

Почему 5 дней: логика спринта и что происходит, если растянуть
Три недели на аудит звучат солидно. На практике это означает: неделя на согласование доступов, неделя на интервью, которые переносятся, и финальная неделя с попыткой собрать всё в связный документ. Клиент устаёт, фокус размывается, а на выходе получается консалтинговый отчёт на 80 страниц, который никто не читает.
Пять дней работают по другой механике.
Это не дефицит времени, а давление, которое заставляет и консультанта, и клиента держаться сути. Нет возможности уйти в сторону, нет смысла копать слои, которые не влияют на решение. McKinsey в своём отчёте за 2025 год зафиксировали картину, которую я вижу на каждом втором проекте: большинство компаний использует AI точечно, 1-2 инструмента без связной архитектуры. Именно это и надо поймать быстро: где инструменты есть, где они висят в воздухе и ни с чем не связаны, и где зияет очевидная дыра.
Структура пяти дней у меня выглядит так. День первый: брифинг с ключевыми людьми и сбор исходных данных (процессы, стек, текущие AI-инициативы, если они есть). Дни второй и третий: погружение по доменам, обычно это продажи, операции, продукт и поддержка в разных пропорциях в зависимости от бизнеса. День четвёртый: анализ и приоритизация, где я отделяю то, что даёт результат за 30 дней, от того, что требует полугодовой трансформации. День пятый: финальный отчёт и презентация стейкхолдерам.
Для SMB и mid-market этой глубины достаточно. Там редко бывает 15 департаментов с уникальными процессами. Обычно есть 3-4 узла, которые реально влияют на деньги, и их можно закрыть за пять рабочих дней без того, чтобы загнать команду клиента в усталость от бесконечных встреч.
Если растянуть дольше, возникает ещё одна проблема: контекст устаревает. За три недели в компании успевает поменяться приоритет, уйти ключевой сотрудник или выйти новый инструмент, который ломает часть выводов. Короткий спринт фиксирует момент. Длинный аудит описывает то, чего уже нет.

Пятидневный спринт закрывает то, на что классический аудит тратит шесть недель.
День 1: брифинг, стейкхолдеры и сбор первичных данных
Первый день аудита делает одно: создаёт карту людей и их реальных болей. Не процессов, не инструментов. Сначала люди.
На стартовый звонок нужны конкретные роли. CEO или COO, ИТ-директор, руководители продаж, операций и HR. Если кто-то из них недоступен "прямо сейчас" и вместо себя присылает заместителя, это уже первые данные: либо тема не приоритетна, либо есть что скрывать. Фиксируй.
Разговор строится вокруг трёх блоков.
Первый: текущий инструментальный стек. Не официальный список из ИТ-политики, а что люди реально используют. ChatGPT в браузере, Notion AI, Otter.ai для записи звонков с клиентами, и всё это мимо любых корпоративных закупок. Спрашивай прямо: "Какие AI-инструменты используют ваши сотрудники, о которых ИТ не знает?" Пауза после этого вопроса обычно длиннее, чем комфортно.
Второй: бюджет на ИИ и автоматизацию за 2025-2026 годы. Здесь важна конкретная цифра: сколько уже потрачено, сколько запланировано, кто принимает решения о закупках. Расхождение между суммой в бюджете и реально развёрнутыми инструментами покажет либо теневые закупки, либо несработавшие проекты, которые не принято обсуждать.
Третий: инциденты с утечкой данных через AI-инструменты. За последние полтора года таких случаев стало кратно больше: сотрудник вставляет CRM-выгрузку в Claude, менеджер диктует условия контракта голосовому ассистенту. Большинство компаний не фиксировали это как "инциденты" и не расскажут об этом сами. Надо спросить напрямую.
По итогам звонка запрашивай три документа: оргсхему (актуальную, не ту, что висит на сайте), список всех SaaS-подписок с владельцами, три последних операционных отчёта. Именно три, не один: динамика метрик говорит больше, чем срез.
Артефакт первого дня: карта стейкхолдеров. На ней по каждому участнику: зона ответственности, что называет своей болью, и что, судя по разговору, болью реально считается. Это два разных столбца. ИТ-директор говорит "нам нужна стандартизация инструментов", а по интонации понятно, что настоящая боль: он узнаёт о новых AI-инструментах в компании последним и это его унижает. С такими данными потом разговаривать про рекомендации значительно проще.
Всё сказанное устно пиши в отдельный блокнот или отдельный документ, изолированно от официальных данных. Расхождение между тем, что написано в политике, и тем, что сказал вслух финдиректор, часто оказывается самым ценным наблюдением всего аудита.
Карта стейкхолдеров фиксирует, кто принимает решения и где болит сильнее всего.
Чек-лист аудита: 6 доменов и конкретные проверочные вопросы
Прежде чем идти по доменам, сделай одно простое упражнение. Спроси у каждого руководителя отдела: "Какие ИИ-инструменты вы используете?" Запиши ответы. Потом загляни в корпоративную карту платежей и сравни. Расхождение между официальным списком и реально используемыми инструментами нередко оказывается значительным. Это и есть отправная точка аудита.
Домен 1. Инвентаризация
Речь не о том, что куплено или задемонстрировано на стратсессии. Речь о том, что реально открывают в браузере в понедельник утром. Для каждого инструмента нужны три вещи: дата первого использования, список активных пользователей за последние 30 дней, и кто платит: ИТ-бюджет, отдел или личная карточка сотрудника. Последнее особенно важно: инструменты на личных картах означают отсутствие договора, отсутствие DPA и полную невидимость для безопасников.
Домен 2. Данные и интеграции
Для каждого инструмента из списка нужно ответить: откуда он берёт данные? Часто выясняется, что CRM-данные вручную копируются в GPT-обёртку, потому что нормальной интеграции нет. Это и дублирование, и риск, и потеря времени. Зафиксируй, где есть API-связки, а где живёт ручной ввод. Ручной ввод в 2026 году почти всегда признак либо недозрелой интеграции, либо инструмента, купленного без анализа fit.
Домен 3. Безопасность
Самый болезненный домен. Конкретный вопрос, который вскрывает проблему мгновенно: передаются ли персональные данные клиентов или сотрудников во внешние LLM без анонимизации? В большинстве компаний, где я видел этот процесс, ответ "мы не знаем". Это хуже, чем "да". Дополнительно проверяй: есть ли SSO для ИИ-инструментов или каждый логинится отдельным паролем, логируется ли использование вообще, и если да, кто эти логи читает.
Домен 4. Процессы и ROI
Для каждого инструмента должна быть метрика до и после. Время на задачу, количество обращений в поддержку, процент ошибок. Если метрики нет, это не катастрофа, но нужно честно записать: "измерений не проводилось". Инструменты без измерений в следующем бюджетном цикле отрезать проще всего, что иногда правильно, а иногда нет. Без данных не разберёшься.
Домен 5. Компетенции команды
Типичная картина: один человек в компании умеет писать промпты, знает обходные пути, настроил пять интеграций и держит всё в голове. Это критическая зависимость. Проверяй: сколько сотрудников прошли хоть какое-то обучение работе с конкретным инструментом, есть ли задокументированные промпты и workflows, и что произойдёт, если энтузиаст уйдёт в отпуск на три недели. Именно этот сценарий описывает, почему корпоративное AI-обучение так часто заканчивается ничем: знания живут в одном человеке, а не в команде.
Домен 6. Governance
Кто решает, подключать ли новый ИИ-инструмент? Если ответа нет, решение де-факто принимает любой, у кого есть корпоративная карта. Проверяй: существует ли AI-политика в письменном виде, как компания обрабатывает ошибки ИИ (когда модель выдала неверный результат, который ушёл клиенту, был ли постмортем), и есть ли вообще ответственный за AI-стратегию или это размазано по трём вице-президентам.
CHECKLIST_DOMAINS = [
{
'domain': 'Инвентаризация',
'questions': [
'Полный список ИИ-инструментов с датой подключения',
'Активные пользователи за последние 30 дней',
'Кто владелец подписки (ИТ / отдел / физлицо)'
]
},
{
'domain': 'Данные и интеграции',
'questions': [
'Откуда каждый инструмент берёт данные',
'Где данные вводятся вручную вместо API',
'Есть ли дублирование одних данных в нескольких инструментах'
]
},
{
'domain': 'Безопасность',
'questions': [
'Передаются ли PII в ChatGPT/Claude без анонимизации',
'Есть ли SSO для ИИ-инструментов',
'Логируется ли использование'
]
},
{
'domain': 'Процессы и ROI',
'questions': [
'Есть ли метрика до/после для каждого инструмента',
'Кто замерял эффект и когда последний раз',
'Какие инструменты не имеют ни одного измерения'
]
},
{
'domain': 'Компетенции',
'questions': [
'Сколько сотрудников обучено работе с инструментом',
'Задокументированы ли промпты и workflows',
'Есть ли зависимость от одного носителя знаний'
]
},
{
'domain': 'Governance',
'questions': [
'Существует ли AI-политика в письменном виде',
'Кто принимает решения о подключении новых инструментов',
'Как обрабатываются ошибки ИИ, попавшие к клиентам'
]
}
]
def run_domain_audit(domains: list[dict]) -> dict:
results = {}
for d in domains:
print(f"\n=== {d['domain']} ===")
answers = {}
for q in d['questions']:
answer = input(f"{q}: ").strip()
answers[q] = answer if answer else 'не заполнено'
results[d['domain']] = answers
return results
if __name__ == '__main__':
audit_results = run_domain_audit(CHECKLIST_DOMAINS)
empty_count = sum(
1 for domain in audit_results.values()
for v in domain.values()
if v == 'не заполнено'
)
total = sum(len(d['questions']) for d in CHECKLIST_DOMAINS)
print(f"\nПробелов: {empty_count} из {total} пунктов")
Скрипт намеренно простой. Он не анализирует ответы, только собирает их и считает пустые поля. Если пустых больше трети, у компании нет аудита, есть иллюзия аудита. Это тоже результат, и он важен.

Шесть доменов аудита охватывают всё: от качества данных до готовности команды.
Дни 2-3: глубокие интервью и полевые наблюдения
К этому моменту у тебя уже есть первичный срез по зрелости. Дни 2-3 дают то, что документы и опросники не дают никогда: живое поведение людей с инструментами.
Интервью я делю по доменам. Продажи: смотрю на CRM-автоматизацию и AI SDR. Поддержка: чат-боты, авто-роутинг тикетов. Финансы: сверка и отчётность. HR: скрининг резюме и первичная квалификация кандидатов. В каждом домене есть свои типичные провалы и свои типичные победы, так что универсальный вопросник не работает.
Самый ценный инструмент этих двух дней называется теневым наблюдением. Прошу конкретного сотрудника просто показать свой рабочий день с инструментами, без презентаций. Именно здесь всё и вскрывается. Я видел ситуацию, когда компания считала, что у неё автоматизирована сверка счетов: бот действительно сопоставлял строки в двух таблицах. Но финансист после каждого прогона открывал Excel и перепроверял вручную, потому что "бот иногда ошибается". Это не автоматизация. Это автоматизация плюс ручной дублирующий шаг, который съедает половину выигрыша.
Такой паттерн встречается почти везде. Формально инструмент внедрён, фактически он вызывает тревогу у людей, которые с ним работают, и они страхуются.
Если клиент не видит результатов от внедрённых инструментов, причины, как правило, две: либо реализация сломана, либо замеров просто нет и никто не знает, что происходит. Второй случай встречается чаще, чем первый.
Отдельно фиксирую теневой ИИ. На интервью периодически выясняется, что сотрудники используют личные аккаунты ChatGPT или Gemini для рабочих задач, потому что корпоративные инструменты медленнее или их нет вообще. Иногда через личный Perplexity уходят фрагменты клиентских данных или финансовых отчётов. Люди не злоумышленники, им просто нужно работать быстро. Это прямой риск по данным и одновременно точка входа для нормального governance: если спрос на ИИ уже есть, его нужно легализовать, а не запрещать.
Артефакт дней 2-3: карта процессов AS-IS. На ней отмечаю каждый процесс с тремя статусами: ИИ включён и работает, ИИ включён формально но есть ручной обходной путь, ИИ отсутствует. Рядом с каждой пометкой пишу причину: техническая, организационная, культурная. Это не красивая схема для слайда. Это рабочий документ, который на следующем шаге ляжет в основу gap-анализа.

Цветовая кодировка сразу показывает, какие шаги процесса можно автоматизировать первыми.
AI Maturity Score: как поставить оценку и не обидеть клиента
Первое, что делает консультант после аудита, это объясняет клиенту, где он находится. И здесь важно не превратить разговор в разбор полётов. Матрица зрелости работает именно потому, что она нормализует: у вас уровень 2.4, и это не диагноз, а координата.
Уровни выглядят так:
- 1 - ИИ-инструментов нет вообще, тема воспринимается как что-то далёкое
- 2 - есть точечные эксперименты: кто-то купил подписку на ChatGPT, кто-то запустил пилот, но измерений нет и воспроизвести результат нельзя
- 3 - повторяемые процессы с метриками, команда знает, что считать
- 4 - масштабированные внедрения, есть governance: политики, ответственные, контроль рисков
- 5 - ИИ встроен в бизнес-модель, без него компания буквально не работает так же
По отчёту McKinsey за 2025 год, большинство компаний застряли на втором уровне: ChatGPT-подписки есть, системной архитектуры нет.
Шесть измерений скоринга
Оценивать только технологии бессмысленно. Я использую шесть измерений, каждое от 1 до 5:
- Лидерство - понимает ли C-level, что они покупают и зачем
- Стратегия - есть ли дорожная карта с конкретными целями
- Операции - встроен ли ИИ в реальные рабочие процессы
- Технологии - инфраструктура, интеграции, MLOps
- Люди - компетенции команды, обучение, adoption
- Governance - политики использования, управление рисками, compliance
Итоговый скор считается как среднее, но среднее здесь почти не информативно само по себе. Паттерн важнее числа.
maturity_score = {
'leadership': 3,
'strategy': 2,
'operations': 3,
'technology': 4,
'people': 2,
'governance': 1
}
avg = sum(maturity_score.values()) / len(maturity_score)
# avg = 2.5
gaps = {k: v for k, v in maturity_score.items() if v < 3}
# gaps = {'strategy': 2, 'people': 2, 'governance': 1}
Смотрите на gaps: стратегия 2, люди 2, governance 1 при технологиях 4. Это классический красный флаг. Компания купила инструменты, но не построила систему вокруг них. Технический долг здесь не в коде, а в организации.
Высокий technology-скор при низком people-скоре означает, что инструменты используют 3 человека из 200, и то без понимания ограничений. Это риск, а не достижение. И именно здесь компании чаще всего застревают: менеджерам нужны готовые сценарии работы с AI-инструментами, а не абстрактные курсы по промптингу, которые не конвертируются в ежедневную практику.
Как подать результат клиенту
Никогда не говори "у вас плохо с governance". Говори: "по измерению governance вы на уровне 1, это типично для компаний, которые только начали формализовывать AI-практики. За 6 месяцев реально выйти на 2.5, за 12 - на 3."
Конкретный скрипт для слайда: "Ваш текущий AI Maturity Score: 2.5. Медиана по вашей отрасли и размеру компании: 2.3. Целевой показатель через 12 месяцев: 3.5. Три приоритетных направления роста: governance, люди, стратегия."
Цифра 2.5 перестаёт звучать как провал, когда рядом стоит медиана 2.3. Клиент слышит не "вы отстаёте", а "вы чуть выше среднего, но до следующего уровня есть конкретный путь". Разница в восприятии огромная, а данные те же самые.
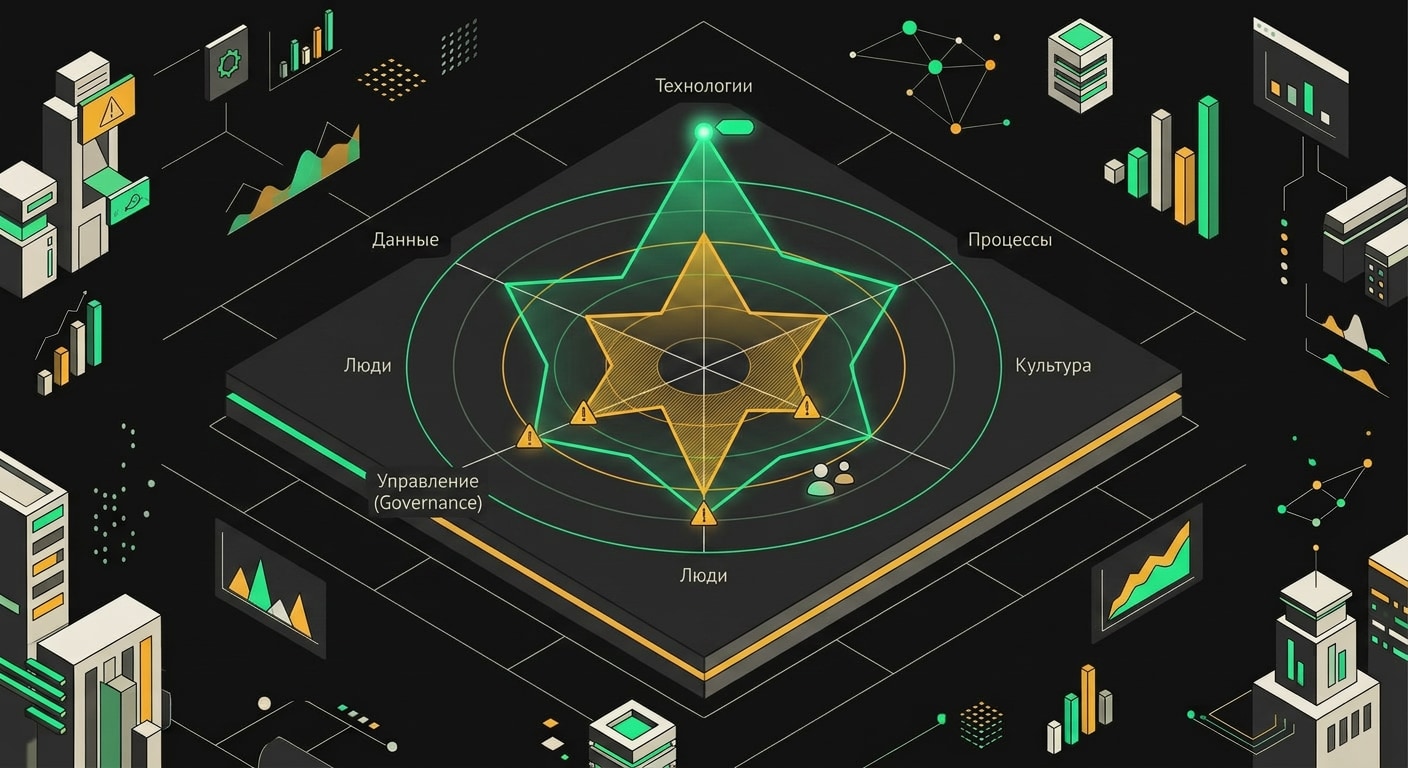
Перекошенный радар наглядно объясняет, почему одни направления тормозят весь проект.
День 4: приоритизация находок и построение роадмапа
К четвёртому дню аудита у вас на руках список из 20-40 наблюдений. Часть из них критическая, часть косметическая, часть вообще не ваша зона ответственности. Без структуры этот список превращается в документ, который открывают один раз и кладут в папку "разобраться потом".
Инструмент, который реально работает: матрица 5x5, где по горизонтали откладывается сложность внедрения (1, настройка за полдня, 5, полгода разработки и миграция данных), по вертикали, бизнес-эффект (1, приятно иметь, 5, прямо влияет на выручку или операционные потери). Каждую находку ставим точкой. Никаких субъективных ощущений: сложность считается в человеко-днях с конкретной командой клиента, эффект привязывается к деньгам или времени из интервью третьего дня.
Четыре квадранта дают четыре судьбы для каждой находки. Левый верхний (сложность 1-2, эффект 3-5), быстрые победы, делаем первыми. Правый верхний (сложность 4-5, эффект 4-5), стратегические проекты, требуют отдельного планирования и бюджета. Левый нижний (сложность 1-2, эффект 1-2), низкий приоритет, можно сделать попутно, если руки дойдут. Правый нижний (сложность 4-5, эффект 1-2), "пересмотреть": либо клиент переоценил ценность, либо есть более дешёвый способ достичь того же.
Быстрые победы в B2B-компаниях выглядят предсказуемо. Автоматизация входящих лидов через n8n или Make с маршрутизацией по источнику и размеру сделки, хорошо реализованный пайплайн может заметно сократить время до первого контакта с потенциальным клиентом. Шаблонизация еженедельных отчётов через Notion AI или аналог, 1-2 человеко-дня, задача типичная. Автоответы по FAQ в поддержке с передачей контекста оператору, 4-6 дней внедрения, цель: снизить долю тикетов, требующих участия человека.
Для каждой рекомендации в таблице три колонки помимо координат матрицы: конкретный инструмент или подход (не "AI-решение", а "Claude API через Zapier" или "GPT-4o в OpenAI Assistants"), оценка в человеко-днях с разбивкой на настройку, тестирование и обучение команды, и метрика через 90 дней с базовым значением из аудита. Базовое значение критически важно записать сейчас, потому что через три месяца никто не вспомнит, сколько времени тратили до.
Роадмап строится на трёх горизонтах. Первые 30 дней: только быстрые победы из левого верхнего квадранта, максимум 3-4 инициативы, иначе команда распылится. С 30 по 90 день: интеграции между системами и обучение, здесь появляются задачи из правого верхнего квадранта в стадии подготовки. С 90 по 180 день: масштабирование работающего и governance, политики использования AI, контроль качества, аудит промптов.
Артефакт дня 4 выглядит так: одна страница с матрицей (можно скриншот из Miro или таблица в Google Sheets), вторая страница с роадмапом в виде таблицы "горизонт / инициатива / ответственный / метрика / статус". Ничего лишнего. Клиент должен быть способен взять этот документ, вставить в итоговый отчёт и показать совету директоров без правок. Если вам нужно объяснять структуру прежде чем показать содержание, вы сделали артефакт для себя, а не для них.
Один практический момент по оценкам сложности: всегда спрашивайте у клиента, есть ли в команде человек, который уже работал с выбранным инструментом. Если есть, делите оценку на 1.5. Если нет, умножайте на 2. Кривая обучения съедает больше времени, чем любая техническая интеграция.




