если убрать любой из них, система либо слепнет, либо немеет.
Первый слой: источники данных. Главный из них - ЕИС (zakupki.gov.ru). Портал поддерживает интеграцию через SOAP и REST согласно требованиям к информационному взаимодействию, документация публично доступна. На практике REST работает стабильнее, особенно при поллинге новых закупок по дате публикации. Параллельно подключаются коммерческие агрегаторы: Мультитендер, например, даёт API с уже нормализованными данными и охватывает региональные площадки, которые ЕИС индексирует с задержкой. RSS-ленты некоторых агрегаторов закрывают оставшиеся щели. Итог: три источника, каждый со своей задержкой и форматом.
Второй слой: обработка. Здесь живёт логика того, что агент считает "вашим" тендером. Сначала работает классификатор: фильтрует по ОКПД2, ключевым словам в названии и описании, иногда по конкретным заказчикам из белого или чёрного списка. Это быстро и дёшево. Тендеры, прошедшие фильтр, передаются в LLM. Модель разбирает техническое задание, вытаскивает требования к опыту, срокам, обеспечению, специфические ограничения. После этого скоринговая модель присваивает закупке оценку релевантности: например, от 0 до 100, где выше 70 уходит к менеджеру, от 40 до 70 попадает в дайджест, ниже - в архив.
LLM здесь выполняет именно ту часть, которую классификатор не осилит: читать ТЗ на 40 страниц и понять, что формально подходящий тендер на поставку серверов требует сертификат ФСТЭК, которого у компании нет.
Третий слой: действия. После скоринга агент не просто молчит. Telegram или email доставляют уведомление с карточкой тендера: номер, заказчик, НМЦК, срок подачи, оценка релевантности и краткое резюме от LLM. Если компания решает участвовать, агент заполняет шаблон заявки данными из извещения - реквизиты заказчика, предмет, сроки. Запись уходит в CRM, менеджеру ставится задача с дедлайном за три дня до окончания приёма заявок.
По расписанию или по событию - это отдельный выбор. Cron раз в час подходит для большинства случаев, ЕИС всё равно публикует данные с некоторой задержкой. Webhook реален при работе через агрегаторы, у части из них есть механизм push-уведомлений. Гибридная схема выглядит так: webhook от агрегатора плюс cron по ЕИС каждые 30 минут для перепроверки.
Весь пайплайн от появления закупки в системе до уведомления менеджера укладывается в 2-5 минут. Без агента тот же путь вручную занимает от часа до "мы это пропустили".
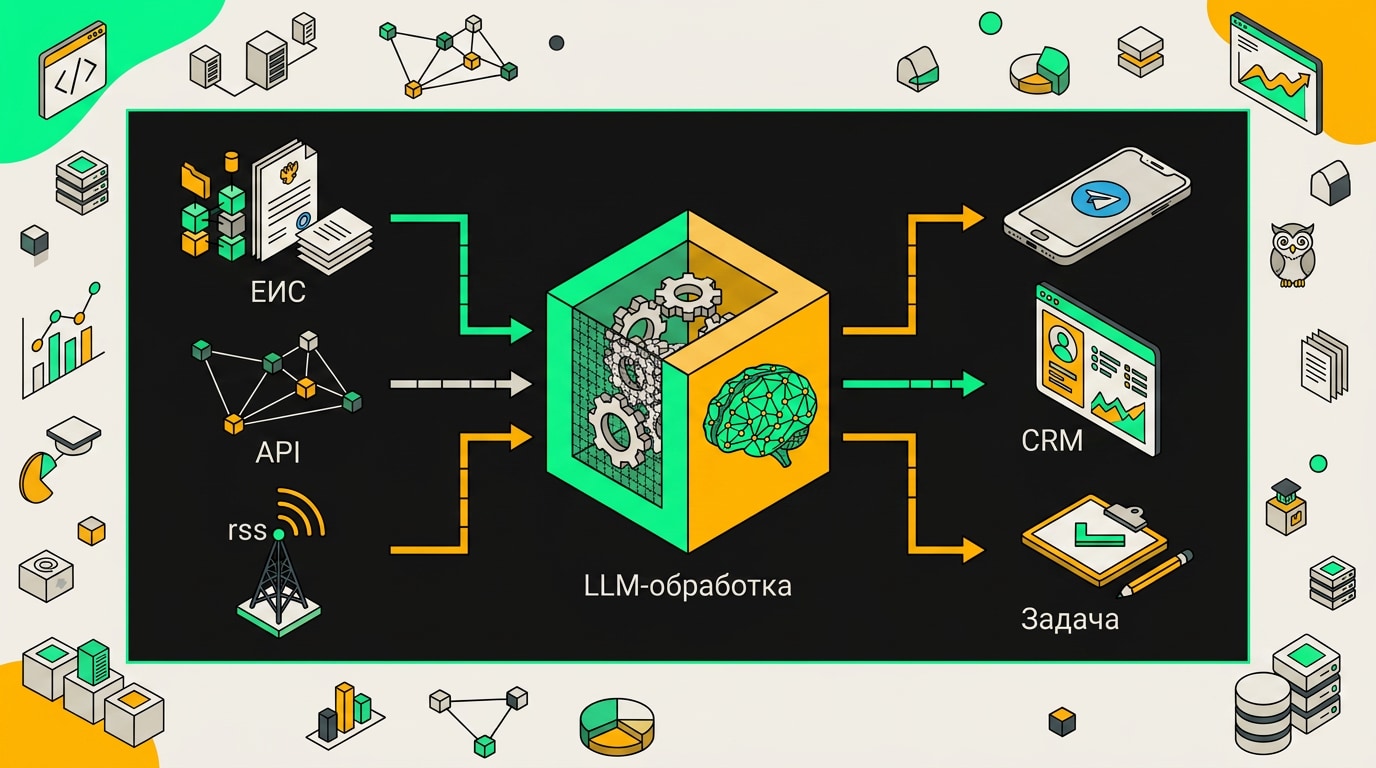
Агент получает данные из внешних источников, обрабатывает их языковой моделью и вызывает инструменты для конкретных действий, поиска, фильтрации, генерации текста.
Подключение к данным ЕИС и агрегаторам
Официальный источник всего один: zakupki.gov.ru. Там лежат открытые данные по 44-ФЗ и 223-ФЗ, доступ через SOAP, формат XML. Документация называется "Требования к информационному взаимодействию" и находится в разделе для разработчиков на том же портале. Звучит нормально, пока не откроешь схему.
SOAP-интерфейс ЕИС неудобен практически. Схема XSD многоуровневая, отклик на запрос занимает несколько секунд даже при небольшой выборке, а полученный XML надо разбирать вручную. Для продакшн-системы это решаемо, но для MVP или первого прототипа тратить неделю на разбор схемы нецелесообразно.
Коммерческие агрегаторы закрывают эту боль. Мультитендер и Тендерплан дают REST API с JSON, фильтрацией прямо в параметрах запроса и покрытием сразу трёх слоёв: 44-ФЗ, 223-ФЗ и коммерческие торги. Стоимость подписки зависит от тарифа и выбранных площадок; при активном использовании она, как правило, окупается за счёт сэкономленного времени на разработку.
Фильтрация на уровне запроса там реально полезная. Можно указать код ОКПД2 (классификатор видов деятельности), регион по коду ФИАС или ОКТМО, диапазон НМЦ (начальная максимальная цена контракта), тип процедуры и статус. Это означает, что клиенту прилетают только релевантные закупки, а не весь поток, который потом нужно фильтровать на своей стороне.
Запрос к Мультитендер выглядит так:
# Пример запроса к REST API Мультитендер
import requests
params = {
'apiKey': 'YOUR_KEY',
'okpd2': '62.01.1', # разработка ПО
'regionCode': '77', # Москва
'priceFrom': 500000,
'law': '44',
'status': 'published',
'limit': 50
}
resp = requests.get('https://api.multitender.ru/v2/tenders', params=params)
tenders = resp.json()['items']
print(f'Найдено: {len(tenders)} закупок')
Параметр okpd2 принимает как точный код, так и префикс. Если передать 62, вернутся все закупки по IT-разделу целиком. Для первых тестов удобно, потом лучше сужать до конкретного подкласса, иначе в выдаче окажутся ремонт оргтехники и техподдержка 1С вперемешку с разработкой.
Для MVP без бюджета на коммерческий API есть резервный вариант: RSS-ленты. Тендерплан и СБИС.Тендеры публикуют их бесплатно с базовой фильтрацией. Парсить RSS через feedparser проще, чем SOAP, а для закупок, которые не попали в ленту, можно добавить HTML-парсинг карточек. Это грязнее REST, зато работает с нулевыми затратами и позволяет проверить гипотезу до того, как платить за подписку.
Один практический момент: коды ОКПД2 в разных источниках иногда указаны с точкой, иногда без, иногда с хвостом из нулей. Приведи их к единому виду на входе, иначе потом будешь дебажить пустую выдачу полчаса и не поймёшь почему.
Фильтрация и скоринг: как агент отбирает нужные тендеры
Поиск тендеров без фильтрации - это просто шум. На ЕИС ежедневно публикуются тысячи закупок, и задача агента не "найти всё", а выбросить нерелевантное до того, как человек потратит хоть минуту своего времени.
Я строю этот процесс в три прохода.
Первый проход: жёсткие фильтры. Здесь никакого AI нет. Обычные условия по коду ОКПД2, начальной максимальной цене контракта, региону поставки и типу процедуры (запрос котировок, электронный аукцион, конкурс). Это грубое сито убирает значительную часть потока. Если компания строит дороги в Поволжье и не работает с контрактами ниже 5 млн, то закупка канцелярии для школы в Мурманске не должна вообще попасть во второй проход.
Второй проход: LLM читает текст. До LLM доходит то, что прошло жёсткие фильтры. Модель читает название и краткое описание закупки, сравнивает с профилем компании и присваивает тег: высокая, средняя или низкая релевантность. Причину тоже нужно запрашивать явно. Без поля reason ты получаешь цифру, которой не можешь доверять.
Вот рабочий вариант функции:
import openai
import json
def score_tender(company_profile: str, tender_text: str) -> dict:
prompt = f"""
Профиль компании:
{company_profile}
Текст закупки:
{tender_text}
Оцени релевантность по шкале 0-100 и дай причину.
Ответ строго в JSON: {{"score": int, "reason": str, "risks": list}}
"""
resp = openai.chat.completions.create(
model='gpt-4o',
messages=[{'role': 'user', 'content': prompt}],
response_format={'type': 'json_object'}
)
return json.loads(resp.choices[0].message.content)
Профиль компании передаётся как строка: виды работ, регионы присутствия, ограничения по объёму контракта, субподрядные возможности. Чем конкретнее профиль, тем точнее скоринг. Если написать "строительные работы", модель будет путаться. Если написать "монтаж инженерных систем (ОВиК, ВК) в жилых и коммерческих зданиях, Самарская и Ульяновская области, НМЦ от 3 млн до 80 млн", точность резко вырастет. Похожая логика работает в промптах для AI-агента поддержки клиентов: чем точнее описан контекст в системном промпте, тем меньше галлюцинаций в продакшне.
Третий проход: скоринговая модель поверх LLM-оценки. Скор от GPT-4o учитывает только текст. Но у тебя есть история: у какого заказчика компания уже выигрывала, какова маржинальность конкретной категории работ, сколько дней осталось до подачи заявки. Я добавляю эти факторы отдельным весовым слоем поверх LLM-оценки. Простая линейная формула справляется: взвешенная сумма из LLM-скора, коэффициента заказчика и поправки на срок. Если заявку нужно подать через двое суток, а у компании нет готовых документов под этот тип закупки, итоговый скор падает автоматически.
Результат: из сотен закупок, которые прошли первый фильтр, агент передаёт менеджеру несколько десятков с оценкой и причиной по каждой. Менеджер смотрит только их. Это принципиальный момент: человек не исключается из процесса, он просто перестаёт тратить время на очевидный мусор.
Порог отсечения настраивается. Для компании, которая готова рисковать и хочет видеть больше вариантов, порог ставят на 50. Для компании с узкой специализацией и плотным загрузом производства - 75 или выше. Я рекомендую начинать с 60 и в первые две недели проверять вручную, что агент отбросил: это быстро покажет, не срезает ли модель нужное.
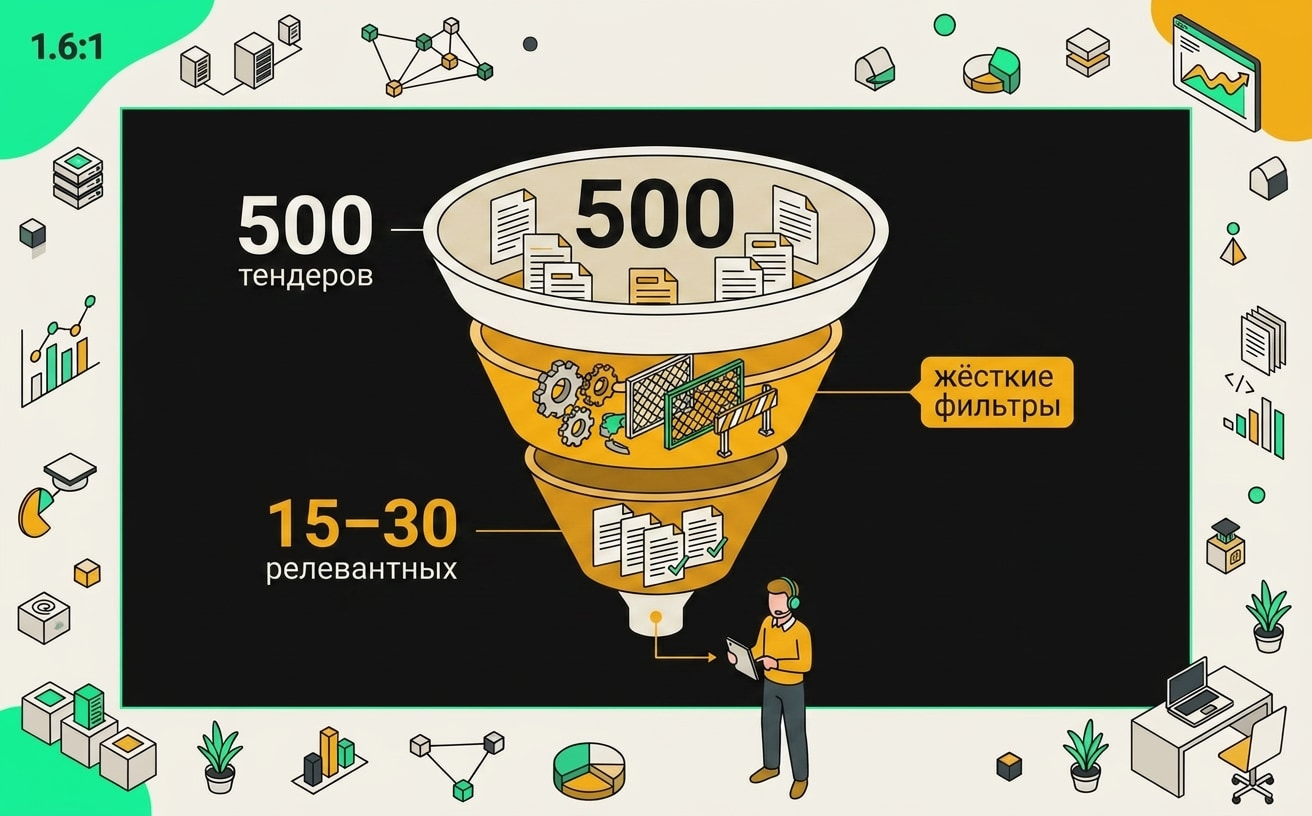
Трёхуровневая воронка отсеивает нерелевантные закупки последовательно: по ключевым словам, по параметрам контракта и по скоринговой оценке соответствия профилю компании.
Автоматическая подготовка заявки: что агент делает, а что оставляет человеку
Агент разбирает техническое задание не как текст для чтения, а как структурированный набор требований. Из 40-страничного ТЗ он выцепляет конкретику: технические характеристики товара или работы, сроки поставки, квалификационные критерии (опыт, лицензии, членство в СРО), и отдельно фиксирует ограничения по национальному режиму. Если заказчик установил запрет на иностранные товары по постановлению 616 или 878, агент помечает это явно, а не прячет в общий список.
Дальше начинается сборка черновика по шаблону компании. Стандартные разделы заполняются автоматически: реквизиты, сведения об опыте, данные о лицензиях. Агент обращается к базе документов и подтягивает нужные файлы. Не копирует вручную, а именно подставляет: выписку ЕГРЮЛ, действующие лицензии, сертификаты соответствия, если они есть в хранилище. По архитектуре это близко к тому, как устроен RAG-агент по корпоративной базе знаний: модель не держит документы в памяти, а извлекает их по запросу из векторного хранилища.
Параллельно LLM генерирует описание коммерческого предложения под конкретное ТЗ. Это не просто вставка стандартного текста компании. Модель адаптирует его под требования заказчика: если ТЗ про поставку медоборудования в бюджетное учреждение Сибири с монтажом и обучением персонала, описание будет именно про это, с нужными акцентами и терминологией из самого ТЗ.
Отдельная функция: проверка комплектности. Агент сверяет список обязательных документов по ТЗ с тем, что реально есть в базе. Если лицензия просрочена или выписка ЕГРЮЛ старше 30 дней, он сигнализирует. Специалист видит конкретный список недостающего, а не узнаёт об этом в последний день подачи.
Весь черновик готов за 15-20 минут. Без агента тот же объём работы занимает ощутимо больше: читаешь ТЗ, ищешь нужные документы по папкам, переписываешь описание, проверяешь комплектность вручную.
Но есть жёсткая граница. Финальную цену агент не ставит. Ценообразование остаётся за человеком: слишком много переменных, которые модель не видит (загрузка производства, договорённости с поставщиками, маржинальность по конкретному контрагенту). КЭП тоже подписывает только живой сотрудник с правом подписи. Спорные трактовки ТЗ агент помечает как неоднозначные, но не решает: если требование допускает два прочтения, это уходит на разбор к специалисту. Запросы разъяснений в адрес заказчика тоже пишет человек. Это уже позиция компании, а не техническая задача.
Специалист в итоге тратит 1-2 часа на проверку черновика, корректировку цены и финальный контроль. Не на рутину, а именно на те решения, которые требуют суждения.
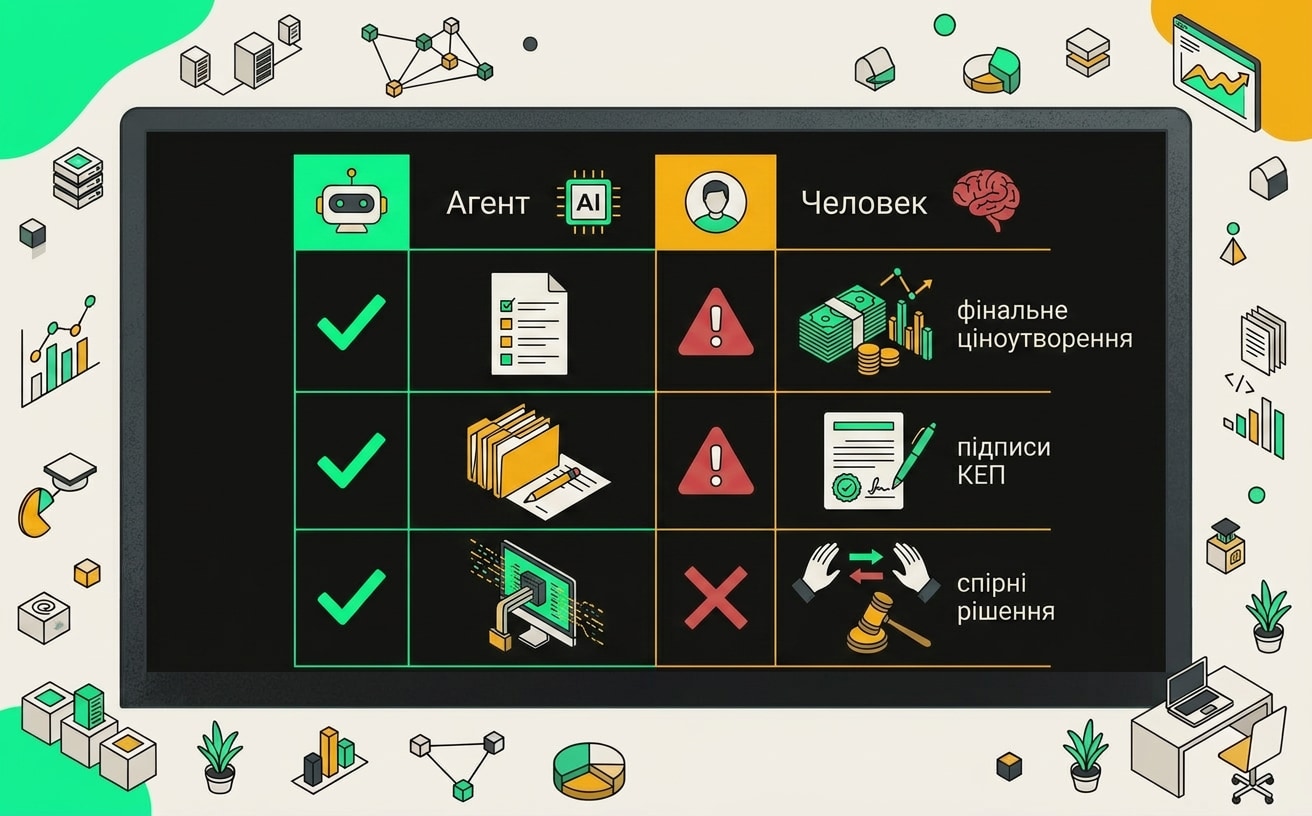
Агент берёт на себя рутинные операции: мониторинг, первичный анализ и черновики документов, оставляя специалисту финальные решения и коммуникацию с заказчиком.
Мониторинг изменений и дедлайнов: как агент держит отдел в курсе
Один из самых частых сценариев потери контракта выглядит так: заказчик публикует изменение в техническом задании на пятый день после размещения закупки, а менеджер замечает это за несколько часов до окончания подачи заявок. По 44-ФЗ заказчик обязан публиковать любые правки, включая изменение НМЦ, сроков или ТЗ, в ЕИС. Но "обязан публиковать" не означает, что кто-то в вашем отделе это увидит вовремя.
Агент решает это механически. Он подписывается на конкретный ID закупки и при любом изменении статуса или содержания немедленно пушит уведомление в Slack или Telegram. Не дайджест раз в сутки. Именно в момент, когда ЕИС фиксирует правку.
С дедлайнами работает отдельная логика. Агент вычисляет точное время до закрытия подачи заявок и отправляет напоминания за пять дней, два дня и за сутки. Три точки, не одна. Практика показывает, что напоминание за пять дней позволяет ещё скорректировать документацию, а за сутки уже только проверить, что всё отправлено.
После подачи агент переходит в режим трекинга. Он регулярно проверяет ЕИС на предмет публикации протоколов рассмотрения заявок и итоговых протоколов. Парсит их, извлекает статус вашей заявки: допущена, отклонена, победила. Если отклонена, фиксирует причину из протокола. Это убирает ситуацию, когда менеджер узнаёт об отклонении случайно или вообще не узнаёт.
Параллельно собирается информация о других участниках. Протоколы ЕИС содержат ИНН и наименования всех компаний, подавших заявки. По каждому конкуренту агент смотрит историю: в каких закупках этой категории они участвовали, какие цены предлагали, как часто побеждали. За несколько месяцев работы складывается реальный профиль соперника: кто демпингует, кто подаётся только на крупные лоты, у кого типичная ценовая тактика снижения на 3-5% от НМЦ.
Всё это пишется в CRM или Notion. По каждой закупке: полная история изменений, временные метки уведомлений, статус заявки, итог, данные конкурентов. Через полгода такой базы отдел перестаёт принимать решения по интуиции.
Технический стек для MVP: что собрать за разумные деньги
Начну с самого частого вопроса заказчиков: "сколько это стоит в инфраструктуре?" Для MVP ответ приятный. Недорогой VDS закрывает всё, кроме одного случая, о котором ниже.
Оркестратор. Беру Python с LangGraph. LangChain тоже работает, но LangGraph даёт явный граф состояний, и когда через три недели надо добавить ветку "тендер на переторжке, отправить на переоценку", это делается в одном месте без переписывания цепочки. Минимальная структура выглядит так:
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class TenderState(TypedDict):
raw_tenders: List[dict]
filtered: List[dict]
scored: List[dict]
drafts_created: int
def fetch_node(state: TenderState) -> TenderState:
# вызов API агрегатора
state['raw_tenders'] = fetch_from_api()
return state
def filter_node(state: TenderState) -> TenderState:
state['filtered'] = [t for t in state['raw_tenders']
if passes_hard_filters(t)]
return state
def score_node(state: TenderState) -> TenderState:
state['scored'] = [add_llm_score(t) for t in state['filtered']]
return state
graph = StateGraph(TenderState)
graph.add_node('fetch', fetch_node)
graph.add_node('filter', filter_node)
graph.add_node('score', score_node)
graph.set_entry_point('fetch')
graph.add_edge('fetch', 'filter')
graph.add_edge('filter', 'score')
graph.add_edge('score', END)
agent = graph.compile()
Три узла: забрать, отфильтровать по жёстким критериям (ОКВЭД, регион, NMC), проставить LLM-скор. В passes_hard_filters никакой нейросети нет, только SQL-подобная логика. LLM подключается только на этапе скоринга, и это принципиально для стоимости.
Кто хочет собрать похожий пайплайн без написания кода с нуля, может посмотреть на реализацию AI-агента на n8n: там аналогичная логика узлов собирается визуально, а интеграции с Telegram и CRM подключаются без программирования.
LLM. На старте берите GPT-4o через OpenAI API. Не потому что это дешевле, а потому что это быстрее проверить гипотезу. Реальные цифры по нагрузке зависят от объёма обрабатываемых тендеров и длины промптов. Если агент обрабатывает несколько сотен тендеров в день и на каждый уходит около 800 токенов (системный промпт + описание ТЗ + ответ), расходы на API остаются умеренными. Считайте под свою нагрузку по актуальному прайсу провайдера.
Когда объём вырастает до 5000+ тендеров или появляется несколько клиентов на одной инфраструктуре, считайте аренду GPU-сервера под Qwen2.5-72B. Aruba, Selectel или RunPod дают H100 от 2$/час. Для батч-обработки ночью модель поднимается, делает свою работу, сервер останавливается. Стоимость падает в 4-5 раз по сравнению с API.
Хранилище. PostgreSQL с tsvector закрывает 80% задач: полнотекстовый поиск по описаниям, фильтрация по статусу, история изменений. Если нужна аналитика, например BI по выигрышам за квартал или динамика NMC по категориям, добавляйте ClickHouse отдельным инстансом. Но не с первого дня. На MVP Postgres справляется с несколькими миллионами строк без проблем.
Планировщик. Для старта достаточно cron + простой Python-скрипт. Если нужны ретраи, мониторинг упавших задач и возможность запустить задачу вручную из интерфейса, берите Celery с Redis. Redis на том же VDS, отдельный контейнер. Это добавляет полдня настройки и даёт нормальную observability.
Уведомления. Telegram Bot API поднимается за два часа и работает надёжно. Если у заказчика уже стоит Bitrix24 или amoCRM, делайте webhook: тендер прошёл пороговый скор, событие летит в CRM, менеджеру ставится задача. Это не сложнее