
Bitrix24 и HubSpot в одной воронке: гибридная CRM-связка для международных команд
Зачем международным командам гибридная связка Bitrix24 + HubSpot
В 2026 году у любой компании с командами в СНГ и одновременно в ЕС или Северной Америке есть структурная проблема: ни одна CRM не закрывает весь периметр одновременно без болезненных компромиссов. Bitrix24 широко используется для операционной работы в России, Казахстане, Беларуси, Узбекистане. HubSpot — то, на чём сидит маркетинг в Берлине, Бостоне, Боготе и Сингапуре. Пытаться перевезти всех на одну платформу — значит либо объяснять немецкой команде, зачем им интерфейс с русскоязычной поддержкой, либо просить ташкентский офис платить в долларах за инструмент, который в их юрисдикции работает медленно и стоит несоразмерно.
Поэтому не «переезд», а интеграция — это рациональное решение, а не временный костыль.
Разделение по функциям здесь важнее, чем разделение по географии. Bitrix24 хорошо держит операционный слой: телефония с записью звонков, задачи и проекты, складской учёт, документооборот с электронными подписями, сквозные бизнес-процессы. Всё это — зона, где HubSpot либо слабее, либо требует дорогих сторонних интеграций. HubSpot, в свою очередь, выигрывает там, где нужна серьёзная маркетинговая механика: email sequences с поведенческими триггерами, ABM-кампании с тиром аккаунтов, атрибуция по нескольким касаниям, детальная аналитика воронки с когортами. Это не дублирующие системы — это разные уровни одного процесса.
Типовых сценария связки два, и оба рабочие. Первый: глобальный маркетинг живёт полностью в HubSpot — лидогенерация, nurturing, скоринг — а когда лид достигает порога SQL, он автоматически передаётся в Bitrix24, где начинается продажа, выставление счёта, фулфилмент и постпродажное сопровождение. Второй сценарий: жёсткое региональное разделение, где СНГ-рынок ведётся целиком в Bitrix24, а всё остальное — в HubSpot, и оба потока сходятся в единый дашборд отчётности через промежуточный слой данных. Оба варианта решают главную боль — дублирование лидов и потерю SLA первого касания, когда лид «провисает» между системами.
Есть и экономический аргумент. Лицензирование по ролям при гибридной модели реально снижает TCO: продавцы в Алматы не платят за маркетинговый хаб HubSpot, а маркетолог в Амстердаме не занимает место в Bitrix24 Enterprise. Каждый платит за то, чем пользуется.
Наконец, существует аргумент compliance, который в 2026 году стал ещё весомее. Для ряда компаний полный переезд в одну систему — не техническая, а юридическая проблема: локализация данных, требования регуляторов, санкционные ограничения на использование американского ПО в определённых контекстах. Гибридная архитектура здесь — не архитектурная слабость, а осознанная позиция.
 A global map illustrating how two separate CRM platforms serve different regional markets while sharing critical customer data across borders.
A global map illustrating how two separate CRM platforms serve different regional markets while sharing critical customer data across borders.
Архитектура связки: master-slave, dual-write или event-driven
Когда я проектирую интеграцию HubSpot ↔ Bitrix24, первый вопрос, который задаю команде: кто из вас источник истины и для чего? От ответа зависит вся остальная архитектура, и попытка увильнуть («ну пусть синхронизируются в обе стороны») всегда заканчивается тем, что через полгода менеджеры жалуются на дубли контактов и пропавшие комментарии к сделкам.
Master-slave: скучно, но работает
Самый простой и самый недооценённый паттерн. Делите сущности по доменной ответственности:
- HubSpot — мастер для контактов, компаний и сделок верхнего уровня (lifecycle stage, lead score, маркетинговые атрибуты, владелец сделки на стратегическом уровне).
- Bitrix24 — мастер для операционных стадий: воронка продаж, задачи, звонки, чек-листы, всё, что менеджер трогает руками каждый день.
Поля, которые принадлежат мастеру, в slave-системе read-only — либо технически (через права), либо организационно (договорённость + алерт при расхождении). Конфликт «кто победил» решается заранее, а не в момент инцидента.
Хорошо подходит для небольших команд. По мере роста начинаются гонки записей и хочется чего-то посерьёзнее.
Dual-write через middleware
n8n, Make, Workato или собственный сервис на Node.js/Python, который слушает вебхуки с обеих сторон и перекидывает изменения. Соблазнительно: быстро поднимается, гибко мапится, видно в UI.
Чем убивает на проде:
- Циклы записи. Изменили контакт в HubSpot → улетело в Bitrix24 → Bitrix24 кинул вебхук об обновлении → middleware пишет обратно в HubSpot → новый вебхук. Без флага «это техническая запись» или дедупликации по хешу полей вы получите бесконечный пинг-понг и rate limit.
- Отсутствие идемпотентности. Make ретраит упавший шаг — и вы создаёте две сделки вместо одной, потому что не проверили external_id перед
POST /deals. Любая операция записи должна быть upsert по внешнему ключу, а не слепой create. - Порядок событий. Вебхуки не гарантируют порядок. Если апдейт стадии пришёл раньше создания сделки, middleware должен либо ждать, либо явно обработать out-of-order.
Если идёте этим путём — обязательны: idempotency key на каждой операции, дедуп по hash(payload), отдельная таблица операций с retry/DLQ, и фильтр «не реагировать на собственные записи» (обычно по полю last_modified_by = integration_user).
Event-driven через очереди
Для крупных команд я рекомендую только это. RabbitMQ, Kafka, AWS EventBridge или Google Pub/Sub — выбор зависит от того, что уже есть в инфраструктуре. Архитектура:
HubSpot webhook ─┐
├──► Ingest service ──► Queue (topic per entity) ──► Workers ──► Bitrix24 API
Bitrix24 webhook ┘ └──► HubSpot API
Что это даёт:
- Декомпозиция. Приём событий не зависит от доступности целевой системы. Bitrix24 отвалился на 20 минут — события копятся в очереди, потом разгребаются.
- Идемпотентность естественна. Каждое событие имеет
event_id, воркер делает upsert. Двойная доставка безопасна. - Партиционирование по entity_id (особенно в Kafka) гарантирует порядок изменений для одного контакта.
- Наблюдаемость. DLQ, метрики лагов, retry с экспоненциальным бэкоффом — из коробки.
Минус один: команда должна уметь это эксплуатировать. Если у вас нет дежурного, который понимает Kafka, лучше возьмите managed-решение (EventBridge, Confluent Cloud) или останьтесь на dual-write.
Маппинг сущностей
Базовое соответствие, от которого я обычно стартую:
| HubSpot | Bitrix24 |
|---|---|
| Contact | Контакт |
| Company | Компания |
| Deal | Сделка |
| Ticket | Лид / Обращение |
Тонкость: Ticket в HubSpot и Лид в Bitrix24 — не один к одному. Лид в Bitrix24 это пред-сделочная сущность, Ticket — постпродажный сервис. Если у вас сервисный отдел в HubSpot Service Hub, а первичная квалификация — в Bitrix24, маппьте Ticket на отдельную сущность (смарт-процесс) в Bitrix24, не на лид. Иначе смешаете воронки.
Где хранить ID-связки
Это вопрос, в который упираются все. Мой стандартный подход:
- В Bitrix24 заводим пользовательское поле
UF_HUBSPOT_IDна каждой сущности (контакт, компания, сделка). - В HubSpot — custom property
bitrix_id(single-line text, indexed). - Дополнительно — внешняя таблица в БД middleware с парами
(hubspot_id, bitrix_id, entity_type, last_synced_at, sync_hash).
Зачем три места? Поля в самих CRM нужны для ручного дебага и фильтрации в UI. Внешняя таблица — для быстрого lookup без обращения к API (особенно при батч-операциях) и для хранения метаданных, которым не место в CRM (хеш состояния, версия маппинга, timestamp последней синхронизации).
Тайминг: вебхуки + страховочный поллинг
Только на вебхуках жить нельзя. И HubSpot, и Bitrix24 периодически их теряют — особенно Bitrix24 при массовых изменениях через импорт или роботов. Поэтому:
- Вебхуки — основной канал, latency 1–5 секунд.
- Периодический поллинг по
modified_since— страховка. Сравнивает хеши, синхронизирует расхождения, пишет в лог «доехало через поллинг, а не вебхук» (этот счётчик — индикатор здоровья вебхуков). Интервал подбирается под конкретный трафик и лимиты API. - Полная сверка раз в сутки ночью — для критичных сущностей (открытые сделки, активные контакты). Не синхронизация, а именно diff-репорт: что разошлось и почему.
Интервал поллинга — компромисс между актуальностью данных и нагрузкой на API. Bitrix24 особенно чувствителен к частым запросам, поэтому пороги стоит подбирать индивидуально.
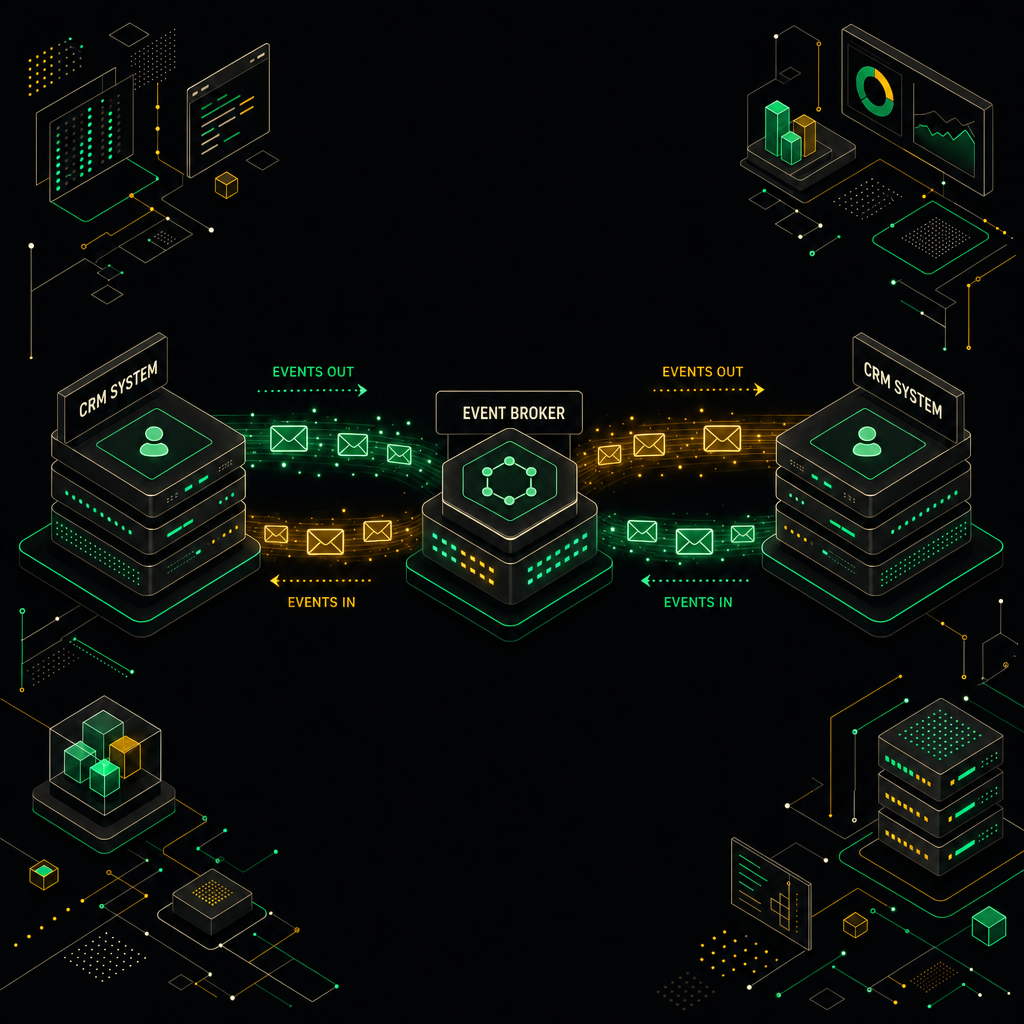 This diagram depicts how real-time events flow through a central message broker to keep both CRM systems instantly synchronized without direct coupling.
This diagram depicts how real-time events flow through a central message broker to keep both CRM systems instantly synchronized without direct coupling.
Маппинг воронки и стадий между двумя CRM
Когда у тебя две CRM, первое, что разваливается — это понимание, на какой стадии реально находится сделка. У маркетинга в HubSpot человек уже «Opportunity», а в Bitrix24 менеджер всё ещё двигает его по «Переговорам». Лечится это не синхронизацией стадий один-в-один (это путь в ад), а единой бизнес-воронкой поверх обеих систем.
Я делаю так: фиксирую 5–7 верхнеуровневых стадий, которые отражают реальный процесс, а не настройки CRM. У меня обычно это Lead → MQL → SQL → Opportunity → Customer → Churned. Это контракт между маркетингом и продажами. Под каждой такой стадией в HubSpot и Bitrix24 могут быть свои подстадии — пусть менеджеры дробят «Opportunity» на «Счёт выставлен», «Договор на согласовании», «Предоплата получена», мне это для отчётности на уровне бизнеса не важно.
Кто владеет переходом. Главный принцип: в каждый момент времени стадией владеет ровно одна система. Двунаправленное редактирование — это гарантированный race condition и ночные звонки. У меня граница проходит по SQL: до SQL включительно ведёт HubSpot (там скоринг, nurturing, формы), после SQL — Bitrix24 (там менеджеры, счета, телефония). Webhook от HubSpot на достижении SQL создаёт сделку в Bitrix24, дальше HubSpot стадию сделки уже не трогает — только читает. Обратно в HubSpot прилетают только два события: Closed Won и Closed Lost, чтобы маркетинг видел атрибуцию по кампаниям и считал CAC.
Маппинг как код. Маппинг живёт в git, не в головах и не в комментариях к интеграции. YAML, ревью раз в квартал, PR с обоснованием изменений:
# stage-mapping.yaml
hubspot_to_bitrix:
subscriber: { pipeline: 1, stage: NEW }
marketingqualifiedlead: { pipeline: 1, stage: IN_PROCESS }
salesqualifiedlead: { pipeline: 2, stage: NEW, create_deal: true }
opportunity: { pipeline: 2, stage: PREPAYMENT_INVOICE }
customer: { pipeline: 2, stage: WON }
Флаг create_deal: true на salesqualifiedlead — это и есть тот самый триггер передачи владения. Воркер интеграции читает этот YAML на старте, и любое изменение воронки (добавили подстадию, переименовали pipeline) проходит через PR с дифом, а не через «Вася в админке поправил». В ревью обязательно зову одного человека от продаж и одного от маркетинга — иначе через полгода маппинг перестаёт отражать реальность, и начинается тихая деградация данных.
Отдельно держу обратный маппинг bitrix_to_hubspot только для двух финальных стадий — это сознательно узкое горлышко, чтобы не было соблазна расширить его и снова получить двунаправленную синхронизацию. Этот же принцип контракта между командами хорошо описан в контексте автоматизации передачи лидов между маркетингом и продажами.
 A structured mapping table that translates equivalent pipeline stages between two CRM systems to ensure consistent sales reporting and handoffs.
A structured mapping table that translates equivalent pipeline stages between two CRM systems to ensure consistent sales reporting and handoffs.
Техническая интеграция: API, webhooks и подводные камни 2026 года
Когда я строю мост между HubSpot и Bitrix24, в 99% случаев речь идёт не про «подключить API», а про то, чтобы это не развалилось через месяц под реальным трафиком. Расскажу, на что наступал сам и что изменилось к этому году.
Что именно изменилось к 2026
Bitrix24. Входящие и исходящие вебхуки никуда не делись — это по-прежнему быстрый способ стартовать. Но если вам нужна публикуемая интеграция или OAuth-приложение, готовьтесь к тому, что с 2025 года часть сценариев Маркетплейса требует активной подписки — особенно всё, что связано с распространением приложений и расширенными правами. Личные вебхуки в рамках одного портала это пока не задело, но архитектуру я закладываю сразу под OAuth, чтобы потом не переписывать авторизационный слой.
HubSpot. API Keys окончательно ушли — работаем через Private Apps с scoped-токенами либо через публичные OAuth-приложения. API v3 стабилен, но в webhooks-настройках посыпались устаревшие параметры: rateLimitPolicy и period помечены как deprecated, и я уже видел подписки, которые после автомиграции начали отдавать события пачками иначе, чем ожидало приложение. Перепроверяйте размеры батчей на проде, не на стейдже.
Лимиты, которые реально упираются
Актуальные лимиты HubSpot зависят от тира подписки и регулярно обновляются — сверяйтесь с официальной документацией перед запуском интеграции. Bitrix24 имеет ограничение в 2 req/sec на метод, плюс золотое правило — batch до 50 операций за вызов. Без batch ваша синхронизация контактов будет ползти часами.
Для HubSpot главная практическая проблема не бёрсты, а фоновый sync, который незаметно съедает квоту.
Обработка ошибок и идемпотентность
Любой webhook рано или поздно прилетит дважды. Поэтому два неотменяемых правила:
- Backoff на 429 и 5xx. Экспоненциальный, с jitter. Если после 5–7 попыток не пролезло — в DLQ, не в основной поток.
- Correlation ID в каждом событии. Я кладу его в Redis с TTL на 24–72 часа и проверяю до записи в Bitrix24. Без этого «повторная доставка» превращается в дубли сделок, и чистить их потом — отдельный квест.
Подписи HMAC — теперь в обе стороны
Главный тренд 2026: верификация подписей перестала быть «хорошей практикой» и стала минимальной гигиеной. HubSpot отдаёт X-HubSpot-Signature-v3, Bitrix24 для исходящих вебхуков из приложений тоже подписывает payload. Я подписываю и свои ответы/коллбэки — некоторые корпоративные клиенты в этом году уже требуют двустороннюю верификацию по умолчанию, без неё интеграцию не пропускает их безопасник.
Минимальный приёмник на Node.js
// Node.js: приём webhook от HubSpot и передача в Bitrix24
app.post('/hs/contact', async (req, res) => {
const sig = req.headers['x-hubspot-signature-v3'];
if (!verifyHubSpotSignature(sig, req.rawBody)) return res.sendStatus(401);
const { objectId, propertyName, propertyValue } = req.body[0];
await queue.publish('contact.updated', {
objectId,
propertyName,
propertyValue,
correlationId: req.headers['x-request-id']
});
res.sendStatus(204);
});
Что здесь принципиально:
- Проверка подписи до парсинга бизнес-логики — иначе вы уже потратили ресурсы на невалидный запрос.
- В Bitrix24 идём не напрямую, а через очередь (RabbitMQ, SQS, Redis Streams — что удобнее). Это даёт ретраи, DLQ и развязывает SLA HubSpot и Bitrix24.
correlationIdпробрасываем сквозь всю цепочку: при записи в Bitrix24 воркер сначала проверит, не обрабатывали ли мы это событие.- Отдаём
204быстро. HubSpot считает webhook упавшим, если ответа нет за ~5 секунд — и начинает ретраить, добавляя вам нагрузки на ровном месте.
Главный подводный камень, который я повторяю каждому, кто берётся за такую интеграцию: не пытайтесь делать sync синхронным. Очередь, идемпотентность и подписи — это не overengineering, это минимальный набор, без которого интеграция в 2026 не живёт дольше первого маркетингового всплеска.
Дедупликация контактов и компаний между системами
Когда я в первый раз синхронизирую две CRM, наивный подход «склеим по email» отваливается на первой же тысяче записей. И HubSpot, и Salesforce из коробки умеют дедуплицировать только по точному совпадению email (ну или по ID, что вообще не помогает в кросс-системном сценарии). А у меня в реальности ivan.petrov@acme.com в одной системе и i.petrov@acme.com в другой — это один человек, но для нативной логики это два разных контакта. Плюс компании: Acme Inc., ACME, Inc, Acme Incorporated — три записи, ноль совпадений.
Поэтому я строю собственный матчинг в несколько слоёв:
- Email после нормализации. Lowercase, обрезаем
+tagдля Gmail, схлопываем точки в локальной части для гугл-доменов, убираем пробелы и невидимые символы. - Телефон в E.164. Пропускаю всё через
phonenumbersс дефолтным регионом по стране контакта. Без этого+7 (495) 123-45-67и84951234567живут отдельной жизнью. - Домен компании. Если у двух контактов одинаковый корпоративный домен (отрезаю
mail.,corp.и публичные провайдеры из чёрного списка), это сильный сигнал, что они из одной компании, даже если названия выглядят по-разному. - Fuzzy-match имён и названий. Jaro-Winkler для латиницы; для имён, которые транслитерируются туда-сюда, добавляю фонетику — Double Metaphone для латиницы и адаптированный Soundex для кириллицы (Metaphone на кириллице работает плохо, лучше сначала транслитерировать в латиницу по ГОСТ 7.79 и уже потом фонетику).
- Каноникализация юрформ. Перед сравнением названий компаний прогоняю строку через словарь:
ООО,LLC,Pvt Ltd,GmbH,S.A.,Co., Ltd.→ выкидываются или приводятся к единому маркеру. ИначеBeta GmbHиBetaне совпадут даже на высокой схожести.
Скоринг я держу простым и интерпретируемым — никакой ML на старте, потому что объяснить бизнесу, почему два контакта склеились, важнее, чем выжать лишний процент точности:
def match_score(a, b):
score = 0
if normalize_email(a.email) == normalize_email(b.email):
score += 0.6
if e164(a.phone) == e164(b.phone):
score += 0.3
if domain(a.email) == domain(b.email):
score += 0.1
score += 0.2 * jaro_winkler(a.name, b.name)
return min(score, 1.0)
Дальше — пороги. Записи с высоким скором мерджу автоматически. Пограничный диапазон уходит в очередь ручного ревью: тимлид RevOps смотрит пары side-by-side и кликает merge/keep/split. Записи с низким скором считаю разными и не трогаю. Конкретные пороги калибруются на размеченной выборке из реальных данных проекта — универсальных значений нет, почти всегда приходится двигать их пару раз после первых прогонов.
По инструментам выбор такой: если матчинг нужен внутри одной CRM и быстро — Dedupely или LeadAngel закрывают 80% кейсов без кода. Для двусторонней синхронизации с дедупом на лету хорошо ложится Stacksync. Когда логика становится специфичной (мультиязычные имена, отраслевые правила по компаниям, B2B-иерархии с дочками), я ухожу на собственный сервис на базе Python-библиотеки RecordLinkage или dedupe.io — там есть и блокировка по ключам, чтобы не сравнивать N×N, и активное обучение на ревью-очереди.
Главное правило, которое я выучил на дорогих ошибках: никогда не мерджить автоматически без журналируемого undo. Любой авто-merge пишет в отдельную таблицу merge_log с обеими исходными записями в JSON, чтобы через неделю, когда выяснится, что Acme Inc. и Acme LLC — это разные юрлица одной группы, можно было откатить пакетом, а не восстанавливать вручную из бэкапа.
Compliance: GDPR, 152-ФЗ и data residency в 2026
Если вы держите CRM-стек на двух полюсах — Bitrix24 и HubSpot — то регуляторика не абстракция, а архитектурное ограничение, которое нужно зашить в схему данных до первого синка.
152-ФЗ: первичная запись на территории РФ. Роскомнадзор интересует не «где-то лежит копия», а где произошла первичная запись персональных данных гражданина РФ. Это значит, что если лид с российским телефоном или паспортом приходит через форму, он должен сначала попасть в Bitrix24 — либо коробку на ваших серверах, либо облако с подтверждённым RU-датацентром (у Битрикса есть отдельный контур, проверяйте договор и фактический IP-адрес инстанса, не маркетинговые буклеты). Передавать такого субъекта в HubSpot первичной записью — нарушение, даже если вы потом синхронизируете обратно.
GDPR для европейских контактов. Здесь обратная логика: для субъектов из ЕС нужно законное основание обработки (consent или legitimate interest, задокументированное), DPA с HubSpot подписано (он сам выступает processor), и хранение в EU data center — у HubSpot он есть, активируется при создании аккаунта и не переключается потом. Трансграничка из ЕС в РФ — отдельная боль: РФ не имеет adequacy decision, SCC к санкционке не очень применимы, поэтому проще всего такую
 This compliance map identifies where customer data must legally reside, guiding architects on routing and storage decisions within a dual-CRM setup.
This compliance map identifies where customer data must legally reside, guiding architects on routing and storage decisions within a dual-CRM setup.