

Что такое vibe coding и почему он перестал быть мемом к 2026
Андрей Карпатый в феврале 2025 года написал в X несколько абзацев о том, как он пишет код: «forget that the code even exists», просто описываешь задачу, принимаешь всё что предлагает модель, и только иногда смотришь что там вообще происходит. Пост разошёлся мгновенно. Половина сообщества начала смеяться, другая половина тихо начала так делать.
За год термин успел пройти полный цикл. Сначала мем, потом панический op-ed про «смерть разработки», потом спокойное признание того, что это просто новый режим работы. В 2026 vibe coding уже не надо объяснять на конференциях.
Базовая петля выглядит так: ты описываешь задачу на русском или английском, получаешь код, запускаешь, смотришь что сломалось, описываешь что сломалось, получаешь фикс. Повторяешь. Это не магия и не будущее. Это просто другой интерфейс к инструменту, где ввод идёт на человеческом языке, а не на Python сразу.
Но тут есть разрыв, который люди продолжают игнорировать.
Vibe coding хорошо работает для прототипа. Тебе нужен дашборд за выходные, скрипт для парсинга, MVP с тремя экранами. Модель тянет это уверенно. Продакшен-код это другая история: там нужен контроль над архитектурными решениями, понимание того почему именно так сделана авторизация, кто и как будет поддерживать это через восемь месяцев. AI-assisted development, в отличие от vibe coding, предполагает что ты читаешь что генерируется, споришь с этим, выбрасываешь куски и переспрашиваешь. Разница в уровне внимания и ответственности, не в наборе инструментов.
Один человек сегодня реально закрывает задачи, которые в 2022 году требовали пяти. Это не гипербола. Я видел соло-основателей с работающим SaaS, который три года назад потребовал бы команды с фронтендером, бэкендером и DevOps. Сейчас Claude или Gemini пишут шаблонный код быстрее чем джун, а разработчик фокусируется на том, что модель не вытащит из головы: бизнес-логику, специфику домена, решения с долгосрочными последствиями.
И всё-таки. Исследование SWE-bench Verified, которое гоняло топовые модели на реальных задачах из GitHub Issues, показывало около 25% ошибок на сложных случаях даже у лидирующих моделей конца 2025 года. Примерно каждый четвёртый нетривиальный баг модель не чинит или чинит с побочным эффектом. Это не повод не использовать инструмент. Это повод не закрывать глаза когда принимаешь diff.

Vibe coding превращает ноутбук и AI-агента в полноценную команду из одного человека.
Claude Code против Cursor: когда какой инструмент
Я держу оба инструмента открытыми параллельно. Это не лень и не дублирование, у них разные роли.
Claude Code живёт в терминале и работает как агент. Я говорю ему "разбери папку auth/, перепиши на новую схему JWT, прогони тесты, закоммить пачкой по логическим шагам", иду пить кофе, возвращаюсь через сорок минут, читаю diff. Он сам ходит по файлам, сам запускает pytest, сам видит падение и фиксит. Sonnet 4.5 я ставлю по умолчанию, на длинные автономные сессии (часовые рефакторинги, миграции схем БД) переключаю на Opus 4.1. Opus заметно лучше держит контекст на 200+ файлах и реже теряет нить через два часа работы.
Cursor у меня для другого. Открыт файл, я вижу функцию, жму Cmd+K, пишу "вынеси retry-логику в декоратор, оставь сигнатуру". Получаю инлайн-diff прямо в редакторе, принимаю или правлю по строчкам. Composer хорош, когда правка задевает 3-5 файлов и я хочу видеть каждое изменение до применения. Плюс навигация: Cmd+P по большому монорепо, переход к определению, поиск по символам, всё то, что в чистом терминале делать больно.
Грубое правило, которым я живу сейчас:
- Фича целиком, ясное ТЗ, не страшно отдать руль → Claude Code
- Точечная правка в открытом файле, рефакторинг функции, "сделай так же, но для другого случая" → Cursor
- Разобраться в незнакомом куске кода, прочитать, поспрашивать → Cursor с чатом по файлу
- Миграции, массовые переименования, генерация бойлерплейта по шаблону → Claude Code
Гибрид работает лучше всего. Claude Code пишет фичу скелетом: модели, роуты, тесты, миграция. Я открываю результат в Cursor и довожу руками те две функции, где агент перемудрил с абстракциями или неправильно понял доменную логику. На код-ревью самого себя уходит минут двадцать вместо часа писанины с нуля.
Деньги. Cursor Pro стоит $20 в месяц и включает щедрый лимит запросов, для большинства разработчиков этого хватает с запасом. Claude Code считается иначе: либо по API (платишь за токены, на активной неделе у меня выходит $80-150), либо через подписку Claude Max за $100 или $200, где Code входит в пакет с веб-чатом. Max за $200 окупается, если гоняешь агента ежедневно и часами, на API то же самое выходит дороже. Cursor дешевле и предсказуемее, Claude Code дороже, но за эти деньги ты получаешь часы своего времени обратно. Я плачу за оба и не вижу смысла выбирать.
Plan-then-Execute: двухфазный рабочий процесс
Сценарий «напиши мне фичу импорта из CSV» на проекте в 200 строк работает. На проекте в 20 000 строк он гарантированно провалится: агент придумает несуществующие модули, переизобретёт уже написанный парсер, сломает контракт сервиса, который дёргают три других места. Я через это прошёл столько раз, что в 2026-м просто не запускаю кодинг-сессию без отдельной фазы планирования.
Идея простая. Сначала исследование и план. Потом, в другой сессии, исполнение. Между ними ревью человеком.
Фаза 1: план без единой правки кода
В Claude Code я держу команду /plan, в Cursor для этого есть режим Ask (он не пишет в файлы по определению). Агент читает задачу, ходит по репозиторию, смотрит существующие модули, тесты, зависимости. И отвечает текстом, а не диффом.
Вот моя команда целиком:
# .claude/commands/plan.md
Прочитай задачу из $ARGUMENTS.
Изучи структуру проекта, не правя файлы.
Выдай:
1. Список файлов на изменение
2. Новые модули и их интерфейсы
3. Тесты, которые нужно добавить
4. Риски и неясности
Не пиши код. Жди подтверждения.
Результат сохраняю в PLAN.md в корне репо. Дальше я его читаю глазами, иногда минут двадцать. Правлю руками, добавляю «не трогай legacy/billing.py, там завязки на старого клиента», вычёркиваю придуманные миграции. Этот шаг нельзя пропускать. Если агент в плане ошибся на уровне архитектуры, в коде он ошибётся в десяти местах сразу.
Чек-лист, по которому проверяю PLAN.md
- Затронутые файлы перечислены поимённо, не «модуль авторизации»
- Новые зависимости названы с версиями. Если их больше двух, спрашиваю «зачем именно эти»
- Контракты API: какие эндпоинты или сигнатуры функций меняются, что ломается для вызывающих
- Тесты: что добавляется, что переписывается, какие сценарии покрыты
- Риски и неясности отдельным списком. Если этот список пустой, план плохой. На реальной задаче неясности всегда есть.
Фаза 2: исполнение по утверждённому плану
Новая сессия. Контекст: только PLAN.md и нужные файлы. Прошу делать по одному пункту за раз, с коммитом после каждого. Не «реализуй весь план», а «сделай шаг 1, покажи дифф, жди».
Почему так. У агента ограниченный контекст и склонность к импровизации. Когда план уже зафиксирован и одобрен, импровизировать не надо, надо переводить пункты в код. Это совсем другая задача, и она у моделей получается заметно лучше, чем гибридная «придумай и сразу сделай».
Побочный эффект приятный: PLAN.md остаётся в истории. Через месяц, когда я смотрю на странный кусок кода и не помню зачем, я открываю PR, нахожу план и вижу контекст решения. Архитектурная документация пишется сама собой, бесплатно.
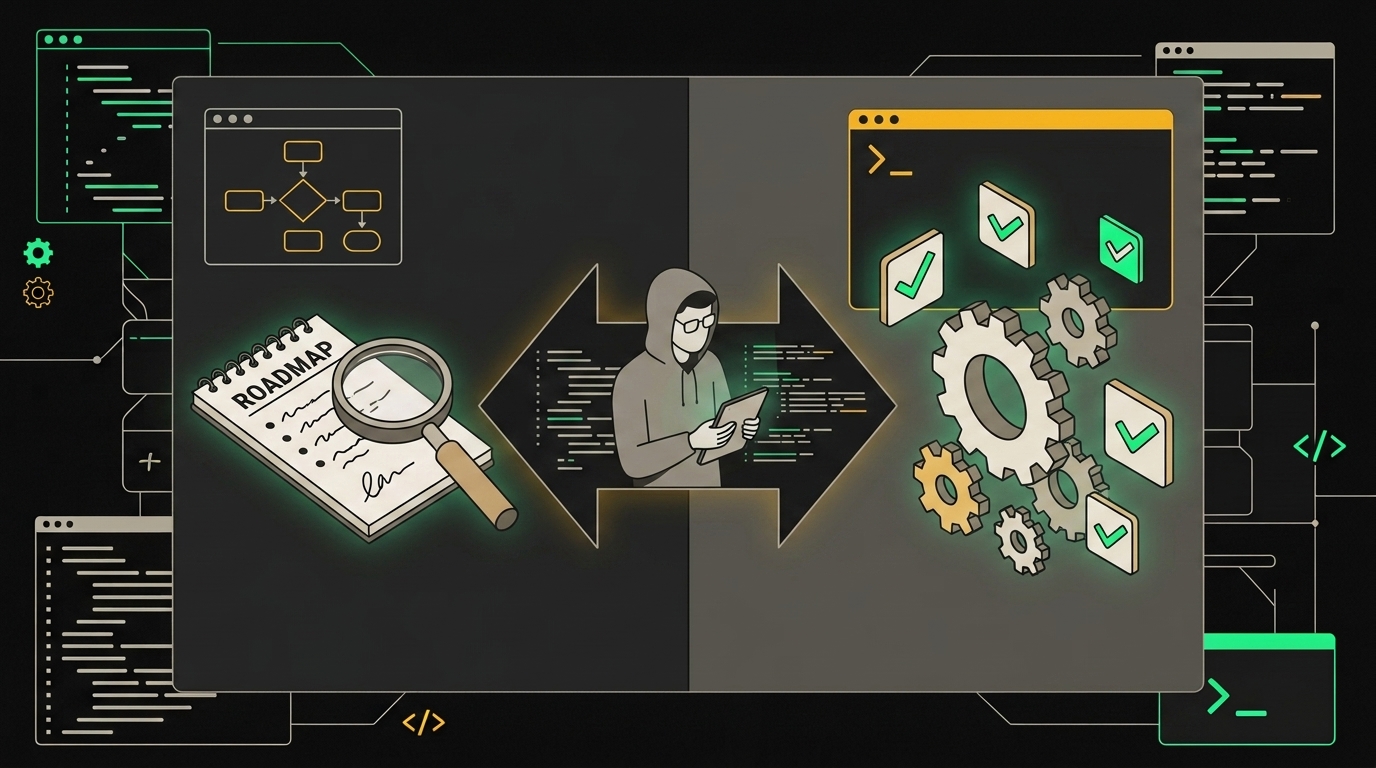
Сначала агент строит план и согласует его с разработчиком, только потом начинает писать код.
Управление контекстом: главный навык 2026 года
К весне 2026 я окончательно убедился: умение работать с контекстом отделяет тех, кто реально ускоряется с AI, от тех, кто бесконечно жалуется на "тупую модель". Модели стали умнее, окна выросли до сотен тысяч токенов, а качество ответов всё равно падает к середине дня. Причина банальна. Контекстное окно это рабочий стол, и если ты весь день кидал на него черновики, отменённые правки, три разных тикета и сценарий миграции БД, то к обеду на столе хаос. Модель видит этот хаос и галлюцинирует.
Первое, что я делаю в любом новом проекте: завожу CLAUDE.md (для Claude Code) или .cursorrules (для Cursor). Это постоянная память, которая подгружается в каждую сессию автоматически. Туда идёт стек, конвенции именования, какие библиотеки запрещены, как устроены слои приложения, где лежат миграции. Не художественное описание проекта на две страницы, а сухие факты, которые модель должна знать всегда. У меня типичный CLAUDE.md это 40-80 строк. Больше уже вредно, начинает заглушать сам запрос.
Второе правило: никаких "посмотри весь репозиторий". Это худшее, что можно сделать с контекстом. Я указываю файлы вручную через @-меншены: @src/services/billing.ts, @tests/billing.spec.ts, и всё. Если модели не хватит, она попросит. Просить будет конкретно, по имени, и это в десять раз дешевле и точнее, чем грузить дерево из 800 файлов "на всякий случай".
Третье, и тут многие спорят: /clear после каждой завершённой задачи. Закрыл тикет, смержил PR, починил баг, чисти контекст. Не работай четыре часа в одной сессии, перепрыгивая между задачами. Контекст загрязняется не линейно, а кумулятивно: модель начинает тянуть решения из предыдущей задачи в новую, путать имена, держаться за устаревшие предположения. Личное правило: если сессия идёт больше 40 минут и я чувствую, что окно забито, новая сессия. Без сожалений.
Для крупных задач в Claude Code я активно использую subagents. Условно, основная сессия пишет фичу, а параллельно subagent гоняет тесты, ещё один читает документацию API, третий ищет похожие паттерны в кодовой базе. Каждый из них работает в своём изолированном контексте и возвращает только результат. Главное окно остаётся чистым, без портянок логов и сырых файлов документации на 20 тысяч токенов.
Звучит как бюрократия, но по ощущениям за последние полгода это заметно улучшает долю ответов, которые я принимаю без переделки. Когда контекст чистый, модель попадает с первого раза. Когда замусорен, ты получаешь правдоподобный код, который не компилируется, и тратишь полчаса на разбор почему.
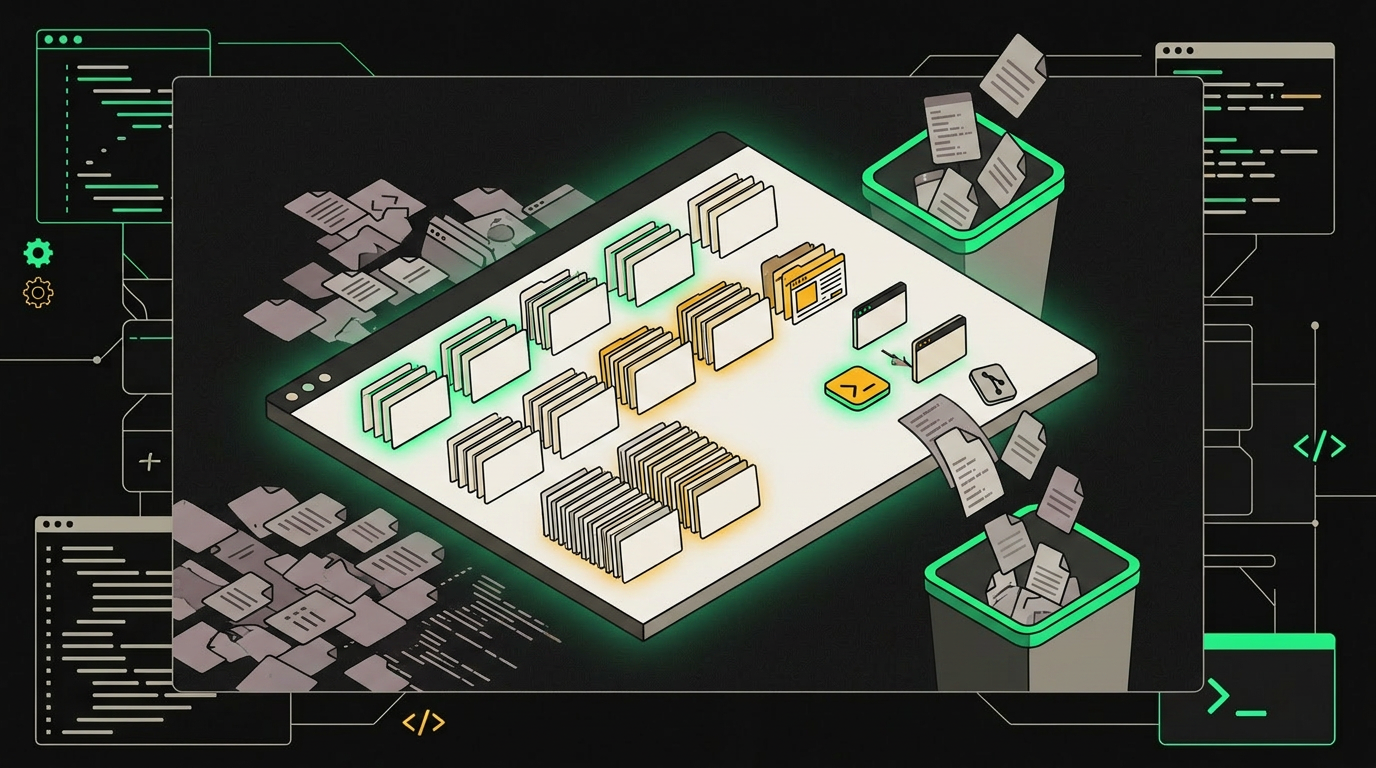
Контекстное окно работает как стол: полезные файлы под рукой, шум вынесен за его пределы.
TDD-петля для соло-разработчика
Когда я работаю один, без ревьюера и QA, тесты становятся моим единственным честным сигналом "оно работает или я себя обманываю". И с AI-агентом это правило усилилось десятикратно: модель умеет очень убедительно объяснять, почему её код правильный, а тесты на это не ведутся.
Петля у меня такая. Сначала спека, потом тесты от AI по этой спеке, потом реализация под зелёные тесты. Не наоборот. Если дать Claude или Codex написать сразу код, а тесты "потом", то тесты будут подгоняться под существующее поведение, включая баги. Я ловил это десятки раз.
Конкретная сессия в Claude Code выглядит примерно так:
# claude code session
> /plan добавь endpoint POST /api/orders с валидацией
> # после ревью плана
> сначала напиши tests/test_orders.py по плану
> запусти pytest, покажи что красные
> теперь реализуй src/orders.py до зелёных
Между шагами я реально читаю план и тесты. Не доверяю слепо. План занимает 30 секунд на просмотр, тесты минуту, и это окупается тем, что не приходится выкорчёвывать кривую архитектуру через два дня.
Почему это работает лучше, чем "напиши мне endpoint с валидацией"? Потому что тест это конкретный критерий успеха. assert response.status_code == 422 when email is missing модель не может интерпретировать креативно. А ТЗ "сделай нормальную валидацию" она интерпретирует как угодно, от регэкспа на email до полной интеграции с pydantic v2 со всеми custom validators, которые мне не нужны.
Тесты прогоняются после каждого изменения, не раз в день. У меня pytest-watch в одном терминале, агент в другом. Изменил файл, через секунду видно красное или зелёное. Если агент сделал три правки подряд без запуска тестов между ними, я его останавливаю и заставляю запустить. Иначе он накапливает дельту, в которой потом сам не может разобраться.
Pre-commit хуки обязательны. У меня минимум: ruff, mypy в strict режиме на изменённых файлах, и запрет коммитить файлы больше 500 строк без флага. Это не паранойя, это защита от того, что агент в азарте закоммитит # type: ignore на каждой второй строке или нагенерит файл на 2000 строк "утилит". Хук молча его остановит.
Для экспериментальных веток ставлю [skip ci] в commit message. GitHub Actions минуты на бесплатном тарифе кончаются быстро, если каждый эксперимент с промптом гонять через полный pipeline. CI запускается только когда я готов мерджить в main или открываю PR.
По личному опыту, TDD с агентом снижает количество продовых багов заметнее, чем любой другой приём, который я пробовал. Большая часть проблем, которые всё-таки вылезают в прод, появляется на стыках с внешними API, где тестами без моков всё равно не покрыть нормально.
Главное, чему я научился: TDD с агентом это не про дисциплину тестирования. Это про то, чтобы у модели был объект, с которым она спорит. Без тестов она спорит с тобой и почти всегда побеждает риторически. С тестами она спорит с pytest и проигрывает честно.
Долг понимания и как его не накопить
Модели хватает секунд, чтобы выдать сотни строк кода. Прочитать и осмыслить тот же объём нетривиального кода у человека уходит от двадцати минут и выше. Разница в скорости и есть та самая щель, через которую в проект протекает долг понимания. Технический долг я хотя бы вижу в линтере. А этот накапливается тихо.
Через три месяца открываешь файл, видишь класс EventDispatcher с приватной очередью на weak refs и хуком на GC, и не помнишь, почему так. Ты это не писал. Ты это принял в PR.
У меня одно жёсткое правило, без исключений: каждый PR от AI читается построчно перед мерджем. Не "просмотрел, тесты зелёные, влил". Построчно. Если поймал себя на том, что 15 минут смотрю в экран и не понимаю, что происходит в коде, который сам же и закоммитил неделю назад, это сигнал тревоги, а не нормальный режим работы. Это значит, я где-то смерджил то, что не понял.
Что помогает на практике:
- В промпте к Claude Code прошу не только написать код, но и объяснить ключевые решения в теле коммита. Не комментарии в коде (они быстро устаревают), а именно сообщение коммита: почему выбран такой подход, какие альтернативы рассматривались, что сломается при изменении. Через три месяца
git log -pотвечает на вопрос "зачем". ARCHITECTURE.mdобновляется в том же PR, где появляется новый модуль. Не "потом задокументируем". Задним числом архитектурные документы пишут только под аудит, и читаются они соответствующе.- Если модель предлагает паттерн, который я не узнаю с ходу, я останавливаюсь и прошу её показать минимальный пример того же паттерна вне моего проекта. Иногда выясняется, что паттерна нет, есть хайп-микс из двух разных идей.
Главный признак, что долг копится: вы перестаёте спорить с AI. Соглашаетесь с первым предложением, потому что разбираться долго, а закрыть тикет хочется сегодня. С этого момента кодовая база перестаёт быть вашей.
Автономный режим Claude Code: где это работает, где нет
Headless mode я использую с осени 2025 года. Сейчас, в мае 2026-го, у меня три типа ночных задач, которые агент тащит без меня: триаж входящих багов по шаблону (репро, минимальный пример, label), обновление зависимостей с прогоном тестов, и первичное ревью PR по чек-листу команды. Всё остальное либо живёт в дневном режиме под надзором, либо не пускается к Claude вообще.
Главное правило, которое я вывел за полгода эксплуатации: автономии можно доверять задачи с измеримым критерием успеха. Тесты позеленели или нет. Линтер прошёл или нет. PR соответствует чек-листу из 12 пунктов или нет. Когда критерий бинарный, агент работает предсказуемо. Когда критерий вкусовой ("сделай код красивее", "оптимизируй"), начинается дрейф: агент крутит файлы, переписывает то, что трогать не просили, и к утру ты разгребаешь diff на 4000 строк.
Чего я Claude в автономе не даю никогда:
- архитектурные решения уровня "выбери очередь сообщений" или "перепиши слой данных". Ошибка тут стоит недели, а агент уверенно сделает что угодно
- доступ к продовым секретам. Никаких
.env.production, никаких живых API-ключей в окружении агента. Только моки и dev-креды - миграции БД на чём-то кроме одноразовой dev-копии. Schema drift, который ты заметишь через две недели, отлаживать невозможно. Именно так Claude дописал SQL-миграцию и удалил продовую таблицу, когда никто не смотрел
- удаление файлов вне рабочей директории задачи
Песочница обязательна. У меня агент крутится в Docker-контейнере с примонтированным только тем репо, над которым работает, без сети наружу кроме whitelisted-хостов (npm registry, GitHub API). Dev-контейнер VS Code тоже годится. Пускать Claude Code прямо в хост-систему, особенно с правами на ~/, я считаю профессиональной халатностью. У агента бывают моменты, когда он решает "почистить кеши", и в хосте это заканчивается грустно.
Аудит. Каждое действие агента (вызов tool, запуск bash, edit файла) пишется в audit.log отдельным потоком, не в общий stdout задачи. Утром я открываю лог и за пять минут понимаю, что происходило в 3:47, когда тесты упали и агент решил откатить ветку. Без аудита автономный режим это чёрный ящик, и доверять ему нельзя.
Конкретный пример, который у меня бегает каждую ночь со среды на четверг. Контейнер поднимается в 02:00, дёргает свежий main, и запускает:
claude --headless \
--task "обнови зависимости npm, прогони тесты, откати если красные" \
--max-turns 30 \
--output-file night-run.log
Что происходит внутри: Claude делает npm outdated, поднимает minor и patch (major я запретил отдельной строкой в системном промпте), запускает npm test и npm run e2e, и если что-то красное, откатывает package.json и package-lock.json через git и пишет в лог конкретный пакет, на котором всё сломалось. Утром я вижу либо готовый PR с зелёными чеками, либо строчку "react-router-dom@7.2.1 ломает 14 e2e-тестов, откат выполнен". Лимит в 30 ходов я ставлю как предохранитель на случай, если агент зайдёт в цикл: безлимитные ночные прогоны при цикличном поведении могут нажечь неожиданный счёт.
За полгода такой схемы у меня было два инцидента. Один раз агент попытался обойти упавший snapshot-тест, обновив снапшот, что технически было решением задачи но не тем, что я хотел. Починилось добавлением в промпт строки "никогда не обновляй.snap файлы". Второй раз обновление esbuild прошло тесты, но сломало прод-сборку из-за другого таргета. С тех пор в ночной прогон добавлен npm run build:prod как отдельный gate.
Вывод по автономии простой. Это инструмент для рутины с зелёным/красным критерием, запертый в контейнере, с логом каждого шага. Всё, что выходит за этот периметр, я делаю с Claude интерактивно, глядя на экран.

Ночью агент разворачивается в изолированном контейнере и прогоняет весь цикл без участия человека.
Антипаттерны vibe coding, на которых горят соло-разработчики
Самая частая ловушка, в которую я сам залезал: промпт-снова-снова. Билд падает, ты копируешь ошибку, модель предлагает фикс, не помогает, ты пишешь "не работает, попробуй ещё", получаешь второй вариант, третий, седьмой. Через сорок минут код мутировал в трёх местах, а ты так и не прочитал, что говорит сам интерпретатор. Правило простое: если после двух итераций ошибка не ушла, закрой чат и сядь читать traceback глазами. Там почти всегда написана точная причина, просто на английском и с номером строки.
Кстати про traceback. Видел десятки скриншотов в чатиках, где человек кидает в Claude или GPT-5 простыню из стека и пишет "почини". Модель чинит верхний кадр, а реальная причина в третьем снизу, где вылезает KeyError из конфига, который ты сам же подсунул. Прочитай стек снизу вверх, найди свой код среди библиотечного, и только потом думай, нужна ли тут модель вообще.
Дальше идёт доверие на слово. Модель пишет "я обновил функцию, теперь всё работает корректно". Она не запускала тв



