
AI-агенты на n8n: собираем автономного ассистента для отдела продаж за выходные
Зачем отделу продаж AI-агент именно сейчас
Я смотрю на типичного SDR в 2026 году — и вижу человека, который половину рабочего дня занимается тем, что мог бы делать скрипт. Поиск компаний в LinkedIn, обогащение контактов через Clay или Apollo, копирование данных в CRM, первичная квалификация по BANT — всё это съедает от 40 до 50% времени. Не продажи. Логистика продаж.
Это уже не ощущение — это измеренные цифры. По данным ряда внедрений, команды, использующие AI-квалификацию лидов, сообщают о росте конверсии из лида во встречу и экономии времени на одного SDR. Для малого бизнеса с тремя менеджерами это как нанять четвёртого, только без зарплаты и онбординга. ROI зависит от конкретного внедрения и условий — «грамотного» — к нему вернусь.
Теперь про инструмент. Я пробовал строить агентов на Zapier и Make — оба упираются в одно и то же ограничение: они заточены под линейные сценарии «триггер → действие». Агент — это принципиально другое. Ему нужно автономно планировать шаги, вызывать инструменты в зависимости от контекста, держать память между сессиями. Zapier это не умеет архитектурно. Make умеет частично, но через такие костыли, что поддерживать невозможно.
n8n закрыл этот разрыв нативно — у него есть узлы LLM Agent и Tools, которые работают именно так, как должны работать агенты: модель сама решает, что вызвать следующим. Не случайно проект набрал больше 180 тысяч звёзд на GitHub и в 2025 году достиг оценки в миллиард долларов. Это не хайп — это сообщество, которое проверило инструмент на реальных задачах.
И последнее, что важно понять до того, как идти дальше: агент — это не кнопочный чат-бот с ветками if/else. Чат-бот отвечает по скрипту. Агент ставит цель, составляет план, вызывает нужные API, оценивает результат и корректирует следующий шаг. Это разница между калькулятором и аналитиком — один считает то, что ему сказали, другой понимает, что именно нужно посчитать.
 AI-powered sales managers consistently outperform manual workflows in speed, coverage, and cost per qualified lead.
AI-powered sales managers consistently outperform manual workflows in speed, coverage, and cost per qualified lead.
Что такое AI-агент в архитектуре n8n
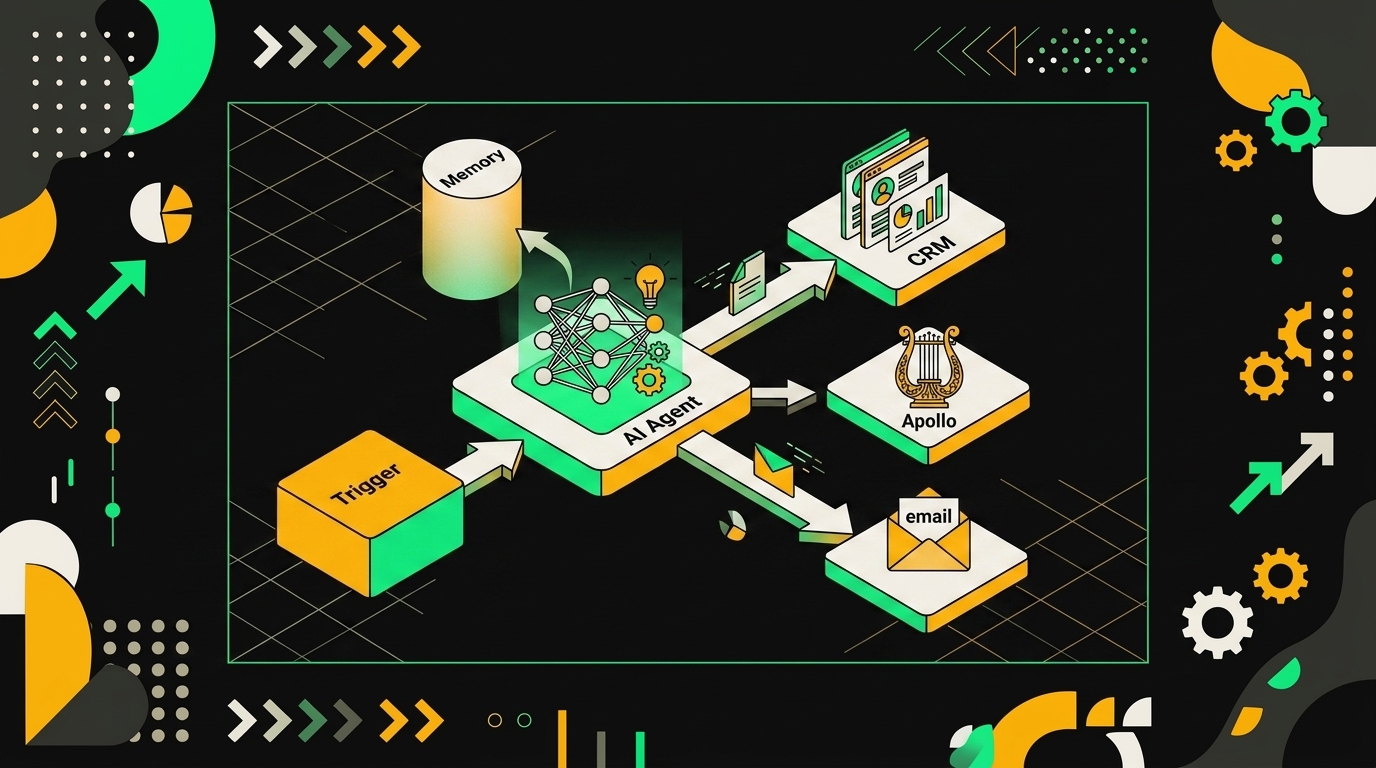
Если коротко: AI-агент в n8n — это workflow, где LLM получает доступ к инструментам, помнит контекст и запускается по событию. Не отдельный сервис, не магия — просто четыре компонента, собранные вместе.
LLM принимает решения. Tools — это то, что агент может делать: HTTP-запросы, SQL-запросы, отправка писем, поиск по векторной базе. Memory хранит контекст между сообщениями — через Vector Store или простой буфер последних N сообщений. Trigger определяет, когда всё это запускается: по расписанию, по вебхуку, по входящему сообщению в чат.
В интерфейсе n8n это выглядит как цепочка узлов. Chat Trigger принимает сообщение пользователя. Узел AI Agent передаёт его модели. Модель решает, какой инструмент вызвать — и вызывает HTTP Request, или лезет в Postgres, или достаёт релевантные чанки из Pinecone. Ответ возвращается обратно.
HTTP Request как универсальный tool — это важная деталь. Любой API, у которого есть endpoint, становится инструментом агента без кастомной интеграции. Написал описание функции, указал URL и параметры — готово.
Три типа агентов, которые есть в n8n прямо сейчас
Conversational — самый простой. Агент с памятью, который отвечает на сообщения. Подходит для поддержки, FAQ-ботов, внутренних ассистентов.
Tools Agent — основной рабочий режим. Модель получает список инструментов и сама решает, что и когда вызвать. OpenAI function calling, Anthropic tool use — всё это под капотом.
Plan-and-Execute — агент сначала строит план из шагов, потом выполняет их последовательно. Нужен для задач, где нельзя принять решение без предварительного анализа: «собери данные из трёх источников, сравни, напиши отчёт».
На практике в 2026 году большинство продакшн-агентов на n8n — это Tools Agent с кастомными инструментами и простой памятью на базе последних сообщений. Plan-and-Execute используют реже, он дороже по токенам и медленнее.
Self-hosted против n8n Cloud
Тут прямой ответ зависит от двух вещей: данные клиентов и экономика.
Если агент работает с персональными данными, медицинской информацией, финансовыми документами — self-hosted на Docker. Никаких вопросов. Данные не уходят за периметр, вы контролируете хранилище и логи.
Если строите что-то быстро, прототипируете, команда небольшая — n8n Cloud снимает головную боль с инфраструктурой. Но считайте: при серьёзной нагрузке (тысячи executions в день) self-hosted на VPS дешевле в два-три раза. Плюс латентность у self-hosted предсказуемее, если сервер в том же регионе, что и ваши API.
Почему n8n, а не Dify, Langflow или Just AI
Dify удобен для быстрого старта с RAG-пайплайнами, у него хороший UI для нетехнических пользователей. Langflow — Python-native, хорош для экспериментов с LangChain. Just AI ориентирован на NLU и корпоративные голосовые сценарии.
n8n выигрывает в одном: 400+ интеграций из коробки плюс произвольная логика workflow. Агент не живёт в изоляции — он часть процессов: получил данные из CRM, обработал, записал в базу, отправил уведомление в Slack, создал задачу в Jira. Всё в одном workflow, без клея из кастомного кода. Это не маркетинг — это реальное преимущество при построении операционных агентов, а не демо-чатботов.
 The n8n agent architecture connects triggers, memory stores, and external tools into a single orchestrated workflow.
The n8n agent architecture connects triggers, memory stores, and external tools into a single orchestrated workflow.
План на выходные: scope ассистента и распределение времени
Прежде чем браться за клавиатуру, я зафиксировал на бумаге одно правило: за выходные нельзя построить всё. Можно построить работающее ядро. Разница между этими двумя целями — разница между готовым инструментом в понедельник и кладбищем незаконченных веток в git.
Суббота, утро — 3 часа: фундамент
Первые три часа я трачу только на инфраструктуру. Регистрирую ключи API: OpenAI или Anthropic в зависимости от того, что дешевле на этой неделе для моего объёма токенов, плюс ключи для источников данных. Поднимаю первый workflow в n8n или LangGraph — зависит от того, нужна мне визуальная отладка или контроль над кодом. Цель этого блока одна: агент должен принять тестовый триггер и вернуть осмысленный ответ. «Hello agent» — не метафора, это буквально первый тест. Если к обеду субботы это не работает, дальше строить не на чём.
Суббота, день — 4 часа: данные о лидах и CRM
После обеда подключаю источник лидов. Чаще всего это Apollo.io — у него нормальный REST API и разумные лимиты на enrichment. Если нужен более глубокий профиль физлица, смотрю в сторону Pipl или Clay. Параллельно настраиваю запись в CRM: amoCRM если у клиента уже стоит, Битрикс24 если команда большая и процессы завязаны на его экосистему. Критерий готовности этого блока: агент находит лида по имени и домену, обогащает карточку и создаёт сделку в CRM без моего участия. Четырёх часов на это хватает, если не уходить в кастомизацию полей.
Воскресенье, утро — 3 часа: мозг квалификации
Воскресное утро — самая интеллектуально насыщенная часть. Здесь я пишу логику квалификации. BANT как базовый фрейм, MEDDIC если продукт сложный и цикл сделки длинный. Промпты пишу итеративно: первая версия всегда слишком многословна, третья — обычно рабочая. Сюда же встраиваю RAG: загружаю продуктовую документацию, прайсы, описания кейсов в векторное хранилище. Цель — агент должен отвечать на вопрос «подходит ли этот лид» не абстрактно, а опираясь на конкретные данные о продукте. Без RAG квалификация будет галлюцинировать.
Воскресенье, день — 4 часа: каналы, тесты, метрики
Последний блок — выход агента в реальные каналы. Telegram проще всего через Bot API, WhatsApp — через официальный Cloud API или WABA-партнёра, email — через SendGrid или SMTP с нормальными SPF/DKIM записями. После подключения каналов прогоняю сквозные тесты: лид входит через один канал, агент квалифицирует, пишет ответ, обновляет CRM. Последний час воскресенья — метрики. Минимальный набор: время от триггера до первого ответа, процент лидов, прошедших квалификацию, количество ошибок API.
Что я осознанно не делаю за эти два дня
Голосовые боты — нет. Это отдельная инфраструктура, отдельная модель латентности, отдельные дни работы. Fine-tuning — нет: у меня нет размеченного датасета нужного объёма, а без него fine-tuning только сломает модель. Сложный multi-agent оркестр с несколькими специализированными агентами, планировщиком и памятью между сессиями — тоже нет. Это красиво на схемах и дорого в отладке. За выходные я строю одного агента, который делает одну вещь хорошо. Этого достаточно, чтобы в понедельник показать результат.
 A structured two-day sprint breaks the agent build into focused blocks so you ship a working prototype by Sunday evening.
A structured two-day sprint breaks the agent build into focused blocks so you ship a working prototype by Sunday evening.
Шаг 1. Поднимаем n8n и подключаем LLM
Начинаю с инфраструктуры. Локальный SQLite в n8n годится для демо, но как только появляются параллельные воркфлоу с LLM-вызовами и вебхуками от CRM, он становится бутылочным горлышком. Поэтому сразу разворачиваю связку Postgres + Redis + n8n в режиме очередей. Postgres держит состояние и историю выполнений, Redis — очередь задач для воркеров через Bull.
Минимальный docker-compose.yml, с которого начинаю любой проект:
version: '3.8'
services:
n8n:
image: n8nio/n8n:latest
ports:
- '5678:5678'
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- N8N_ENCRYPTION_KEY=${N8N_KEY}
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
volumes:
- n8n_data:/home/node/.n8n
depends_on: [postgres, redis]
postgres:
image: postgres:16
environment:
POSTGRES_DB: n8n
POSTGRES_USER: n8n
POSTGRES_PASSWORD: ${PG_PASS}
redis:
image: redis:7-alpine
volumes:
n8n_data:
Под прод этого мало — нужен ещё хотя бы один сервис-воркер с тем же образом и командой n8n worker, но для первого прохода хватит.
Переменные окружения, на которых не стоит экономить
N8N_ENCRYPTION_KEY— генерирую черезopenssl rand -hex 32и кладу в.env. Если потеряете ключ после того, как сохранили credentials, восстановить их будет невозможно. Бэкаплю отдельно от БД.N8H_HOSTиWEBHOOK_URL— указывают на публичный домен. Без корректногоWEBHOOK_URLвходящие вебхуки от CRM будут указывать наlocalhost.N8N_PROTOCOL=https— даже если TLS терминируется снаружи, иначе n8n генерит http-ссылки.
Наружу пробрасываю через Cloudflare Tunnel — не нужно открывать порты, и сразу получаю DDoS-защиту и валидный TLS:
cloudflared tunnel create n8n-sdr
cloudflared tunnel route dns n8n-sdr n8n.mycompany.ru
cloudflared tunnel run --url http://localhost:5678 n8n-sdr
После этого в .env ставлю WEBHOOK_URL=https://n8n.mycompany.ru/ и перезапускаю стек.
Подключаем LLM
В разделе Credentials добавляю провайдеров, которые буду дёргать из узлов AI Agent. Для SDR-ассистента я обычно держу два контура: внешний (OpenAI или Anthropic — что-то из линейки Claude Sonnet 4.5 или GPT-5.1, в зависимости от того, на чём лучше идёт русский язык в конкретной задаче) и российский (YandexGPT 5 Pro или GigaChat 2 Max) — на случай, если данные клиента нельзя гнать за периметр РФ.
Что важно при настройке:
- OpenAI / Anthropic — кроме API-ключа задаю Base URL, если ходим через корпоративный прокси.
- YandexGPT — credential просит
folder_idи IAM-токен; токен живёт 12 часов, поэтому в проде использую сервисный аккаунт с автообновлением через отдельный n8n-воркфлоу. - GigaChat — OAuth по
client_id/client_secret, областьGIGACHAT_API_CORPдля корпоративных тарифов.
Первый AI Agent
Создаю новый workflow, кидаю узел Chat Trigger (он же даёт встроенный чат для тестов прямо в UI), за ним — AI Agent в режиме Conversational Agent. В качестве модели подключаю одну из credentials выше, в Memory — Window Buffer на 10 сообщений, чтобы агент держал контекст диалога.
Системный промпт делаю максимально приземлённым, без «ты — лучший в мире AI»:
Ты — SDR-ассистент компании X. Компания продаёт <одно предложение про продукт>.
Твоя задача: квалифицировать входящего лида по BANT, отвечать на типовые
возражения и предлагать слот для звонка с менеджером.
Правила:
- Отвечай по-русски, короткими абзацами, без маркетингового шума.
- Если не знаешь ответ — честно говори и предлагай связать с человеком.
- Не обещай скидок и сроков, которых нет в базе знаний.
Дальше открываю встроенный чат (кнопка Chat у Chat Trigger), пишу что-то вроде «Привет, расскажите про ваш продукт и сколько он стоит» и смотрю на ответ. На этом этапе у агента ещё нет ни базы знаний, ни инструментов — он просто отрабатывает на знаниях модели и системном промпте. Это нужно, чтобы убедиться: связка n8n ↔ LLM-провайдер ↔ Cloudflare работает, токены не протухают, кириллица не превращается в ???.
Когда диалог в чате осмысленно идёт — переходим к следующему шагу и подцепляем агенту инструменты: поиск по базе знаний, работу с CRM и календарём.
 Running n8n in Docker gives you a portable, reproducible environment to build and test your first agent in minutes.
Running n8n in Docker gives you a portable, reproducible environment to build and test your first agent in minutes.
Шаг 2. Источники лидов: Apollo.io, Clay, Pipl как инструменты агента
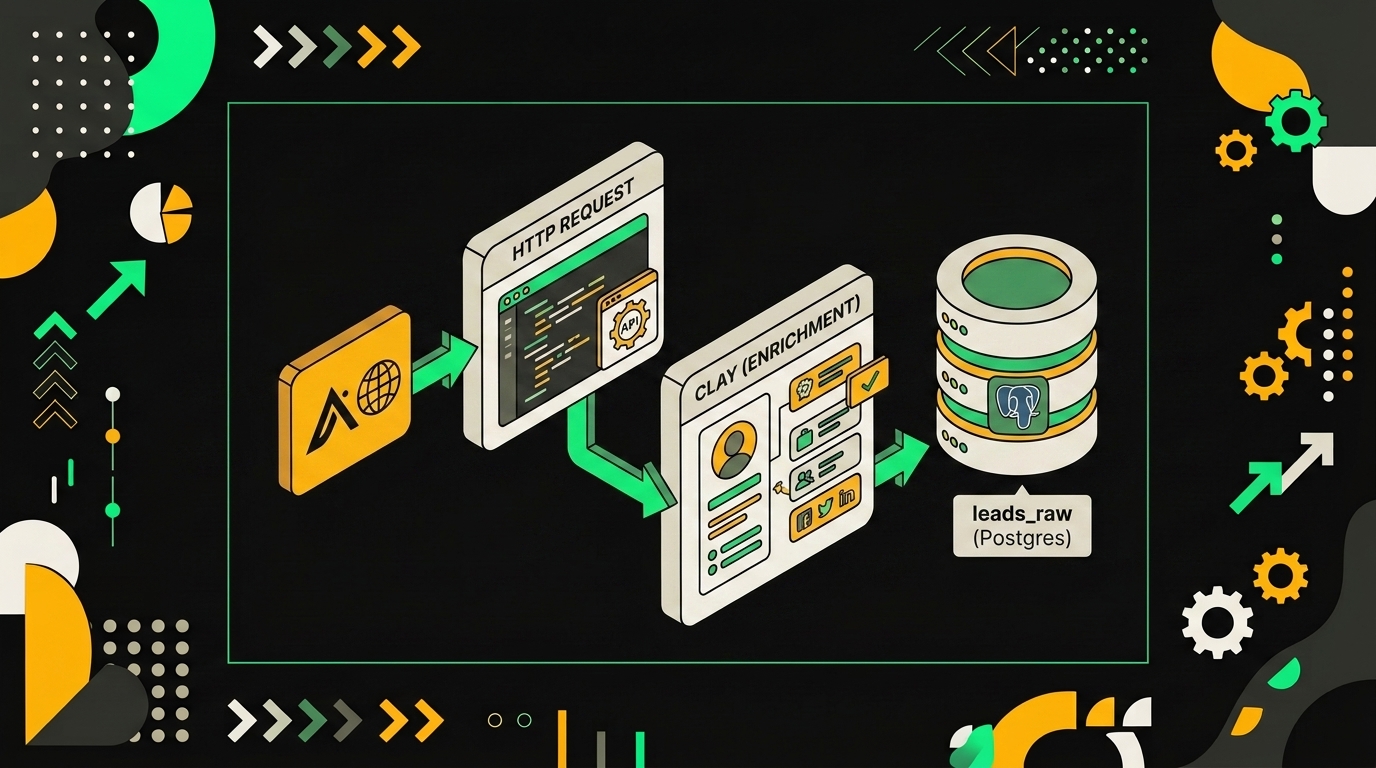
Дальше я подключаю агенту руки — три источника, каждый под свою задачу. Apollo.io даёт основной поток B2B-контактов, Clay добивает холодные данные из 100+ внешних источников, Pipl ловит фрод и левые личности. Ни один из них не вызывается агентом напрямую — между ними и LLM лежат HTTP Request узлы, обёрнутые в Tools с человеческими описаниями. Так агент сам решает, когда нужен поиск, когда обогащение, а когда фрод-чек.
Apollo.io: базовый поток
Уточните актуальные условия доступа к API в документации Apollo.io — тарифная сетка периодически меняется, и доступность API зависит от выбранного плана.
Я оборачиваю Apollo Search API в HTTP Request узел и отдаю агенту как инструмент:
// Tool description для AI Agent
{
"name": "search_leads_apollo",
"description": "Поиск B2B-контактов по должности, индустрии, размеру компании. Возвращает имя, email, LinkedIn, компанию.",
"parameters": {
"job_titles": ["string"],
"industries": ["string"],
"company_size": "string",
"limit": "number (max 25)"
}
}
Описание короткое и без воды — LLM-у не нужен мануал, ему нужно понимать, когда дёргать тулзу. limit: max 25 стоит не случайно: Apollo пагинирует по 25 контактов на страницу, и если попросить больше — получите ошибку либо тихую обрезку. При активной пагинации учитывайте дневные лимиты вашего тарифа — при их превышении начинаются троттлинги и предупреждения от службы аккаунтов.
Clay: обогащение того, что Apollo не знает
Apollo силён по US/EU SaaS-сегменту, но проседает на менее засвеченных рынках и редких ролях. Clay подключаю вторым тулом — enrich_contact_clay. Он принимает email или LinkedIn URL и возвращает технографику, последние посты, события компании, иногда личный телефон. Полезно для холодных контактов, по которым Apollo вернул только имя и должность.
Pipl: фрод-чек
Pipl я ставлю не для обогащения, а для проверки. Когда лид приходит из формы или из спорного источника, агент дёргает verify_identity_pipl — и я смотрю, существует ли реальный человек за этим email и телефоном, нет ли расхождений между именем и публичными профилями. По моему опыту это позволяет заметно сократить количество мусорных лидов ещё до того, как они попадут в CRM и съедят время сейлзов.
Postgres как буфер перед CRM
Все три источника пишут не сразу в CRM, а в leads_raw в Postgres. Структура минимальная: source, external_id, email_normalized, phone_e164, payload jsonb, fetched_at. Перед вставкой — нормализация (email в lowercase, телефон в E.164) и дедупликация по уникальному индексу (email_normalized, source). На уровне ETL дополнительно мержу одного человека из разных источников по email.
Это даёт две вещи. Первая — агент может несколько раз за день дёргать Apollo с пересекающимися фильтрами и не дублировать контакты в HubSpot. Вторая — у меня есть сырые ответы API в payload jsonb, и если завтра я поменяю логику обогащения, могу прогнать всё заново без новых вызовов и без расхода кредитов.
 Piping Apollo prospects through Clay automatically fills in firmographic and contact details before any outreach begins.
Piping Apollo prospects through Clay automatically fills in firmographic and contact details before any outreach begins.
Шаг 3. Интеграция с CRM: amoCRM и Битрикс24
CRM — это место, где агент становится полезным бизнесу, а не просто красивым демо. Здесь важно не сломать прод и не упереться в лимиты, поэтому начинаем с инфраструктуры, а не с креатива.
Лимиты и rate limiter
У amoCRM два уровня ограничений: 7 запросов в секунду на интеграцию и 50 запросов в секунду на аккаунт. Если у вас один агент дёргает API в цикле по списку компаний — вы упрётесь в первый порог почти мгновенно. Я закладываю rate limiter сразу, не дожидаясь 429.
В n8n это удобно делать через узел Loop Over Items с задержкой 150 мс между батчами по 1 элементу — получается ~6 rps с запасом. Для более высоких нагрузок беру очередь Redis и воркер, который вычитывает её с фиксированным темпом. Не полагайтесь на retry с backoff в самом HTTP Request — он спасает от случайных всплесков, но не от системной перегрузки.
OAuth2 и refresh token
Авторизация — через n8n Credentials, тип OAuth2 API. Один раз настраиваете client_id, client_secret, redirect_uri из настроек интеграции в amoCRM, и n8n хранит токены сам. Access token живёт 24 часа, refresh — 3 месяца. n8n обновляет access автоматически при истечении, но я завёл отдельный workflow по cron раз в сутки, который дёргает дешёвый эндпоинт /api/v4/account — это и health-check, и страховка от ситуации, когда refresh уже протух, а вы об этом узнаёте в пятницу вечером.
Создание сделок: маппинг через агента
Самое интересное — как агент сам решает, что класть в поля. Я не хардкожу маппинг в коде, а отдаю агенту JSON-схему карточки сделки и прошу заполнить её на основе диалога:
{
"name": "string, название компании клиента",
"price": "number, оценка сделки в рублях",
"responsible_user_id": "integer, ID менеджера",
"custom_fields_values": [
{ "field_id": 123456, "type": "email" },
{ "field_id": 123457, "type": "phone" }
]
}
Агент возвращает заполненный JSON, я валидирую его через Code ноду (минимум: проверка обязательных полей и типов) и только потом отправляю в amoCRM:
// HTTP Request → amoCRM создание лида с rate limit
POST https://{subdomain}.amocrm.ru/api/v4/leads
Headers: Authorization: Bearer {{ $credentials.amocrm.access_token }}
Body: [{
"name": "{{ $json.company }}",
"price": {{ $json.estimated_value }},
"custom_fields_values": [
{ "field_id": 123456, "values": [{ "value": "{{ $json.email }}" }] }
]
}]
Обратите внимание: тело — массив, даже если лид один. Это та грабля, на которую все наступают в первый раз. Ответ тоже массив — _embedded.leads[0].id сохраняем для последующих апдейтов.
Битрикс24 как альтернатива
Если клиент сидит на Битриксе — логика та же, но API другое. REST через webhook-токены проще в настройке, чем OAuth: получили входящий вебхук с правами crm, дёргаем crm.lead.add.json, crm.deal.update.json и так далее. Лимиты мягче — 2 запроса в секунду на пользователя, но конкуренция за них в больших порталах жёсткая, так что rate limiter всё равно нужен.
Входящие события (новый лид с сайта, смена стадии) ловлю через исходящие вебхуки Битрикса в n8n Webhook-ноду — это даёт агенту реактивность без поллинга.
Двусторонняя синхронизация
Это та часть, где обычно начинается боль. Договариваемся о направлениях явно:
- CRM → агент: при старте диалога подтягиваю стадию сделки, последние примечания и кастомные поля. Это контекст, без него агент будет здороваться с клиентом, который уже три недели в работе.
- Агент → CRM: каждое значимое действие пишется примечанием в карточку (
/api/v4/leads/{id}/notes), смена стадии — отдельным PATCH. Никаких «тихих» апдейтов: менеджер должен видеть, что делал бот.
И обязательный флаг created_by или кастомное поле «источник записи» со значением ai_agent — чтобы потом можно было отфильтровать действия агента в аналитике и при разборе инцидентов. Поверьте, через месяц это сэкономит вам пару часов разговоров с РОПом.
Шаг 4. Квалификация лидов: промпты, RAG и сценарии BANT
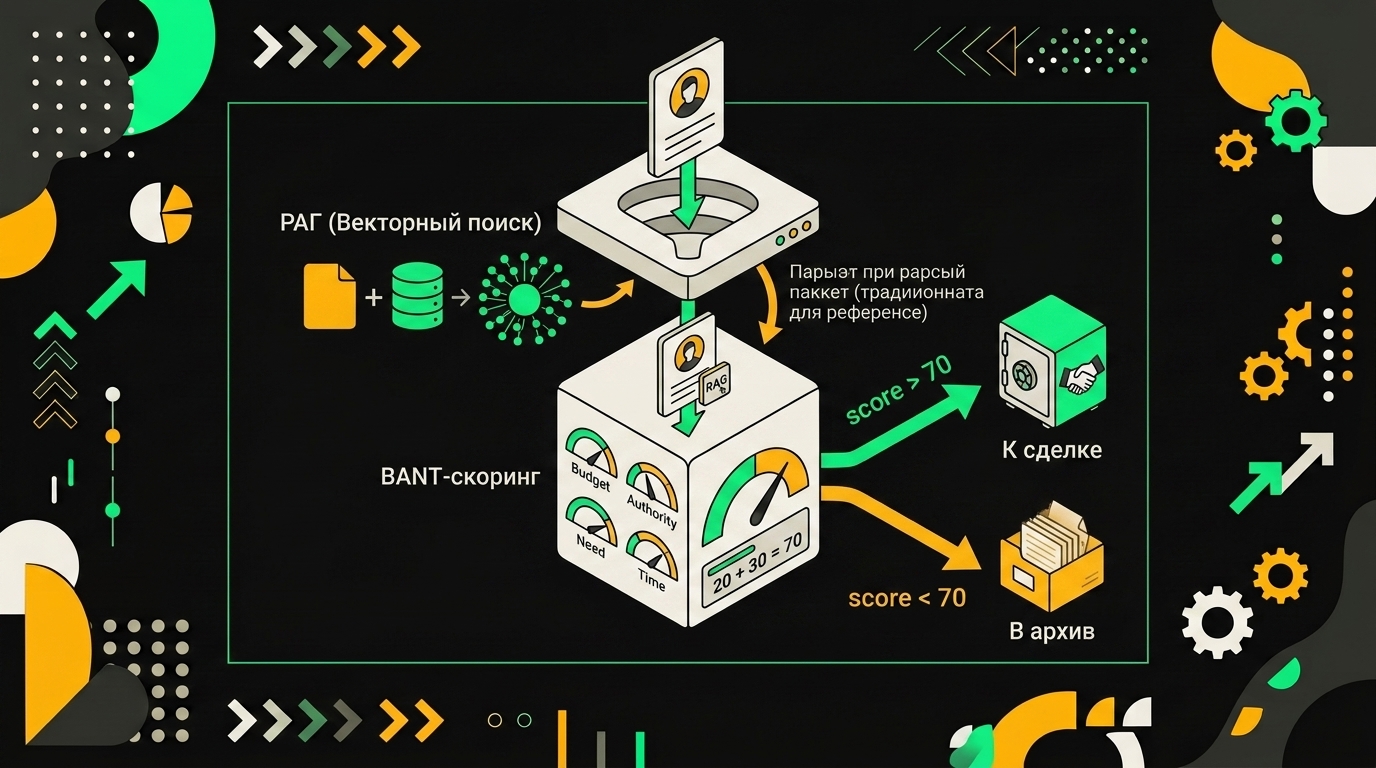
После обогащения у меня на руках сырой профиль: компания, должность, индустрия, размер, иногда — последние новости. Дальше его надо превратить в число от 0 до 100 и одно из трёх решений: гнать в сделку, греть дальше или закрыть. Этим занимается отдельный узел LLM с жёстким контрактом на выход.
Системный промпт
Я держу его коротким: роль, что считать, что вернуть. Никакой воды про «будь полезным ассистентом» — модель и так справится, а лишние инструкции размывают фокус.
Ты — SDR-ассистент. На входе данные о лиде. Оцени по
*Layering RAG-based scoring onto the BANT framework lets the agent prioritize only the leads most likely to convert.*